Автор: Денис Аветисян
Новое исследование углубляется в методы кодирования положения в Vision Transformers, оценивая эффективность различных маскировок внимания и токенов-резюме.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"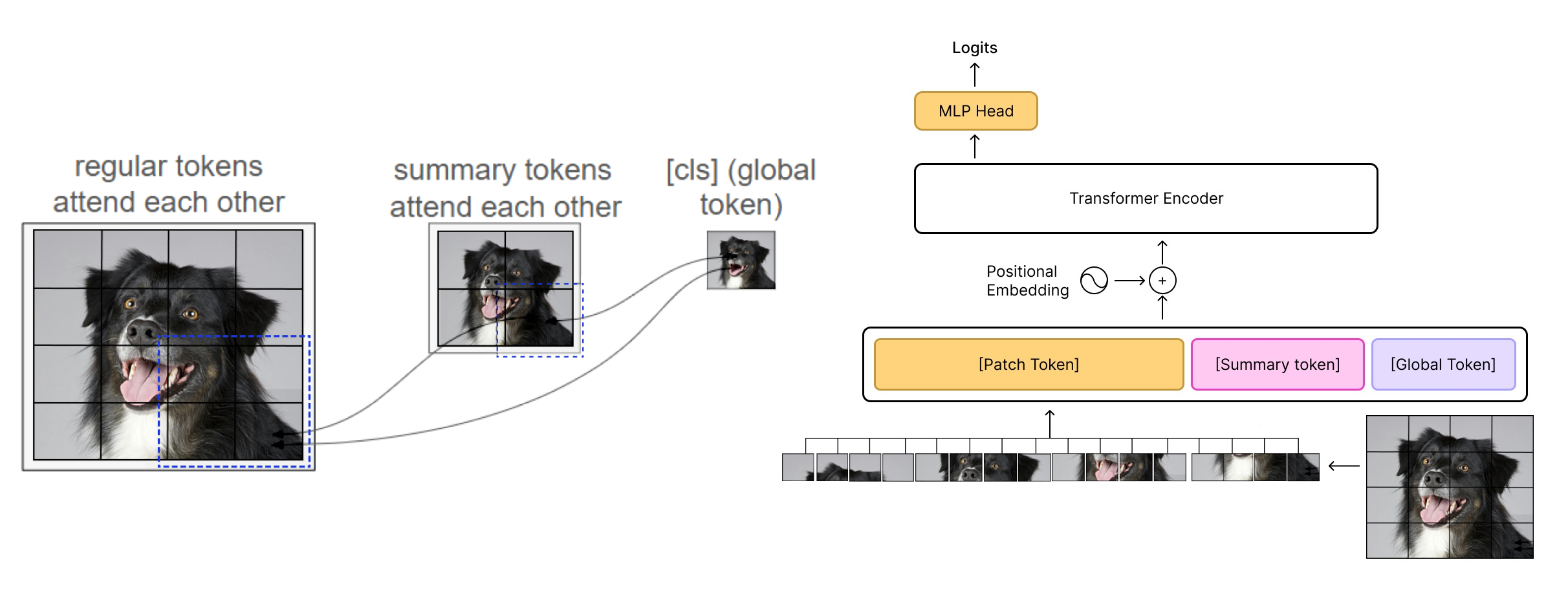
Анализ схем позиционного кодирования, включая Fractal ViT, NoPos и использование токенов-маркеров, показывает ограниченный эффект от дополнительных элементов в текущих конфигурациях.
Несмотря на успехи Vision Transformer (ViT) в задачах компьютерного зрения, вопросы оптимального кодирования позиционной информации остаются открытыми. В данной работе, ‘ViT Registers and Fractal ViT’, исследуется влияние дополнительных «регистровых» токенов и фрактальных масок внимания на производительность ViT, вдохновленные недавними наблюдениями об эффективности трансформеров без позиционного кодирования. Полученные результаты демонстрируют, что предложенные схемы кодирования, использующие дополнительные токены и фрактальные маски, не приводят к улучшению показателей по сравнению со стандартным ViT с регистровыми токенами. Какие факторы определяют эффективность различных схем позиционного кодирования в архитектурах Vision Transformer и как можно адаптировать их к различным задачам и масштабам?
