Автор: Денис Аветисян
Исследователи предлагают инновационный метод адаптации алгоритмов к индивидуальным особенностям мозга, значительно повышая точность систем управления на основе ЭЭГ.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"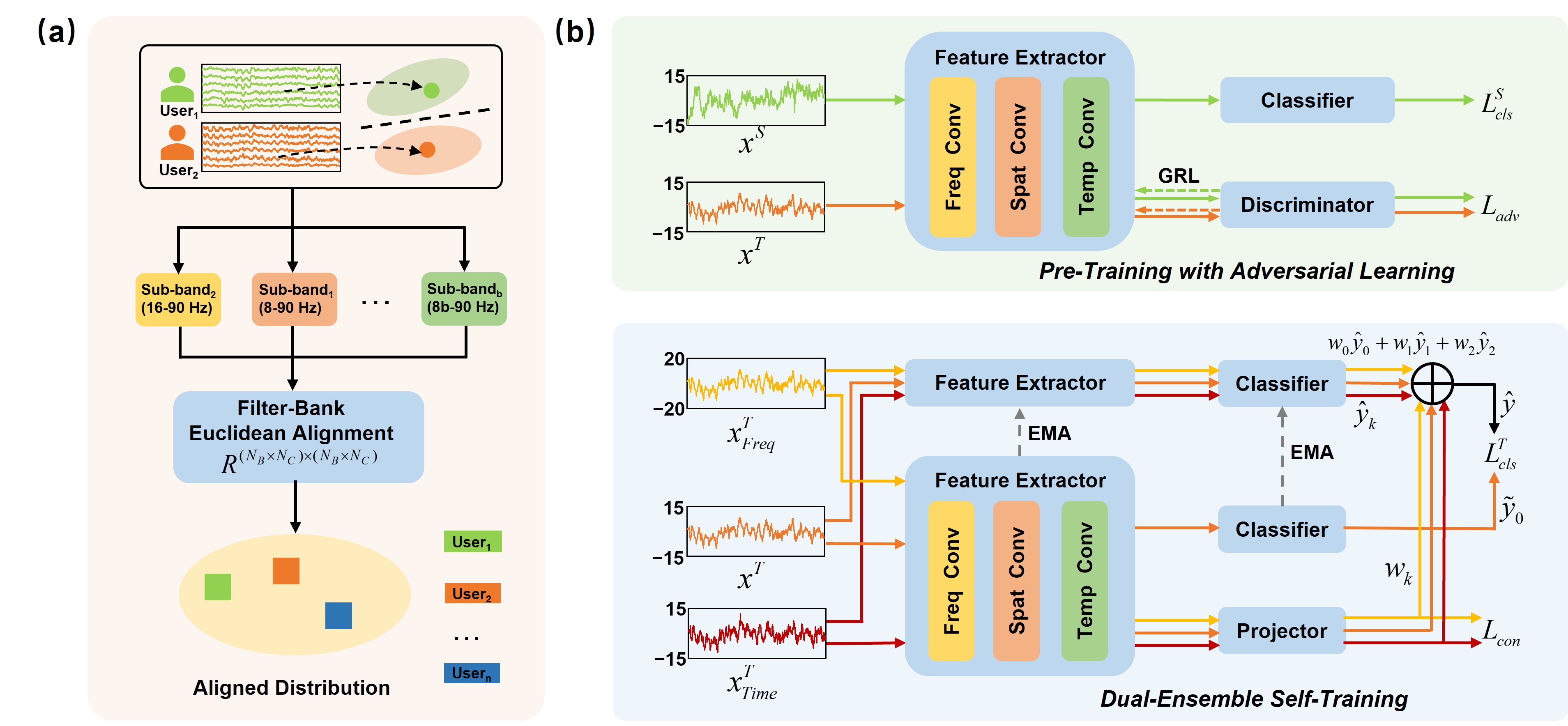
В статье представлен новый метод кросс-субъектной адаптации домена для классификации SSVEP, использующий выравнивание фильтр-банков, самообучение с двойными ансамблями и контрастное обучение с расширением во времени и частоте.
