Автор: Денис Аветисян
Новая архитектура CRANE позволяет эффективно использовать информацию из разных источников для повышения точности и скорости рекомендаций.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"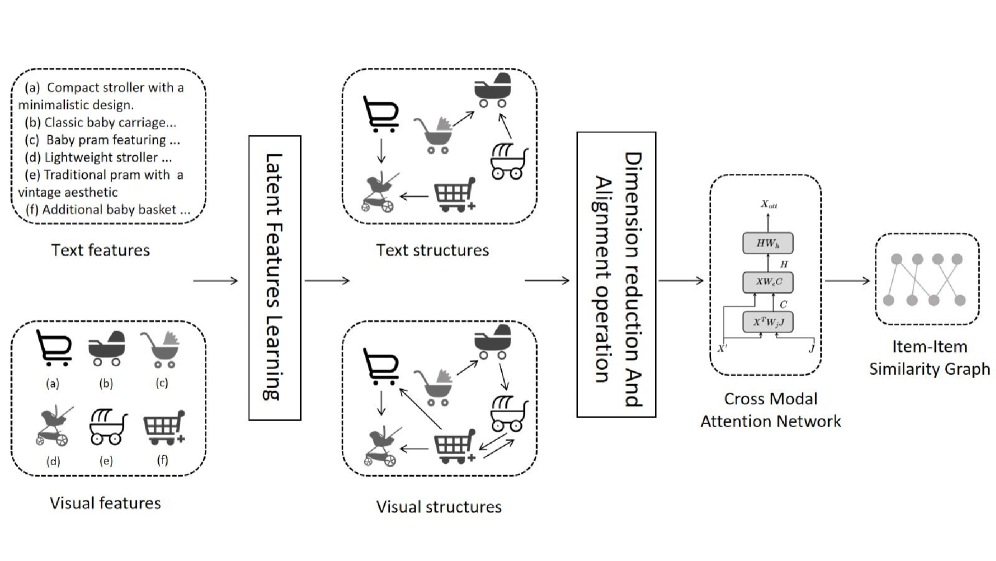
В статье представлена модель CRANE, использующая двойные графы и рекурсивный кросс-модальный механизм внимания для улучшения мультимодальных рекомендаций.
Несмотря на значительный прогресс в области рекомендательных систем, эффективное объединение разнородной мультимодальной информации и симметричное представление пользователей и объектов остается сложной задачей. В данной работе, посвященной ‘Cross-Modal Attention Network with Dual Graph Learning in Multimodal Recommendation’, предложена новая архитектура CRANE, использующая рекурсивный механизм кросс-модального внимания и двойную графовую структуру для более глубокого понимания взаимосвязей между пользователями и объектами. Предложенный подход позволяет не только повысить точность рекомендаций, но и добиться значительного улучшения вычислительной эффективности. Возможно ли дальнейшее расширение возможностей CRANE за счет интеграции дополнительных источников информации и более сложных моделей взаимодействия?
Пределы Традиционных Рекомендательных Систем
Традиционные методы коллаборативной фильтрации, такие как BPR (Bayesian Personalized Ranking), сталкиваются с существенными трудностями при работе с разреженными данными о взаимодействиях пользователей и предметов. Проблема возникает из-за того, что большинство пользователей взаимодействуют лишь с небольшой частью доступных предметов, создавая матрицу взаимодействий, заполненную преимущественно пустыми значениями. Это явление, известное как «разреженность», затрудняет выявление надежных закономерностей и прогнозирование предпочтений. Кроме того, эти методы испытывают трудности в ситуации «холодного старта», когда необходимо рекомендовать предметы новым пользователям или пользователям, для которых доступно крайне мало информации о предпочтениях, поскольку алгоритм не имеет достаточных данных для точного прогнозирования. В результате, качество рекомендаций значительно снижается при работе с разреженными данными и новыми пользователями, что требует разработки более эффективных подходов, способных преодолеть эти ограничения.
Традиционные методы рекомендаций, такие как коллаборативная фильтрация, зачастую упрощают взаимосвязи между товарами, рассматривая их как изолированные единицы. Это приводит к ограничению разнообразия предлагаемых рекомендаций и снижению их точности. Вместо учета сложных семантических связей, например, схожести по характеристикам, жанру или функциональности, алгоритмы склонны фокусироваться исключительно на истории взаимодействий пользователей с конкретными позициями. В результате, система может упустить потенциально интересные для пользователя товары, которые косвенно связаны с его предпочтениями, но не были явно оценены ранее. Неспособность уловить эти неявные связи существенно ограничивает возможности предоставления персонализированных и релевантных рекомендаций, приводя к однообразию и снижению пользовательской удовлетворенности.
