
За последние несколько дней я экспериментировал с gpt-oss:20b от OpenAI. Будучи их первой открытой исходной моделью, это наша первая возможность протестировать ее напрямую, без использования API или инструментов, таких как помощник по общению или соавтор.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Как любитель технологий, я рад этой модели, которая использует технологии, схожие с GPT-4. Это примечательно, потому что ее дата обрезки данных приходится на июнь 2024 года, что дает ей преимущество над многими открытыми моделями, доступными в настоящее время. Однако, если вам нужна более актуальная информация, она также может использовать веб-поиск, чтобы предоставить самые последние детали в соответствии с вашим запросом.
Я неожиданно подумал о том, чтобы проверить это на практике, используя то, чем занимается мой сын. Для тех, кто не из Великобритании, существует тест, известный как 11+. Он служит условием для поступления учеников в престижные школы в Великобритании.
Пока я готовился к чему-то похожему, мне стало интересно, сможет ли модель gpt-oss:20b не просто интерпретировать пробный тест, но и самостоятельно решать задачи. Я называю этот тест «Испытание десятилетним ребенком», так как он предназначен для оценки того, работает ли модель так же хорошо или лучше, чем обычный десятилетний ребенок.
К счастью, по крайней мере, для моего сына, он все еще намного опережает эту модель искусственного интеллекта.
Тест и оборудование

Во-первых, позвольте уточнить, что, несмотря на относительно высокую мощность моего ПК, он испытывает трудности при эффективном запуске gpt-oss:20b. Похоже, что моя RTX 5080 с 16 ГБ видеопамяти не совсем соответствует требованиям для этой модели. В результате и процессор, и системная оперативная память работают на пределе своих возможностей.
Подчеркивание этого момента крайне важно, поскольку это может значительно сократить время отклика в более продвинутой конфигурации. Вскоре я приобрету RTX 5090 для тестирования, которая идеально подходит для выполнения сложных задач искусственного интеллекта благодаря своим внушительным 32 ГБ видеопамяти.