Визуальные Трансформеры: Масштабируемость и Позиционная Инвариантность
Визуальные трансформаторы (ViT) представляют собой мощную альтернативу сверточным нейронным сетям, однако их эффективное масштабирование сопряжено с определенными трудностями. Основная проблема заключается в вычислительной сложности механизма внимания, который, хотя и обеспечивает превосходную производительность, требует значительных ресурсов при обработке изображений высокого разрешения. По мере увеличения размера входных данных и количества патчей, необходимых для анализа изображения, вычислительная нагрузка растет квадратично, что ограничивает возможности ViT в задачах, требующих обработки больших объемов визуальной информации. В результате, для реализации потенциала ViT в практических приложениях необходимо разрабатывать новые методы оптимизации и снижения вычислительной стоимости механизма внимания, либо искать альтернативные архитектуры, сохраняющие высокую производительность при меньших вычислительных затратах.
Ключевая сложность при использовании Vision Transformers (ViT) заключается в обеспечении инвариантности к перестановкам — способности модели корректно интерпретировать пространственные взаимосвязи внутри изображения. В отличие от сверточных нейронных сетей, которые по своей архитектуре учитывают локальную структуру, ViT обрабатывает изображение как последовательность патчей, порядок которых может влиять на результат. Поэтому для успешного анализа изображений, ViT нуждается в эффективном методе кодирования положения (positional encoding), позволяющем модели понимать, как различные патчи связаны друг с другом в пространстве. Отсутствие такой информации привело бы к тому, что модель не смогла бы различать изображения, полученные путем перестановки их частей, что существенно снизило бы точность распознавания объектов и сцен.
Первоначальные эксперименты со стандартными методами позиционного кодирования в Vision Transformers выявили ряд ограничений, связанных с эффективностью и масштабируемостью. Исследования показали, что традиционные подходы не всегда способны адекватно передать информацию о пространственном расположении элементов изображения, что негативно сказывается на производительности модели, особенно при обработке изображений высокого разрешения. Данные недостатки стимулировали поиск более надежных и эффективных альтернатив, направленных на улучшение способности модели понимать и использовать пространственную информацию, что стало ключевым направлением дальнейших исследований в области архитектур Vision Transformers.
Неожиданные результаты, полученные в области обработки естественного языка, показали, что вполне возможно достичь высокой производительности моделей даже без использования позиционного кодирования (NoPos). Этот факт вызвал закономерный вопрос о том, какие компоненты действительно необходимы для эффективной обработки последовательностей. Исследования, проведенные в рамках данной работы, продемонстрировали, что в задачах компьютерного зрения различные схемы позиционного кодирования — включая усвоенные, 2D-ALiBi и синусоидальные — обеспечивают сопоставимые результаты на наборе данных ImageNet-1k. Полученные данные указывают на то, что, хотя позиционное кодирование играет важную роль, конкретный выбор метода не оказывает существенного влияния на общую производительность моделей-трансформеров в задачах классификации изображений.
Позиционное Кодирование: Преодолевая Традиционные Ограничения
Стандартные методы позиционного кодирования, такие как Sincos2d и RoPE, обеспечивают информацию о пространственном расположении элементов, однако их вычислительная сложность становится узким местом при увеличении разрешения изображений. Это связано с тем, что эти методы обычно требуют вычисления позиционных кодов для каждого пикселя или патча изображения, что приводит к квадратичному росту вычислительных затрат и потребления памяти по отношению к размеру входного изображения. В результате, при обработке изображений высокого разрешения, применение этих методов становится неэффективным и ограничивает масштабируемость моделей, использующих их для обработки визуальной информации.
В качестве альтернативы традиционным методам позиционного кодирования, таким как Sinusoidal и RoPE, исследователи изучили подход Attention with Linear Biases (ALiBi) и его двухмерное расширение (2D-ALiBi). ALiBi использует концепцию относительной позиционной информации, что позволяет модели оценивать расстояние между токенами, а не абсолютное положение. Внедрение контрастивных целей в процесс обучения и учет симметрии группы E(2) способствуют повышению эффективности модели. Использование относительных смещений вместо абсолютных позиций потенциально снижает вычислительную сложность и улучшает обобщающую способность модели, особенно при работе с изображениями высокого разрешения.
Несмотря на эффективность альтернативных методов позиционного кодирования, таких как ALiBi и 2D-ALiBi, в больших Vision Transformer (ViT) возникают определенные сложности, связанные с феноменом «attention sinks» и появлением «outlier tokens». «Attention sinks» — это токены, которые необоснованно притягивают внимание, искажая распределение весов и снижая качество обработки. «Outlier tokens» — это токены, демонстрирующие аномально высокие значения внимания, что также нарушает работу механизма внимания и негативно влияет на производительность модели. Наблюдается, что эти явления особенно выражены при увеличении размера ViT и требуют разработки новых архитектурных решений для обеспечения стабильной и эффективной работы механизма внимания.