Несмотря на высокую помехоустойчивость и удобство интерфейса, эффективность мозговых интерфейсов на основе устойчивых вызванных потенциалов (SSVEP) ограничена из-за индивидуальных различий в сигналах и затрат на разметку данных для каждого пользователя. В данной работе, посвященной ‘Rethinking Self-Training Based Cross-Subject Domain Adaptation for SSVEP Classification’, предложен новый метод адаптации домена между субъектами, основанный на самообучении. Ключевым нововведением является стратегия выравнивания на основе фильтр-банков и двухэтапный алгоритм самообучения с использованием ансамблей и контрастивного обучения во временной и частотной областях. Позволит ли предложенный подход существенно повысить точность и надежность SSVEP-интерфейсов в реальных условиях эксплуатации и открыть новые горизонты для персонализированных нейротехнологий?
Вызов межсубъектной вариабельности в SSVEP-интерфейсах
Интерфейсы мозг-компьютер, основанные на стабильных вызванных потенциалах (SSVEP), демонстрируют высокую производительность и точность в управлении устройствами. Однако, существенной проблемой является значительное снижение эффективности при переносе обученной модели с одного пользователя на другого. Несмотря на перспективность технологии, индивидуальные различия в физиологической активности мозга, а также особенности формирования и восприятия визуальных стимулов, приводят к тому, что модель, идеально работающая для одного человека, может давать значительные сбои у другого. Это требует либо трудоемкой и затратной по времени индивидуальной калибровки для каждого нового пользователя, либо разработки более адаптивных и обобщающих алгоритмов, способных компенсировать эту межсубъектную вариабельность и обеспечить стабильную работу системы для широкого круга пользователей.
Неоднородность мозговой активности между разными людьми является ключевым фактором, ограничивающим эффективность интерфейсов «мозг-компьютер», основанных на стабильных вызванных потенциалах (SSVEP). Индивидуальные различия в анатомии мозга, физиологическом состоянии и даже особенностях когнитивной обработки приводят к заметным вариациям в характеристиках сигналов SSVEP, таких как амплитуда, частота и фаза. Эти различия проявляются не только в абсолютных значениях, но и в относительных паттернах активности, что существенно усложняет задачу разработки универсальных моделей, способных эффективно декодировать намерения пользователя у разных людей. Именно поэтому, несмотря на высокую точность в рамках одного пользователя, перенос моделей SSVEP между людьми зачастую приводит к значительному снижению производительности и требует индивидуальной калибровки для каждого нового субъекта.
Традиционные методы построения интерфейсов «мозг-компьютер» на основе стабильных вызванных потенциалов (SSVEP) часто сталкиваются с проблемой низкой обобщающей способности. Вместо того, чтобы модель, обученная на данных одного пользователя, эффективно работала с данными другого, требуется трудоемкая и непрактичная процедура повторной калибровки для каждого нового индивидуума. Эта необходимость связана с тем, что физиологические особенности мозговой активности, включая амплитуду, частоту и фазу SSVEP, значительно различаются между людьми. Попытки создать универсальную модель, игнорирующую эти индивидуальные вариации, приводят к существенному снижению точности и надежности системы, что ограничивает ее широкое применение в реальных условиях и затрудняет адаптацию к потребностям конкретного пользователя.
Адаптация к индивидуальности: Стратегии доменной адаптации
Методы адаптации домена направлены на минимизацию расхождений между исходным (обучающим) и целевым (новым пользователем) доменами, что позволяет моделям эффективно обобщать данные и улучшать производительность в новых условиях. Несоответствие между доменами может возникать из-за различий в распределении входных данных, что приводит к снижению точности модели при переходе от обучающей выборки к данным нового пользователя. Адаптация домена использует различные техники, такие как перенос признаков, адаптация признаков и обучение с самообучением, для уменьшения этого разрыва и повышения обобщающей способности модели в целевом домене. Эффективная адаптация критически важна для приложений, где данные о новых пользователях ограничены или отсутствуют, поскольку позволяет использовать знания, полученные на более крупной обучающей выборке, для улучшения работы модели в новых сценариях.
