Автор: Денис Аветисян
Новая система позволяет гуманоидным роботам автономно выбирать оптимальные стратегии захвата и управления движением, ориентируясь на визуальное восприятие и лингвистические команды.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"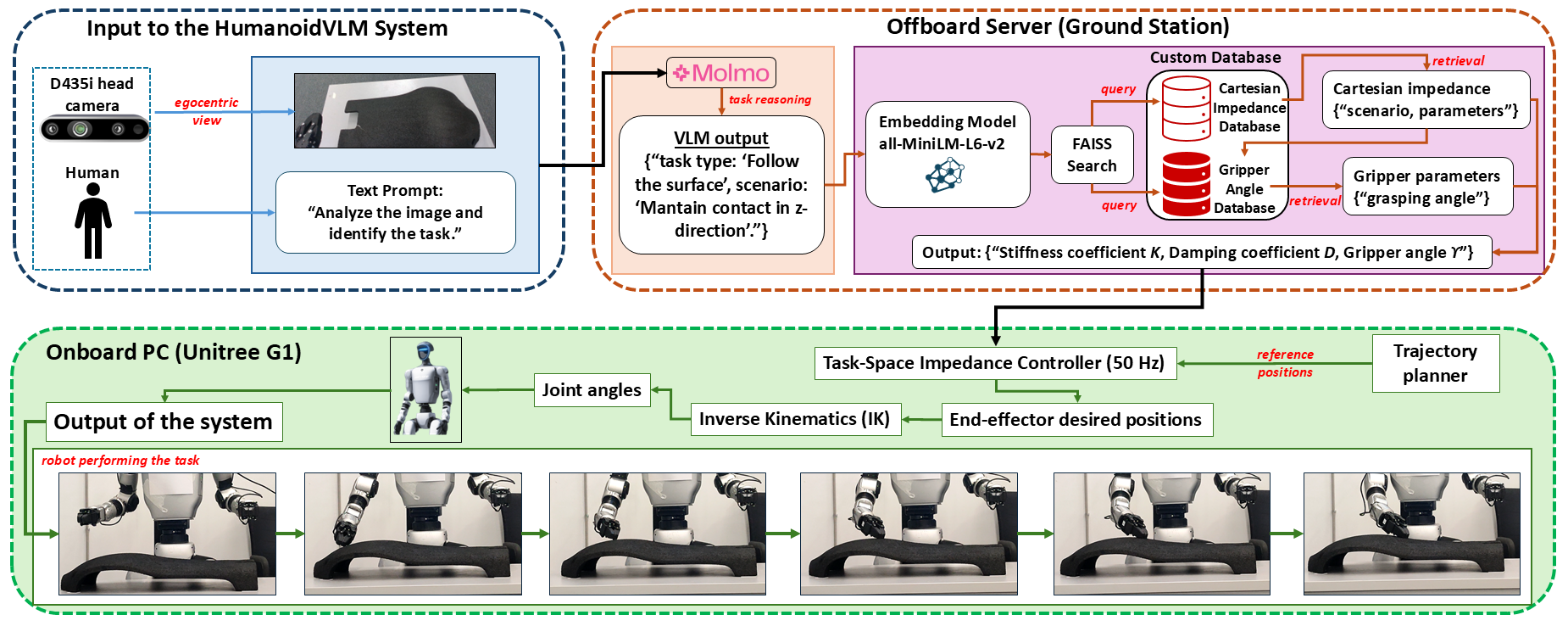
Представлена HumanoidVLM — система управления импедансом, основанная на моделях обработки зрения и языка, для эффективного манипулирования в условиях тесного контакта.