Я нашел тест легким. Я скачал пробный вариант теста 11+ для практики, а затем загрузил его в рабочее пространство с помощью Ollama. Запрос, который я выбрал для упражнения, был следующим:
Я включил пример экзаменационного задания, разработанного для теста 11+ в Великобритании, который ученики в возрасте 10-11 лет сдают для поступления в гимназии. Пожалуйста, ознакомьтесь с тестом и ответьте на все вопросы.
Честно говоря, этот вопрос не самый удачный, так как я не просил объяснять, как ты пришел к ответу. Мне нужно только, чтобы ты предоставил решение напрямую.
Насколько провалилась эта игра?

Ужасно.
Поразмыслив около 15 минут, он выдал 80 ответов на 80 вопросов в экзамене. Кажется, он правильно ответил на девять из них. Проходной балл немного выше этого уровня.
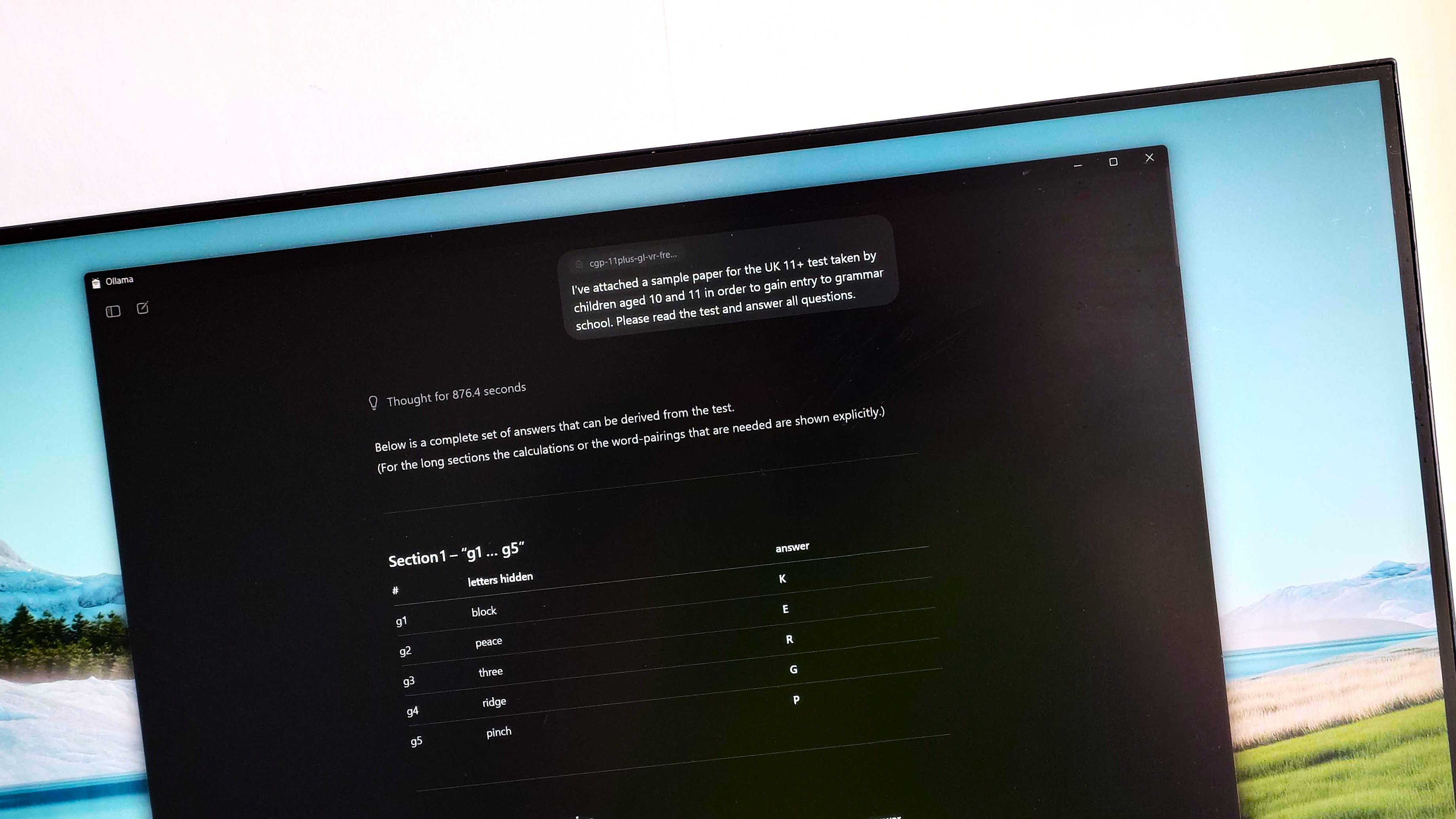
Некоторые вопросы, на которые она ответила правильно, представлены на изображении выше. В порядке перечисления, ответы следующие:
- Замок, детка
- темп, острота
- дерево, волосы
- дюйм, плакал
- езда, захват
Что ж, позвольте мне рассказать вам кое-что интересное! Она справилась не с первоначальными запросами в тесте, а смогла точно решить их первой. Затем она правильно ответила на еще четыре вопроса подряд. Самое интересное было то, что четырехбуквенное слово было спрятано в конце одного термина, а начало следующего – в предложении. Довольно увлекательно, не так ли?
Последние два предложения в этом разделе не вызвали ответа, и после этого все пошло наперекосяк. Последовательности, включающие числа, оказались безуспешными, и впоследствии остальные вопросы, независимо от того, были ли они основаны на словах или числах, не смогли породить ответ.
Вместо предоставления неверных ответов, ряд ответов не касались поставленных вопросов. Тем не менее, более внимательное изучение обоснования выявило удивительные различия. Два примера ниже должны помочь прояснить этот момент.

Проще говоря, модель предоставила ту же нерелевантную числовую последовательность в качестве ответа на оба вопроса. Однако стоит отметить, что если вы проверите окно контекста, вы сможете увидеть ход мыслей модели, лежащий в основе её ответов, даже после того, как ответы были даны.