Традиционные системы рекомендаций, основанные исключительно на явных взаимодействиях пользователя с предметами, зачастую упускают из виду ценную информацию, заключенную в характеристиках самих предметов и их семантических связях. Анализ только тех предметов, с которыми пользователь уже взаимодействовал, игнорирует потенциально релевантные предметы, обладающие схожими атрибутами или входящие в одну категорию. Например, если пользователь оценил несколько научно-фантастических романов, система, полагаясь лишь на историю взаимодействий, может не предложить ему книгу того же жанра, выпущенную недавно, или произведение, затрагивающее схожие темы, но написанное другим автором. В то время как учет внутренних свойств предметов и их взаимосвязей позволяет расширить горизонты рекомендаций, предлагая пользователю более разнообразный и релевантный контент, даже если прямого взаимодействия с ним ранее не было.
Графовые Нейронные Сети: Моделирование Взаимосвязей
Графовые нейронные сети (GCN) представляют собой мощный инструмент для кодирования данных, представленных в виде графов, таких как взаимодействия пользователей и элементов. В основе GCN лежит принцип распространения информации между узлами графа посредством операций свертки. Каждый узел агрегирует информацию от своих соседей, учитывая структуру связей, и использует эту агрегированную информацию для обновления своего собственного представления. Этот процесс позволяет моделировать зависимости между узлами и эффективно извлекать признаки из графовой структуры данных. В контексте систем рекомендаций, узлы могут представлять пользователей и элементы, а связи — взаимодействия между ними, например, покупки или оценки. G = (V, E), где V — множество вершин (узлов), а E — множество ребер (связей), является стандартным обозначением графа, используемого в GCN.
Методы, такие как LightGCN, оптимизируют графовые сверточные сети (GCN) для эффективной коллаборативной фильтрации, упрощая архитектуру и концентрируясь на ключевых графовых операциях. В отличие от стандартных GCN, LightGCN удаляет нелинейные активации и слои признаков, оставляя только умножение матрицы смежности и усреднение соседних узлов. Это позволяет значительно снизить вычислительную сложность и объем параметров, сохраняя при этом способность эффективно моделировать взаимодействия между пользователями и элементами. Основная операция в LightGCN — это последовательное применение матрицы смежности \tilde{A} для получения вложений пользователей и элементов, что позволяет моделировать их предпочтения на основе графа взаимодействий.
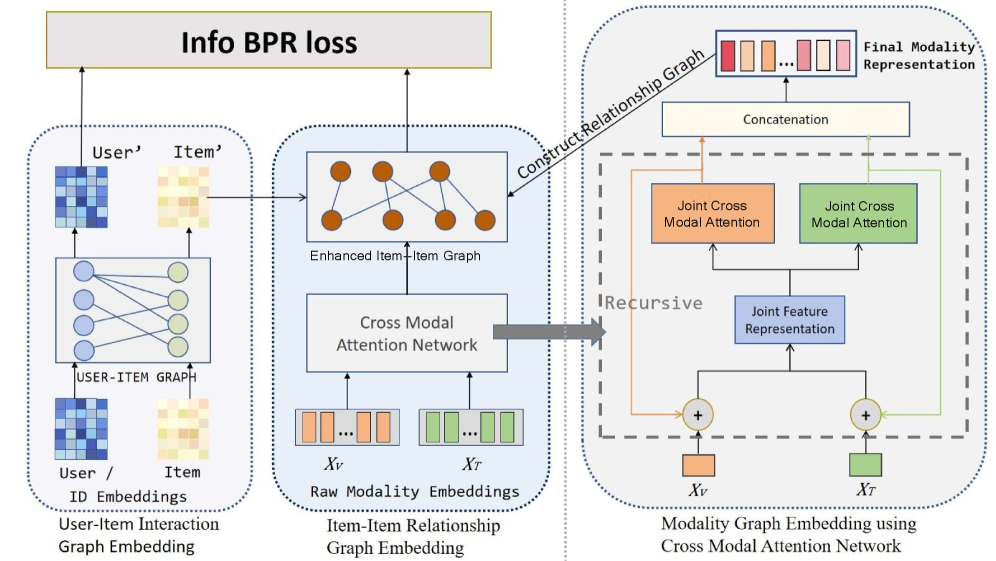
Метод FREEDOM оптимизирует графовые нейронные сети для задач коллаборативной фильтрации за счет двух ключевых стратегий. Во-первых, выполняется шумоподавление (denoising) графа взаимодействий пользователь-товар, что позволяет снизить влияние случайных или нерелевантных связей на процесс обучения. Во-вторых, граф взаимодействий между товарами (item-item graph) фиксируется (freezing) в процессе обучения, что повышает стабильность модели и снижает вычислительные затраты, поскольку параметры связей между товарами не обновляются. Данный подход позволяет добиться улучшения производительности и обобщающей способности модели, особенно в условиях разреженных данных.