Несмотря на значительный прогресс в робототехнике, надежное манипулирование объектами в реальных условиях остается сложной задачей для гуманоидных роботов. В данной работе, представленной в статье ‘HumanoidVLM: Vision-Language-Guided Impedance Control for Contact-Rich Humanoid Manipulation’, предлагается система HumanoidVLM, использующая зрение и обработку естественного языка для адаптации параметров управления и захвата объектов. Ключевым достижением является возможность автономного выбора оптимальных настроек импеданса и захвата на основе визуального анализа сцены, что обеспечивает устойчивое и плавное взаимодействие робота с окружающей средой. Открывает ли этот подход новые перспективы для создания более гибких и адаптивных гуманоидных роботов, способных к сложным манипуляциям в неструктурированных условиях?
Традиции и Пророчества: Роботы в Неопределенности
Традиционные системы управления роботами, как правило, опираются на детальные математические модели и жестко запрограммированные последовательности действий. Такой подход, хотя и эффективен в строго определенных и статичных условиях, демонстрирует существенные ограничения при столкновении с динамичными, непредсказуемыми средами. Роботы, функционирующие на основе таких моделей, испытывают трудности при адаптации к непредвиденным обстоятельствам, изменениям в окружающей обстановке или новым объектам, что значительно снижает их полезность в реальных приложениях, требующих гибкости и автономности. Неспособность к оперативному перепрограммированию и корректировке действий в ответ на внешние факторы делает их уязвимыми и ограничивает спектр решаемых задач, особенно в сферах, где требуется взаимодействие с постоянно меняющимся миром.
Для обеспечения надежной манипуляции роботом необходима система, способная интерпретировать задачу по визуальным данным и преобразовывать это понимание в соответствующие действия. Это означает, что робот должен не просто распознавать объекты, но и понимать их функциональное назначение и взаимосвязь в контексте решаемой задачи. Такой подход требует интеграции компьютерного зрения, алгоритмов распознавания образов и планирования движений, чтобы робот мог самостоятельно адаптироваться к изменяющимся условиям и выполнять сложные манипуляции с высокой точностью и эффективностью. В отличие от традиционных систем, полагающихся на жестко запрограммированные последовательности, данная концепция предполагает создание «интеллектуальной» системы, способной к обучению и самокоррекции, что открывает путь к созданию действительно универсальных роботов-манипуляторов.
Современные системы управления роботами часто испытывают трудности при объединении понимания задачи на высоком, семантическом уровне с непосредственным управлением моторами. Несмотря на успехи в распознавании объектов и планировании действий, перевод абстрактного “понимания” — например, “поднять чашку” — в точные последовательности движений суставов остается сложной задачей. Это связано с тем, что системы, как правило, разрабатываются отдельно: одни специализируются на обработке визуальной информации и построении целей, а другие — на низкоуровневом контроле, что создает “разрыв” между восприятием и действием. В результате, роботы часто демонстрируют неуклюжесть и неспособность адаптироваться к незначительным изменениям в окружающей среде или к неожиданным препятствиям, что ограничивает их возможности в реальных, динамичных условиях. Преодоление этой проблемы требует разработки новых архитектур, интегрирующих оба уровня управления в единую, когерентную систему.

Зрение, Язык и Управление: Новая Эра Роботизированных Действий
Система HumanoidVLM использует модель «Зрение-Язык» для непосредственного определения задач манипулирования на основе визуальной информации, получаемой с эгоцентричной RGB-камеры. Это позволяет системе интерпретировать визуальные данные и преобразовывать их в высокоуровневые инструкции для управления манипулятором. Модель принимает в качестве входных данных изображение и генерирует описание необходимой задачи, что обеспечивает возможность выполнения манипуляций, основанных на визуальном восприятии окружающей среды, без необходимости предварительного программирования или ручного ввода команд.
В основе HumanoidVLM лежит механизм Retrieval-Augmented Generation (RAG), обеспечивающий эффективный поиск параметров управления для выполнения манипуляций. Система использует две специализированные базы данных: базу данных кинематических параметров (Cartesian Impedance Database) и базу данных углов захвата (Gripper-Angle Database). При получении визуального ввода, RAG извлекает релевантные параметры из этих баз данных, используя поиск по подобию. Такой подход позволяет быстро и точно определить необходимые настройки для стабильного и адаптируемого управления манипулятором, избегая сложных вычислений в реальном времени и повышая надежность выполнения задач.