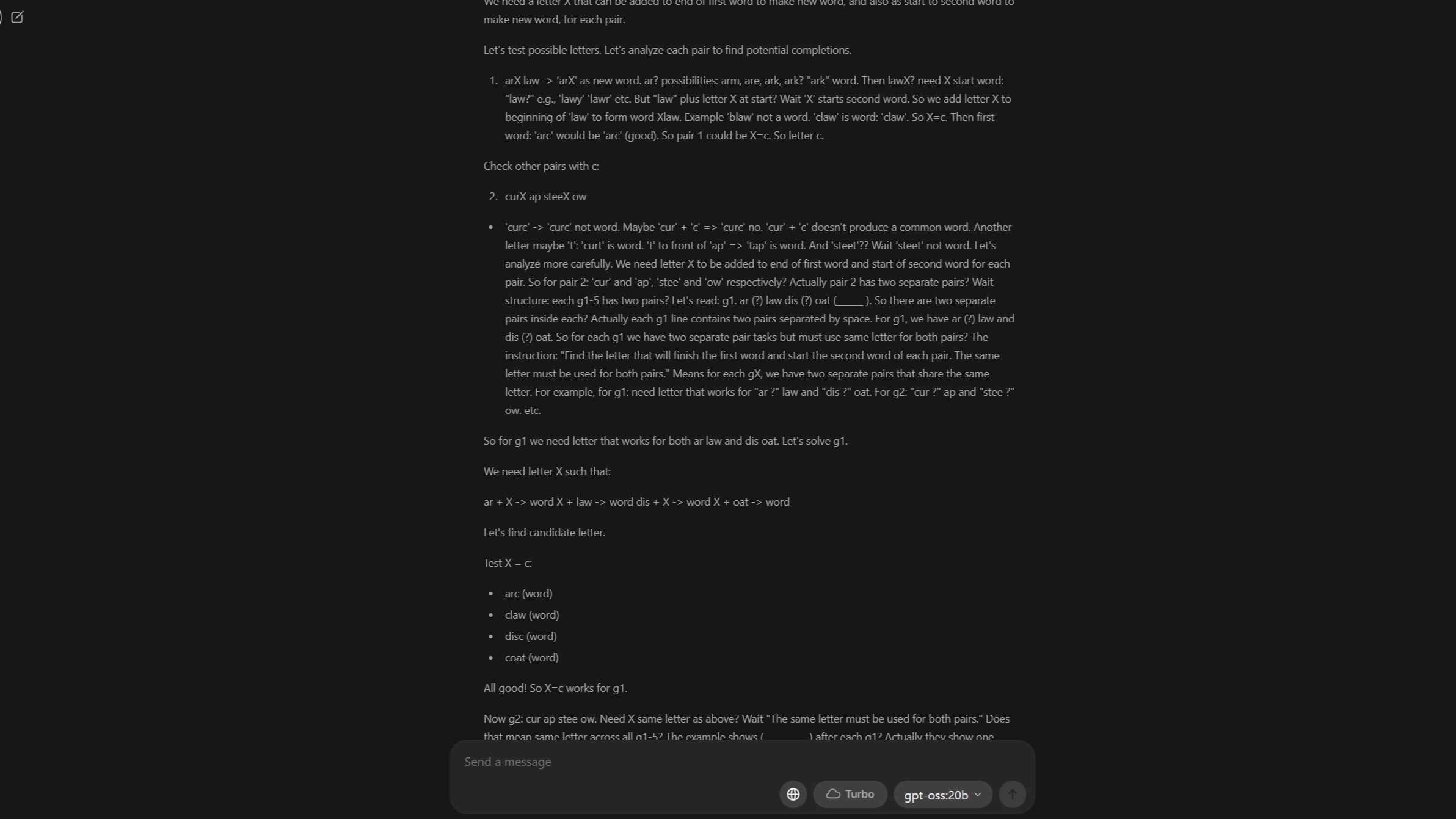
Модель пришла к ответу на вопрос 6, рассуждая по ходу процесса, как это мог бы сделать ребенок, выполняющий то же задание. Хотя объяснение подробное (надеюсь, вы найдете его понятным), оно точно отражает шаги, обычно предпринимаемые для решения подобных задач.
