Автор: Денис Аветисян
Новый подход позволяет эффективно находить рукописные документы, написанные на разных языках, используя визуальные признаки.
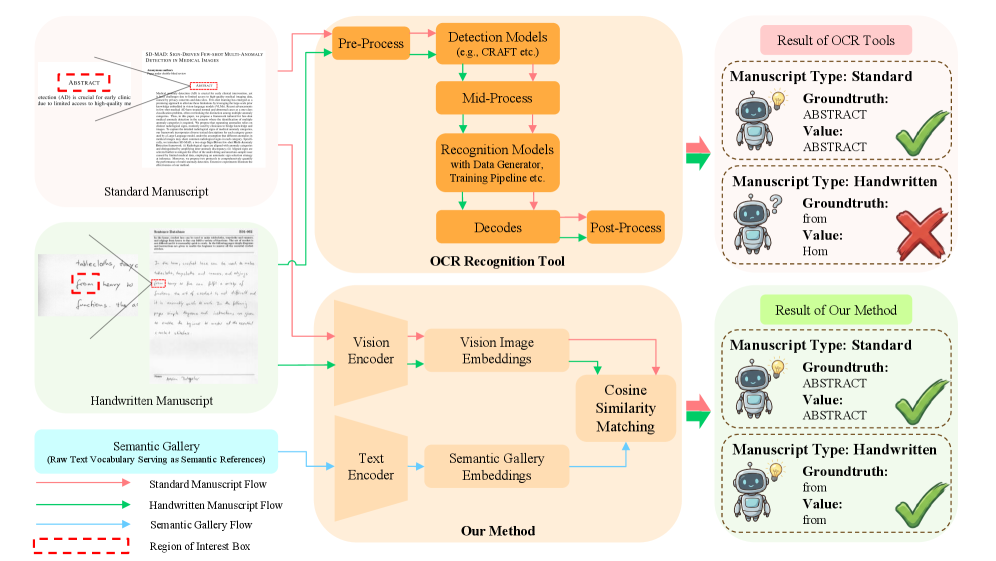
Представлена асимметричная архитектура двойного энкодера для кросс-лингвального поиска рукописного текста с высокой точностью и минимальными вычислительными затратами.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Несмотря на возрастающий объём оцифрованных рукописных документов, поиск по ним остаётся сложной задачей из-за вариативности почерка и языковых барьеров. В работе, озаглавленной ‘Language-Agnostic Visual Embeddings for Cross-Script Handwriting Retrieval’, предложен эффективный асимметричный двухэнкодерный фреймворк, обучающийся создавать унифицированные визуальные представления, инвариантные к стилю и языку. Достигнуто передовое качество поиска рукописных текстов, при этом вычислительные затраты существенно снижены благодаря минимизации числа параметров. Сможет ли данный подход обеспечить масштабируемое решение для оцифровки и анализа исторических архивов, содержащих рукописи на различных языках?
Искусство Распознавания: Вызовы и Перспективы Рукописного Текста
Традиционные системы оптического распознавания символов (OCR) сталкиваются со значительными трудностями при обработке рукописного текста из-за присущей ему вариативности. Каждый почерк уникален — форма букв, наклон, соединение символов, толщина линий — всё это вносит существенные искажения, которые затрудняют точную интерпретацию. В отличие от печатного текста, где символы стандартизированы, рукописные символы могут значительно отличаться даже у одного и того же человека, не говоря уже о разных людях. Эта непредсказуемость приводит к высокой частоте ошибок при распознавании, что существенно ограничивает эффективность OCR в задачах поиска и извлечения информации из рукописных документов, таких как исторические архивы, личные записи или медицинские карты. Неспособность эффективно справляться с этой вариативностью является ключевым препятствием на пути к автоматизации обработки рукописного текста.
Несмотря на то, что методы, основанные на векторных представлениях (embedding), позволяют обойти необходимость явного распознавания рукописного текста, они зачастую демонстрируют недостаток семантического понимания. В отличие от систем, стремящихся к точному преобразованию символов, эти методы фокусируются на создании числовых представлений документов, что позволяет сравнивать их по смыслу, но не всегда обеспечивает корректное извлечение конкретной информации. Например, система может успешно определить, что два документа обсуждают схожую тему, но не сможет точно выделить конкретные факты или даты, упомянутые в этих документах. Это ограничение связано с тем, что векторные представления, хотя и улавливают общие паттерны, не всегда способны отразить нюансы и сложные связи между словами и понятиями, характерные для естественного языка, что снижает эффективность извлечения точных данных из рукописных источников.
