Автор: Денис Аветисян
Исследователи представляют CANVAS — комплексный тест, оценивающий способность моделей компьютерного зрения и обработки языка создавать пользовательские интерфейсы с использованием инструментов.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"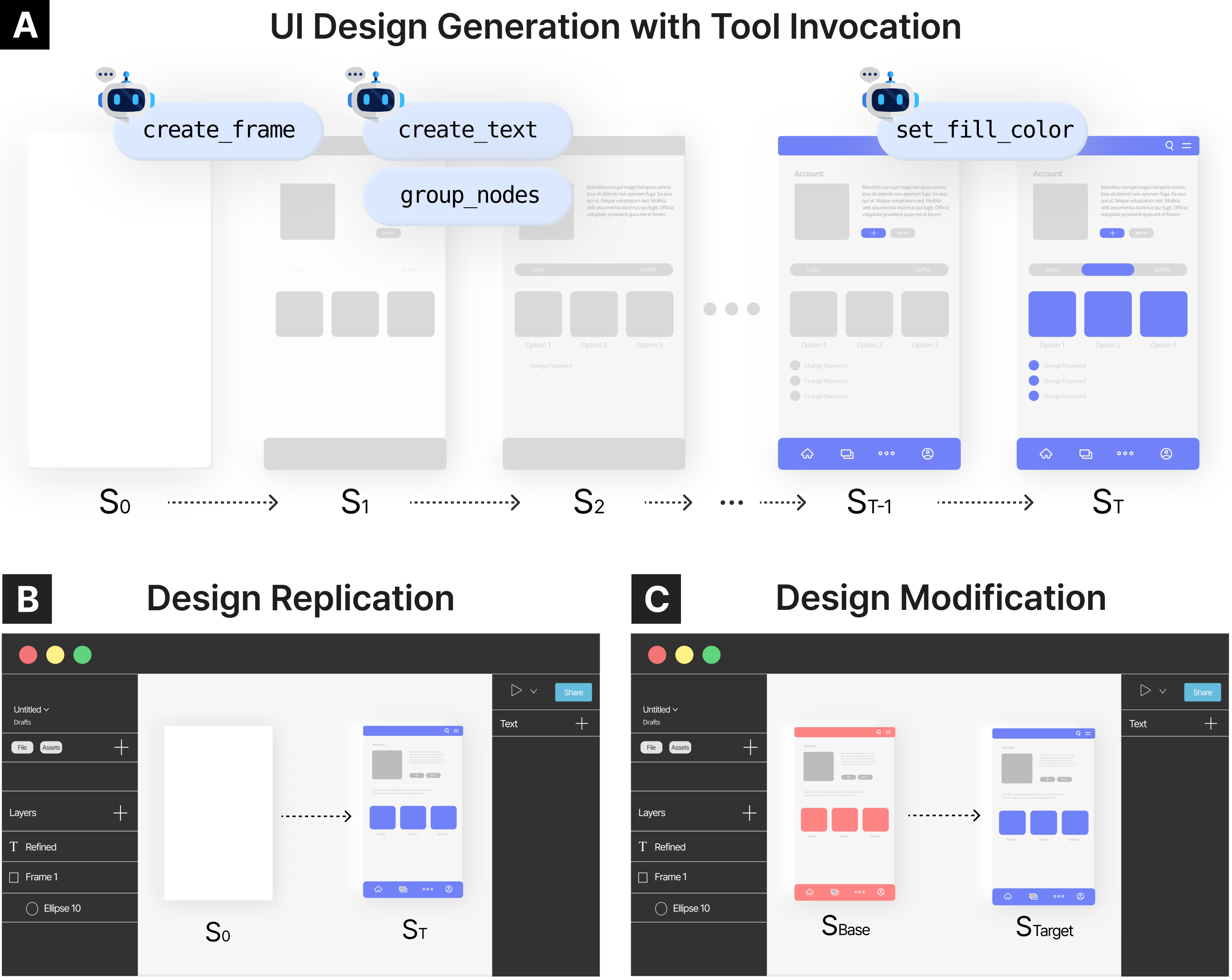
CANVAS — это новый эталон для оценки возможностей моделей в автоматизации дизайна пользовательских интерфейсов, включая последовательное взаимодействие с инструментами и точный выбор операций.