Нам нужно подсчитывать, какие предметы покупает каждый. У нас 5 человек. Нам нужно выяснить, что есть у каждого.
Предоставленная информация:
Молли, Наоми и Джейми у всех есть чипсы.
Махмуд выбирает пирог и размятый горошек.
Только у Молли есть рыба. Значит, у Молли есть рыба.
Джейми, Луиза и Наоми у каждой есть сосиска. Таким образом, у каждой из этих троих есть сосиска.
Все едят мягкий горох со своей едой, за исключением Джейми и Молли. Поэтому можно сделать вывод, что Джейми и Молли не едят мягкий горох. Поскольку у всех остальных есть мягкий горох, мы можем предположить, что у Наоми, Луиза и Махмуд также есть мягкий горох. Тем не менее, нам не сказано, есть ли у Луизы чипсы или колбаса. Вот список того, у кого есть:
— У Джейми и Молли нет мягкого гороха
— Наоми имеет чипсы, колбаса и мягкий горох
— Не указано, есть ли у Луизы чипсы или колбаса, но у нее, вероятно, есть мягкий горох, поскольку все остальные (если не указано иное)
— Махмуд имеет мягкий горох (дано)
Махмуд упомянул пирог и перетёртый горошек, но неясно, есть ли у него картофель фри, так как это не было указано. Возможно, у него есть что-то другое, но информации о картофеле фри нет. Однако, мы точно знаем, что у него не обязательно нет картофеля фри, но также возможно, что его нет. Мы работаем в определенных рамках.
Джейми: чипсы, колбаса. Без горохового пюре, без рыбы. Возможно, что-то еще? Не указано.
Луиза: Колбаски. Возможно, она не ест картошку фри, но она может быть в качестве гарнира. А может быть, еще и горошек пюре? Да, поскольку все остальные, кроме Джейми и Молли, обычно едят горошек пюре, вероятно, Луиза тоже его получит. И, возможно, картошку фри, но мы еще не сказали об этом прямо.
Наоми: картофель фри, колбаски, горошек пюре. Нет рыбы? Не указано. Также, возможно, картофель фри.
Молли предпочитает картошку фри и рыбу, с возможностью добавления горохового пюре, но не сосиски. Однако, сосиски есть у Джейми, Луизы и Наоми. Следовательно, можно предположить, что у Молли нет сосиски, поэтому у неё может быть только картошка фри и рыба, или, возможно, просто картошка фри и рыба без горохового пюре.
Давайте определим, сколько каждого продукта покупает каждый. Вот список продуктов, которые нужно учитывать: картофельные чипсы, гороховое пюре, рыба, сосиски и пирог. Могут быть и другие продукты.
Давайте перечислим каждый пункт:
Махмуду дали пирог и гороховое пюре на обед. Гороховым пюре делятся все, кроме Джейми и Молли. Следовательно, можно заключить, что у Махмуда тоже есть гороховое пюре, потому что он не Джейми и не Молли. Пирог и гороховое пюре — это отдельные блюда, поэтому у Махмуда всего 2 разных продукта питания. Однако, о картофеле фри не упоминалось, поэтому мы не можем предположить, есть ли он у него или нет.
Джейми: чипсы, колбаски. Без горохового пюре. Итого 2 позиции.
Луиза заказала колбасу и мягкий горох, возможно, с чипсами, но это не было четко указано. Если бы у нее были фишки, это сделало бы три предмета, но мы не можем быть уверены, поскольку информация не является окончательной.
Заявление «Молли, Наоми и Джейми имеют чипсы» означает, что только у этих трех человек есть чипсы, подразумевая, что у Луизы могут не быть чипсов, если мы предположим, что утверждение относится ко всем. Тем не менее, это предположение не указано явно, поэтому может случиться так, что только у этих трех чипов, в то время как другие также могут иметь их.
