Автор: Денис Аветисян
Исследователи представили GaINeR — инновационный подход к представлению 3D-объектов, сочетающий в себе непрерывные функции и обучаемые гауссовские вложения для достижения фотореалистичной реконструкции и редактирования.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
GaINeR — это новое неявное нейронное представление, объединяющее геометрию и непрерывные функции для высокоточной 3D-реконструкции, редактирования и интеграции с симуляциями физики.
Несмотря на успехи неявных нейронных представлений в моделировании изображений, традиционные архитектуры часто уступают в гибкости и интеграции с физическими симуляциями. В данной работе представлена новая методика — GaINeR: Geometry-Aware Implicit Network Representation, объединяющая обучаемые гауссовские распределения с нейронной сетью для создания неявного представления изображений. Предложенный подход позволяет добиться высокоточной реконструкции, редактируемой геометрии и бесшовной интеграции с физическими моделями, обеспечивая непрерывное представление изображения. Открывает ли это путь к новым интерактивным приложениям и реалистичным визуальным эффектам, основанным на физически корректных симуляциях?
Преодолевая Границы Пикселей: Новый Взгляд на Представление Изображений
Традиционные методы представления изображений, основанные на пиксельных сетках, сталкиваются с существенными ограничениями при изменении разрешения. При увеличении масштаба изображение быстро теряет четкость, превращаясь в размытое полотно, а при уменьшении — детали попросту исчезают. Более того, редактирование пиксельных изображений зачастую требует трудоемкой работы с каждым отдельным пикселем, что делает процесс сложным и неэффективным. Каждое изменение требует пересчета и перерисовки, что особенно проблематично для сложных изображений или анимаций. По сути, пиксельная сетка представляет собой дискретную выборку непрерывного сигнала, что неизбежно приводит к потере информации и ограничениям в гибкости редактирования. Данные ограничения стимулируют поиск альтернативных методов представления изображений, способных преодолеть эти недостатки и обеспечить более высокое качество, компактность и удобство редактирования.
Вместо традиционного представления изображений в виде дискретной сетки пикселей, неявные нейронные представления (ННП) предлагают принципиально иной подход, определяя изображение как непрерывную функцию. Это позволяет преодолеть ограничения, связанные с разрешением и масштабируемостью, поскольку изображение может быть реконструировано в любом желаемом разрешении без потери качества. Фактически, ННП кодируют изображение в виде параметров нейронной сети, что обеспечивает значительно более компактное хранение данных по сравнению с традиционными форматами. Представьте, что вместо хранения каждого пикселя, сохраняется лишь набор весов, определяющих значение цвета в любой точке изображения. Такая функциональная параметризация открывает новые возможности для редактирования и манипулирования изображениями, позволяя плавно изменять детали и создавать реалистичные визуальные эффекты с беспрецедентной точностью и эффективностью. Вместо фиксированной сетки, изображение становится математической функцией $f(x, y)$, описывающей цвет в каждой точке пространства.
Несмотря на многообещающие результаты, первоначальные реализации неявных нейронных представлений (INR), такие как SIREN и WIRE, сталкивались с трудностями при моделировании сложных геометрических форм и динамических сцен. Эти методы, хотя и позволяли создавать изображения с высоким разрешением из компактных представлений, часто демонстрировали ограниченную способность к точному воспроизведению тонких деталей, особенно в областях с высокой кривизной или быстрыми изменениями. Проблемы возникали из-за сложностей в обучении нейронных сетей, представляющих сложные функции, и необходимости обеспечения достаточной гибкости для захвата всех нюансов изображений. Ограничения в представлении динамики проявлялись в трудностях с последовательным отображением изменений во времени, что затрудняло их применение в задачах, требующих реалистичной анимации или отслеживания движений.