Несмотря на прогресс в области мультимодальных моделей, оценка их способности к итеративному проектированию пользовательских интерфейсов с использованием специализированных инструментов остаётся сложной задачей. В данной работе представлена новая методика оценки, ‘CANVAS: A Benchmark for Vision-Language Models on Tool-Based User Interface Design’, включающая набор из 598 задач по редактированию мобильных UI, направленных на проверку возможностей моделей в репликации и модификации дизайнов. Результаты демонстрируют, что современные модели проявляют стратегический подход к выбору инструментов, однако всё ещё сталкиваются с трудностями при выполнении сложных операций и точной настройке элементов интерфейса. Какие новые архитектуры и методы обучения позволят преодолеть эти ограничения и приблизить мультимодальные модели к полноценному сотрудничеству с дизайнерами?
Эволюция Визуального Понимания в Искусственном Интеллекте
Традиционные модели искусственного интеллекта испытывают значительные трудности при решении сложных задач, требующих последовательного использования различных инструментов, что особенно заметно при разработке пользовательских интерфейсов. В отличие от человеческой способности логически комбинировать действия, например, сначала выбрать инструмент рисования, а затем применить его к определенному элементу дизайна, большинство существующих систем не способны к подобному планированию и выполнению последовательности операций. Эта неспособность связана с тем, что они часто разрабатываются для выполнения конкретных, изолированных задач, а не для адаптации к меняющимся условиям и координации действий, необходимых для достижения более сложной цели. В результате, даже относительно простые задачи, такие как изменение цвета кнопки или перемещение элемента дизайна, могут оказаться непосильными для этих систем, подчеркивая потребность в новых подходах к созданию более гибких и адаптивных моделей искусственного интеллекта.
В связи с растущей потребностью в искусственном интеллекте, способном решать сложные задачи, такие как проектирование пользовательских интерфейсов, активно ведутся исследования в области Визуально-Языковых Моделей (ВЯМ). Эти модели, обладающие способностью воспринимать визуальную информацию и взаимодействовать с ней посредством языка, представляют собой перспективное направление развития. Исследователи стремятся создать ВЯМ, способные не только понимать визуальные инструкции, но и эффективно работать с программным обеспечением для дизайна, манипулируя элементами интерфейса и создавая новые проекты. Акцент делается на разработке моделей, способных к последовательному использованию инструментов, что позволяет им решать задачи, требующие многоэтапных действий и логического планирования. Такой подход открывает возможности для автоматизации процессов проектирования и создания более интуитивно понятных и удобных пользовательских интерфейсов.
Для адекватной оценки возможностей искусственного интеллекта в области визуального взаимодействия с программным обеспечением необходимы надежные критерии и тестовые среды. Исследователи подчеркивают, что недостаточно просто проверить способность модели воспроизвести существующий дизайн; ключевым является умение вносить в него осознанные изменения и улучшения. Разрабатываемые бенчмарки должны включать в себя задачи, требующие не только точного копирования, но и креативного применения инструментов, а также оценки качества и логичности внесенных изменений. Такой подход позволит установить, насколько эффективно модель понимает визуальные инструкции и способна решать сложные дизайнерские задачи, приближая искусственный интеллект к уровню человеческого творческого мышления.

CANVAS: Стандартизированная Платформа для Оценки Дизайнерских Возможностей ИИ
Бенчмарк CANVAS представляет собой стандартизированную платформу для оценки производительности визуально-языковых моделей (VLM) в задачах, связанных с проектированием пользовательских интерфейсов. Он включает в себя два основных типа задач: Воспроизведение дизайна, требующее от модели точного воссоздания существующего UI, и Модификация дизайна, где модель должна вносить изменения в заданный UI в соответствии с инструкциями. Такая структура позволяет комплексно оценить способности моделей к пониманию визуальной информации и ее преобразованию в соответствии с заданными требованиями, охватывая как базовое копирование, так и более сложные сценарии редактирования и адаптации UI.
