Автор: Денис Аветисян
Новая методика позволяет компьютерам более эффективно ориентироваться и рассуждать в трехмерном пространстве, приближая их к человеческому восприятию окружающего мира.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"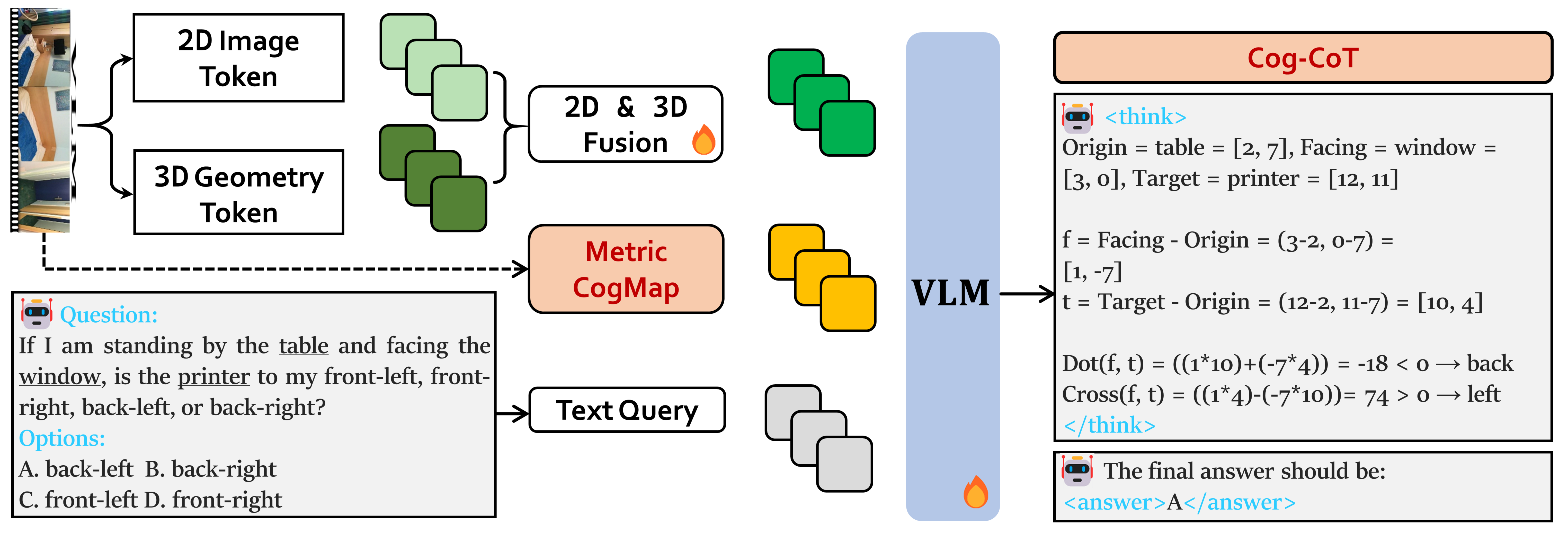
Исследователи представили Map2Thought — фреймворк, использующий метрические когнитивные карты и цепочку рассуждений для улучшения 3D-пространственного понимания в моделях «зрение-язык».
Несмотря на успехи современных визуально-языковых моделей, их способность к явному и интерпретируемому пространственному рассуждению в 3D-пространстве остаётся ограниченной. В данной работе представлена методика ‘Map2Thought: Explicit 3D Spatial Reasoning via Metric Cognitive Maps’ — фреймворк, использующий метрические когнитивные карты и цепочку рассуждений для улучшения 3D-понимания. Эксперименты демонстрируют, что Map2Thought позволяет добиться высокой точности, превосходя современные методы на 5.3%, 4.8% и 4.0% при использовании лишь части обучающей выборки. Сможет ли подобный подход стать основой для создания действительно «видящих» и разумных систем искусственного интеллекта?