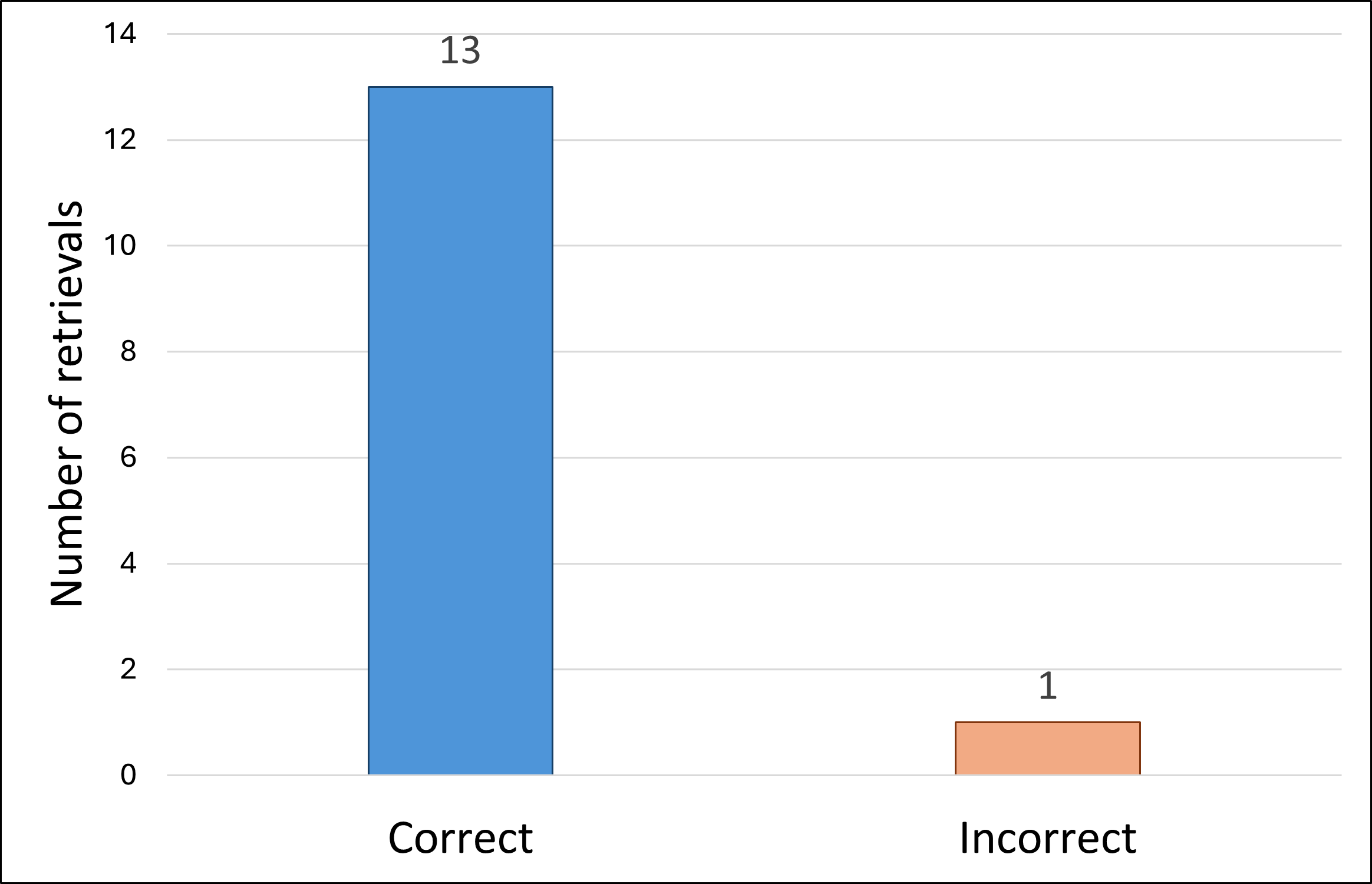
В процессе извлечения параметров управления, система HumanoidVLM демонстрирует точность в 93% при определении корректных значений импеданса и угла захвата. Достижение такой высокой точности позволяет обеспечить стабильную и податливую манипуляцию в реальных условиях эксплуатации. Эффективность поиска обеспечивается использованием библиотеки FAISS, которая реализует быстрый алгоритм поиска ближайших соседей для определения наиболее подходящих параметров из баз данных.
