Автор: Денис Аветисян
Исследователи предлагают инновационный подход к анализу спутниковых изображений, позволяющий автоматически выделять объекты без предварительного обучения.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
В статье представлена методика глубокого объединения моделей компьютерного зрения и обработки естественного языка для семантической сегментации изображений дистанционного зондирования с использованием суперпикселей и контрастивного обучения.
Высокодетальные снимки дистанционного зондирования Земли характеризуются плотным расположением объектов и сложными границами, что предъявляет повышенные требования к точности геометрической локализации и семантической интерпретации. В данной работе, посвященной проблеме открытой семантической сегментации в контексте анализа данных дистанционного зондирования (‘Bidirectional Cross-Perception for Open-Vocabulary Semantic Segmentation in Remote Sensing Imagery’) предложен фреймворк SDCI, глубоко объединяющий возможности моделей CLIP и DINO с учетом структур суперпикселей. Ключевым результатом является достижение передового уровня точности благодаря использованию двунаправленного механизма взаимодействия и кросс-модального обмена информацией. Не приведет ли дальнейшая интеграция суперпиксельных структур и моделей диффузии к созданию еще более эффективных и надежных систем анализа изображений дистанционного зондирования?
Истинная Элегантность Семантической Сегментации: От Ограничений к Открытым Горизонтам
Традиционные методы семантической сегментации, несмотря на значительные успехи, сталкиваются с серьезными ограничениями в реальных условиях. Суть проблемы заключается в том, что эти модели обучаются распознавать лишь ограниченный набор объектов, заданный в процессе тренировки. Встречаясь с объектом, который не был представлен в обучающей выборке, система оказывается неспособной корректно его идентифицировать и выделить на изображении. Это значительно снижает практическую ценность таких моделей в динамичных и непредсказуемых средах, где разнообразие объектов может быть огромным. Представьте, например, систему автономного вождения, обученную распознавать стандартные дорожные знаки, внезапно сталкивающуюся с новым, экспериментальным знаком — она просто не сможет его интерпретировать, что может привести к опасным последствиям. Таким образом, ограниченность обучающего набора становится критическим препятствием для широкого применения семантической сегментации в реальном мире.
Визуально-языковые модели (ВЯМ) представляют собой перспективное решение проблемы распознавания новых объектов, с которой сталкиваются традиционные системы сегментации изображений. Вместо жёсткой привязки к заранее определённым категориям, ВЯМ используют текстовые описания для понимания и идентификации объектов, даже тех, которые не встречались в процессе обучения. Этот подход позволяет моделям не просто классифицировать пиксели, но и интерпретировать визуальную информацию в контексте текстового запроса, открывая возможности для сегментации изображений с использованием произвольных текстовых подсказок. В результате, ВЯМ способны адаптироваться к новым задачам и распознавать объекты, которые ранее считались «неизвестными», что значительно расширяет область их применения в различных сферах, от робототехники до медицинской визуализации.
Появление технологии открытой семантической сегментации (OVSS) знаменует собой значительный прорыв в области компьютерного зрения. В отличие от традиционных методов, которые ограничены классами объектов, изученными в процессе обучения, OVSS позволяет идентифицировать и выделять на изображениях объекты, не встречавшиеся ранее. Это достигается за счет использования языковых моделей и текстовых описаний, что дает возможность системе «понимать» новые классы по текстовому запросу. Благодаря этому, OVSS открывает широкие перспективы для применения в реальных сценариях, где постоянно появляются незнакомые объекты, например, в робототехнике, автономном вождении и анализе спутниковых снимков, обеспечивая гибкость и адаптивность, недоступные классическим алгоритмам сегментации.