За гранью пикселей: Понимание трёхмерного пространства
Современные модели, объединяющие зрение и язык, зачастую демонстрируют ограниченные возможности в тонком трёхмерном пространственном мышлении, что негативно сказывается на их производительности в задачах, требующих геометрического понимания. Неспособность адекватно интерпретировать пространственные отношения между объектами и их взаимное расположение приводит к ошибкам в таких областях, как распознавание сцен, планирование движения и понимание инструкций, связанных с манипулированием объектами в трёхмерном пространстве. Например, модель может испытывать трудности с определением, находится ли объект «перед» или «за» другим, или с пониманием сложных пространственных предлогов, что существенно ограничивает её применимость в реальных условиях и подчеркивает необходимость разработки более совершенных подходов к обучению трёхмерному пространственному мышлению.
Для полноценного пространственного мышления недостаточно обработки двухмерных изображений. Реальный мир по своей природе трёхмерен, и попытки свести его к плоским представлениям неизбежно приводят к потере важной информации о глубине, объеме и взаимном расположении объектов. Эффективное понимание окружающей среды требует анализа и моделирования трёхмерного пространства, что позволяет учитывать не только то, что видно на изображении, но и где это находится относительно других объектов и самого наблюдателя. Такой подход критически важен для систем, взаимодействующих с физическим миром, поскольку позволяет им точно воспринимать геометрию пространства и адекватно реагировать на изменения в нём, избегая столкновений и обеспечивая успешное выполнение поставленных задач.
Разработка надёжной системы трёхмерного понимания пространства становится ключевым фактором для прогресса в таких областях, как робототехника, дополненная и виртуальная реальность, а также автономная навигация. В робототехнике способность точно воспринимать и взаимодействовать с трёхмерным окружением необходима для выполнения сложных задач, требующих манипулирования объектами и ориентирования в пространстве. В сферах AR/VR реалистичное и интуитивно понятное взаимодействие с виртуальными мирами напрямую зависит от точности трёхмерного моделирования и отслеживания положения пользователя. Наконец, для автономных транспортных средств, таких как беспилотные автомобили и дроны, адекватное восприятие трёхмерной среды является абсолютно критичным для обеспечения безопасности и эффективной навигации в реальном мире, позволяя им избегать препятствий и адаптироваться к изменяющимся условиям.