В ходе исследований больших Vision Transformer (ViT) были выявлены так называемые «выбросы» — токены, демонстрирующие аномально высокие оценки внимания. Данные токены способны нарушать работу механизма внимания, ухудшая общую производительность модели. Предпринятые попытки смягчить эту проблему путем добавления дополнительных токенов (регистров или суммарных токенов) с использованием позиционного кодирования не привели к существенному улучшению результатов на датасете ImageNet-1k, демонстрируя прирост всего в 1-2 стандартных отклонения по сравнению с базовой моделью. Это указывает на необходимость поиска новых архитектурных решений для более эффективной обработки позиционной информации и стабилизации работы механизма внимания в больших моделях.
Fractal ViT: Новая Архитектура для Эффективного Внимания
Архитектура Fractal ViT использует специализированные токены, называемые «summary tokens», для агрегации информации по всему изображению. Эти токены функционируют как глобальный контекст, позволяя модели учитывать взаимосвязи между различными областями изображения. В отличие от стандартных Vision Transformers, где каждый патч обрабатывается независимо, summary tokens позволяют эффективно кодировать информацию о расположении и взаимосвязях между патчами, что способствует более полному пониманию изображения и повышению точности модели. Количество summary tokens является гиперпараметром, определяющим степень агрегации информации и вычислительную сложность.
В архитектуре Fractal ViT маскирование внимания применяется для управления взаимодействием между токенами, что позволяет «саммари-токенам» эффективно кодировать позиционную информацию и снижать вычислительные затраты. Конкретно, маскирование ограничивает область внимания, предотвращая взаимодействие между всеми токенами и фокусируя внимание «саммари-токенов» на релевантных участках изображения. Это достигается путем определения матрицы маски, которая указывает, какие пары токенов могут взаимодействовать друг с другом во время вычисления внимания. Ограничение области внимания не только уменьшает сложность вычислений, но и способствует более стабильному обучению, поскольку уменьшается влияние от выбросов и нерелевантной информации. Таким образом, стратегическое применение маскирования внимания является ключевым компонентом эффективности и масштабируемости Fractal ViT.
В архитектуре Fractal ViT для повышения стабильности модели добавлены так называемые «регистры» — временные токены, которые не участвуют в конечном вычислении, но используются для подавления влияния выбросов (outlier tokens) в процессе внимания. Эти токены, по сути, служат «шумом», снижающим чувствительность механизма внимания к аномальным значениям входных данных. Добавление регистров позволяет уменьшить дисперсию результатов и повысить надежность модели, особенно при работе с изображениями, содержащими артефакты или нетипичные паттерны. Их роль заключается в обеспечении более устойчивой работы механизма внимания, не оказывая влияния на конечный результат классификации.
Архитектура Fractal ViT продемонстрировала свою эффективность на датасете ImageNet-1k, представляя собой потенциальный путь к созданию более эффективных и масштабируемых Vision Transformers. Наблюдаемая точность Top-1 на валидационном наборе данных оказалась незначительно выше базового уровня, однако добавление summary и register токенов привело лишь к небольшому улучшению результатов — в пределах 1-2 стандартных отклонений. Это указывает на то, что предложенная архитектура может обеспечить небольшое повышение производительности без существенного увеличения вычислительных затрат, что важно для практического применения в задачах компьютерного зрения.
Последствия и Перспективы Развития
Успех архитектуры Fractal ViT демонстрирует, что тщательно разработанные инновации в структуре нейронной сети могут оказаться более эффективными, чем простое увеличение её размера или применение сложных схем кодирования позиций. Исследование показывает, что фокусировка на оптимизации внутренней организации модели, а не на наращивании вычислительных ресурсов, способна привести к значительным улучшениям в производительности и эффективности. Вместо того чтобы полагаться на грубую силу масштабирования, Fractal ViT предлагает элегантный подход, позволяющий достичь сопоставимых, а в некоторых случаях и превосходящих результатов, используя более компактную и оптимизированную структуру. Этот подход открывает новые перспективы в области компьютерного зрения, подчеркивая важность интеллектуального проектирования архитектур, а не только увеличения их сложности.
