Автор: Денис Аветисян
Новая разработка позволяет крупным языковым моделям понимать и взаимодействовать с трехмерными сценами, получая информацию из потокового видео.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"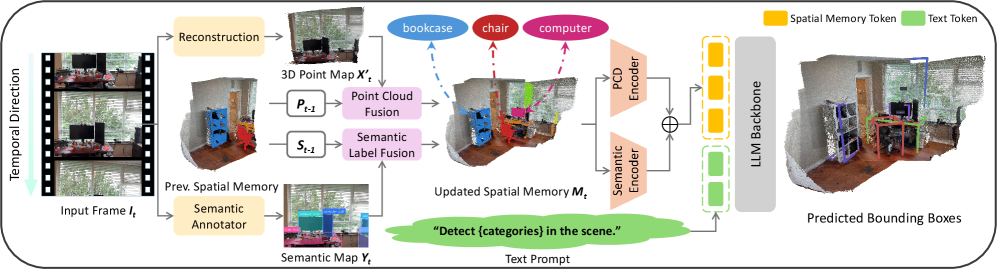
Представлена платформа OnlineSI, объединяющая обработку облаков точек с семантическим анализом для онлайн-понимания и привязки 3D-сцен.
Несмотря на растущий интерес к оснащению мультимодальных больших языковых моделей (MLLM) способностью к пространственному пониманию, большинство существующих подходов игнорируют необходимость непрерывной адаптации к динамично меняющемуся окружению и возможности развертывания на встроенных системах. В данной работе представлена система OnlineSI: Taming Large Language Model for Online 3D Understanding and Grounding, предназначенная для непрерывного улучшения пространственного понимания окружения на основе видеопотока. Ключевой особенностью является использование ограниченной пространственной памяти для сохранения прошлых наблюдений и интеграция информации из 3D-облаков точек с семантическими данными, что позволяет MLLM точнее локализовать и идентифицировать объекты в сцене. Открывает ли это путь к созданию действительно автономных агентов, способных ориентироваться и взаимодействовать с реальным миром?
Открытие Новых Горизонтов: Переход от 3D-Данных к Семантическому Пониманию
Традиционное понимание трехмерных сцен сталкивается со значительными трудностями при анализе реальных окружений, обусловленными их inherentной сложностью и неструктурированностью. В отличие от контролируемых лабораторных условий, повседневный мир характеризуется зашумленностью данных, частичной видимостью объектов и огромным разнообразием форм и текстур. Простое распознавание отдельных объектов, даже при высокой точности, недостаточно для полноценного осмысления сцены; необходим учет контекста, взаимосвязей между объектами и их функционального назначения. Например, система должна уметь отличать стул от скамьи, учитывая окружающую обстановку и вероятное использование этих предметов. Отсутствие способности к контекстуальному рассуждению приводит к ошибкам интерпретации и снижает эффективность систем компьютерного зрения в реальных приложениях, таких как автономная навигация и робототехника.
Для полноценной интерпретации трехмерных данных недостаточно простого распознавания объектов; необходима система, способная интегрировать «сырые» данные облака точек с богатой семантической информацией. Такой подход позволяет не только идентифицировать объекты, но и понимать их взаимосвязи, функции и контекст в сцене. Например, система должна уметь различать «стул» как таковой и «стул, за которым сидит человек», или определить, что «стол» является частью «обеденной зоны». Интеграция семантики позволяет перейти от простого перечня объектов к осмысленному представлению об окружающей среде, открывая возможности для более сложных задач, таких как планирование действий робота или создание интерактивных виртуальных моделей. В конечном итоге, подобный подход к обработке трехмерных данных обеспечивает более глубокое и полезное понимание окружающего мира.

SpatialLM: Многомодальная Основа для Интеллектуального Анализа Сцен
SpatialLM формирует надежную основу для анализа сцен, объединяя большую мультимодальную языковую модель (LLM) со специализированными кодировщиками для обработки трехмерных данных. В отличие от моделей, работающих непосредственно с необработанными данными, SpatialLM использует отдельные кодировщики для извлечения релевантных признаков из 3D-данных, таких как облака точек. Эти признаки затем интегрируются с семантическими вложениями, что позволяет языковой модели формировать комплексное понимание сцены и эффективно решать задачи, связанные с анализом и интерпретацией трехмерного пространства. Такой подход позволяет SpatialLM превосходить существующие модели в задачах, требующих понимания геометрии и семантики сцен.