Семантический Контроль: От Восприятия к Точным Действиям
В составе VLM используется модель Molmo-7B-O, которая для представления визуальных запросов (Visual Queries) в семантическом пространстве использует алгоритм all-MiniLM-L6-v2. Этот подход позволяет эффективно кодировать визуальную информацию в векторные представления, что облегчает поиск и извлечение релевантных данных. Векторное представление, полученное с помощью all-MiniLM-L6-v2, служит основой для семантического поиска, обеспечивая возможность сопоставления визуальных запросов с соответствующими объектами или сценами в базе данных VLM.
Система управления роботом использует Картезианский Импеданс-контроль для модуляции взаимодействия с окружающей средой посредством вычисления виртуальной силы. Этот подход позволяет роботу адаптировать свои усилия и положение в ответ на внешние воздействия, обеспечивая контролируемое и стабильное взаимодействие. Расчет виртуальной силы основан на желаемых характеристиках жесткости, демпфирования и инерции, которые определяют реакцию робота на отклонения от заданной траектории или приложенные силы. Использование Картезианского Импеданс-контроля позволяет роботу выполнять задачи, требующие точного позиционирования и взаимодействия с объектами, одновременно обеспечивая защиту от перегрузок и повреждений.
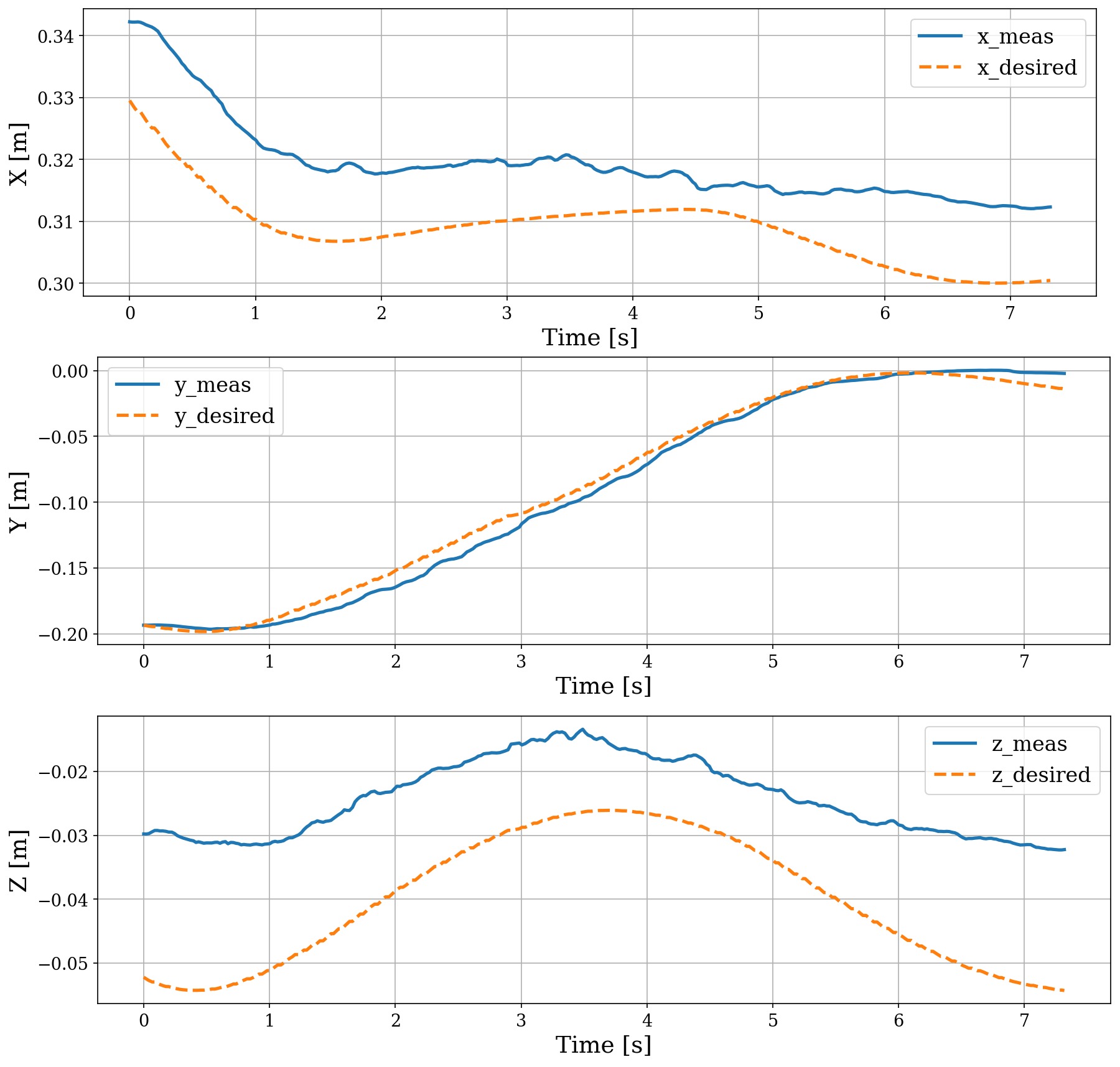
В ходе выполнения задачи следования по поверхности (Surface Following Task) система продемонстрировала высокую степень соответствия требованиям (Task-Space Compliance). В процессе тестирования удалось добиться погрешности отслеживания по оси Z менее 2.5 см во всех сценариях, что подтверждает способность системы к адаптивному и точному взаимодействию с окружающей средой. Данный показатель свидетельствует о стабильной работе алгоритмов управления и их эффективности в обеспечении плавного и контролируемого движения робота по заданной траектории.