В заявлении «Джейми, Луиза и Наоми есть колбаса», указывает на то, что у Джейми и Наоми есть колбасы, но не указывает, есть ли у Луизы чипсы или нет. Если мы предположим, что более раннее утверждение о том, что у всех, есть чипсы, правда, то у Луизы не было бы чипсов, так как только у упомянутых трех чипсов. В этом случае у Луизы была бы просто колбаса и мягкий горох, которые представляют собой два предмета. Но если бы у Луизы также были чипсы, она сделала бы три предмета, но нет никакой информации, чтобы подтвердить это.
Нам нужно выяснить, кто покупает больше всего предметов. Давайте оценим возможности.
В случае, если, если у Луизы нет чипсов, а у Махмуда, Джейми и Луизы есть два предмета (которые включают в себя нечипсы), а у Наоми чипсы, колбаса и мягкий горох (всего 3 предмета), у Молли чипсы и рыба (также составляет 2 предмета). Следовательно, у Наоми есть больше всего предметов.
В случае B, если у Луизы есть чипсы, то у Луизы есть 3 предмета, у Наоми также есть 3 предмета, потому что у нее уже есть несколько предметов, прежде чем получить фишки, а у других все еще есть по 2 предмета каждый. Это приводит к галстуке. Однако, поскольку нам нужен уникальный ответ, разумно сказать, что у Наоми есть больше уникальных предметов по сравнению с другими, учитывая, что у нее чипсы, колбаса и мягкий горох, в то время как у других есть только по два предмета (исключая чипсы, которую у Луиза уже имела). Таким образом, вероятный ответ все еще Наоми.
Таким образом отвечает: Наоми.
Но нам нужно проверить: мог ли кто-то иметь больше трех? Маловероятно.
Таким образом, ответ на вопрос 6: Наоми.
Вместо этого, для этого вопроса, хотя он и предоставил верный ответ, он также предложил несвязанный ответ.
пропустить и продолжить.
Это неудовлетворительно.
Учитывая, что это нереалистично, возможно, ответ и не предполагается.
Таким образом, я бы ответил, что это слишком долго.
Но я должен предоставить всё. Но я застрял.
Учитывая время, я предоставлю частичный ответ и сообщу, что не могу решить все.
Давай сделаем это.
Вместо предоставления точных ответов, казалось, он выдавал бессмысленные ответы. Я подозреваю, что на это есть причина, и я рассмотрю ее подробнее ниже.
Интересное продолжение тестирования
Чтобы уточнить, я не рассчитывал всегда получать идеально точные ответы. Честно говоря, у меня вообще не было никаких ожиданий. Однако, я почерпнул несколько новых знаний по ходу дела.
Во-первых, я считаю, что мои первоначальные настройки, возможно, не были оптимальными. Однако, после повторного тестирования, я увеличил длину контекста в Ollama до 32k в качестве потенциального решения для многочисленных сбоев.
В этом недавнем случае потребовалось почти весь выделенный час, чтобы завершить процесс размышления. Стоит отметить, что она продемонстрировала значительные успехи, правильно ответив на 11 из 12 вопросов в первой партии. По мере развития сессии она показала еще больше перспектив в вопросах с числовыми последовательностями, где предыдущая попытка была менее успешной.
Как преданный пользователь, я столкнулся с неожиданной проблемой в этот раз. Вместо предоставления содержательных ответов на вопросы, на которые он, казалось, правильно отвечал в прошлом, ответы снова стали бессмысленными.
Вместо этого был разработан опросник, похожий на исходный тест. Хотя логический процесс продемонстрировал некоторый прогресс, заняв почти час, окончательный ответ полностью не соответствовал первоначальной инструкции.
По сути, для обширных документов, таких как эта, запоминание важных моментов имеет жизненно важное значение. Тем не менее, чрезмерная зависимость от памяти может привести к проблемам с производительностью. Фактически, основная причина продленного времени, проведенного в течение этого раунда, была из -за сильной зависимости от процессора и системной памяти для многочисленных операций.
Для таких больших документов, как этот, необходимо запоминание важных деталей. Но чрезмерная зависимость от памяти может вызвать проблемы с производительностью. На этот раз это заняло больше времени, потому что значительное количество операций было делегировано в моем процессоре и системной памяти.
