Автор: Денис Аветисян
Исследование представляет архитектуру Prism, объясняющую трансформеры как операторы шумоподавления, основанные на принципах теории информации и геометрии.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"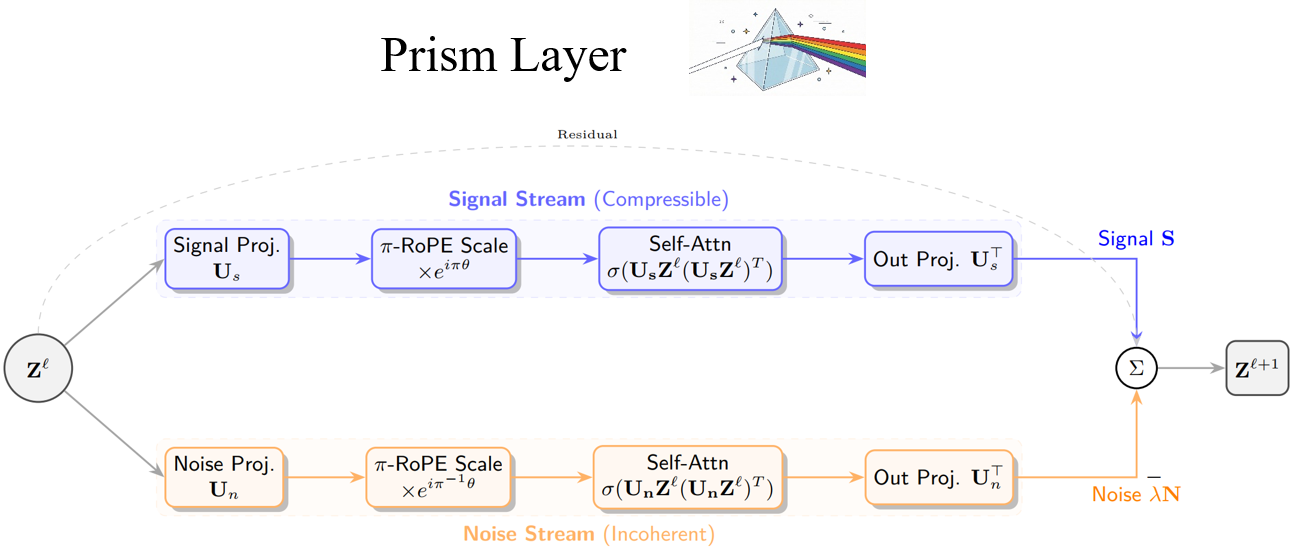
Разделение спектров семантической и синтаксической информации с помощью избыточных словарей и π-RoPE обеспечивает функциональное разделение и повышает стабильность модели.
Несмотря на впечатляющие успехи, архитектура Transformer часто воспринимается как «черный ящик», лишенный прозрачности и интерпретируемости. В настоящей работе, озаглавленной ‘PRISM: Deriving the Transformer as a Signal-Denoising Operator via Maximum Coding Rate Reduction’, предложена новая архитектура Prism, основанная на принципах максимизации снижения скорости кодирования (\text{MCR}^2) и рассматривающая механизм внимания как процесс градиентного подъема на многообразии сигнал-шум. Показано, что введение избыточного словаря и нерационального разделения частот (π-RoPE) позволяет добиться неконтролируемого функционального разделения и улучшить стабильность модели. Возможно ли, таким образом, преодолеть дихотомию между производительностью и интерпретируемостью в глубоком обучении?
Предел масштабируемости: Трансформеры и провал внимания
Несмотря на значительные успехи, стандартные архитектуры Transformer демонстрируют ограничения в обработке длинных последовательностей данных, подвергаясь явлению, известному как “Attention Sink”. Суть этого феномена заключается в том, что по мере увеличения длины входного текста, модель начинает терять способность эффективно фокусироваться на наиболее релевантной информации. Вместо этого, внимание распределяется неравномерно, отдавая предпочтение более ранним элементам последовательности или вовсе рассеиваясь, что приводит к снижению точности и ухудшению результатов в задачах, требующих понимания контекста. Данное ограничение становится особенно заметным при работе с текстами, содержащими сложные зависимости и требующими глубокого анализа взаимосвязей между различными частями информации.