Методы SUTL (Selective Unlabeling for Transfer Learning) и OACCA (Optimal Assignment of Classifiers with Confidence Adaptation) направлены на повышение эффективности переноса знаний путем интеллектуального отбора и выравнивания переносимых признаков от исходных испытуемых к целевому пользователю. SUTL осуществляет выборочную разметку данных, исключая нерелевантные примеры, что снижает влияние различий между доменами. OACCA, в свою очередь, использует оптимальное сопоставление классификаторов, адаптируя их к особенностям целевого домена и повышая точность прогнозов. Оба подхода позволяют уменьшить расхождения в распределениях признаков между исходным и целевым доменами, улучшая обобщающую способность моделей и повышая их производительность при работе с новыми пользователями.
Метод самообучения, расширенный подходами, такими как SFDA, использует неразмеченные данные целевого домена для уточнения модели и дальнейшего уменьшения расхождений между доменами. Однако, на наборе данных BETA, SFDA демонстрирует скорость ввода 131.99 \pm 7.86 бит/мин, что указывает на необходимость разработки более эффективных стратегий адаптации для улучшения производительности в новых условиях.
К обобщению: Создание надежных моделей декодирования SSVEP
Методы доменной генерализации, такие как Ensemble-DNN и tt-CCA, направлены на обучение представлений, инвариантных к индивидуальным различиям между испытуемыми. В контексте декодирования SSVEP (стационарных зрительных вызванных потенциалов) это означает, что модели разрабатываются таким образом, чтобы минимизировать влияние особенностей конкретного пользователя на процесс классификации. Данный подход позволяет создавать модели, способные эффективно работать с новыми испытуемыми, не требуя переобучения для каждого конкретного случая, поскольку извлекаемые признаки не зависят от специфических характеристик отдельных пользователей. Это достигается за счет применения техник, которые акцентируют внимание на общих закономерностях в данных SSVEP, игнорируя индивидуальные вариации.
Методы обобщения предметной области, такие как Ensemble-DNN и tt-CCA, строят модели, способные напрямую применять знания, полученные на основе данных от множества исходных испытуемых, к новым, ранее не встречавшимся испытуемым. Это достигается путем обучения представлений, инвариантных к индивидуальным особенностям каждого испытуемого, что позволяет избежать необходимости переобучения или калибровки модели для каждого нового пользователя. В результате, модель, обученная на группе испытуемых, может эффективно декодировать SSVEP сигналы от неизвестного испытуемого без значительной потери точности, обеспечивая возможность широкого применения системы без индивидуальной адаптации.
Использование методов обработки сигналов, таких как Filter Banks и FBEA (Frequency-domain Band-Energy Analysis), в сочетании со сверточными нейронными сетями (CNN), позволяет значительно улучшить извлечение признаков из данных SSVEP. Filter Banks разделяют входной сигнал на несколько частотных диапазонов, а FBEA оценивает энергию сигнала в каждом диапазоне, предоставляя более информативное представление данных для CNN. Комбинация этих методов позволила достичь точности 94.80% на Benchmark датасете, что демонстрирует эффективность данного подхода для повышения обобщающей способности моделей декодирования SSVEP и их устойчивости к индивидуальным вариациям испытуемых.
Динамическое совершенствование: Продвинутые методы межсубъектного переноса
Методики, такие как CSST, представляют собой инновационный подход к адаптации моделей машинного обучения, осуществляя динамическую настройку в процессе работы. В основе этих систем лежит сочетание состязательного обучения и механизмов двойного ансамбля. Состязательное обучение позволяет модели адаптироваться к новым данным, минимизируя расхождения между доменами, а двойной ансамбль повышает устойчивость и обобщающую способность за счет объединения предсказаний нескольких моделей. Этот симбиоз позволяет системе непрерывно совершенствоваться, подстраиваясь под изменяющиеся условия и обеспечивая высокую производительность даже при переносе знаний между различными субъектами. В результате, модель способна эффективно использовать информацию, полученную от одного пользователя, для улучшения работы с данными другого, что открывает новые возможности в различных областях, от нейроинтерфейсов до персонализированной медицины.