Современные подходы к извлечению информации из рукописных текстов, основанные на визуальных больших языковых моделях, сталкиваются с существенными вычислительными трудностями. Несмотря на впечатляющие результаты в распознавании сложных структур и контекста, потребность в огромных вычислительных ресурсах для обучения и развертывания этих моделей препятствует их широкому применению в реальных сценариях. Обучение таких моделей требует значительных затрат энергии и дорогостоящего оборудования, а процесс обработки больших объемов рукописных документов может быть крайне медленным и неэффективным. Это ограничивает возможность использования этих технологий в приложениях, требующих оперативного извлечения информации, например, в архивах, медицинских учреждениях или для автоматизации документооборота, где важна скорость и экономичность.
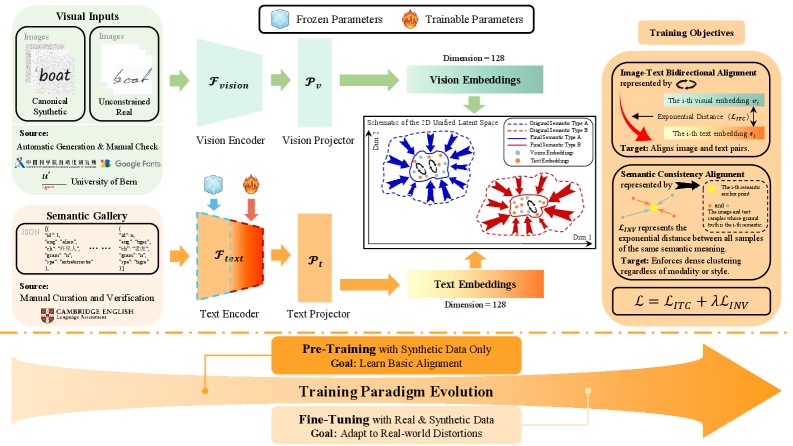
Асимметричная Гармония: Семантическое Выравнивание в Рукописном Тексте
Предлагаемая асимметричная двухкодировщиковая архитектура использует замороженный, предварительно обученный многоязычный текстовый кодировщик в качестве стабильного семантического якоря. Этот подход позволяет зафиксировать семантическое пространство, предоставляя надежную основу для выравнивания с визуальными представлениями. Замораживание весов предварительно обученного кодировщика предотвращает их изменение в процессе обучения, обеспечивая сохранение его способности к обобщению и поддержанию семантической согласованности. Использование предварительно обученной модели, такой как BERT или XLM-RoBERTa, обеспечивает сильную отправную точку для извлечения семантически богатых представлений текста, что критически важно для последующего выравнивания с визуальными данными.
В рамках предложенной архитектуры используется облегченный визуальный энкодер, основанный на MobileNetV3-Small, для преобразования изображений рукописного текста в единое векторное пространство. MobileNetV3-Small выбран в качестве основы благодаря своей эффективности и небольшому количеству параметров, что позволяет снизить вычислительные затраты и требования к памяти. Этот энкодер принимает на вход изображения рукописного текста и генерирует компактные векторные представления, которые затем используются для выравнивания с семантическими представлениями, полученными из текстового энкодера. Архитектура энкодера включает в себя сверточные слои, функции активации и слои пулинга, оптимизированные для обработки изображений рукописного текста и извлечения значимых признаков.
Основным нововведением предложенной архитектуры является выравнивание представлений, полученных из текстового и визуального энкодеров, посредством техник выравнивания на уровне экземпляров и семантической согласованности. Выравнивание на уровне экземпляров обеспечивает соответствие между конкретными рукописными изображениями и их текстовыми описаниями, в то время как семантическая согласованность направлена на достижение инвариантности к семантическим изменениям, таким как вариации в стиле написания или формулировках. Оптимизация данных техник позволяет добиться устойчивости системы к небольшим отклонениям во входных данных и повысить ее обобщающую способность, фокусируясь на сохранении семантического содержания независимо от поверхностных различий.