Квадратичный рост вычислительных затрат в зависимости от длины последовательности представляет собой фундаментальное ограничение для стандартных архитектур Transformer. Это означает, что при увеличении количества токенов во входных данных, требуемые вычислительные ресурсы растут пропорционально квадрату этой длины O(n^2). В результате, обработка длинных последовательностей становится непомерно дорогой и замедляет процесс обучения и инференса. Это затрудняет эффективную обработку информации в контекстах, требующих анализа больших объемов данных, таких как длинные тексты, видео или аудиопотоки. По сути, архитектура сталкивается с проблемой, когда количество необходимых вычислений растет быстрее, чем объем полезной информации, извлекаемой из входных данных, что приводит к снижению производительности и эффективности.
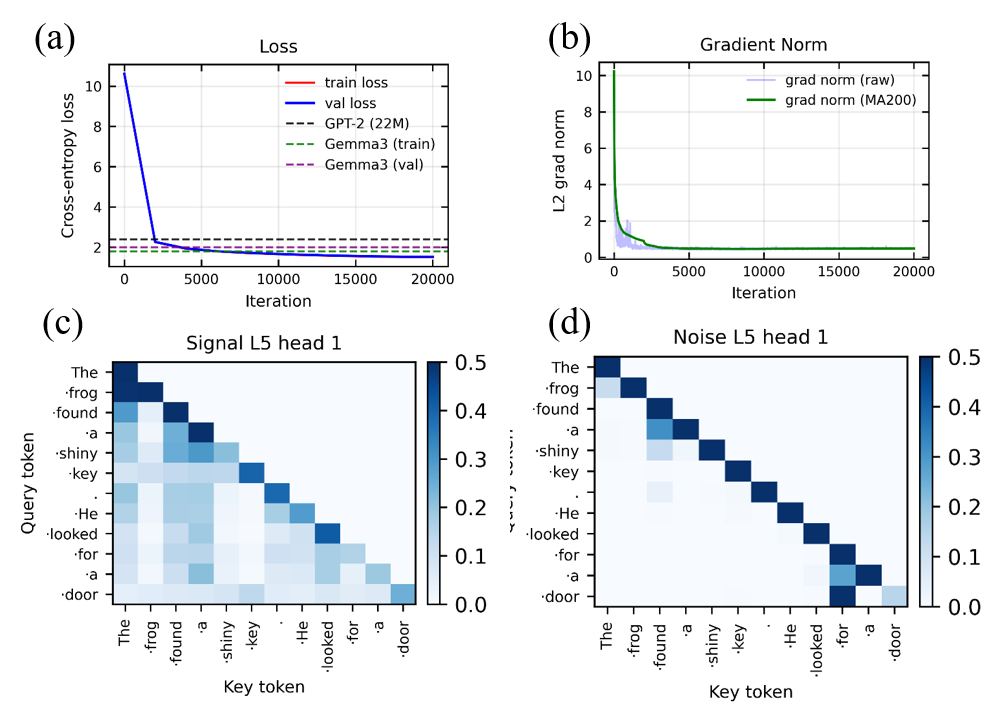
Попытки улучшить производительность Transformer-моделей за счет простого увеличения количества параметров демонстрируют закономерное снижение эффективности. Хотя стандартная модель GPT-2 с 22 миллионами параметров способна обеспечить базовый уровень обработки информации, более новая архитектура Prism, содержащая 50 миллионов параметров, превосходит её по показателям. Данное наблюдение указывает на то, что увеличение масштаба модели само по себе не является решением фундаментальной проблемы — ограниченной способности эффективно обрабатывать длинные последовательности данных. Вместо этого, необходимы инновационные подходы к архитектуре и механизмам внимания, позволяющие преодолеть узкое место, связанное с квадратичным ростом вычислительных затрат при увеличении длины входной последовательности.
Частотное разделение: Вдохновленные физикой решения
Архитектура Prism представляет собой новый подход к обработке информации, вдохновленный принципами физики и использующий геометрические ограничения. В основе данного подхода лежит идея моделирования взаимодействия данных посредством аналогий с физическими системами, что позволяет оптимизировать процесс обработки и повысить эффективность. Использование геометрических ограничений обеспечивает структурированность данных и позволяет более эффективно решать задачи, требующие учета пространственных отношений и связей между элементами. Такой подход позволяет снизить вычислительную сложность и повысить устойчивость системы к шумам и помехам, что особенно важно при работе с большими объемами данных и в реальном времени.