Кодировщик точечных облаков, в частности Sonata, преобразует необработанные данные точечных облаков в значимые признаки. Sonata использует архитектуру, оптимизированную для обработки разреженных трехмерных данных, что позволяет извлекать геометрические и структурные характеристики сцены. В процессе преобразования, необработанные точки преобразуются в векторные представления, содержащие информацию о положении, нормалях и других атрибутах точек. Эти признаки служат основой для дальнейшей обработки и анализа трехмерной сцены, позволяя модели SpatialLM понимать геометрию и структуру окружения.
Для обеспечения комплексного понимания сцены, признаки, полученные из кодировщика точечных облаков, интегрируются с семантическими эмбеддингами, генерируемыми семантическим кодировщиком. Эксперименты показали, что использование признаков, полученных на основе модели Llama в семантическом кодировщике, обеспечивает незначительно более высокую производительность по сравнению с использованием признаков, полученных на основе CLIP. Данная интеграция позволяет модели SpatialLM учитывать как геометрию сцены, так и семантическое значение объектов в ней, формируя целостное представление.
OnlineSI: Онлайн-Обработка 3D-Данных в Динамичных Средах
OnlineSI представляет собой расширение SpatialLM, внедряющее систему онлайн-обработки данных и поддерживающую “Пространственную Память” (Spatial Memory). Данная память позволяет системе непрерывно обновлять и хранить представление трехмерной окружающей среды в динамичных условиях. В отличие от традиционных подходов, работающих с фиксированными наборами данных, OnlineSI способна обрабатывать поступающие данные в реальном времени, что критически важно для приложений, требующих понимания 3D-пространства в изменяющейся обстановке, например, для робототехники и автономной навигации. По сути, система строит и поддерживает актуальную 3D-модель окружения на основе последовательного потока данных, обеспечивая непрерывное восприятие и понимание окружающей среды.
Система использует CUT3R для реконструкции облаков точек из видеопотоков и Grounding SAM для семантической аннотации, обеспечивая непрерывное обновление представления окружающей среды. CUT3R выполняет построение трехмерной модели на основе визуальных данных, а Grounding SAM осуществляет привязку семантических меток к элементам этой модели. Данный процесс позволяет системе динамически адаптироваться к изменениям в окружающей среде, добавляя новые объекты и обновляя существующие представления в режиме реального времени, что критически важно для задач, требующих понимания динамичных трехмерных сцен.
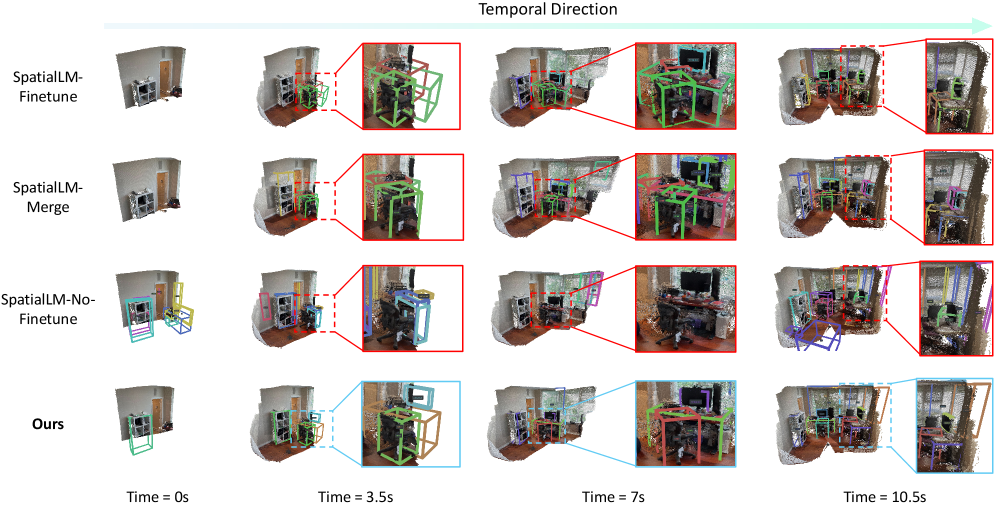
Для обучения и оценки предложенной системы OnlineSI использовались общедоступные наборы данных ScanNet и ScanNet++, содержащие 3D-модели помещений и соответствующие семантические аннотации. Результаты экспериментов показали значительное превосходство OnlineSI над базовыми моделями (baselines) на обоих наборах данных, что подтверждается метриками точности семантической сегментации и реконструкции 3D-геометрии. Количественные показатели демонстрируют улучшение производительности в задачах понимания 3D-сцен в динамических условиях, подтверждая эффективность предложенного подхода к онлайн-обработке данных.
