Автор: Денис Аветисян
Исследователи предлагают использовать трёхмерную среду в качестве промежуточного этапа при генерации изображений по текстовому описанию, открывая возможности для более точной композиции и редактирования.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"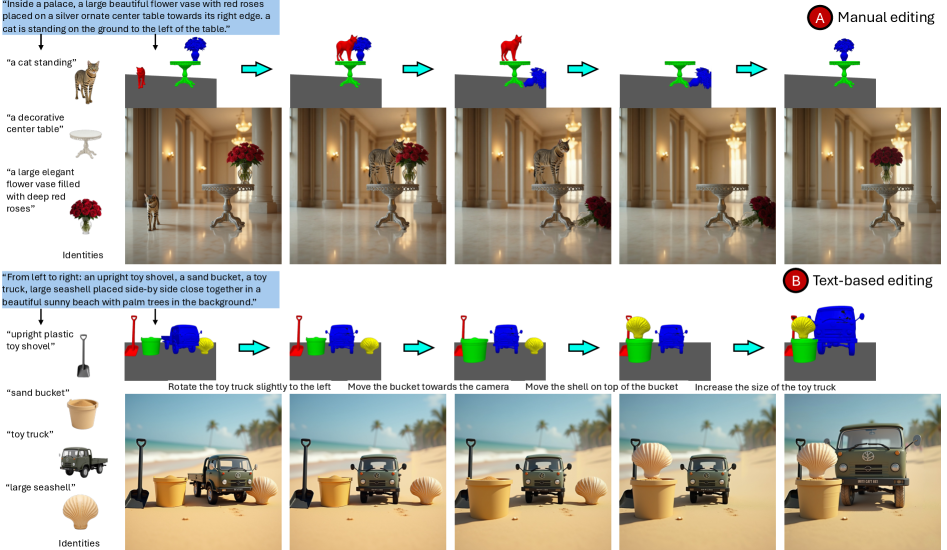
Предложен подход, использующий трёхмерный пространственный буфер для улучшения логического мышления и редактируемости моделей преобразования текста в изображение.
Несмотря на успехи современных визуальных языковых моделей, им часто не хватает способности к точному пространственному рассуждению, что ограничивает генерацию изображений, достоверно отражающих геометрические связи и композиционное намерение. В работе «3D Space as a Scratchpad for Editable Text-to-Image Generation» предложен концепт «пространственного черновика» — трехмерной среды для рассуждений, связывающей лингвистические запросы и синтез изображений. Данный подход, основанный на создании редактируемых 3D-моделей объектов и планировании сцены, обеспечивает повышение точности и возможности редактирования генерируемых изображений. Не откроет ли эта парадигма, использующая не только лингвистические, но и пространственные рассуждения, новые горизонты для контролируемой и точной генерации изображений?
Преодолевая Пиксели: Необходимость Трёхмерного Рассуждения
Современные системы генерации изображений из текстовых описаний часто сталкиваются с трудностями при воссоздании сложных пространственных взаимосвязей и композиционного построения сцены, что приводит к появлению нереалистичных или логически несостоятельных изображений. Ошибки проявляются в нарушении перспективы, неестественном расположении объектов относительно друг друга, и игнорировании физических законов взаимодействия. Например, система может сгенерировать объект, парящий в воздухе без видимой поддержки, или создать тень, не соответствующую направлению света. Эти недостатки особенно заметны при создании сложных сцен с множеством взаимодействующих элементов, где точное понимание трехмерного пространства критически важно для достижения убедительного результата.
Современные методы генерации изображений зачастую рассматривают процесс как задачу, ограниченную двумя измерениями, что препятствует достоверному воссозданию окружающего мира. Этот подход игнорирует фундаментальную трёхмерность реальности, из-за чего синтезированные сцены могут казаться плоскими и неестественными. Отсутствие понимания глубины и пространственных взаимосвязей значительно ограничивает возможности контроля над композицией и деталями изображения. В результате, даже при использовании продвинутых алгоритмов, добиться правдоподобной визуализации сложных сцен с реалистичными объектами и их взаимодействием представляется сложной задачей, а творческий потенциал системы остаётся нереализованным.
Для реалистичного воссоздания сцен требуется система, способная не просто оперировать пикселями, но и понимать, а главное — манипулировать пространственной информацией в трехмерной среде. Вместо плоского представления, подобная система должна строить внутреннюю модель сцены, учитывающую глубину, взаимное расположение объектов и их физические взаимосвязи. Это позволяет учитывать перспективу, тени, отражения и другие визуальные эффекты, делающие изображение правдоподобным. Такой подход позволяет не только генерировать более качественные изображения, но и предоставляет пользователю больший контроль над композицией и содержанием сцены, давая возможность точно задавать положение объектов в пространстве и их взаимодействие друг с другом.