В основе архитектуры Prism лежит принцип частотного разделения, реализуемый посредством масштабируемых вращающихся позиционных вложений (π-RoPE). π-RoPE позволяет разделить входные данные на различные частотные компоненты, обрабатывая их независимо друг от друга. Это достигается за счет применения вращающих матриц к векторам позиционных вложений, что позволяет модели эффективно кодировать и декодировать информацию, зависящую от позиции токенов во входной последовательности. Использование масштабирования в π-RoPE позволяет контролировать влияние различных частотных компонентов, оптимизируя производительность модели и обеспечивая более точное представление данных.
В основе π-RoPE лежит использование принципов, заимствованных из теории диофантовых чисел. Диофантовы числа, представляющие собой целые числа, возникающие в решении диофантовых уравнений, обеспечивают специфические свойства масштабирования и интерференции. Применение этих принципов в π-RoPE позволяет создавать вращающиеся позиционные вложения, которые эффективно разделяют частотные компоненты входных данных. Это разделение снижает вероятность возникновения резонанса в частотной области, что повышает устойчивость модели и предотвращает нежелательные артефакты при обработке данных. Масштабирование, основанное на диофантовых числах, гарантирует, что различные частоты обрабатываются с оптимальным разрешением, минимизируя искажения и обеспечивая точное представление информации в частотном спектре.
Геометрические ограничения и эффективное представление
В архитектуре Prism используется “переполненный словарь” (overcomplete dictionary) для расширения репрезентативного пространства, что позволяет более эффективно разделять полезный сигнал и шум. Данный подход заключается в представлении входных данных в виде линейной комбинации большего количества базисных функций, чем необходимо для минимального представления. Это создает избыточность, но позволяет выделить значимые признаки сигнала, даже если они зашумлены. Фактически, избыточность обеспечивает более надежную кодировку информации и устойчивость к помехам, улучшая качество представления данных и способствуя более точной обработке.
Архитектура Prism использует эффективные вычислительные примитивы, такие как FlashAttention, для ускорения обработки данных. FlashAttention — это алгоритм, оптимизирующий вычисление механизма внимания O(n^2), снижая сложность до O(n) за счет использования чередования между обработкой запросов и ключей/значений. Это достигается путем разбиения операций на блоки и использования более эффективного доступа к памяти, что значительно уменьшает потребление памяти и время выполнения, особенно при обработке длинных последовательностей. Использование FlashAttention позволяет Prism обрабатывать более крупные модели и последовательности данных с меньшими задержками, повышая общую производительность и эффективность.
Масштабирование модели Prism достигается за счет использования слоев «Mixture of Experts» (MoE). Вместо использования одной большой нейронной сети, MoE слои состоят из нескольких «экспертов» — небольших нейронных сетей. Для каждого входного токена специальный «router» (маршрутизатор) выбирает один или несколько экспертов для обработки. Это позволяет значительно увеличить емкость модели — количество параметров — без пропорционального увеличения вычислительных затрат, поскольку на каждый токен активируется лишь часть экспертов. Эффективность достигается за счет распараллеливания вычислений и снижения общей вычислительной нагрузки, что делает возможным обучение и инференс моделей с большим количеством параметров.