Влияние и Перспективы Адаптивной Робототехники
HumanoidVLM знаменует собой важный прорыв в области робототехники, представляя систему, способную к пониманию и адаптации к сложным условиям окружающей среды без необходимости явного программирования каждого действия. В отличие от традиционных роботов, требующих детальных инструкций для выполнения даже простых задач, данная разработка полагается на визуально-языковое понимание (VLM), позволяющее роботу интерпретировать окружающий мир и принимать решения на основе семантического анализа. Это открывает перспективы для создания роботов, способных самостоятельно справляться с неожиданными ситуациями, ориентироваться в незнакомой обстановке и выполнять широкий спектр задач, не предусмотренных заранее. Фактически, HumanoidVLM приближает нас к созданию действительно автономных роботов, способных к гибкому и интеллектуальному взаимодействию с миром.
В основе надежной работы разработанной системы в условиях постоянно меняющейся обстановки лежит способность к семантическому пониманию и эффективному поиску информации. Вместо жесткого программирования на каждый возможный сценарий, робот способен интерпретировать смысл происходящего, вычленять ключевые объекты и отношения между ними. Благодаря этому, система способна быстро находить релевантные данные из своей базы знаний и применять их для решения текущей задачи, даже если ситуация отличается от тех, с которыми робот сталкивался ранее. Эффективный механизм извлечения информации позволяет избегать задержек, критичных для работы в динамичной среде, обеспечивая своевременное и адекватное реагирование на изменения.