Создание правдоподобных и сложных визуальных сцен остается значительной проблемой для современных генеративных моделей. Отсутствие глубокого понимания трехмерного пространства и взаимодействия объектов в нем приводит к тому, что сгенерированные изображения часто демонстрируют нелогичные перспективы или физически невозможные ситуации. Например, объекты могут непропорционально располагаться относительно друг друга, нарушая ощущение глубины и реализма. До тех пор, пока системы искусственного интеллекта не научатся эффективно моделировать и манипулировать пространственными отношениями, достижение подлинной визуальной достоверности и создание действительно убедительных взаимодействий в сгенерированных изображениях останется недостижимой целью, ограничивая потенциал этих технологий в таких областях, как виртуальная реальность, робототехника и визуализация данных.
Пространственный Черновик: Двигатель Трёхмерного Рассуждения
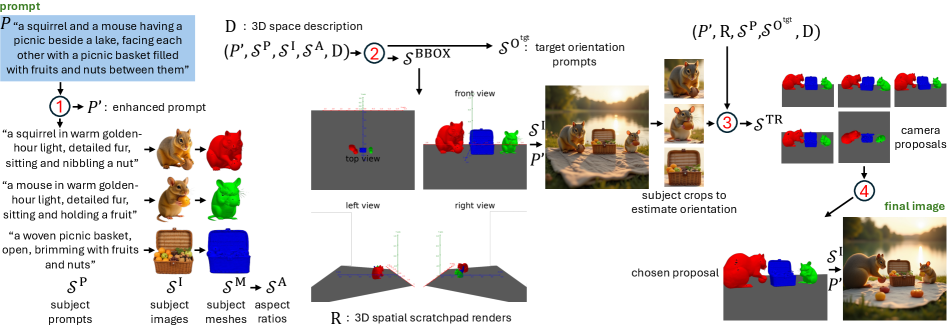
“Пространственный Черновик” представляет собой трехмерную подложку для рассуждений, предназначенную для преобразования лингвистических запросов в визуальные синтезы. Данная система функционирует как промежуточное звено между текстовым описанием сцены и её последующей визуализацией, позволяя эффективно интерпретировать намерения, выраженные в языке, и транслировать их в трехмерное пространство. В основе лежит концепция создания внутренней репрезентации сцены, которая затем используется для генерации изображения, обеспечивая более точное и осмысленное соответствие между запросом и результатом. Это достигается за счет декомпозиции сложных запросов и последующего формирования согласованной трехмерной структуры.
Система использует агентский подход, разбивая сложные запросы на отдельные объекты и элементы фона посредством LLM-агента (Идентификация Объектов). Этот агент анализирует входящий запрос и выделяет ключевые сущности, определяя их роль в будущей сцене — являются ли они главными объектами, фоновыми элементами или частью окружения. Процесс идентификации включает в себя семантический анализ текста запроса для точного определения объектов и их характеристик, что необходимо для последующего планирования их размещения в трехмерном пространстве и создания реалистичной визуализации. Разложение сложных запросов на отдельные компоненты позволяет системе эффективно управлять сложностью сцены и обеспечивать согласованность визуального результата с исходным текстовым описанием.
Агент планирования размещения (LLM Agent (Placement Planning)) осуществляет стратегическое позиционирование идентифицированных объектов и элементов фона в трехмерном пространстве. Этот процесс включает определение координат и ориентации каждого элемента относительно других, формируя базовое представление сцены (Scene Representation). Позиционирование основывается на семантических связях между элементами, полученных от агента идентификации субъектов, и направлено на создание пространственно-логичной и визуально-согласованной структуры. Результатом является структурированное представление сцены, которое служит основой для последующей визуализации и рендеринга.
Пространственная Записная Книжка использует условие глубины (Depth Condition) для обеспечения пространственной согласованности и реалистичности генерируемых изображений. Данный механизм контролирует взаимное расположение объектов в трехмерном пространстве, основываясь на их предполагаемой глубине относительно камеры и друг друга. Это позволяет избежать пересечений объектов, неестественных перспектив и других визуальных артефактов, которые могут возникнуть при произвольном размещении элементов. Условие глубины применяется как во время планирования размещения объектов (Placement Planning), так и в процессе финальной визуализации, гарантируя, что сгенерированное изображение соответствует принципам трехмерной геометрии и выглядит правдоподобно.