В процессе обучения моделей переноса знаний, выравнивание признаков между различными субъектами является ключевой задачей. Для её решения используется механизм градиентного обращения (Gradient Reverse Layer), который позволяет эффективно адаптировать признаки одного субъекта к другому. Кроме того, разработанная методика DEST (Dual-ensemble Pseudo-labeling with Multi-view) использует псевдометки, полученные из ансамбля моделей, обученных на различных «взглядах» на данные. Такой подход, объединяющий несколько перспектив и использующий псевдометки для усиления сигнала, обеспечивает более устойчивое и надежное обучение, позволяя модели обобщать знания и эффективно работать с новыми, ранее не встречавшимися данными. Это способствует повышению точности и скорости обучения, а также улучшению способности модели адаптироваться к изменениям в данных.
Разработанные методики, включающие алгоритмы CSST и DEST, продемонстрировали впечатляющие результаты в области передачи информации между различными субъектами. На тестовом наборе данных Benchmark достигнута передовая скорость передачи информации в 203.1 \pm 8.03 бит/мин, что значительно превосходит показатели предыдущих методов, таких как SFDA (194.54 \pm 10.07 бит/мин), с высокой статистической значимостью (p < 0.01). Аналогичные улучшения наблюдаются и на наборе данных BETA, где достигнута скорость передачи информации в 160.93 \pm 6.93 бит/мин, что также значительно выше (p < 0.001) по сравнению с результатами, полученными с использованием SFDA (131.99 \pm 7.86 бит/мин). Данные показатели свидетельствуют о высокой эффективности предложенных подходов для решения задачи межсубъектной передачи информации.
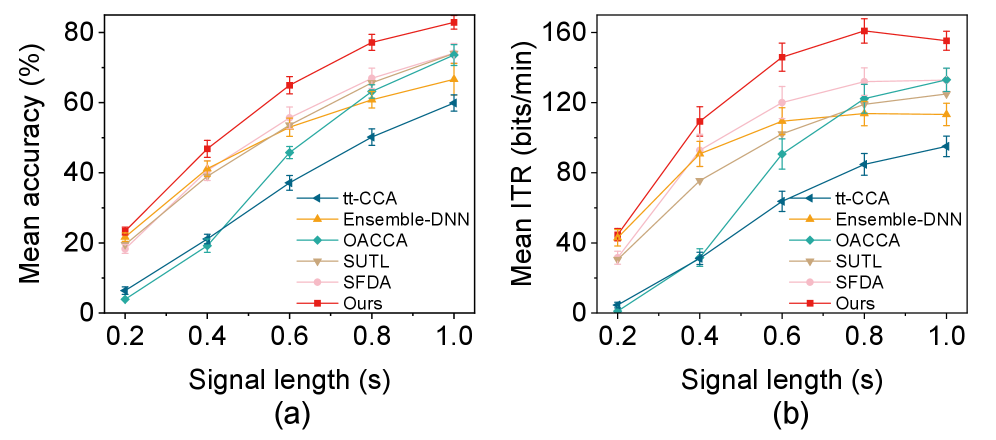
Перспективы: К по-настоящему персонализированным системам ИМК
Сочетание методов доменной адаптации и обобщения представляется перспективным подходом к созданию надежных систем интерфейсов мозг-компьютер. Доменная адаптация позволяет системе эффективно переносить знания, полученные в одной среде (например, в лабораторных условиях), в другую (например, в реальной жизни, с изменением освещения или шума), минимизируя необходимость повторного обучения для каждого пользователя или каждой новой ситуации. В то же время, методы обобщения направлены на повышение устойчивости системы к вариациям внутри одной и той же среды, учитывая индивидуальные особенности мозга каждого пользователя и обеспечивая стабильную работу даже при незначительных изменениях в нейронной активности. В результате, синергия этих двух подходов способствует созданию систем, которые не только адаптируются к новым условиям, но и способны к самообучению и оптимизации, обеспечивая более плавное и интуитивно понятное взаимодействие между человеком и машиной.