Концепция суммарных токенов представляет собой эффективный механизм агрегации информации и снижения вычислительных затрат, что выходит за рамки задач компьютерного зрения. В основе лежит идея сжатия информации из различных частей входных данных в компактное представление, которое затем используется для последующей обработки. Данный подход позволяет значительно уменьшить объем вычислений, особенно при работе с большими изображениями или последовательностями, сохраняя при этом важные детали. Помимо анализа изображений, суммарные токены могут найти применение в обработке естественного языка, анализе временных рядов и других областях, где требуется эффективное сжатие и агрегация информации для уменьшения нагрузки на вычислительные ресурсы и повышения скорости обработки данных.
Дальнейшие исследования могут быть направлены на интеграцию методов разреженного внимания в архитектуру Fractal ViT. Такой подход позволит значительно оптимизировать вычислительные затраты и уменьшить требования к объему памяти, что особенно важно для работы с изображениями высокого разрешения и крупномасштабными наборами данных. Разреженное внимание предполагает, что не все элементы изображения нуждаются в одинаковом уровне обработки, и фокусируется на наиболее значимых областях, тем самым снижая сложность вычислений без существенной потери точности. Эксперименты с различными стратегиями разреженности, такими как фиксированные шаблоны или динамическое определение значимых областей, могут привести к созданию еще более эффективных и масштабируемых Vision Transformers, способных решать сложные задачи компьютерного зрения с меньшими ресурсами.
Разработка Fractal ViT знаменует собой важный прогресс в области Vision Transformers, предлагая путь к созданию более эффективных, масштабируемых и устойчивых моделей компьютерного зрения. В отличие от тенденции к увеличению размера моделей и сложности кодирования позиций, данная архитектура демонстрирует, что тщательно продуманные инновации в структуре сети могут привести к значительным улучшениям производительности. Это открывает перспективы для решения сложных задач обработки изображений и видео, требующих высокой точности и скорости, включая автономное вождение, медицинскую диагностику и расширенную аналитику изображений. Внедрение принципов Fractal ViT позволяет создавать системы, способные эффективно обрабатывать огромные объемы визуальных данных, что является ключевым фактором для развития передовых приложений компьютерного зрения.
Исследование, представленное в работе, демонстрирует стремление к упрощению архитектуры Vision Transformer. Авторы, изучая различные схемы позиционного кодирования, выявили, что добавление дополнительных токенов и фрактальных масок не приносит существенной пользы. Это подтверждает идею о том, что истинное совершенство достигается не за счет усложнения, а через очищение и удаление избыточного. Тим Бернерс-Ли однажды сказал: «Главная проблема — это не недостаток технологий, а недостаток понимания того, как их использовать для создания чего-то полезного для людей.». Данное утверждение резонирует с подходом, представленным в статье, где акцент делается на эффективное использование существующих механизмов внимания, а не на бесконечное добавление новых элементов. Поиск оптимального баланса между сложностью и ясностью — ключевая задача в разработке любого алгоритма, и данная работа вносит свой вклад в её решение.
Куда Дальше?
Представленная работа, несмотря на отрицательный результат в отношении предложенных модификаций позиционного кодирования, обнажает более глубокую проблему. Попытки усложнить архитектуру Vision Transformer, добавляя новые типы токенов или маски, подобны наслоению декора на трещину — проблема не исчезает, а лишь маскируется. Становится очевидным, что само понятие «позиции» в контексте визуальных данных требует переосмысления. Недостаточно просто «указать» положение; необходимо понять, как информация о положении влияет на процесс внимания.
Будущие исследования должны сосредоточиться не на увеличении количества параметров или усложнении схем кодирования, а на фундаментальном понимании принципов, лежащих в основе эффективного внимания. Возможно, ключ кроется в динамических, контекстно-зависимых схемах кодирования, которые адаптируются к конкретному изображению, а не являются статичными и предопределенными. Попытки «обогатить» представление о положении посредством добавления новых токенов оказались бесплодными; более продуктивным путем представляется поиск минимально достаточного представления, лишенного избыточности.
Отказ от усложнения, от стремления к «полному» представлению, представляется наиболее перспективным направлением. В конечном счете, истинное понимание приходит не через добавление, а через вычитание — через осознание того, что действительно необходимо, а от чего можно отказаться.
Оригинал статьи: https://arxiv.org/pdf/2601.15506.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- 10 лучших OLED ноутбуков. Что купить в июне 2026.
- Российский рынок: от инфляции к инвестициям: что ждет инвесторов? (11.06.2026 02:32)
- vivo S60 ОБЗОР: скоростная зарядка, объёмный накопитель, современный дизайн
- Как сделать фотографию резкой.
- Обзор Motorola Edge 50 Fusion
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Прогнозы цен на CC: анализ криптовалюты CC
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Что купить фотографу. Рекомендации
2026-01-25 15:58