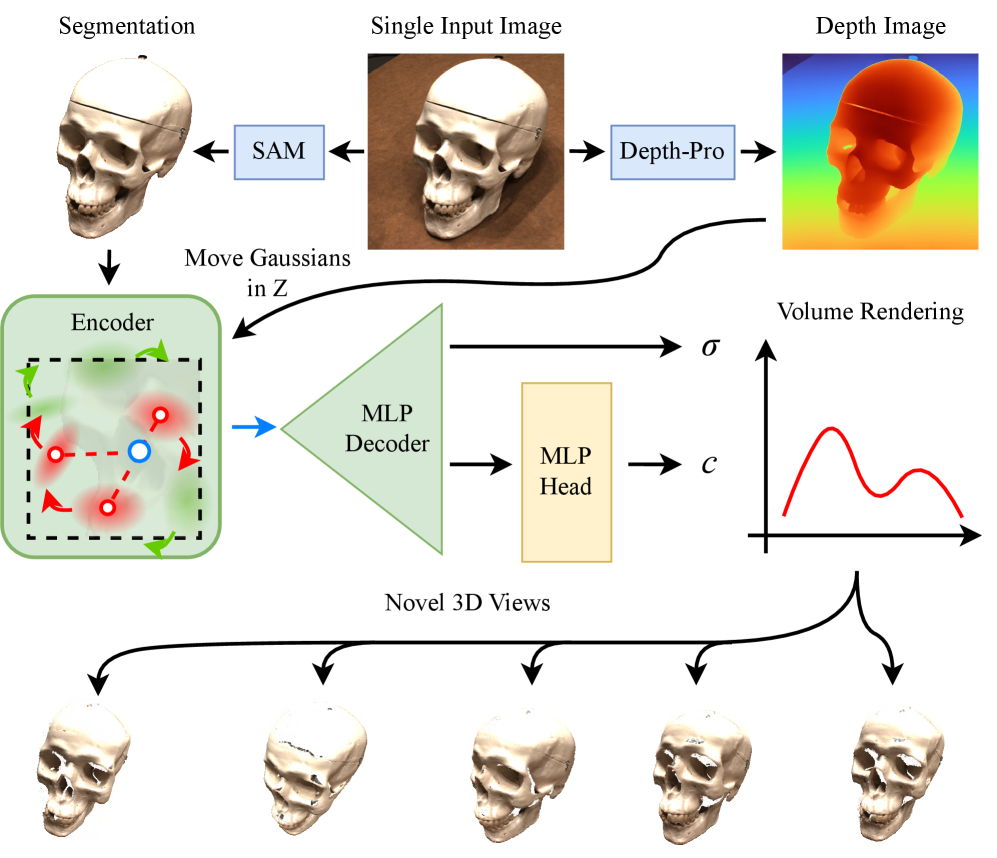
GaINeR: Гауссовские Вложения для Улучшенной Геометрии
GaINeR представляет собой новый подход к представлению 3D-сцен, объединяющий нейронные сети неявного представления (INRs) с обучаемыми гауссовыми вложениями. В отличие от традиционных методов, использующих фиксированные признаки, GaINeR позволяет кодировать локальные признаки в виде гауссовых распределений, параметры которых оптимизируются в процессе обучения. Это обеспечивает более детальное и точное представление геометрии сцены, особенно в областях с высокой сложностью или изменениями. Использование гауссовых вложений позволяет сети эффективно захватывать и использовать пространственный контекст, что приводит к улучшению качества реконструкции и визуализации.
Метод GaINeR использует свойства гауссовских распределений для кодирования пространственного контекста, что позволяет добиться детальной и точной реконструкции изображений. В основе лежит представление каждой точки пространства как взвешенной суммы гауссиан, где веса определяются обучаемыми параметрами. Использование гауссовских функций обеспечивает плавную интерполяцию между точками дискретизации, что снижает артефакты и улучшает качество результирующего изображения. Ширина гауссианы, определяемая параметрами модели, позволяет контролировать степень влияния каждой точки на окружающее пространство, эффективно моделируя локальные детали и общую структуру сцены. Применение гауссовских распределений позволяет эффективно захватывать и кодировать информацию о геометрии и внешнем виде объекта, обеспечивая высокую точность реконструкции даже при ограниченном количестве входных данных.
Эффективность GaINeR во многом обусловлена использованием структуры данных `Hashgrid` для быстрого извлечения многомасштабных гауссовских признаков. `Hashgrid` представляет собой пространственно-индексированную таблицу хэшей, позволяющую осуществлять быстрый доступ к гауссовским признакам на разных уровнях детализации. Это достигается путем разбиения пространства на воксели и хэширования координат каждого вокселя в индекс таблицы. В процессе обучения и реконструкции, для получения признаков в заданной точке, выполняется поиск ближайших вокселей в `Hashgrid` и интерполяция соответствующих гауссовских значений. Такой подход значительно снижает вычислительные затраты по сравнению с полным перебором признаков, обеспечивая высокую скорость работы GaINeR даже при работе с высокодетализированными сценами.