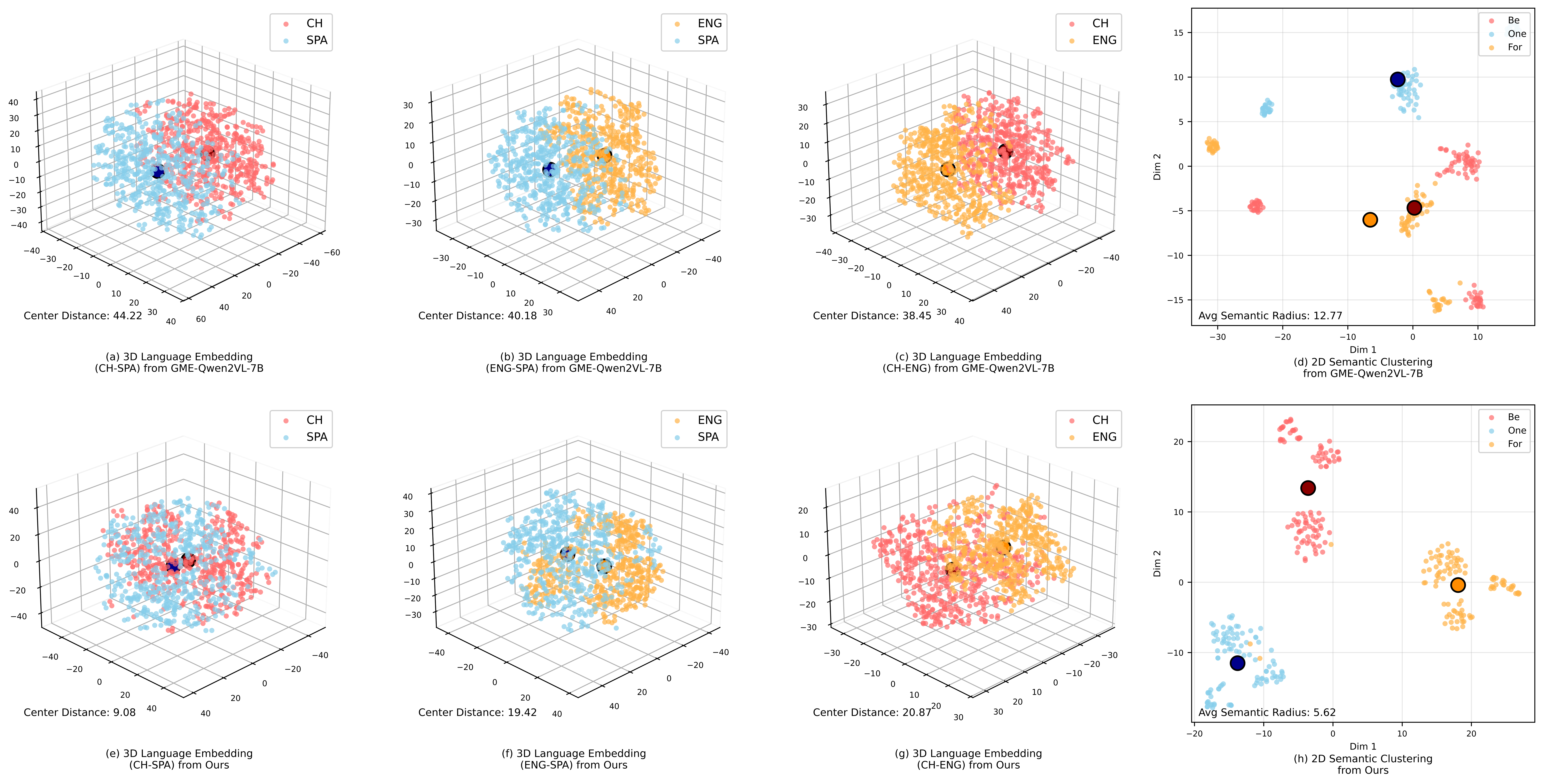
Оптимизация для Эффективности и Производительности
В рамках оптимизации модели используется функция потерь InfoNCE, которая одновременно обеспечивает выравнивание на уровне экземпляров и семантическую согласованность. Выравнивание на уровне экземпляров позволяет модели различать схожие, но различные входные данные, в то время как семантическая согласованность гарантирует, что представления, полученные для семантически связанных данных, будут близки друг к другу в пространстве признаков. Совместная оптимизация этих двух аспектов значительно повышает устойчивость модели к шуму и вариациям во входных данных, обеспечивая более надежную работу в различных условиях и повышая общую производительность.
Для повышения эффективности работы фреймворка применяется квантизация модели, позволяющая снизить вычислительную нагрузку и потребление памяти. В процессе валидации используется симулятор NeuRRAM, реализующий вычисления в памяти (in-memory computing). Этот подход позволяет оценить производительность фреймворка на специализированном оборудовании и подтвердить его пригодность для задач, требующих высокой скорости обработки данных и низкого энергопотребления.
Для повышения обобщающей способности и устойчивости разработанного фреймворка, процесс обучения дополнен использованием синтетических данных. В результате, на стандартном бенчмарке OOD (Out-of-Distribution), фреймворк достиг показателя точности в 86.05%, что является современным уровнем для данной задачи. Использование синтетических данных позволило расширить обучающую выборку и улучшить способность модели к обобщению на невидимых ранее данных, повышая её устойчивость к изменениям в распределении входных данных.