Уточнение Сцены: Трансформация и Точка Обзора
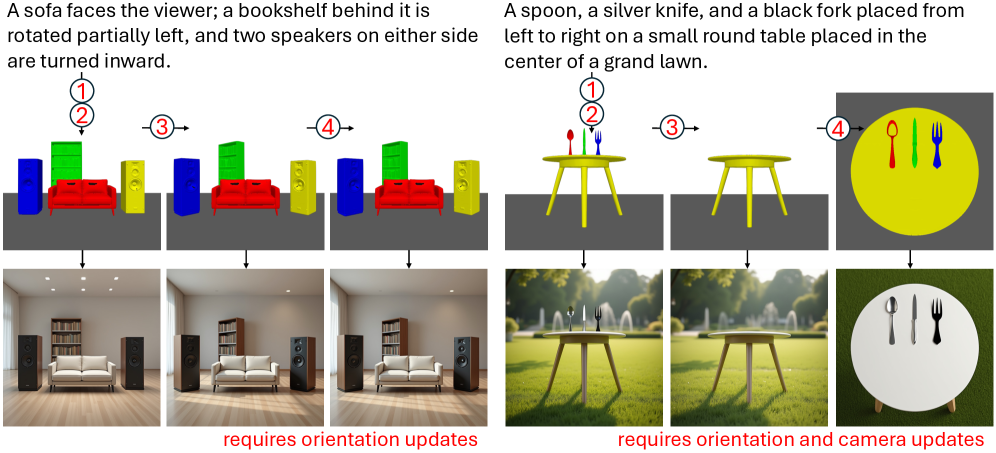
Агент LLM (Корректировка Трансформаций) осуществляет точную настройку трехмерных трансформаций — вращения, перемещения и масштабирования — каждого объекта в представлении сцены. Этот процесс включает в себя анализ относительного положения и ориентации объектов для обеспечения реалистичного взаимодействия между ними. Настройка трансформаций критически важна для предотвращения пересечений объектов, неестественных поз и других визуальных артефактов, что необходимо для создания правдоподобной сцены. Алгоритм учитывает физические ограничения и вероятные взаимодействия объектов, оптимизируя их положение в трехмерном пространстве.
Коррекция 3D-трансформаций — вращения, переноса и масштабирования — каждого объекта в сцене критически важна для сохранения его идентичности и предотвращения искажений в процессе рендеринга. Неточности в этих параметрах могут приводить к неестественным деформациям или потере узнаваемых черт объекта, что негативно сказывается на реалистичности и визуальном качестве итогового изображения. Точная настройка трансформаций обеспечивает соответствие объектов их предполагаемому виду и пропорциям, способствуя поддержанию визуальной целостности и достоверности всей сцены.
Агент LLM (Выбор Камеры) определяет оптимальную точку обзора камеры, что оказывает существенное влияние на финальную композицию и визуальное восприятие изображения. Этот процесс включает в себя анализ расположения объектов в трехмерном пространстве и выбор параметров камеры — угла обзора, высоты и расстояния до сцены — для достижения желаемого эстетического эффекта и акцентирования ключевых элементов композиции. Оптимизация точки обзора направлена на максимизацию визуального воздействия и создание сбалансированной, привлекательной картинки, соответствующей заданным критериям качества.
Окончательно откорректированная 3D-сцена передается в модель генерации изображений для создания финального изображения. Этот процесс включает в себя рендеринг трехмерной сцены с использованием параметров, определенных на предыдущих этапах, таких как положение объектов, освещение и текстуры. Модель генерации изображений преобразует трехмерное представление в двумерное изображение, которое затем может быть сохранено или отображено. Качество и реалистичность финального изображения напрямую зависят от точности 3D-сцены и возможностей используемой модели генерации изображений.

Подтверждение и Расширение Рамок
Исследования показали, что разработанная «Пространственная Черновик» демонстрирует превосходные результаты при работе со сложными композиционными запросами. Оценка проводилась на основе датасета GenAI-Bench, который позволяет комплексно оценить возможности генеративных моделей. Полученные данные свидетельствуют о значительном улучшении качества генерируемых изображений, особенно в сценариях, требующих точного расположения объектов и учета сложных пространственных взаимосвязей. Этот подход позволил добиться повышения производительности, что подтверждает эффективность предложенной архитектуры в задачах, где важна детальная проработка композиции и согласованность визуальных элементов.
Предложенная архитектура открывает новые возможности для продвинутого редактирования изображений, позволяя точно манипулировать трехмерной сценой до этапа рендеринга. Вместо традиционного двухмерного редактирования, система оперирует с полным трехмерным представлением, что обеспечивает беспрецедентный контроль над перспективой, освещением и взаимным расположением объектов. Это позволяет пользователям не просто изменять пиксели, а фактически перестраивать виртуальное пространство, добиваясь желаемого визуального результата с высокой степенью точности и реализма. Возможность предварительной настройки трехмерной сцены существенно расширяет творческий потенциал и позволяет создавать изображения, которые ранее были недостижимы с использованием стандартных инструментов редактирования.