Функциональная специализация и CRATE-фреймворк
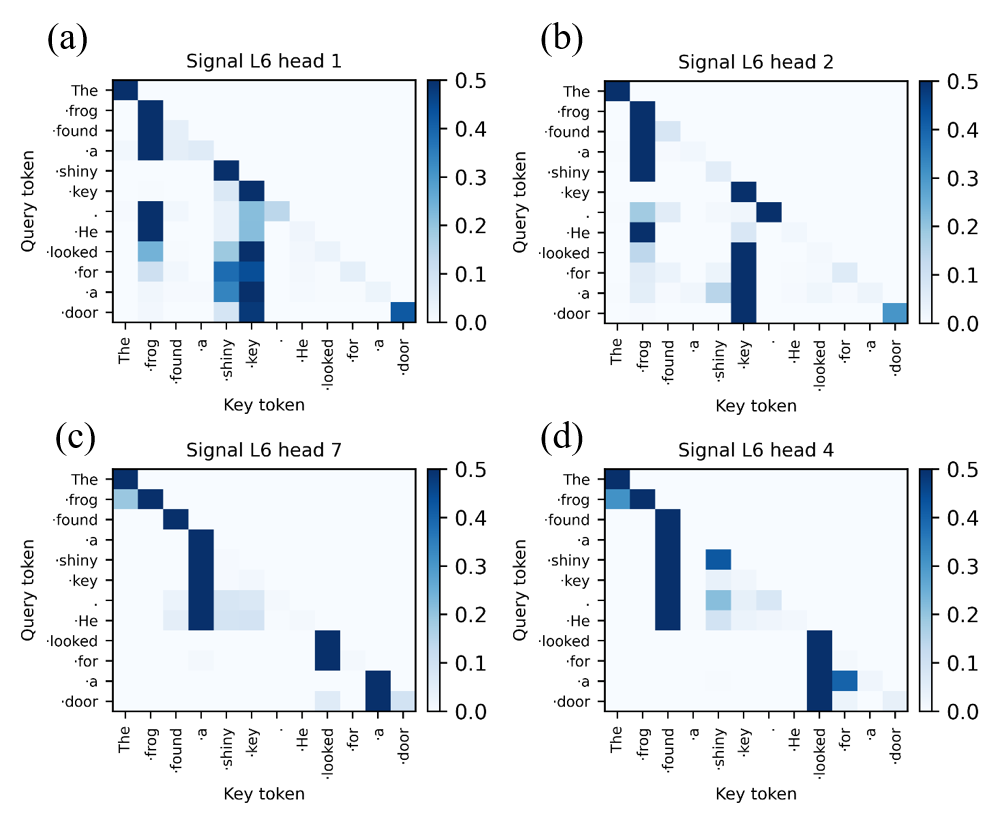
Эмпирические результаты, полученные в ходе исследований архитектуры Prism, демонстрируют явление функциональной специализации внутри её голов (heads). Наблюдается, что отдельные головки самовнимания спонтанно развивают чётко выраженные функции, что свидетельствует о высокой степени модульности системы. Вместо того чтобы обрабатывать информацию универсально, различные головки концентрируются на специфических аспектах данных, подобно экспертам в различных областях. Такая организация позволяет архитектуре Prism эффективно решать сложные задачи, используя меньше параметров и демонстрируя повышенную устойчивость к шуму. Проявление функциональной специализации указывает на то, что Prism не просто запоминает данные, а активно строит внутреннее представление о мире, разделяя информацию на значимые компоненты.
Исследования показали, что механизм самовнимания, лежащий в основе современных нейронных сетей, оптимизирует процесс так называемого «уменьшения скорости передачи данных» — максимизации полезного сигнала и минимизации шума. Этот принцип, сформулированный в рамках CRATE-фреймворка, предполагает, что эффективное обучение требует не просто обработки информации, но и её сжатия и фильтрации. По сути, нейронная сеть стремится передавать наиболее важные данные с минимальными издержками, что повышает её устойчивость к помехам и позволяет более эффективно использовать ресурсы. Таким образом, самовнимание выступает не просто как механизм установления связей между различными частями входных данных, а как способ оптимизации передачи информации и повышения общей эффективности обучения модели.
Архитектура Prism, состоящая всего из 50 миллионов параметров, демонстрирует принципы сжатия данных и максимального снижения скорости кодирования (MCR), что указывает на более эффективный и устойчивый процесс обучения. Достигнутая валидационная ошибка в районе 1.55 на наборе данных TinyStories свидетельствует о способности модели к обобщению и сохранению информации при относительно небольшом количестве параметров. Данный подход позволяет снизить вычислительные затраты и повысить надежность системы, поскольку уменьшается риск переобучения и требуется меньше данных для достижения сопоставимых результатов. По сути, Prism оптимизирует представление данных, концентрируясь на наиболее значимых сигналах и отфильтровывая шум, что обеспечивает высокую производительность и устойчивость к помехам.
К механистической интерпретируемости и за её пределы
Архитектурные принципы, заложенные в основу системы Prism, способствуют достижению так называемой «Механистической Интерпретируемости» — способности детально понимать, как нейронные сети обрабатывают информацию на каждом этапе своей работы. В отличие от традиционных «черных ящиков», Prism позволяет исследователям не просто наблюдать за результатом, но и проследить логику принятия решений внутри сети, выявляя конкретные нейроны и связи, ответственные за определенные функции. Такой подход открывает возможности для диагностики ошибок, оптимизации производительности и создания более надежных и предсказуемых систем искусственного интеллекта, позволяя увидеть внутреннюю «механику» работы нейронной сети и, как следствие, значительно улучшить её понимание и контроль.