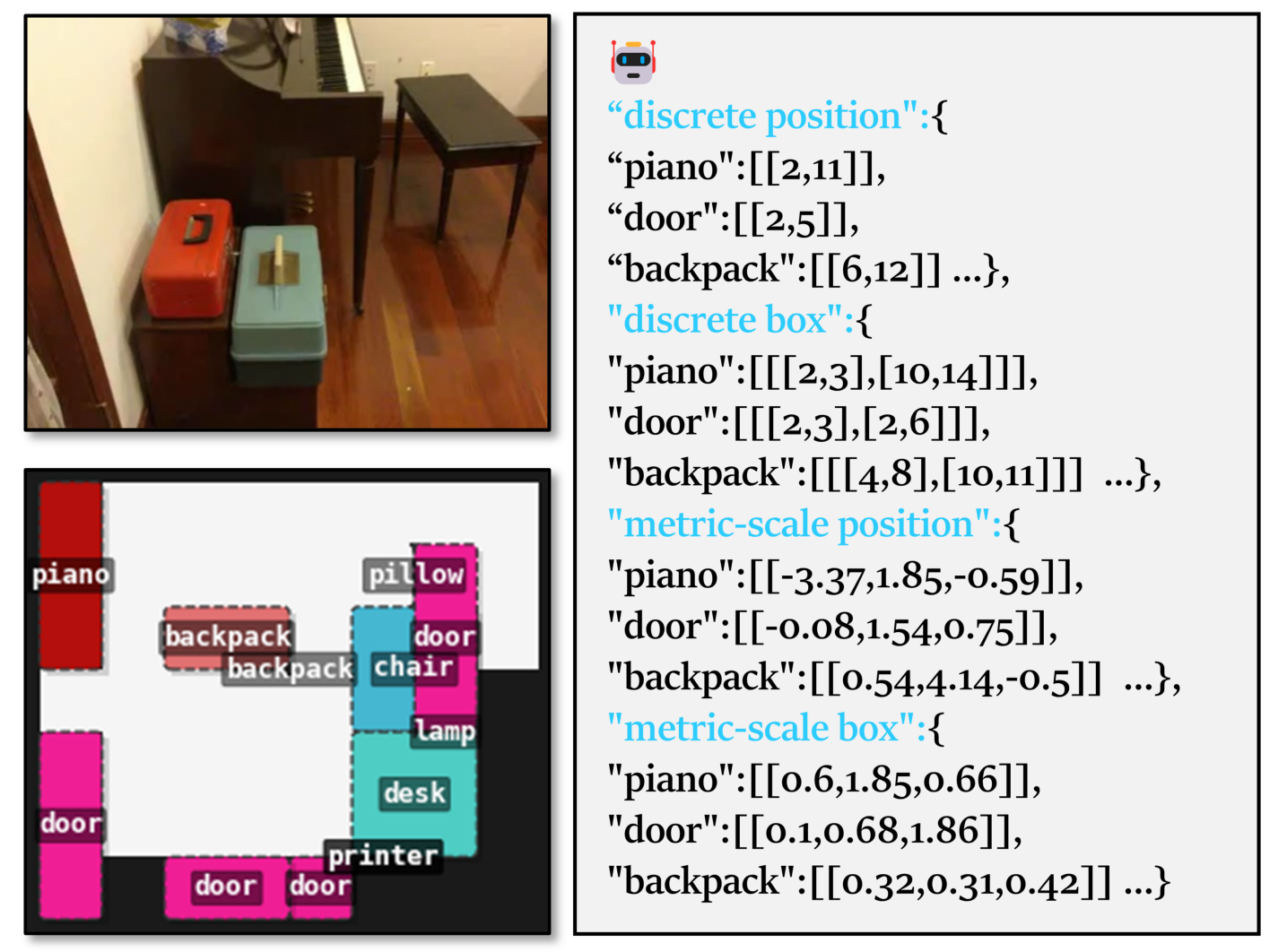
Метрическая Ког-Карта: Единое пространственное представление
Метрическая Ког-Карта (Metric-CogMap) объединяет дискретные сетчатые представления для символьных рассуждений с непрерывной метрической геометрией для точной локализации. Дискретные сетки, представляющие собой деление пространства на ячейки, обеспечивают основу для символической обработки и планирования, позволяя эффективно представлять и манипулировать абстрактными понятиями пространства. Одновременно непрерывная метрическая геометрия, основанная на реальных координатах и расстояниях, позволяет осуществлять точную локализацию агента в пространстве и вычислять оптимальные траектории. Такая интеграция позволяет системе одновременно оперировать символическими представлениями пространства и точными геометрическими данными, обеспечивая гибкость и эффективность в различных задачах, таких как навигация и планирование маршрутов. Пространственные данные кодируются как в дискретном, так и в непрерывном виде, что позволяет использовать преимущества обоих подходов.
Гибридный подход, реализованный в Metric-CogMap, обеспечивает возможность одновременного выполнения задач высокоуровневого планирования и детализированных геометрических вычислений в единой системе координат. Это достигается за счёт интеграции дискретных сеток, используемых для символьного представления и логических выводов, с непрерывной метрической геометрией, обеспечивающей точную локализацию и расчёт расстояний. Такая архитектура позволяет системе эффективно решать задачи, требующие как абстрактного мышления (например, выбор оптимального маршрута), так и точных расчётов (например, избежание препятствий), без необходимости переключения между различными системами представления информации. Возможность одновременной обработки данных различного типа значительно повышает эффективность и гибкость системы в целом.
Традиционные подходы к представлению пространственной информации часто ограничиваются либо дискретными, символьными представлениями, обеспечивающими логическое рассуждение, но не позволяющими точную локализацию, либо непрерывными, метрическими представлениями, которые, хотя и обеспечивают высокую точность, затрудняют высокоуровневое планирование и символьные выводы. Metric-CogMap преодолевает эти ограничения, объединяя преимущества обеих парадигм. Такая гибридная архитектура позволяет одновременно выполнять символьное планирование на основе дискретной сетки и точные геометрические вычисления в непрерывном метрическом пространстве, обеспечивая более полное и гибкое представление окружающей среды.