Декодирование и Валидация: От Вложений к Симуляции
В GaINeR для преобразования агрегированных гауссовских эмбеддингов в значения цвета используется многослойный перцептрон (MLP). Этот подход позволяет получить высококачественную визуализацию, поскольку MLP эффективно отображает многомерное пространство эмбеддингов в цветовое пространство изображения. Архитектура MLP оптимизирована для регрессии, что обеспечивает точное предсказание значений RGB для каждого пикселя. Использование MLP в качестве декодера позволяет GaINeR эффективно восстанавливать детали и текстуры изображения, обеспечивая реалистичное и качественное рендеринг.
Для эффективной агрегации признаков в GaINeR используется алгоритм поиска ближайших соседей (KNN Search). В процессе реконструкции изображения, для каждой точки выходного изображения выполняется поиск $k$ ближайших центров гауссовых распределений в пространстве признаков. Идентифицированные центры и соответствующие им веса используются для вычисления значения цвета в этой точке. Такой подход позволяет точно восстановить детали изображения, поскольку агрегация признаков основана на наиболее релевантных гауссовых представлениях, что способствует высокой точности реконструкции.
Функциональные возможности GaINeR были тщательно проверены с использованием метода материальных точек (Material Point Method, MPM), что подтверждает применимость системы для физически корректных симуляций. MPM является вычислительно эффективным методом, позволяющим моделировать поведение деформируемых тел и жидкостей. Использование MPM в процессе валидации позволило оценить способность GaINeR адекватно воспроизводить динамическое поведение сложных сцен, обеспечивая стабильность и точность результатов симуляции. Результаты тестирования с использованием MPM демонстрируют, что восстановленные изображения, полученные с помощью GaINeR, соответствуют физическим принципам, что делает систему подходящей для приложений, требующих реалистичной визуализации динамических процессов, таких как моделирование тканей, жидкостей и других деформируемых материалов.
Результаты тестирования показали значительное улучшение качества реконструкции изображений при использовании GaINeR. На стандартном наборе данных Kodak, показатель PSNR увеличился с 59.52 до 77.09. Аналогичные улучшения были достигнуты и на более сложном наборе данных DIV2K, где PSNR возрос с 54.54 до 62.20. Данные показатели демонстрируют существенный прогресс в точности восстановления изображений по сравнению с существующими методами.
В процессе обучения GaINeR используется функция потерь Smooth L1, представляющая собой гибрид между L1 и L2 потерями. В отличие от L2 потерь, которые склонны к переоценке больших ошибок, и L1 потерь, которые могут приводить к нестабильности градиентов вблизи нуля, Smooth L1 Loss обеспечивает более устойчивую регрессию. Это достигается путем использования квадратичной функции потерь для небольших ошибок и линейной функции для больших ошибок. Такой подход позволяет минимизировать ошибки реконструкции, эффективно обрабатывая как незначительные, так и существенные отклонения в процессе обучения модели и обеспечивая более точное восстановление изображения. Функция потерь определяется как $0.5 x^2$ если $|x| < 1$ и $0.5 (|x| — 1)$ в противном случае, где $x$ — разница между предсказанным и истинным значением пикселя.

Расширяя Горизонты: Применение и Будущие Направления
В отличие от традиционных изображений, основанных на дискретных пикселях, система GaINeR представляет картинки как непрерывные функции. Это принципиальное отличие позволяет добиться бесконечного масштабирования без потери качества и появления характерных для пиксельных изображений ступенчатых границ. Вместо фиксированного набора точек, GaINeR оперирует математическим описанием изображения, позволяя воссоздавать детали на любом уровне приближения. По сути, изображение становится бесконечно детализированным, так как его разрешение не ограничено фиксированным числом пикселей, а определяется точностью математического описания. Такой подход открывает новые возможности для визуализации данных, создания реалистичных виртуальных сред и обработки изображений с беспрецедентным уровнем детализации и плавности.
Архитектура GaINeR не ограничивается представлением двумерных изображений; её принципы успешно расширяются и на трёхмерные сцены. Это позволяет создавать детальные и реалистичные виртуальные окружения, а также осуществлять синтез новых видов изображения из произвольных точек обзора. По сути, GaINeR обеспечивает возможность “пролетать” сквозь сложную 3D-графику, получая плавные и высококачественные изображения, что открывает широкие перспективы для разработки иммерсивных приложений виртуальной реальности и интерактивных 3D-моделей. Возможность манипулирования трехмерными сценами на основе непрерывных функций, а не дискретных пикселей, обеспечивает беспрецедентный уровень детализации и плавности, необходимый для создания убедительных виртуальных миров.