Надежное Обнаружение и Оценка в Потоковых Данных
Система OnlineSI обеспечивает обнаружение объектов в режиме реального времени непосредственно из непрерывных видеопотоков. В отличие от традиционных методов, требующих полной обработки видео перед идентификацией, данная технология анализирует каждый кадр последовательно, позволяя мгновенно реагировать на появление и перемещение объектов. Это достигается за счет оптимизированных алгоритмов и эффективной обработки данных, что критически важно для приложений, требующих немедленной реакции, таких как автономные транспортные средства, системы безопасности и мониторинга, а также автоматизированные производственные линии. Благодаря возможности оперативной идентификации объектов, OnlineSI открывает новые перспективы для анализа данных в динамичных условиях, предоставляя информацию практически мгновенно после её появления в видеопотоке.
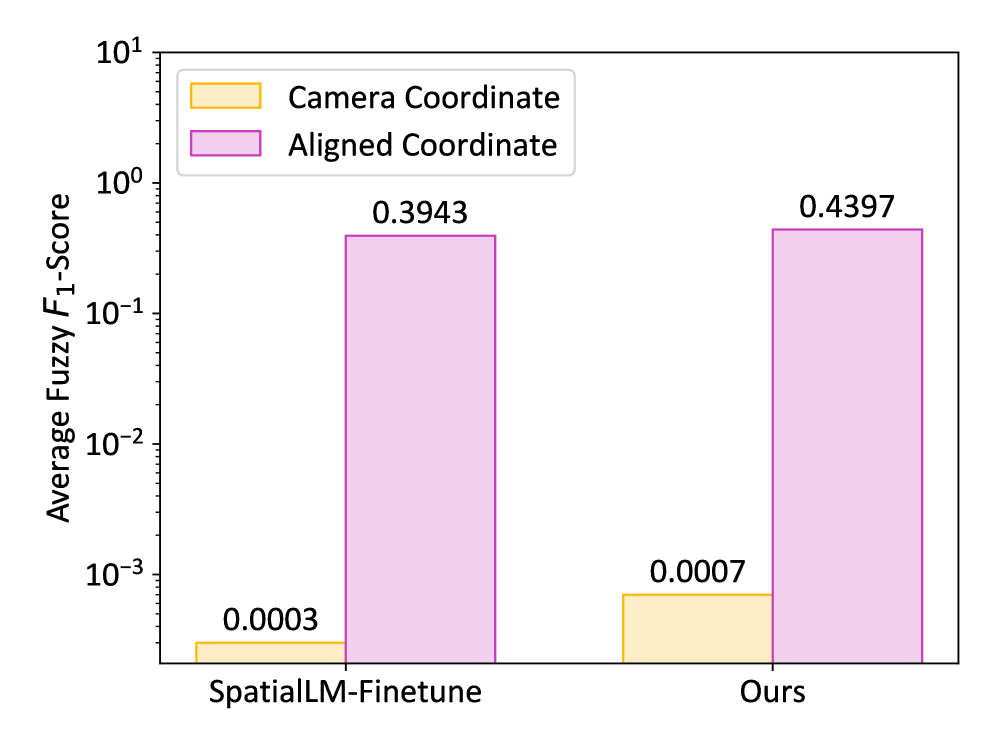
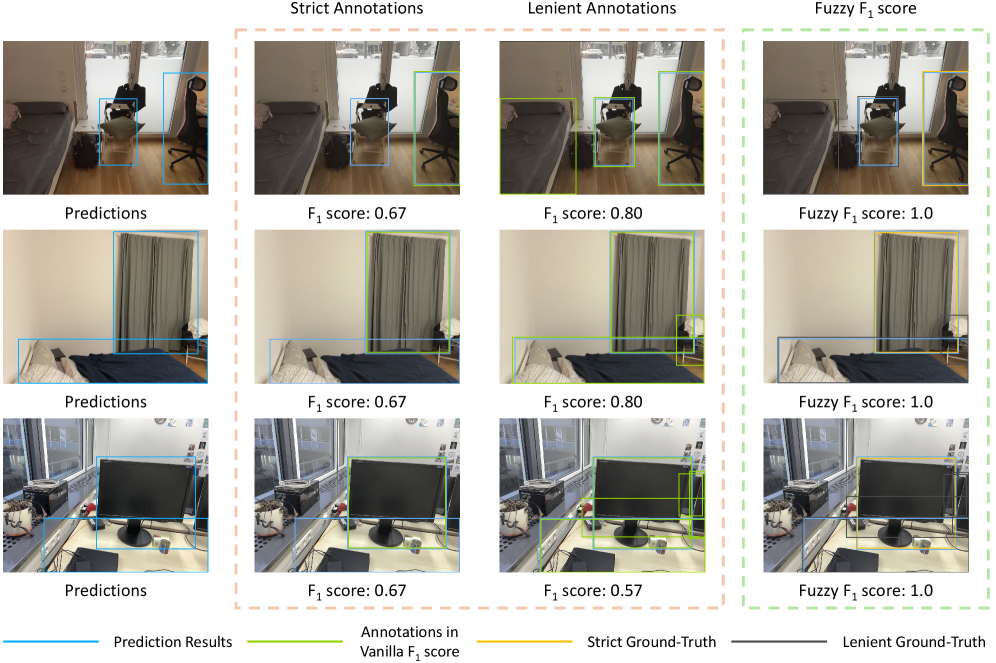
В условиях потоковой обработки данных, когда объекты обнаруживаются не полностью или с помехами, традиционные метрики оценки, такие как F1-мера, могут давать неточные результаты. Для решения этой проблемы предлагается использование нечеткой F1-меры (Fuzzy F1 Score), которая позволяет более тонко оценивать качество обнаружения. В отличие от классической F1-меры, нечеткая версия учитывает степень принадлежности объекта к определенной категории, позволяя оценивать частичные наблюдения и учитывать неопределенность. Fuzzy\ F1\ Score предоставляет более гибкий и надежный способ оценки, особенно в ситуациях, когда данные неполны или зашумлены, обеспечивая более точную картину производительности системы онлайн-детектирования.