Мультимодальное Слияние и Рекурсивное Внимание
Модели, такие как MMGCN и DGAVE, эффективно объединяют визуальные и текстовые признаки для обогащения представлений элементов, преодолевая ограничения унимодальных подходов. Традиционные методы, использующие только один тип данных (например, только изображения или только текст), часто не позволяют полностью отразить сложность и многогранность информации об элементах. MMGCN и DGAVE решают эту проблему, применяя механизмы слияния признаков, которые позволяют учитывать взаимосвязи между визуальными и текстовыми данными. Это приводит к более полным и информативным представлениям элементов, что, в свою очередь, повышает точность и эффективность рекомендательных систем и других приложений, использующих эти представления. Эффективность такого подхода подтверждается улучшением показателей качества в сравнении с системами, использующими только один тип модальности.
Архитектура CRANE использует двойную графовую структуру, объединяющую граф взаимодействия пользователь-товар и семантический граф товаров. Граф взаимодействия пользователь-товар моделирует прямые связи между пользователями и приобретенными ими товарами, отражая явные предпочтения. Семантический граф товаров, в свою очередь, представляет собой связи между самими товарами, основанные на их атрибутах и категориях, что позволяет учитывать скрытые взаимосвязи и контекст. Комбинирование этих двух графов обеспечивает более полное представление о данных, позволяя модели CRANE учитывать как явные предпочтения пользователей, так и семантические взаимосвязи между товарами.
В основе архитектуры CRANE лежит механизм рекурсивного кросс-модального внимания (RCA), предназначенный для итеративного уточнения корреляций внутри модальностей (визуальных и текстовых признаков) и между ними. RCA позволяет захватывать сложные взаимосвязи между признаками, что приводит к улучшению производительности модели. Экспериментальные результаты на четырех реальных наборах данных показали среднее увеличение эффективности на 5% по сравнению с существующими подходами.
Повышение Эффективности и Персонализация
Модели LPIC и LGMRec демонстрируют значительный прогресс в области персонализированных рекомендаций благодаря использованию обучаемых векторных представлений запросов и моделированию как локальных, так и глобальных интересов пользователя. Вместо статичных запросов, эти модели динамически адаптируют векторные представления в процессе обучения, что позволяет более точно учитывать нюансы предпочтений каждого пользователя. Сочетание анализа текущих действий пользователя (локальные интересы) с долгосрочными предпочтениями (глобальные интересы) позволяет создавать рекомендации, которые одновременно актуальны и соответствуют общим вкусам. Такой подход значительно повышает релевантность предлагаемого контента и способствует более эффективному взаимодействию с пользователем, обеспечивая более персонализированный и удовлетворяющий опыт.
В основе повышения эффективности предложенных моделей лежат методы контрастивного обучения и подходов, ориентированных на идентификаторы (ID-guided). Контрастивное обучение позволяет системе выявлять и усиливать различия между релевантными и нерелевантными элементами, что способствует формированию более чётких и информативных представлений данных. Подходы, основанные на идентификаторах, дополнительно уточняют эти представления, учитывая индивидуальные предпочтения и характеристики пользователей. Благодаря сочетанию этих методов, модели способны более точно ранжировать рекомендации, обеспечивая соответствие запросам пользователей и повышая общую точность системы. Это, в свою очередь, приводит к улучшению качества рекомендаций и повышению удовлетворенности пользователей.
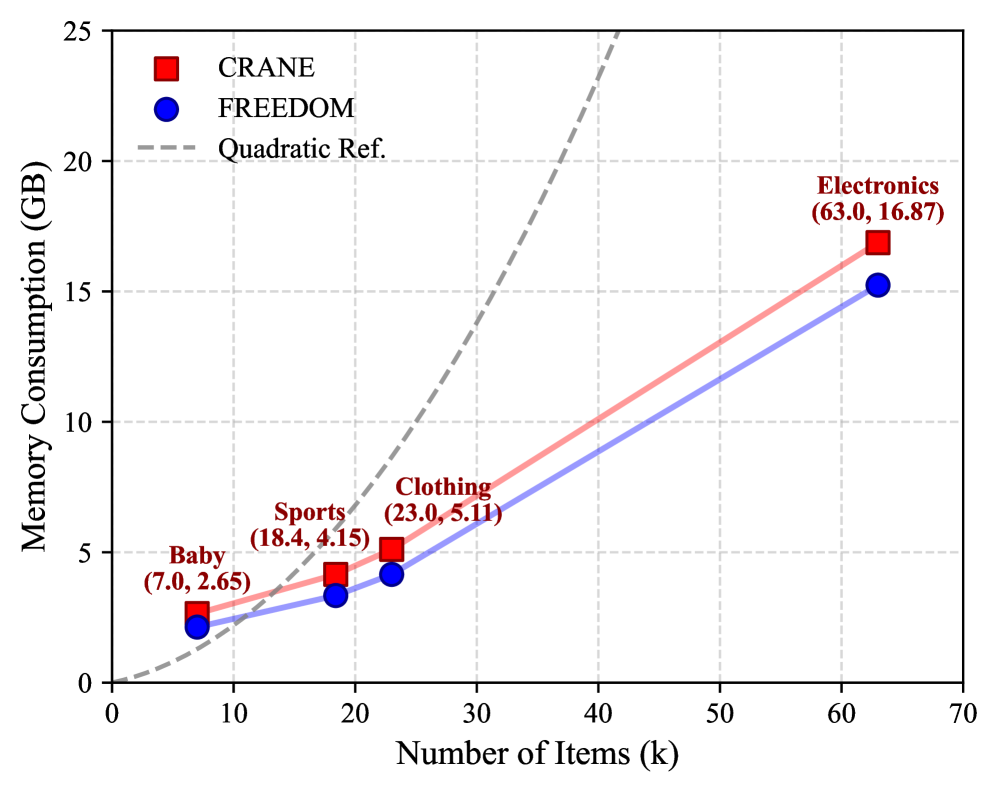