Кросс-Языковой Поиск и Перспективы Развития
Экспериментальные исследования подтвердили высокую эффективность разработанного фреймворка в задачах кросс-языкового поиска рукописных документов. Полученные результаты демонстрируют существенное превосходство предложенного подхода над существующими базовыми методами, что свидетельствует о его потенциале для практического применения. Фреймворк способен успешно извлекать релевантную информацию из документов, написанных на разных языках, обеспечивая более точные и быстрые результаты поиска. Данное достижение открывает новые возможности для оцифровки и анализа исторических архивов, а также для создания интеллектуальных систем обработки документов, способных работать с многоязычными данными.
Разработанная система демонстрирует значительный прогресс в области поиска рукописных документов на разных языках, благодаря приоритету семантической согласованности и вычислительной эффективности. В результате оптимизации, включающей в себя квантизацию int8, удалось добиться впечатляющего снижения задержки в 297.78 раза и уменьшения энергопотребления в 265.35 раза. Это открывает возможности для развертывания системы на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые системы, делая передовые технологии распознавания рукописного текста доступными в самых разных сценариях и местах.
Дальнейшие исследования направлены на расширение возможностей разработанной системы для работы с более сложными структурами документов и разнообразием почерков. Особое внимание будет уделено адаптации алгоритмов к документам, содержащим нестандартное расположение текста, таблицы и графические элементы, что потребует разработки новых методов анализа компоновки страниц. Кроме того, планируется улучшение устойчивости системы к вариативности почерков, включая различия в начертании букв, наклоне и размере, для обеспечения высокой точности распознавания и поиска информации в рукописных документах, созданных разными людьми.
Исследование демонстрирует стремление к элегантности в решении задачи кросс-языкового поиска рукописного текста. Предложенная асимметричная двойная кодировщик-модель, оптимизированная для работы на периферийных устройствах, подчеркивает важность не только точности, но и эффективности вычислений. Как однажды заметил Дэвид Марр: «Понимание — это построение моделей, предсказывающих появление явлений». В данном случае, модель стремится предсказать соответствие между рукописными образцами разных языков, основываясь на визуальных признаках. Это подтверждает, что глубокое понимание проблемы приводит к созданию гармоничного и изящного решения, где форма следует за функцией, а не наоборот. Особенно заметна тенденция к семантической инвариантности, позволяющая системе игнорировать языковые различия и фокусироваться на содержании.
Куда Ведет Эта Дорога?
Представленная работа, безусловно, демонстрирует элегантность решения задачи кросс-лингвального поиска рукописного текста. Однако, истинный прогресс редко бывает полным. Достигнутая эффективность, хотя и впечатляет, лишь подсвечивает фундаментальную проблему: возможно ли вообще создать универсальное представление, не жертвуя при этом нюансами, присущими каждой культуре и языку? Или мы обречены вечно балансировать между обобщением и спецификой?
Следующим шагом видится не столько дальнейшая оптимизация архитектуры, сколько исследование возможностей интеграции с моделями, способными к более глубокому семантическому пониманию. Простое соответствие визуальных признаков — это лишь первый шаг. Необходимо учитывать контекст, намерения автора, даже эмоциональную окраску почерка. А это, в свою очередь, требует значительных вычислительных ресурсов, что ставит под сомнение возможность полной реализации на периферийных устройствах.
В конечном итоге, задача кросс-лингвального поиска рукописного текста — это не просто техническая проблема. Это зеркало, отражающее сложность человеческого общения, границы между языками и культурами. Истинная элегантность решения заключается не в скорости и точности, а в гармонии между формой и функцией, в понимании того, что каждое решение — это лишь временный компромисс в бесконечном поиске совершенства.
Оригинал статьи: https://arxiv.org/pdf/2601.11248.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Лучшие смартфоны. Что купить в июне 2026.
- Неважно, на что вы фотографируете!
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Российский рынок в штопоре: дефицит бюджета, геополитика и падение индекса Мосбиржи (06.06.2026 01:32)
- Российский рынок: консолидация, рубль и секторные тренды – анализ ключевых событий недели (04.06.2026 11:32)
- Sharp Aquos R10 ОБЗОР: плавный интерфейс, яркий экран, объёмный накопитель
- Huawei nova 16 Ultra ОБЗОР: большой аккумулятор, современный дизайн, плавный интерфейс
- vivo S60 ОБЗОР: скоростная зарядка, объёмный накопитель, современный дизайн
- Обзор RayNeo Air 2s и Pocket TV
- Как сделать панорамное фото
2026-01-20 15:01