От видео к карте: Построение трёхмерной модели мира
Конвейер “Видео в Карту” использует современные методы для построения Metric-CogMap. В частности, для обнаружения объектов на видео применяются алгоритмы Detic и Grounding DINO, обеспечивающие 2D-детектирование. Сегментация видео выполняется с использованием SAM2, что позволяет выделять объекты в каждом кадре. Трехмерная реконструкция выполняется на основе CUT3R, создавая 3D-модели объектов и их окружения. Комбинирование этих методов позволяет формировать целостное представление о сцене, представленное в виде Metric-CogMap.
Карты взаимной видимости (Covisibility Maps) применяются для обеспечения геометрической согласованности и точных пространственных взаимосвязей между объектами в создаваемой 3D-модели. Данные карты строятся на основе анализа перекрытия объектов в последовательности кадров видео, выявляя, какие объекты видны друг другу с различных точек обзора. Это позволяет установить корректные относительные позиции объектов, устранить геометрические неточности, возникающие при реконструкции по отдельным кадрам, и обеспечить формирование когерентной и достоверной 3D-карты окружения. Использование карт взаимной видимости критически важно для обеспечения точности и надёжности системы Metric-CogMap.
Механизм перекрестного внимания (Cross-Attention) используется для эффективного объединения токенов визуальных признаков (полученных из CLIP-ViT) с трёхмерной геометрической информацией. Этот механизм позволяет модели устанавливать связи между визуальными характеристиками объектов, представленными в виде токенов, и их соответствующими координатами в трёхмерном пространстве. В частности, перекрестное внимание вычисляет веса, определяющие вклад каждого визуального токена в представление конкретной точки в трёхмерной сцене, и наоборот. Это обеспечивает более точное и надёжное представление трёхмерной модели, учитывающее как визуальные характеристики объектов, так и их пространственное расположение, что критически важно для построения когерентной и точной Metric-CogMap.

Рассуждения с геометрией: Представляем Cog-CoT
Система Cog-CoT осуществляет явное пошаговое рассуждение, опираясь на Metric-CogMap, что позволяет проводить интерпретируемые геометрические вычисления. В отличие от “черных ящиков”, Cog-CoT не просто выдаёт ответ, а демонстрирует ход своих мыслей, разлагая сложные пространственные задачи на последовательность более простых операций. Этот подход, подобный человеческому способу решения геометрических головоломок, позволяет не только получить корректный результат, но и понять, каким образом он был достигнут. В частности, система способна оперировать такими понятиями, как расстояния, углы и относительное положение объектов, представляя эти данные в виде графа и последовательно применяя логические правила для достижения цели. Благодаря этому процесс вычислений становится прозрачным и отлаживаемым, что открывает возможности для анализа и улучшения работы системы, а также для верификации полученных результатов.
Предлагаемый подход позволяет решать сложные задачи пространственного мышления, разбивая их на более мелкие и управляемые этапы. Вместо попыток решить задачу целиком, система последовательно анализирует её компоненты, выстраивая логическую цепочку рассуждений. Каждый этап представляет собой небольшую, чётко сформулированную задачу, решение которой приближает к конечному ответу. Такой декомпозиционный метод не только упрощает процесс решения, но и делает его более прозрачным и понятным, позволяя отслеживать ход мысли системы и выявлять возможные ошибки на каждом шаге. Это особенно важно для задач, требующих точного позиционирования объектов, оценки расстояний или планирования траекторий, где даже небольшая неточность может привести к неправильному результату.
Интеграция геометрического рассуждения с Metric-CogMap открывает новые горизонты в области искусственного интеллекта, способного решать пространственные задачи. Данный подход позволяет системам не просто распознавать объекты в пространстве, но и логически выводить новые факты об их взаимном расположении и свойствах. Используя геометрические принципы и представляя пространство в виде когнитивной карты, алгоритмы способны планировать действия, предсказывать последствия и находить оптимальные решения в сложных ситуациях, таких как навигация, робототехника и анализ изображений. Это качественно новый уровень понимания пространства, позволяющий искусственному интеллекту действовать более эффективно и осмысленно в реальном мире, приближая его к человеческому уровню когнитивных способностей.

