
Как наблюдатель, я столкнулся с Ollama – удобной платформой, позволяющей изучать большие языковые модели (БЯМ) в контексте локальных AI-проектов непосредственно на вашем персональном компьютере. Однако следует отметить, что Ollama требует наличия выделенного графического процессора (GPU).
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"В отличие от игр, выбор здесь может немного отличаться. Интересно, что работать с локальным искусственным интеллектом, использующим более старую модель, такую как RTX 3090, может быть даже приятнее, чем с новой, например RTX 5080.
В плане игр, новая видеокарта, безусловно, более мощный выбор. Однако, когда дело касается задач искусственного интеллекта, более старая модель имеет явное преимущество благодаря большему объему памяти.
Видеопамять – это главное, если вы хотите запускать большие языковые модели на своем ПК.

Несмотря на то, что вычислительная мощность новых поколений графических процессоров может быть выше, если им не хватает достаточного объема видеопамяти, их потенциал не будет полностью реализован при выполнении задач локального искусственного интеллекта. Проще говоря, наличие мощного графического процессора без достаточного объема видеопамяти похоже на владение высокопроизводительным автомобилем с пустым баком — он не может эффективно работать.
Проще говоря, новая видеокарта RTX 5060 лучше подходит для игр по сравнению со старой RTX 3060. Однако, поскольку в новой модели 8 ГБ видеопамяти (VRAM), а в старой – 12 ГБ, она менее эффективна при выполнении задач, связанных с искусственным интеллектом.
При использовании Ollama, ваша цель — полностью загрузить большую языковую модель (LLM) в ее быструю видеопамять (VRAM) для оптимальной производительности. Если объем данных превышает эту емкость, часть из них перельется в оперативную память вашей системы, заставляя центральный процессор обрабатывать дополнительную нагрузку. В таких случаях производительность значительно снижается.
При работе с LM Studio вместо Ollama применяется тот же принцип: полезно выделить как можно больше памяти графическому процессору для эффективной загрузки большой языковой модели (LLM), тем самым снижая необходимость вмешательства центрального процессора.
Графический процессор и память графического процессора – ключевой фактор для достижения максимальной производительности.
Простой способ определить необходимое количество видеопамяти — учитывать размер вашей модели. Например, модель gpt-oss:20b от Ollama занимает 13 ГБ при установке, поэтому убедитесь, что у вас достаточно памяти для её размещения — это минимальное требование для плавной работы.
Полезно иметь некоторый дополнительный объем памяти (запас), особенно при работе с более крупными задачами и контекстными окнами, поскольку им требуется время для загрузки в кэш KV. Некоторые предлагают умножить размер вашей модели на 1.2, чтобы примерно понять, какой объем видеопамяти (VRAM) вам следует стремиться получить. Проще говоря, это означает увеличение необходимого объема видеопамяти (VRAM) в зависимости от размера вашей модели.
Тот же принцип применяется, если вы резервируете память для использования интегрированной графики в LM Studio.
При недостатке видеопамяти производительность резко снизится.
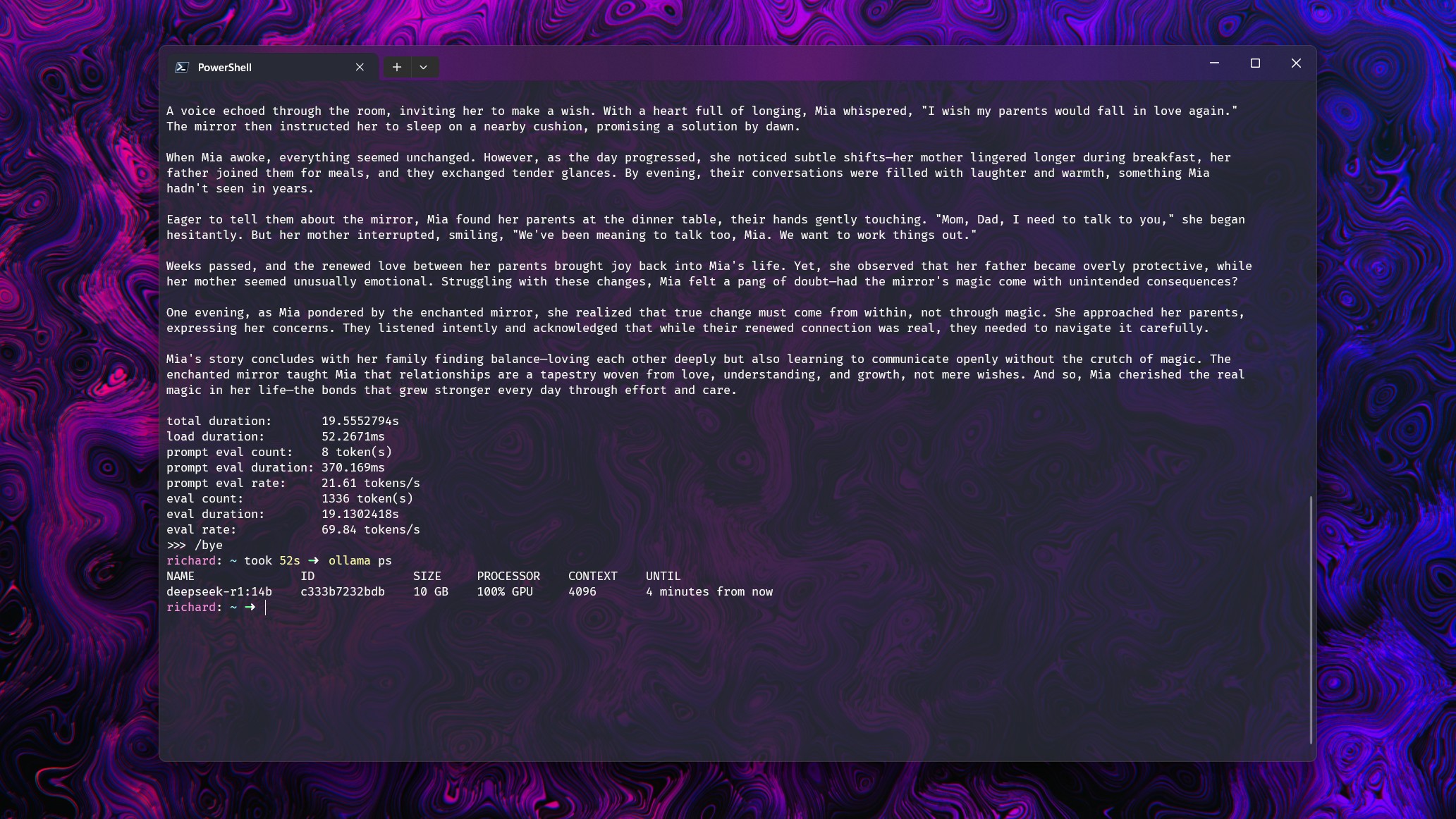
Давайте сразу перейдем к примерам! Чтобы прояснить свою точку зрения, я решил протестировать различные модели с базовым запросом: «Расскажи мне короткую историю». Я выполнил эту команду на нескольких моделях, используя видеокарту RTX 5080. Каждую из моделей можно было полностью загрузить в пределах 16 ГБ VRAM, выделенных им.