Платформа CANVAS использует возможности Figma, широко распространенного программного обеспечения для проектирования пользовательских интерфейсов, предоставляя моделям возможность непосредственного взаимодействия с профессиональной средой разработки. Это позволяет оценивать не только функциональность генерируемого дизайна, но и его соответствие индустриальным стандартам и практикам, принятым в Figma. Взаимодействие с Figma осуществляется через API, что обеспечивает модели полный контроль над элементами дизайна, включая их создание, изменение и позиционирование. Использование профессионального инструмента, такого как Figma, существенно повышает реалистичность и практическую ценность оценки производительности моделей, ориентированных на автоматизацию задач UI-дизайна.
Оценка результатов работы моделей в рамках CANVAS требует применения как количественных метрик, так и качественной оценки с использованием данных предпочтений людей. Количественная оценка включает в себя использование структурного сходства (SSIM), которое измеряет перцептивное сходство между сгенерированным и целевым дизайном. Также применяется оценка схожести подписей, генерируемых моделью BLIP, и компонентное сходство, оценивающее соответствие отдельных элементов дизайна. Качественная оценка предполагает сбор данных о предпочтениях людей для более точной оценки визуального качества и соответствия дизайна заданным требованиям.

Результаты Оценок и Архитектурные Инсайты
Недавние оценки с использованием платформы CANVAS включали в себя модели GPT-4o, Gemini-2.5-Pro и Claude-3.5-Sonnet, что позволило продемонстрировать широкий спектр их возможностей. Эти модели были протестированы в различных задачах, охватывающих обработку естественного языка, визуальное понимание и взаимодействие с инструментами. Результаты оценок позволили выявить сильные и слабые стороны каждой модели, а также оценить их потенциал для решения сложных задач автоматизации пользовательского интерфейса и других приложений. Разнообразие представленных моделей подчеркивает активное развитие области больших языковых моделей и растущую конкуренцию между разработчиками.
Успешные модели, демонстрирующие высокие результаты в задачах взаимодействия с пользовательским интерфейсом, используют архитектуры, такие как ReAct и Model Context Protocol (MCP). ReAct позволяет модели чередовать рассуждения (Reasoning) и действия (Acting), что способствует более целенаправленному и эффективному выполнению задач. MCP, в свою очередь, стандартизирует обмен информацией между моделью и инструментами, обеспечивая корректное формирование запросов и интерпретацию ответов. Такая организация позволяет моделям не только выполнять конкретные действия, но и анализировать результаты, корректировать стратегию и эффективно использовать доступные инструменты для достижения поставленной цели.
Анализ производительности моделей показал, что владение базовыми геометрическими операциями является критически важным для успешной манипуляции пользовательским интерфейсом. При этом, предотвращение переполнения текста ($Text Overflow$) необходимо для обеспечения удобства использования. Оценка моделей проводится с использованием метрики Pos@4, и построенная на основе данных логистическая регрессия демонстрирует точность в 75% при прогнозировании предпочтений пользователей.

Взгляд в Будущее: За Пределами Оценки, К Эре ИИ-Дизайна
Визуальные языковые модели (VLM) демонстрируют растущую способность к выполнению сложных задач, связанных с проектированием пользовательских интерфейсов, что открывает перспективы для автоматизации целых дизайнерских процессов. Исследования показывают, что эти модели способны не только генерировать макеты, но и адаптировать их на основе заданных параметров и требований к функциональности. Это позволяет значительно ускорить и удешевить разработку новых приложений и веб-сайтов, а также высвободить творческий потенциал дизайнеров для решения более сложных и концептуальных задач. Автоматизация рутинных операций, таких как размещение элементов, подбор цветовых схем и адаптация к различным разрешениям экранов, позволяет дизайнерам сосредоточиться на инновациях и создании уникального пользовательского опыта. В перспективе, VLM могут стать незаменимым инструментом для быстрого прототипирования и тестирования различных дизайнерских решений, способствуя тем самым ускорению инноваций в сфере цифровых технологий.