Валидация и направления дальнейших исследований
Разработанная система была тщательно протестирована на наборе данных VSI-Bench, предназначенном для оценки способностей к трёхмерному пространственному мышлению. Результаты продемонстрировали высокую эффективность предложенного подхода, достигнув точности в 59.9% при использовании лишь половины доступных обучающих данных. Этот показатель свидетельствует о значительном потенциале системы в задачах, требующих понимания и анализа пространственных отношений, и указывает на её способность эффективно обучаться даже при ограниченном объеме информации. Успешное выполнение тестов на VSI-Bench подтверждает перспективность применения данной системы в различных областях, где критически важна способность к пространственному рассуждению.
Полученные результаты превзошли показатели базовой модели, обученной на полном объеме данных, достигнув улучшения точности на 4,0% при использовании лишь 50% обучающей выборки. Данное достижение демонстрирует эффективность предложенного подхода в условиях ограниченного объема данных, что особенно важно для практических приложений, где сбор и аннотация больших датасетов могут быть ресурсоемкими и дорогостоящими. Такой прирост точности при уменьшении объема обучающих данных указывает на способность модели к более эффективному обобщению и извлечению значимой информации из имеющихся данных, что открывает перспективы для применения в задачах, где доступ к полным данным ограничен.
Предстоящие исследования направлены на расширение возможностей разработанной системы путем применения к более масштабным наборам данных. Особое внимание будет уделено изучению потенциала этой системы в областях робототехники и дополненной реальности. Планируется исследовать, как улучшенное пространственное рассуждение может способствовать созданию более автономных и эффективных роботов, способных ориентироваться и взаимодействовать с окружающей средой. Кроме того, рассматривается возможность интеграции системы в приложения дополненной реальности для повышения реалистичности и интерактивности виртуальных объектов и сцен, что позволит создавать более захватывающие и полезные пользовательские опыты.
Исследование демонстрирует, что попытки навязать структурированное понимание пространству — создание “метрических когнитивных карт” — лишь временное усмирение хаоса. Каждая карта — это иллюзия порядка, способная объяснить мир до тех пор, пока не встретится первая аномалия. Как точно подметил Дэвид Марр: «Представление — это всегда упрощение, а реальность всегда сложнее». Map2Thought, стремясь к геометрическому обоснованию и цепному рассуждению, лишь создает более изящную иллюзию, позволяя моделям “красиво лгать” о пространстве, пока не столкнётся с истинной непредсказуемостью мира, которую эти самые карты и не способны отобразить.
Куда же ведёт карта?
Представленный подход, выстраивающий когнитивные карты для ориентации в трёхмерном пространстве, конечно, льстит разуму. Но не стоит забывать — любая карта есть упрощение, заклинание порядка над хаосом восприятия. Эта «метрическая» когнитивная карта — лишь очередная попытка заставить данные шептать желаемые ответы, а не те, что они действительно скрывают. Вполне вероятно, что истинное понимание пространства требует не более чёткого картографирования, а скорее, принятия его фундаментальной неопределённости.
Дальнейшее развитие этого направления, скорее всего, столкнётся с необходимостью преодоления иллюзии объективности. Как перенести эту модель из контролируемой среды VSI-Bench в реальный мир, где объекты не всегда соответствуют нашим представлениям, а освещение и окклюзии играют злую шутку? И главный вопрос: способность модели «рассуждать» цепочкой мыслей — это подлинный интеллект или просто более изощрённая форма статистической корреляции, замаскированная под логику?
В конечном итоге, успех подобных исследований будет зависеть не от точности картографирования, а от смирения перед непознаваемостью. Может быть, вместо того, чтобы строить карты, стоит научиться читать следы хаоса, угадывать его прихоти и принимать неточность как неотъемлемую часть реальности. Ведь даже самая совершенная карта — это всего лишь тень, а не сама земля.
Оригинал статьи: https://arxiv.org/pdf/2601.11442.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Как сделать фотографию резкой.
- Обзор Motorola Edge 50 Fusion
- 10 лучших OLED ноутбуков. Что купить в июне 2026.
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Российский рынок: от инфляции к инвестициям: что ждет инвесторов? (11.06.2026 02:32)
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Прогнозы цен на CC: анализ криптовалюты CC
- Nikon D7200
- Синхронизация вспышки. Что такое Sync speed и режим FP.
2026-01-21 04:20