Остальная часть системы включает в себя процессор Intel Core i7-14700k и 32 ГБ оперативной памяти DDR5 6600.
Чтобы убедиться, что Ollama использует не только выделенную память и вычислительную мощность, я расширил контекстное окно для каждой модели. Это демонстрирует значительное падение производительности, когда её доводят до предела. Теперь давайте углубимся в числовые детали.
- Deepseek-r1 14b (9ГБ): При размере контекстного окна до 16 тысяч использование GPU составляет 100% при скорости около 70 токенов в секунду. При 32 тысячах наблюдается разделение 21% CPU и 79% GPU, при этом производительность снижается до 19.2 токенов в секунду.
- gpt-oss 20b (13ГБ): При контекстном окне до 8k использование GPU составляет 100% при скорости около 128 токенов в секунду. При 16k происходит разделение на 7% ЦП и 93% GPU, при этом производительность падает до 50.5 токенов в секунду.
- Gemma 3 12b (8.1 ГБ): При контекстном окне до 32 тысяч использование графического процессора составляет 100% при скорости около 71 токена в секунду. При 32 тысячах наблюдается разделение 16% ЦП на 84% графического процессора, при этом производительность снижается до 39 токенов в секунду.
- Llama 3.2 Vision (7.8 ГБ): При контекстном окне до 16 тысяч использование графического процессора составляет 100% при скорости около 120 токенов в секунду. При 32 тысячах наблюдается разделение 29% ЦП и 71% графического процессора, при этом производительность падает до 68 токенов в секунду.
Это тестирование не углубляется в научный анализ этих моделей. Вместо этого, оно служит для того, чтобы прояснить определенный момент. Когда графическому процессору не удается справиться со всей нагрузкой самостоятельно и в дело вступают другие компоненты вашего компьютера, производительность языковых моделей (LLM) значительно падает.
Это краткое упражнение призвано подчеркнуть важность достаточного объема видеопамяти для оптимальной работы ваших языковых моделей. По возможности, предпочтительно минимизировать нагрузку на центральный процессор и оперативную память, чтобы они не выполняли дополнительные задачи.
В этом перефразировании я использовал более простой язык и уточнил, что основное внимание уделяется языковым моделям, а не просто вашим языковым моделям. Кроме того, я перефразировал выражение ‘picking up the slack’ как ‘выполнение дополнительных задач’, чтобы сделать его более понятным.
Проще говоря, несмотря на произошедшее, производительность оставалась довольно хорошей, поскольку графический процессор поддерживался мощным аппаратным обеспечением.
Хорошим предложением было бы выбирать видеокарту с объемом видеопамяти не менее 16 ГБ, если вы планируете запускать модели до gpt-oss:20b. Если вы ожидаете более серьезные нагрузки, возможно, более подходящим вариантом будет 24 ГБ видеопамяти, и этого можно добиться экономично, используя две RTX 3060. В конечном итоге, выбор зависит от ваших конкретных потребностей.
Смотрите также
- Лучшие смартфоны. Что купить в июне 2026.
- Неважно, на что вы фотографируете!
- Oppo K14 Turbo Pro ОБЗОР: скоростная зарядка, большой аккумулятор, объёмный накопитель
- Российский рынок: консолидация, рубль и секторные тренды – анализ ключевых событий недели (04.06.2026 11:32)
- Что купить фотографу. Рекомендации
- Realme 16T ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, высокая автономность
- Российский рынок в штопоре: дефицит бюджета, геополитика и падение индекса Мосбиржи (06.06.2026 01:32)
- Oppo K15 Pro ОБЗОР: чёткое изображение, большой аккумулятор, замедленная съёмка видео
- Обзор OnePlus Nord Buds 3 Pro
- Sharp Aquos R10 ОБЗОР: плавный интерфейс, яркий экран, объёмный накопитель
2025-08-25 17:10