Результаты проведенных оценок демонстрируют, что CRANE достигает показателя Recall@20 в 0.1021 на наборе данных Baby и 0.0956 на наборе Clothing. При этом, время работы модели составляет 17.54 секунды на эпоху при использовании набора данных Electronics, а потребление памяти составляет 16.87 ГБ. Эти данные свидетельствуют о практической эффективности и масштабируемости предложенного подхода, позволяя использовать его в реальных рекомендательных системах даже при работе с большими объемами данных и ограниченными вычислительными ресурсами. Полученные показатели подтверждают, что CRANE способен эффективно находить релевантные рекомендации, обеспечивая при этом приемлемую скорость работы и потребление памяти.

Исследование, представленное в данной работе, напоминает сложный процесс реверс-инжиниринга. Авторы, подобно опытным взломщикам систем, стремятся проникнуть в суть взаимодействия визуальной и текстовой информации, чтобы повысить эффективность рекомендательных систем. CRANE, предложенная модель с двойным графом и рекурсивным кросс-модальным вниманием, демонстрирует стремление понять, как различные модальности данных могут быть объединены для создания более точных и полезных рекомендаций. Как однажды заметила Барбара Лисков: «Программы должны быть построены таким образом, чтобы изменения в одной части не оказывали непредсказуемого влияния на другие». Эта мудрость применима и к архитектуре CRANE, где тщательно продуманная схема взаимодействия графов и механизмов внимания направлена на обеспечение стабильности и предсказуемости результатов.
Что дальше?
Представленная работа, по сути, лишь очередная попытка расшифровки открытого исходного кода реальности, в данном случае — паттернов взаимодействия пользователей и контента. CRANE, с его дуальными графами и рекурсивным кросс-модальным вниманием, демонстрирует, что эффективная семантическая фузия визуальной и текстовой информации возможна. Однако, необходимо помнить: любая модель — это упрощение, а реальность всегда сложнее любой схемы. Остается открытым вопрос о масштабируемости предложенного подхода к действительно большим и динамичным наборам данных. Игнорирование контекста, лежащего за пределами визуального и текстового контента — потенциальное ограничение, требующее дальнейшего исследования.
Следующим шагом видится не просто улучшение точности рекомендаций, а разработка систем, способных к адаптивному обучению и саморефлексии. Необходимо выйти за рамки пассивного анализа данных и перейти к активному формированию предпочтений пользователя, предвосхищая его потребности. Более того, стоит задуматься о внедрении механизмов объяснимости — чтобы не просто рекомендовать, но и аргументировать свой выбор, демонстрируя «логику» системы.
В конечном счете, задача состоит не в создании идеальной рекомендательной системы, а в разработке инструментов, позволяющих пользователю лучше понять самого себя и окружающий мир. Иными словами, расшифровка исходного кода реальности — процесс бесконечный, и каждое новое открытие лишь открывает двери к новым вопросам.
Оригинал статьи: https://arxiv.org/pdf/2601.11151.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Лучшие смартфоны. Что купить в июне 2026.
- Неважно, на что вы фотографируете!
- Российский рынок в штопоре: дефицит бюджета, геополитика и падение индекса Мосбиржи (06.06.2026 01:32)
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Oppo K14 Turbo Pro ОБЗОР: скоростная зарядка, большой аккумулятор, объёмный накопитель
- Sharp Aquos R10 ОБЗОР: плавный интерфейс, яркий экран, объёмный накопитель
- Обзор Nikon D5500 DX
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Huawei nova 16 Ultra ОБЗОР: большой аккумулятор, современный дизайн, плавный интерфейс
- Как сделать панорамное фото
2026-01-20 08:06