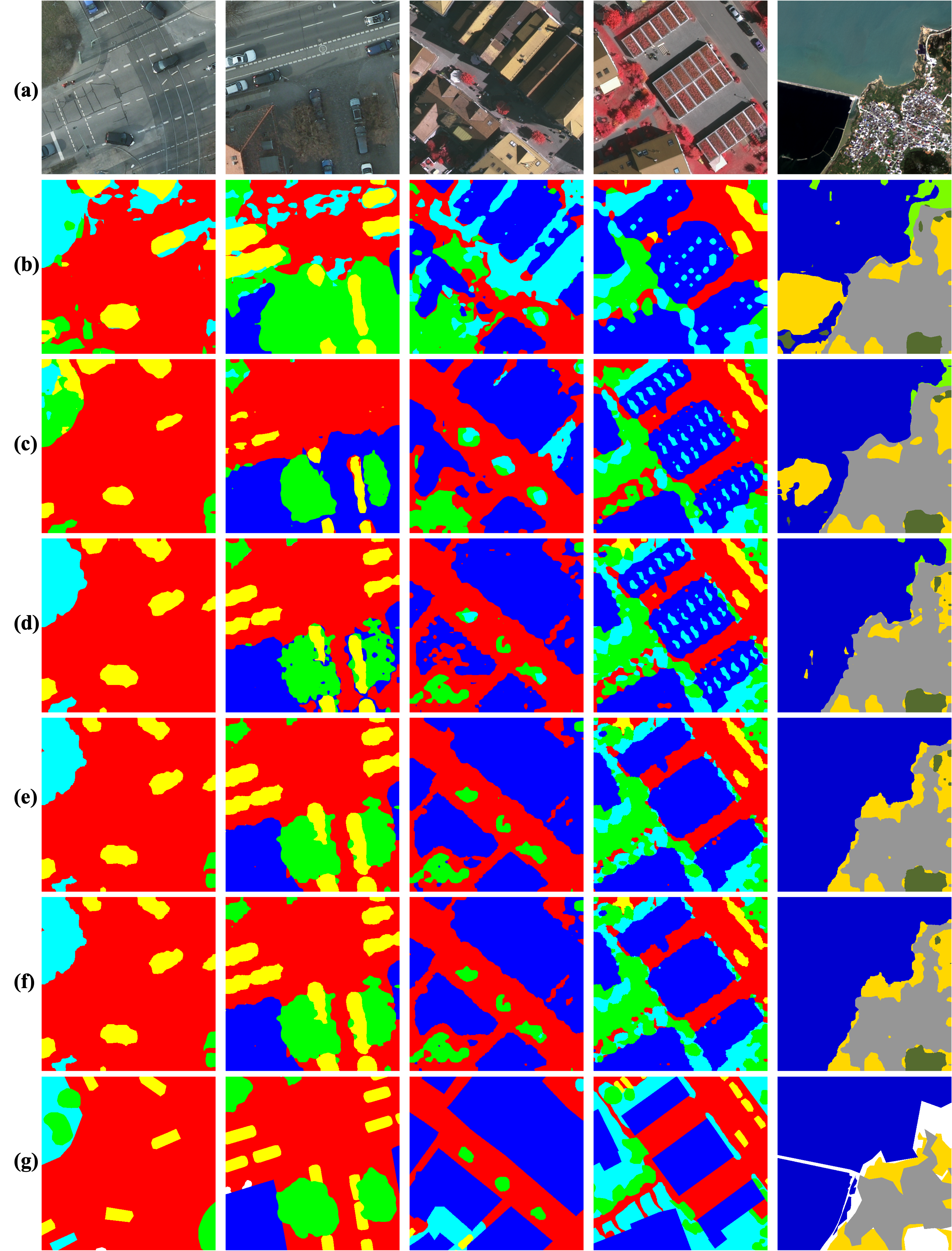
Фундаментальные Модели и Стратегии Извлечения Признаков: Основа для Обобщения
Визуальные фундаментальные модели, такие как DINO и SAM, предоставляют надежные предварительно обученные векторные представления, которые играют ключевую роль в производительности задач Open Vocabulary Semantic Segmentation (OVSS). Эти модели, обученные на масштабных наборах данных изображений, способны извлекать значимые признаки, позволяющие эффективно различать объекты и их контекст. В частности, DINO использует самообучение с дистилляцией знаний для создания устойчивых представлений, а SAM специализируется на генерации масок сегментации для заданных подсказок, что делает их ценными компонентами в конвейерах OVSS, где требуется обобщение на невидимые классы объектов и адаптация к различным сценариям.
Контрастное обучение с использованием пар «изображение-текст» является основополагающим методом для создания визуально-языковых моделей (VLM). В процессе контрастного обучения модель обучается сопоставлять изображения и соответствующие им текстовые описания, одновременно максимизируя сходство между ними и минимизируя сходство с другими, несоответствующими парами. Этот процесс позволяет модели изучать общие представления, связывающие визуальную и текстовую информацию, что необходимо для решения задач, требующих понимания как изображений, так и языка. Эффективность контрастного обучения обусловлена его способностью формировать надежные и обобщаемые представления, что делает его ключевым компонентом современных VLM.