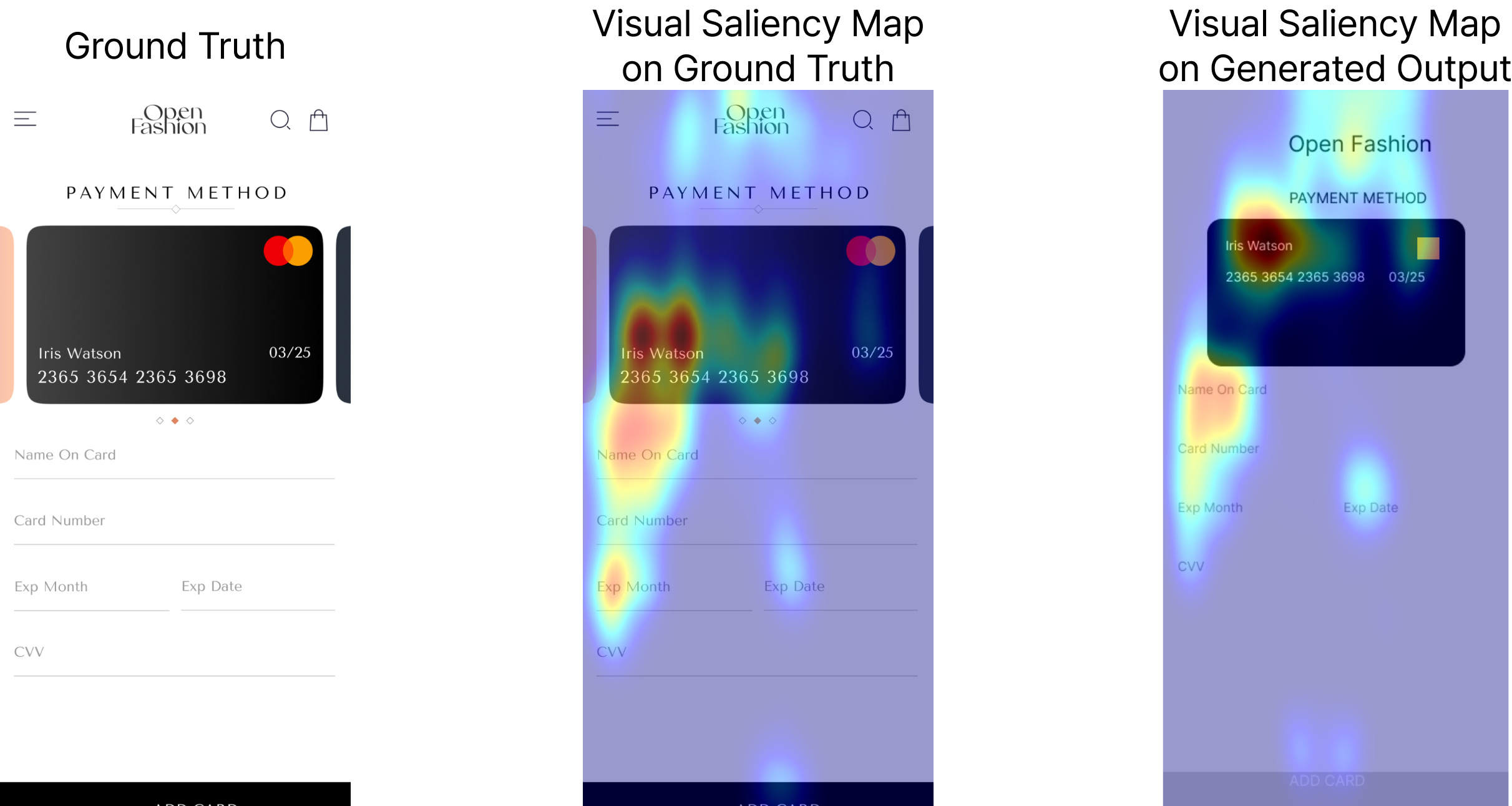
Анализ карт заметности позволяет существенно улучшить понимание визуальных паттернов моделями искусственного интеллекта, что напрямую влияет на создание более эстетичных и удобных для пользователя интерфейсов. Эти карты, визуализирующие области изображения, привлекающие наибольшее внимание, помогают разработчикам выявлять слабые места в логике восприятия модели. Определяя, какие элементы интерфейса модель считает наиболее важными, можно скорректировать её обучение, добиваясь соответствия между машинным «зрением» и человеческим восприятием красоты и удобства. Такой подход позволяет не просто генерировать визуально приемлемые дизайны, но и оптимизировать их с точки зрения юзабилити, делая взаимодействие с интерфейсом более интуитивным и эффективным.