Исследования показывают, что применение усовершенствованных стратегий псевдо-маркировки данных в системах интерфейса «мозг-компьютер» (ИМК) может значительно повысить их эффективность. Вместо полагаться исключительно на ограниченное количество размеченных данных, эти стратегии позволяют использовать неразмеченные данные, присваивая им вероятностные метки на основе анализа модели. Интеграция контекстной информации, такой как текущее состояние пользователя, окружающая среда или задача, которую он выполняет, еще больше усиливает этот эффект. Такой подход позволяет ИМК адаптироваться к индивидуальным особенностям и динамически изменяющимся условиям, что приводит к более точной и надежной интерпретации мозговой активности и, следовательно, к более плавному и интуитивно понятному взаимодействию с цифровым миром.
Конечной целью развития интерфейсов мозг-компьютер (ИМК) является создание по-настоящему персонализированных систем, способных бесшовно адаптироваться к индивидуальным потребностям пользователя. Такие системы должны не просто распознавать намерения, но и предвосхищать их, оптимизируя взаимодействие с цифровым миром в реальном времени. Это предполагает выход за рамки универсальных алгоритмов и переход к моделям, учитывающим уникальные нейрофизиологические особенности каждого человека, его когнитивные способности и даже текущее эмоциональное состояние. В перспективе, персонализированные ИМК смогут не только восстанавливать утраченные функции, но и расширять возможности человека, предоставляя интуитивно понятный и эффективный способ управления устройствами и доступа к информации, что приведет к качественно новому уровню взаимодействия человека и технологий.
Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в области классификации SSVEP. Авторы предлагают не просто эмпирически работающее решение, но и тщательно выстроенный метод доменной адаптации, основанный на выравнивании фильтр-банков и самообучении с использованием двойных ансамблей. Этот подход, подкрепленный контрастным обучением и дискориминацией признаков, позволяет достичь передовых результатов, что подтверждает важность строгого математического обоснования алгоритмов. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что верно, а не о том, что кажется верным». Данная работа иллюстрирует эту мысль, стремясь к доказанной корректности и эффективности алгоритмов классификации SSVEP.
Что дальше?
Представленная работа, безусловно, демонстрирует улучшение в области адаптации моделей для интерфейсов мозг-компьютер, основанных на регистрации стабильных вызванных потенциалов (SSVEP). Однако, не стоит обольщаться кажущимся успехом. Оптимизация без анализа — самообман и ловушка для неосторожного разработчика. Достигнутое улучшение производительности, хотя и значимо, не решает фундаментальную проблему: как гарантированно обеспечить надежную работу системы в условиях реальной, неконтролируемой среды, где изменчивость физиологических сигналов неизбежна.
Будущие исследования должны быть направлены не только на повышение точности классификации, но и на разработку более устойчивых к шумам и артефактам методов. Особый интерес представляет изучение возможности интеграции предложенного подхода с другими техниками, такими как активное обучение и трансферное обучение, для создания самообучающихся систем, способных адаптироваться к индивидуальным особенностям каждого пользователя. Необходимо также уделить внимание разработке метрик, позволяющих объективно оценить обобщающую способность моделей и избежать переобучения на ограниченных наборах данных.
В конечном счете, истинный прогресс в этой области возможен лишь при переходе от эмпирического поиска оптимальных параметров к строгому математическому моделированию и доказательству корректности алгоритмов. Иначе говоря, требуется не просто «заставить работать», а понять, почему это работает, и как это можно улучшить с математической точностью.
Оригинал статьи: https://arxiv.org/pdf/2601.21203.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Acer Aspire 5 Spin 14 ОБЗОР
- Tecno Pova 7 ОБЗОР: беспроводная зарядка, плавный интерфейс, большой аккумулятор
- Как установить SteamOS на игровые портативные устройства ROG Ally и Legion Go под управлением Windows
- Интервью с создателями фильма «Пятая группа крови»
- Финальное обновление Minecraft года официально здесь — Mounts of Mayhem добавляет сражения верхом в Overworld.
- Motorola Moto G77 ОБЗОР: яркий экран, лёгкий, чёткое изображение
- 10 лучших OLED ноутбуков. Что купить в мае 2026.
- Motorola Edge 70 Ultra ОБЗОР: современный дизайн, скоростная зарядка, огромный накопитель
- Как обновить Windows 10 до 11, используя локальную учётную запись — пошаговое руководство по обходу требования к учётной записи Microsoft.
- Лучшие ноутбуки с матовым экраном. Что купить в мае 2026.
2026-01-31 20:16