Анализ спектрального разделения с использованием потока градиента Вассерштейна позволяет значительно углубить понимание внутренней динамики нейронных сетей. Данный подход, основанный на принципах оптимального транспорта, предоставляет инструменты для изучения того, как информация преобразуется и распространяется внутри модели. Поток градиента Вассерштейна, в отличие от традиционных методов, позволяет отслеживать эволюцию распределений активаций в пространстве признаков, выявляя закономерности и зависимости между различными слоями сети. Это, в свою очередь, способствует более детальному пониманию того, какие функции выполняются каждым слоем и как они взаимодействуют друг с другом для достижения конечного результата. Благодаря этому, становится возможным не только диагностировать проблемы в работе сети, но и целенаправленно модифицировать ее структуру для повышения эффективности и надежности.
Архитектура Prism, вдохновленная принципами физики, открывает новые горизонты в создании искусственного интеллекта, отличающегося повышенной эффективностью, устойчивостью и прозрачностью. В отличие от традиционных подходов, Prism стремится к построению систем, функционирование которых можно понять и предсказать, что критически важно для областей, требующих высокой надежности и доверия. Стабильность обучения, подтвержденная нормой градиента около 0.5, свидетельствует о способности системы к саморегуляции и предотвращению нежелательных отклонений от оптимального состояния. Такой подход позволяет создавать более надежные и предсказуемые модели, способные адаптироваться к изменяющимся условиям и демонстрировать высокую производительность в различных задачах, приближая искусственный интеллект к уровню понимания и контроля, сопоставимого с естественными системами.
Наблюдатель, повидавший не один релиз, отмечает, что концепция Prism, с её акцентом на разделение семантической и синтаксической информации, лишь подтверждает старую истину: элегантные теоретические построения неизбежно сталкиваются с суровой реальностью продакшена. Авторы стремятся к функциональному разделению, используя переполные словари и π-RoPE, надеясь на повышение стабильности. И это напоминает о словах Марвина Минского: «Любая достаточно развитая технология неотличима от магии». Магия, конечно, быстро превращается в техдолг, но в данном случае, возможно, удастся немного отсрочить неизбежное, прежде чем очередной кластер выйдет из строя. В конце концов, мы не чиним продакшен — мы просто продлеваем его страдания.
Что Дальше?
Представленная работа, безусловно, элегантна. Построение Transformer на фундаменте теории информации и геометрии — занятное упражнение. Но давайте будем честны: «разложение» семантики и синтаксиса с помощью «переполных» словарей — это лишь ещё один способ усложнить то, что рано или поздно сломается в продакшене. Несомненно, π-RoPE — красивое решение, но история учит, что любая «революционная» позиционная кодировка — это временная передышка перед неизбежным столкновением с данными, которые не вписываются в теоретическую модель.
Настоящий вызов — не в улучшении архитектуры, а в понимании того, что вообще происходит внутри этих чёрных ящиков. Функциональное разделение — это хорошо, но кто сказал, что «разделение» — это вообще то, что нужно? Возможно, вся эта «функциональность» — иллюзия, порождённая переобучением на датасетах, которые не отражают реальную сложность мира. Всё новое — это старое, только с другим именем и теми же багами.
В перспективе, вероятно, нас ждёт не очередная «улучшенная» Transformer, а принципиально иной подход. Возможно, потребуется отказаться от идеи «обучения представлений» вообще и искать способы построения систем, которые работают с данными напрямую, без посредничества этих сложных, хрупких конструкций. Если всё работает — просто подожди. Продакшен — лучший тестировщик.
Оригинал статьи: https://arxiv.org/pdf/2601.15540.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Российский рынок: от инфляции к инвестициям: что ждет инвесторов? (11.06.2026 02:32)
- Как сделать фотографию резкой.
- 10 лучших OLED ноутбуков. Что купить в июне 2026.
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Прогнозы цен на CC: анализ криптовалюты CC
- Обзор Motorola Edge 50 Fusion
- Режимы автофокуса. Как настроить автофокус.
- Обзор Nikon D5500 DX
2026-01-24 09:45