Методы ClearCLIP и CLIPer развивают предварительное обучение моделей, используя подход промптинга для повышения точности и обобщающей способности сегментации изображений. ClearCLIP оптимизирует промпты на основе информации о классах объектов, улучшая разделение на основе семантического понимания. CLIPer, в свою очередь, использует промпты, генерируемые на основе описания изображения, для управления процессом сегментации и адаптации к различным визуальным контекстам. Оба подхода позволяют добиться более высокой точности сегментации, особенно в задачах с ограниченным количеством обучающих данных, благодаря использованию знаний, полученных в процессе предварительного обучения, и эффективному управлению процессом сегментации посредством промптов.
Методы ProxyCLIP и CorrCLIP улучшают производительность моделей, использующих Contrastive Language-Image Pretraining (CLIP), за счет интеграции внешних Vision Foundation Models (VFM). ProxyCLIP использует VFM для генерации прокси-представлений изображений, что позволяет более эффективно сопоставлять визуальные и текстовые данные. CorrCLIP, в свою очередь, применяет VFM для вычисления корреляций между признаками, извлеченными из изображения и текста, тем самым повышая точность сегментации и улучшая понимание контекста. Включение VFM, таких как DINO или SAM, позволяет этим методам извлекать более информативные и семантически богатые признаки, что приводит к повышению общей производительности в задачах визуального понимания.
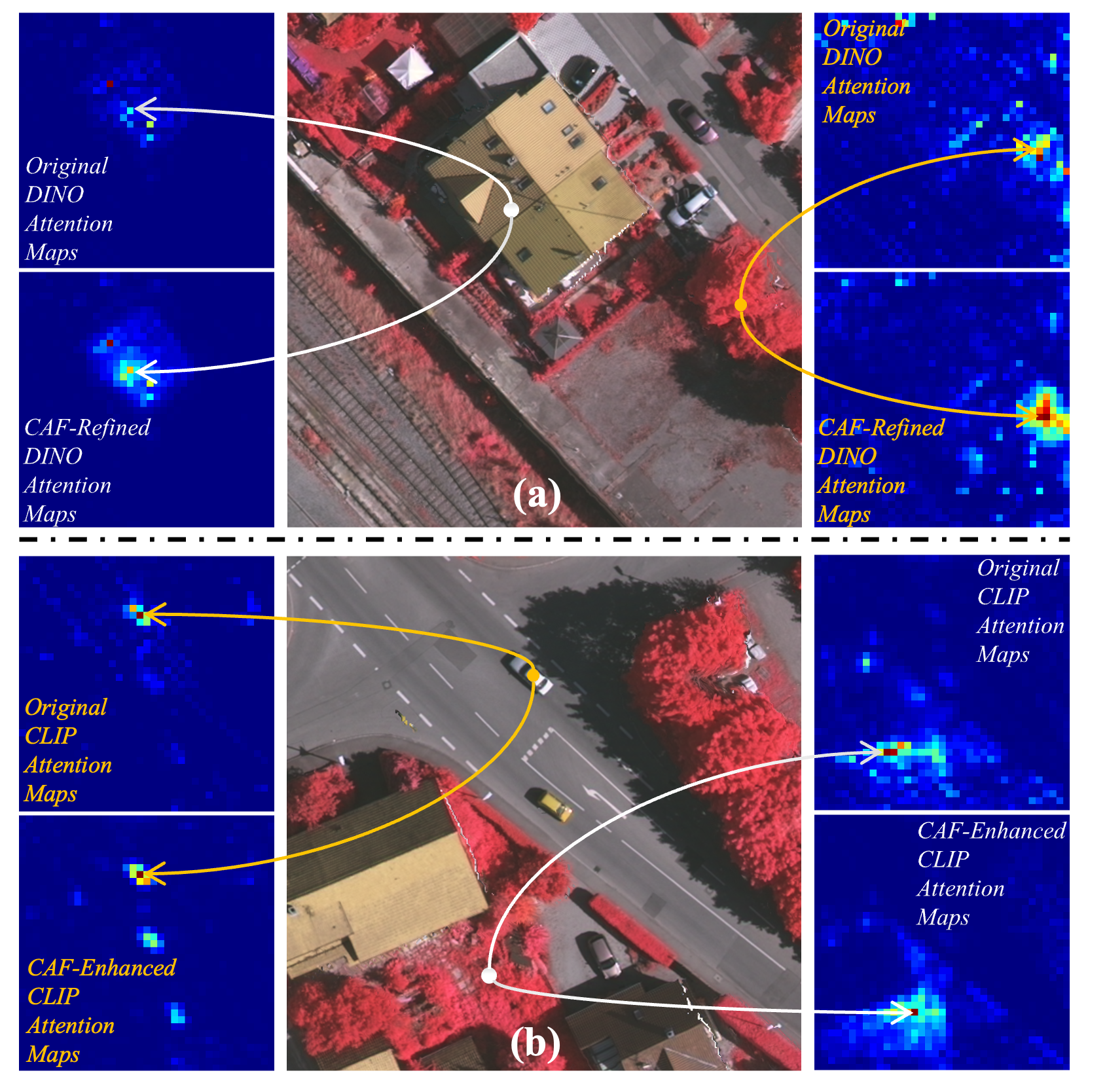
SDCI: Совместный Вывод для Улучшенной Сегментации: Архитектура, Стремящаяся к Гармонии
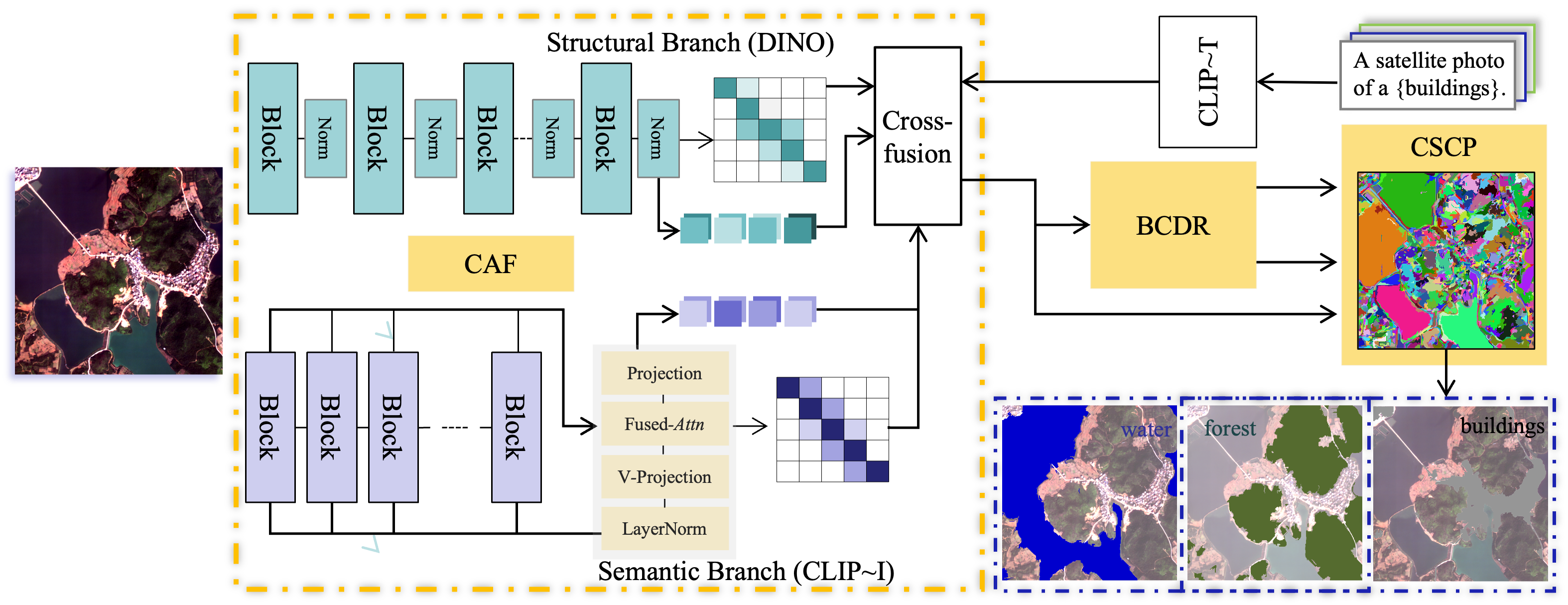
Фреймворк пространственно-регуляризованного двойного ветвления для совместного вывода (SDCI) представляет собой новый подход к задаче Object-Level Visual Semantic Segmentation (OVSS). В отличие от традиционных методов, SDCI использует архитектуру с двумя ветвями, предназначенными для извлечения признаков на основе пространственной информации и семантического анализа. Данная конструкция позволяет более эффективно обрабатывать сложные сцены и улучшать точность сегментации за счет совместного использования признаков, полученных из обоих источников. Ключевым аспектом является учет пространственной регуляризации, что способствует формированию более связных и логичных сегментов, особенно в областях с неоднозначными или нечеткими границами объектов.