Методы, развивающие концепции GaINeR, такие как MiRaGe, используют технику Gaussian splatting для достижения рендеринга в реальном времени и интеграции с физическими движками. В отличие от традиционных подходов, Gaussian splatting представляет сцены как набор трехмерных гауссиан, что позволяет эффективно отображать сложные детали с высокой скоростью. Это особенно важно для интерактивных приложений, таких как виртуальная реальность и симуляции, где требуется мгновенная реакция на действия пользователя. Интеграция с физическими движками позволяет создавать реалистичные взаимодействия объектов в виртуальном пространстве, например, моделировать деформацию материалов или столкновения тел, значительно повышая уровень погружения и достоверности симуляции.
Исследования в настоящее время направлены на интеграцию $Positional Encoding$ в архитектуру GaINeR с целью улучшения представления частот и повышения детализации сложных сцен. Данный метод кодирования позволяет более эффективно захватывать высокочастотные детали, которые критически важны для реалистичного отображения текстур и геометрии. Использование $Positional Encoding$ позволяет системе более точно моделировать сложные функции, описывающие изображение, что приводит к повышению общей точности и фотореалистичности результирующих изображений. Ожидается, что данное усовершенствование значительно расширит возможности GaINeR в задачах, требующих высокой детализации и реализма, таких как создание виртуальной реальности и компьютерной графики.

Исследование, представленное в данной работе, демонстрирует значительный прогресс в области неявных нейронных представлений, особенно в контексте геометрии и редактирования изображений. GaINeR, используя комбинацию непрерывных функций и обучаемых гауссовских вложений, позволяет достичь высокой точности реконструкции и гибкости в манипулировании геометрией объектов. Как однажды заметил Ян ЛеКюн: «Машинное обучение — это обучение представлений». Эта фраза прекрасно отражает суть подхода GaINeR — создание эффективного представления данных, которое позволяет не только точно воспроизводить изображения, но и интегрировать их в симуляции, открывая новые возможности для применения в различных областях, включая графику и физическое моделирование.
Куда Ведет Этот Путь?
Представленная работа, хотя и демонстрирует впечатляющую способность к воссозданию геометрии и интеграции с симуляциями, лишь приоткрывает завесу над истинной сложностью неявных представлений. Заманчиво видеть, как непрерывные функции и обучаемые гауссовы вложения позволяют манипулировать изображениями, однако необходимо признать, что текущие методы часто страдают от вычислительной дороговизны и чувствительности к выбору гиперпараметров. Вопрос не в том, чтобы просто воссоздать сцену, а в том, чтобы понять, как эффективно кодировать и декодировать информацию о форме и внешнем виде, избегая излишней детализации, которая лишь усложняет задачу.
Очевидным направлением для дальнейших исследований представляется разработка методов, позволяющих GaINeR и подобным системам адаптироваться к различным уровням детализации, сохраняя при этом вычислительную эффективность. Интересно исследовать возможности применения принципов разреженности и сжатия данных, чтобы уменьшить объем памяти, необходимый для хранения и обработки неявных представлений. Кроме того, необходимо уделить внимание вопросам обобщающей способности: насколько хорошо модель способна переносить знания, полученные на одном наборе данных, на другие, невидимые ранее сцены?
В конечном счете, успех таких подходов будет зависеть не только от улучшения технических характеристик, но и от развития более глубокого понимания взаимосвязи между геометрией, внешним видом и физическими свойствами объектов. Попытки просто «скопировать» реальность, без осмысления её фундаментальных принципов, обречены на провал. Истинный прогресс лежит в стремлении к пониманию системы, а не просто к её моделированию.
Оригинал статьи: https://arxiv.org/pdf/2511.20924.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- 10 лучших OLED ноутбуков. Что купить в июне 2026.
- Российский рынок: от инфляции к инвестициям: что ждет инвесторов? (11.06.2026 02:32)
- Как сделать фотографию резкой.
- Обзор Motorola Edge 50 Fusion
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Прогнозы цен на CC: анализ криптовалюты CC
- Режимы автофокуса. Как настроить автофокус.
- vivo S60 ОБЗОР: скоростная зарядка, объёмный накопитель, современный дизайн
2025-11-28 14:16