Предложенный подход демонстрирует высокую устойчивость к неполным или зашумленным данным в задачах обнаружения объектов в потоковых данных. Благодаря использованию Fuzzy F1-меры, которая более гибко оценивает результаты, OnlineSI-фреймворк способен эффективно функционировать даже при наличии пропусков или искажений в поступающей информации. Экспериментальные исследования показывают, что разработанная система значительно превосходит существующие базовые алгоритмы, обеспечивая более точную и надежную идентификацию объектов в реальном времени, что особенно важно для приложений, требующих немедленной реакции на изменяющиеся условия.
Исследование, представленное в данной работе, подчеркивает важность последовательного понимания трехмерных сцен из потоковых данных. Система OnlineSI, используя ограниченную пространственную память и семантическое слияние, демонстрирует способность к адаптивному обучению в реальном времени. Как однажды заметил Эндрю Ын: «Самый большой барьер для успеха — это не отсутствие таланта, а отсутствие дисциплины». Это особенно актуально при работе с большими языковыми моделями и потоковыми данными, где систематический подход к обработке информации и поддержание согласованности данных играет ключевую роль в достижении надежных результатов. Способность к адаптации и последовательному обучению, продемонстрированная OnlineSI, является ярким примером того, как дисциплинированный подход может раскрыть потенциал даже самых сложных систем.
Куда Ведет Этот Путь?
Представленная работа, стремясь обуздать мощь больших языковых моделей для понимания трехмерного мира в режиме реального времени, неизбежно наталкивается на ограничения, присущие любой попытке свести сложность к управляемым параметрам. Ограниченный объем пространственной памяти, необходимый для онлайн-обучения, подобен фильтру, пропускающему лишь часть информации, подобно тому, как диффузия ограничивает распространение энергии. Возникает вопрос: не теряется ли при этом принципиально важная информация о структуре и динамике сцены? Не является ли поддержание «четкой» картины мира иллюзией, а не отражением истинной сложности?
Дальнейшие исследования, вероятно, будут сосредоточены на разработке более эффективных механизмов кодирования и сжатия пространственной информации, возможно, вдохновленных принципами работы биологических нейронных сетей — той самой “неопрятной” эффективности, которая так часто ускользает от наших аккуратных алгоритмов. Интересным направлением представляется интеграция моделей с активным восприятием — способностью целенаправленно собирать информацию, подобно тому, как живые организмы исследуют окружающую среду.
В конечном счете, задача состоит не в создании идеальной модели трехмерного мира, а в разработке систем, способных адаптироваться к его неопределенности и извлекать из него полезные знания. Подобно тому, как физик изучает не абсолютную истину, а закономерности, проявляющиеся в наблюдаемых явлениях, так и мы должны научиться извлекать смысл из потока сенсорной информации, даже если он неполный и противоречивый.
Оригинал статьи: https://arxiv.org/pdf/2601.16538.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Российский рынок: от инфляции к инвестициям: что ждет инвесторов? (11.06.2026 02:32)
- 10 лучших OLED ноутбуков. Что купить в июне 2026.
- vivo S60 ОБЗОР: скоростная зарядка, объёмный накопитель, современный дизайн
- Как сделать фотографию резкой.
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Обзор Motorola Edge 50 Fusion
- Прогнозы цен на CC: анализ криптовалюты CC
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Обзор Nikon D5500 DX
2026-01-27 05:04