В рамках SDCI для эффективного объединения и уточнения признаков используются модули CAF (Context-Aware Feature) и BCDR (Bidirectional Contextual Dependency Refinement). Модуль CAF осуществляет взвешенное объединение признаков, учитывая контекстную информацию для повышения репрезентативности. BCDR, в свою очередь, применяет двунаправленный механизм уточнения зависимостей между признаками, что позволяет более точно определить границы объектов и улучшить общую точность сегментации. Комбинированное применение CAF и BCDR способствует снижению влияния шумов и повышению устойчивости к вариациям в данных, что напрямую влияет на повышение метрики mIoU.
Модуль CSCP (Collaborative Superpixel Classification Prediction) осуществляет совместное предсказание сегментации на основе суперпикселей, используя методы Primal-Dual Hybrid Gradient и Total Variation Regularization. Primal-Dual Hybrid Gradient обеспечивает эффективную оптимизацию, решая задачу сегментации как задачу оптимизации с ограничениями, в то время как Total Variation Regularization способствует сглаживанию результатов сегментации, уменьшая шум и улучшая визуальную согласованность. Совместное использование этих техник позволяет CSCP эффективно классифицировать суперпиксели и формировать точную карту сегментации, используя пространственную информацию и семантические характеристики изображений.
В рамках модуля BCDR (Bidirectional Contextual Dependency Refinement) интеграция структурных и семантических графов позволяет уточнить сегментацию за счет использования контекстных взаимосвязей. Структурный граф кодирует пространственные отношения между суперпикселями, отражая их близость и границы. Семантический граф, в свою очередь, моделирует взаимосвязи между классами объектов, определяя, какие объекты обычно встречаются вместе или рядом друг с другом. Совместное использование этих графов позволяет BCDR учитывать как локальный контекст (границы и форму объектов), так и глобальный контекст (вероятные взаимосвязи между классами), что приводит к более точной и согласованной сегментации изображений.
Предложенный фреймворк SDCI демонстрирует передовые результаты в задаче семантической сегментации изображений дистанционного зондирования. На тестовом наборе данных GID достигнута средняя точность пересечения (mIoU) в 48.49%, что превышает показатели предыдущих методов более чем на 2%. Данный результат подтверждает эффективность предложенной архитектуры и ее способность к более точной классификации пикселей на изображениях, полученных с помощью дистанционного зондирования.
Расширение Границ: Применение и Влияние на Реальный Мир
Методы, такие как CutLER, ReCo, FOSSIL и FreeDA, наглядно демонстрируют, что использование вспомогательных данных из внешних источников существенно повышает точность сегментации изображений. Эти подходы позволяют модели обучаться не только на ограниченном наборе размеченных данных, но и извлекать полезную информацию из более широкого спектра визуальных материалов. За счет этого, даже при недостатке размеченных данных для конкретной задачи, алгоритмы способны эффективно выделять объекты и их границы, значительно превосходя традиционные методы сегментации. Такой подход особенно ценен в ситуациях, когда получение большого количества размеченных данных является дорогостоящим или трудоемким процессом, открывая новые возможности для применения сегментации в различных областях, от медицины до дистанционного зондирования.
Методы TokenCut и NACLIP зарекомендовали себя как высокоэффективные решения для задачи сегментации изображений, демонстрируя свою применимость в широком спектре областей. Оба подхода отличаются не только точностью выделения объектов, но и вычислительной эффективностью, что делает их особенно ценными в сценариях, требующих обработки больших объемов данных или работы на устройствах с ограниченными ресурсами. TokenCut, используя концепцию токенов для представления изображений, позволяет быстро и точно определять границы объектов, в то время как NACLIP, опираясь на возможности предварительно обученных моделей, обеспечивает высокую производительность при минимальных затратах на обучение. Благодаря своей универсальности и эффективности, эти методы находят применение в таких областях, как медицинская визуализация, беспилотные системы, анализ спутниковых снимков и автоматизированный контроль качества.
Исследование продемонстрировало значительное преимущество SDCI-v2 в плане вычислительной эффективности. В ходе экспериментов было установлено, что SDCI-v2 требует всего 1656.44 GFLOPs для выполнения задачи сегментации, что существенно ниже, чем у CASS (26943.79 GFLOPs) и NACLIP (242.96 GFLOPs). Такое снижение вычислительных затрат открывает возможности для применения SDCI-v2 на устройствах с ограниченными ресурсами и для обработки больших объемов данных в реальном времени, что делает его перспективным решением для широкого спектра приложений, требующих точной и быстрой сегментации изображений.