Дальнейшее развитие интеллектуальных агентов для дизайна напрямую связано с использованием специализированных бенчмарков, таких как CANVAS. Исследования показали, что точность используемых инструментов ($ρ=0.149, p<0.01$) и разнообразие этих инструментов ($ρ=-0.365, p<0.01$) оказывают существенное влияние на эффективность модели, измеряемую показателем Pos@K. Это указывает на необходимость сбалансированного подхода к разработке, когда агенты способны не только аккуратно выполнять задачи, но и использовать широкий спектр инструментов для создания инновационных и креативных дизайнерских решений, расширяя возможности человеческого творчества и сотрудничества.
Исследование, представленное в данной работе, демонстрирует, что современные модели, работающие с визуальными данными и языком, способны к воспроизведению базовых операций в области дизайна пользовательских интерфейсов. Однако, как показывает CANVAS, их возможности ограничены, когда требуется точный выбор инструмента и выполнение сложных манипуляций. В этой связи, уместно вспомнить слова Дэвида Марра: «Понимание — это не просто накопление фактов, а умение строить полезные представления». Данный принцип напрямую применим к разработке моделей для автоматизации дизайна: недостаточно просто распознавать элементы интерфейса, необходимо понимать их функциональное назначение и взаимосвязь, чтобы эффективно использовать инструменты и создавать целостные, гармоничные проекты. Необходимость в развитии именно этого аспекта подчеркивает важность CANVAS как эталона для оценки и улучшения подобных систем.
Куда же дальше?
Представленный набор данных CANVAS, несомненно, обнажает определенную дисгармонию в текущем поколении моделей «зрение-язык». Способность к имитации, к воспроизведению уже существующего, оказалась неожиданно развита. Однако, за этой внешней ловкостью скрывается фундаментальная проблема: истинное понимание инструмента, его предназначения и точного применения, всё еще ускользает. Модели, подобно искусным подражателям, могут скопировать манеру, но не суть.
Будущие исследования неизбежно должны сосредоточиться на преодолении этого разрыва. Необходимо отойти от простой генерации пикселей и перейти к моделированию намерения. Инструмент должен быть понятен не как последовательность команд, а как средство достижения определенной цели в контексте дизайна. Иначе говоря, элегантность дизайна — это не просто визуальное впечатление, но отражение глубокого понимания задачи.
Появляется необходимость в разработке метрик, способных оценивать не только визуальное сходство, но и функциональную корректность, эффективность и даже эстетическую ценность создаваемого интерфейса. Пока же, кажется, мы наблюдаем лишь изящное, но поверхностное воспроизведение, а не подлинное творчество. И это, пожалуй, самый интересный момент для дальнейшего исследования.
Оригинал статьи: https://arxiv.org/pdf/2511.20737.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Лучшие смартфоны. Что купить в июне 2026.
- Lenovo Legion Y70 (2026) ОБЗОР: скоростная зарядка, чёткое изображение, много памяти
- Фотографируем муравьёв с Андреем Павловым
- Обзор объектива Tokina 11-16mm f/2.8 AF
- Что купить фотографу. Рекомендации
- Honor Play 80 Pro ОБЗОР: плавный интерфейс, большой аккумулятор, удобный сенсор отпечатков
- Blackview Oscal Tiger 12 ОБЗОР: большой аккумулятор, плавный интерфейс, быстрый сенсор отпечатков
- Неважно, на что вы фотографируете!
- Motorola Moto G47 ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, большой аккумулятор
- Honor 600 ОБЗОР: лёгкий, плавный интерфейс, скоростная зарядка
2025-11-28 05:49