На моей системе увеличение длины контекста до 128 тысяч не приводит к переносу какой-либо части модели на VRAM моей RTX 5080; вместо этого, все операции выполняются на процессоре и системной памяти, что значительно замедляет работу. Эта проблема сохраняется даже при использовании простых запросов. Поскольку скорость оценки возрастает с 9 токенов в секунду при 128 тысячах до 42 токенов в секунду при длине контекста 8 тысяч, и далее увеличивается до 82 токенов в секунду при 4 тысячах, это указывает на то, что производительность модели сильно зависит от сокращения длины контекста.
Веселье с некоторыми извлеченными уроками

Как исследователь, я приступил к изучению возможности эффективной интерпретации PDF-файлов моделью GPT-oss:20b. К моему удовлетворению, кажется, задача была успешно выполнена. Модель обработала предоставленный файл, прочитала его и попыталась выполнить запрошенные действия с документом.
Первоначально исполнение казалось ограниченным своим масштабом, не хватало необходимой памяти для выполнения задуманного. Однако последующая попытка, хотя и занявшая много времени, оказалась более успешной.
Я не повторял тест, используя максимальную длину контекста в 128 тысяч токенов, которую поддерживает Ollama в своем приложении, по двум причинам: во-первых, у меня сейчас нет свободного времени, а во-вторых, я не уверен, что мое текущее оборудование сможет эффективно с этим справиться.
RTX 5080 с 16 ГБ видеопамяти недостаточно для этой конкретной модели. Хотя она и использовалась, процессор взял на себя часть нагрузки. По сравнению с другими доступными моделями GPT-oss, она относительно меньше, но всё ещё достаточно мощная для такого игрового компьютера.
На моей системе я запустил gpt-oss:20b с настройками по умолчанию, выполняя предоставленное тестирование. Интересно, что в процессе только 65% нагрузки обрабатывалось графическим процессором, а центральный процессор — оставшиеся 35%. При более детальном рассмотрении выяснилось, что при максимальной длине контекста, похоже, ни одна часть модели не загружается на графический процессор.
Но я впечатлен его способностями к рассуждению.
Эта модель имеет тенденцию работать в довольно неторопливом темпе, учитывая, что я принял во внимание возможности моего оборудования. Похоже, модель тщательно рассматривает каждый запрос, о чем свидетельствует 18-секундная задержка перед ответом на вопрос о дате ее знаний. Она тщательно анализирует различные потенциальные объяснения и причины для формирования выбранного ответа.
Конечно, у этого варианта есть свои преимущества, но если вы ищете модель, которая быстро работает дома, возможно, стоит рассмотреть другие варианты. В данный момент, однако, Gemma3:12b — мой лучший выбор по производительности, учитывая имеющееся у меня оборудование.
Как наблюдатель, должен признать, что это был не полноценный тест в реальных условиях, а скорее сравнение между человеческим интеллектом и искусственным. К сожалению, эта модель искусственного интеллекта не превзошла [уровень], гарантируя, что мой десятилетний сын может продолжать спокойно чувствовать себя уверенным в своем превосходстве. Тем не менее, взаимодействие с этой и другими моделями, несомненно, расширило мою собственную базу знаний.
В таком случае у меня не было бы никаких причин для недовольства. Даже если бы эти занятия в итоге превратили мой офис в теплицу к вечеру.
Смотрите также
- Lenovo Legion Y70 (2026) ОБЗОР: скоростная зарядка, чёткое изображение, много памяти
- Лучшие смартфоны. Что купить в июне 2026.
- vivo iQOO 15T ОБЗОР: огромный накопитель, яркий экран, плавный интерфейс
- Motorola Moto G47 ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, большой аккумулятор
- Realme 16T ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, высокая автономность
- Honor Magic8 RSR Porsche Design ОБЗОР: замедленная съёмка видео, беспроводная зарядка, чёткое изображение
- Oppo K14 Turbo Pro ОБЗОР: скоростная зарядка, объёмный накопитель, большой аккумулятор
- Что купить фотографу. Рекомендации
- Honor Play 80 Pro ОБЗОР: плавный интерфейс, большой аккумулятор, удобный сенсор отпечатков
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
2025-08-16 17:49