Исследование продемонстрировало значительное преимущество SDCI-v2 в плане вычислительной эффективности. В ходе экспериментов было установлено, что SDCI-v2 требует всего 1656.44 GFLOPs для выполнения задачи сегментации, что существенно ниже, чем у CASS (26943.79 GFLOPs) и NACLIP (242.96 GFLOPs). Такое снижение вычислительных затрат открывает возможности для применения SDCI-v2 на устройствах с ограниченными ресурсами и для обработки больших объемов данных в реальном времени, что делает его перспективным решением для широкого спектра приложений, требующих точной и быстрой сегментации изображений.
Исследование продемонстрировало значительное преимущество SDCI-v2 в плане вычислительной эффективности. В ходе экспериментов было установлено, что SDCI-v2 требует всего 1656.44 GFLOPs для выполнения задачи сегментации, что существенно ниже, чем у CASS (26943.79 GFLOPs) и NACLIP (242.96 GFLOPs). Такое снижение вычислительных затрат открывает возможности для применения SDCI-v2 на устройствах с ограниченными ресурсами и для обработки больших объемов данных в реальном времени, что делает его перспективным решением для широкого спектра приложений, требующих точной и быстрой сегментации изображений.
Исследование демонстрирует стремление к математической чистоте в обработке данных дистанционного зондирования. Предложенный фреймворк SDCI, глубоко объединяющий модели CLIP и DINO с использованием суперпиксельной структуры, стремится к непротиворечивому решению задачи семантической сегментации с открытой лексикой. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть построен на принципах понимания, а не просто на распознавании образов». Этот принцип находит отражение в подходе, где акцент делается на глубокое слияние визуальной и языковой информации для достижения более точного и осмысленного анализа изображений, что соответствует стремлению к доказательству корректности алгоритма, а не просто к его работе на тестовых данных.
Куда Далее?
Представленная работа, несмотря на достигнутые результаты в области семантической сегментации изображений дистанционного зондирования, лишь подчеркивает фундаментальную сложность задачи. Глубокое слияние визуальных и языковых моделей, хотя и демонстрирует перспективность, пока остается эвристическим процессом. Полагаться исключительно на контрастивное обучение и предварительно обученные модели — это всё равно что строить храм на песке: каждая новая задача, выходящая за рамки тренировочного набора, рискует обрушить всю конструкцию. Необходим переход к более формальным, доказуемым методам, основанным на строгих математических принципах.
Особую обеспокоенность вызывает зависимость от качества языковых представлений. Естественный язык — инструмент несовершенный, подверженный неоднозначности и контекстуальным искажениям. Полагаться на него в задачах, требующих высокой точности, — это всё равно что использовать не откалиброванный измерительный прибор. Будущие исследования должны быть направлены на разработку более устойчивых и надежных методов представления знаний, возможно, с использованием формальных логических систем или онтологий.
В хаосе данных спасает только математическая дисциплина. Оптимизация архитектур и методов обучения без учета фундаментальных ограничений и принципов — занятие бесплодное. Истинная элегантность алгоритма проявляется не в его способности “работать на тестах”, а в его математической чистоте и доказуемости. Только тогда можно будет говорить о создании действительно интеллектуальных систем, способных к надежной и точной интерпретации изображений дистанционного зондирования.
Оригинал статьи: https://arxiv.org/pdf/2601.21159.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Acer Aspire 5 Spin 14 ОБЗОР
- Tecno Pova 7 ОБЗОР: беспроводная зарядка, плавный интерфейс, большой аккумулятор
- Интервью с создателями фильма «Пятая группа крови»
- Как установить SteamOS на игровые портативные устройства ROG Ally и Legion Go под управлением Windows
- Как обновить Windows 10 до 11, используя локальную учётную запись — пошаговое руководство по обходу требования к учётной записи Microsoft.
- Финальное обновление Minecraft года официально здесь — Mounts of Mayhem добавляет сражения верхом в Overworld.
- 10 лучших OLED ноутбуков. Что купить в мае 2026.
- Motorola Edge 70 Ultra ОБЗОР: современный дизайн, скоростная зарядка, огромный накопитель
- Motorola Moto G77 ОБЗОР: яркий экран, лёгкий, чёткое изображение
- Автофокус. В чём разница между AF-S и AF объективами.
2026-01-31 23:34