Для всесторонней проверки возможностей Spatial Scratchpad в обработке сложных пространственных взаимосвязей и сценариев, была разработана методика использования CompoundPrompts — составных запросов, объединяющих несколько отдельных инструкций и условий. Данный подход позволяет создавать многоуровневые задачи, требующие от системы не только понимания отдельных элементов, но и их корректного размещения и взаимодействия в трехмерном пространстве. Использование CompoundPrompts позволило выявить сильные стороны Spatial Scratchpad в решении задач, требующих точного соблюдения пространственных отношений между объектами, а также в создании детализированных и логически непротиворечивых сцен. Такой подход к тестированию обеспечивает более глубокое понимание возможностей системы и позволяет оценить ее потенциал для решения сложных задач визуализации и редактирования изображений.
Для повышения качества генерируемых изображений применялись методы улучшения текстовых запросов. Эти техники позволяют детализировать и уточнять исходные инструкции, предоставляя модели более чёткое представление о желаемом результате. В ходе исследований было установлено, что даже незначительные корректировки в формулировках запросов существенно влияют на сложность и реалистичность создаваемых изображений. Улучшение запросов позволяет модели более точно интерпретировать намерения пользователя и избегать двусмысленности, что приводит к генерации более детализированных и соответствующих ожиданиям визуальных представлений. Этот подход не требует изменений в самой архитектуре модели, а лишь оптимизирует входные данные, что делает его эффективным и экономичным способом повышения качества генерируемых изображений.
Результаты тестирования Spatial Scratchpad на наборе данных GenAI-Bench продемонстрировали значительный прогресс в генерации изображений — улучшение на 32% по сравнению с существующими подходами. Примечательно, что данное повышение производительности достигнуто без необходимости дополнительного обучения модели, что указывает на эффективность предложенной архитектуры и её способность эффективно использовать существующие знания. Это свидетельствует о том, что Spatial Scratchpad способен более точно интерпретировать сложные текстовые запросы и преобразовывать их в визуально соответствующие изображения, предлагая новый уровень контроля и детализации в процессе генерации контента.

Исследование демонстрирует, что внедрение трехмерного пространственного буфера для генерации изображений из текста позволяет добиться большей непротиворечивости и точности композиции. Это соответствует стремлению к математической чистоте алгоритмов, где каждое действие должно быть логически обосновано и предсказуемо. Как заметил Эндрю Ын: «Машинное обучение — это искусство того, чтобы компьютеры учились без явного программирования». В данном случае, трехмерный буфер выступает не просто инструментом для визуализации, а средой для логического планирования и сохранения идентичности объектов, обеспечивая корректность и доказуемость получаемого результата, что принципиально важно для создания надежных и предсказуемых систем.
Куда Ведет Этот Путь?
Представленная работа, хотя и демонстрирует перспективность использования трехмерного пространства как промежуточного этапа в генерации изображений по текстовому описанию, лишь слегка приоткрывает завесу над истинной проблемой — не просто воспроизведением визуальной информации, но и её детерминированным построением. Устойчивость к малейшим вариациям входных данных, воспроизводимость результатов — вот где кроется подлинный вызов. Если алгоритм не способен гарантировать идентичный результат при идентичном вводе, говорить о “понимании” задачи представляется преждевременным.
Очевидным ограничением остается сложность формализации “идентичности” объектов в трехмерном пространстве. Текущие подходы полагаются на эмпирические наблюдения и статистические закономерности, что в конечном итоге приводит к непредсказуемым ошибкам. Необходима разработка строгих математических моделей, описывающих инвариантные свойства объектов, не зависящие от ракурса или освещения. Иначе, “сохранение идентичности” останется лишь иллюзией, созданной статистической вероятностью.
В будущем, возможно, следует переосмыслить саму концепцию “генерации” изображений. Вместо создания новых пикселей, целесообразно сосредоточиться на построении логических структур, описывающих сцену. Изображение, в таком случае, станет лишь визуализацией этой структуры, а не результатом случайного процесса. Такой подход, хоть и сложен в реализации, позволит добиться истинной детерминированности и предсказуемости, что является необходимым условием для создания действительно интеллектуальных систем.
Оригинал статьи: https://arxiv.org/pdf/2601.14602.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- 10 лучших OLED ноутбуков. Что купить в июне 2026.
- Российский рынок: от инфляции к инвестициям: что ждет инвесторов? (11.06.2026 02:32)
- vivo S60 ОБЗОР: скоростная зарядка, объёмный накопитель, современный дизайн
- Как сделать фотографию резкой.
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Прогнозы цен на CC: анализ криптовалюты CC
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Обзор Motorola Edge 50 Fusion
- Мозг будущего: 6G и нейроинтерфейсы
- Синхронизация вспышки. Что такое Sync speed и режим FP.
2026-01-23 01:55