Дальнейшие исследования направлены на значительное расширение возможностей данной платформы. Планируется усовершенствование способности визуально-языковых моделей к логическому выводу и принятию решений, что позволит роботам более эффективно интерпретировать сложные ситуации. Параллельно ведется работа над созданием более обширных баз знаний, обогащенных разнообразной информацией об окружающем мире, что обеспечит более глубокое понимание контекста. Кроме того, интеграция с передовыми сенсорными системами, включая лидары, камеры высокого разрешения и тактильные датчики, позволит роботам получать более полную и точную информацию об окружающей среде, что критически важно для адаптации и успешного функционирования в динамичных условиях. Успешная реализация этих направлений откроет новые перспективы для создания действительно автономных и интеллектуальных робототехнических систем.
Исследование, представленное в данной работе, демонстрирует, что системы, взаимодействующие с физическим миром, требуют не жесткого программирования, а способности адаптироваться к непредсказуемости окружения. Авторы подчеркивают важность интеграции визуального восприятия и языкового понимания для управления роботами-гуманоидами, позволяя им выбирать оптимальные стратегии манипулирования. В этом контексте, слова Джона фон Неймана приобретают особую значимость: «Любая достаточно сложная система рано или поздно даст сбой». Это напоминает о том, что даже самые передовые системы, подобные HumanoidVLM, должны быть спроектированы с учетом возможности ошибок и непредвиденных обстоятельств, а не стремиться к абсолютной надежности. Именно гибкость и способность к адаптации, а не жесткий контроль, определяют устойчивость системы в долгосрочной перспективе, особенно в задачах, связанных с взаимодействием с реальным миром.
Что дальше?
Представленная работа, безусловно, демонстрирует потенциал симбиоза зрительно-языковых моделей и управления импедансом в задачах манипулирования гуманоидными роботами. Однако, следует признать: это не столько построение системы, сколько взращивание хрупкой экосистемы. Каждый выбор архитектуры — это не просто техническое решение, а пророчество о будущей точке отказа. Успешное выполнение задач в контролируемой среде не гарантирует устойчивости перед лицом непредсказуемости реального мира.
Настоящая устойчивость начинается там, где кончается уверенность в полноте и точности данных, полученных от зрительно-языковой модели. Необходимо сместить фокус исследований с достижения все большей точности распознавания, на разработку механизмов, позволяющих роботу элегантно и безопасно справляться с неясностями и ошибками. Мониторинг — это не просто сбор метрик, а осознанный способ бояться, предвидеть потенциальные сбои и готовиться к ним.
Будущие работы должны быть направлены на исследование возможностей обучения робота адаптации к новым ситуациям, не требующим переобучения модели. Следует уделить внимание разработке методов, позволяющих роботу самостоятельно обнаруживать и исправлять ошибки в интерпретации зрительно-языковых команд, превращая каждый инцидент не в ошибку, а в момент истины, возможность для самосовершенствования.
Оригинал статьи: https://arxiv.org/pdf/2601.14874.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- vivo iQOO Z10 Turbo+ ОБЗОР: скоростная зарядка, плавный интерфейс, объёмный накопитель
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- Рынок в смятении: Снижение ставки ЦБ, волатильность рубля и новые возможности для инвесторов (25.04.2026 01:32)
- Acer Aspire 5 Spin 14 ОБЗОР
- Acer Aspire 5 A515-57G-53N8 ОБЗОР
- AMD разворачивает «штаб-квартиру» для мониторинга нашего веб-сайта на предмет утечек.
- Motorola Moto G77 ОБЗОР: отличная камера, лёгкий, чёткое изображение
- Визуальный язык: от простого к сложному
- Обзор Asus VivoBook 16: лучше большинства бюджетных ноутбуков.
- ZenBook 14 OLED UX3405CA, Ultra 7 255H ОБЗОР
2026-01-22 19:09