Автор: Денис Аветисян
Исследователи предлагают новый подход к поиску соответствий между видеодвижениями и текстовыми описаниями, повышая точность сопоставления за счет анализа на разных уровнях детализации.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"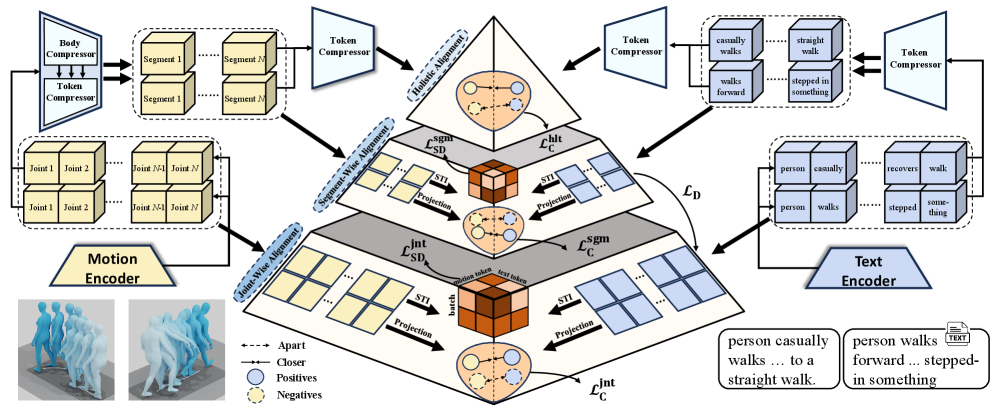
В статье представлена пирамидальная структура обучения с использованием взаимодействия Шепли-Тейлора для более точного поиска соответствий между движением и языком.
Несмотря на значительный прогресс в области кросс-модального анализа, задача сопоставления движения и языка часто страдает от недостаточной детализации. В данной работе, ‘Beyond Global Alignment: Fine-Grained Motion-Language Retrieval via Pyramidal Shapley-Taylor Learning’, предложен новый подход к извлечению информации из движений человека и соответствующих текстовых описаний, основанный на иерархической модели и методе Shapley-Taylor взаимодействия. Предлагаемый фреймворк \text{PST} позволяет улавливать тонкие взаимосвязи между сегментами движения, суставами и текстовыми токенами, значительно превосходя существующие методы. Возможно ли дальнейшее развитие данного подхода для создания более интуитивных и эффективных систем анализа человеческих действий?
Синхронизация Движения и Языка: Преодоление Разрыва
Современные подходы к сопоставлению трехмерных движений человека с их словесными описаниями сталкиваются со значительными трудностями, что препятствует достижению точного извлечения и синтеза информации. Существующие системы зачастую рассматривают движение и язык как отдельные модальности, игнорируя их внутреннюю взаимосвязь и общую семантическую структуру. Это приводит к неточностям при поиске конкретных движений по текстовому запросу или, наоборот, при генерации реалистичных движений на основе словесного описания. Неспособность эффективно связать визуальную информацию о движении с лингвистическим контекстом ограничивает возможности создания интеллектуальных систем, способных понимать и воспроизводить человеческие действия на основе естественного языка.
Существующие подходы к анализу движений человека и их лингвистическому описанию зачастую рассматривают эти два аспекта как изолированные модальности. Это приводит к тому, что важные взаимосвязи и общая семантическая структура, присущая движению и языку, остаются невыявленными. Вместо интеграции, системы стремятся сопоставить движение и текст как отдельные единицы, упуская возможность понять, как конкретные движения воплощают определенные значения и намерения, заложенные в языке. Отсутствие общей семантической модели препятствует точному извлечению информации о движении из текста и, как следствие, ограничивает возможности создания реалистичных и осмысленных синтезированных движений, соответствующих заданному лингвистическому описанию.
PST: Последовательное Выравнивание для Гармонии Движения и Слова
В основе фреймворка PST лежит последовательное выравнивание движения и языка, осуществляемое в три этапа: поэтапное выравнивание по суставам (Joint-Wise), по сегментам (Segment-Wise) и целостное (Holistic) выравнивание. Данный прогрессивный подход позволяет модели сначала устанавливать точные соответствия между отдельными суставами и словами, а затем интегрировать более широкую контекстную информацию для уточнения и обогащения понимания взаимосвязи между движением и языковым описанием. Каждый этап работает с возрастающим масштабом, переходя от локальных связей к глобальному контексту.
Данный прогрессивный подход позволяет модели изначально устанавливать точные соответствия между отдельными суставами и словами, что обеспечивает детальное понимание базовых элементов движения. После установления этих мелкозернистых связей, модель переходит к интеграции более широкого контекста, объединяя локальные соответствия в глобальное понимание всей последовательности движений. Это поэтапное построение позволяет избежать ошибок, возникающих при попытке сразу учесть весь объем информации, и повышает точность выравнивания движения и языка.
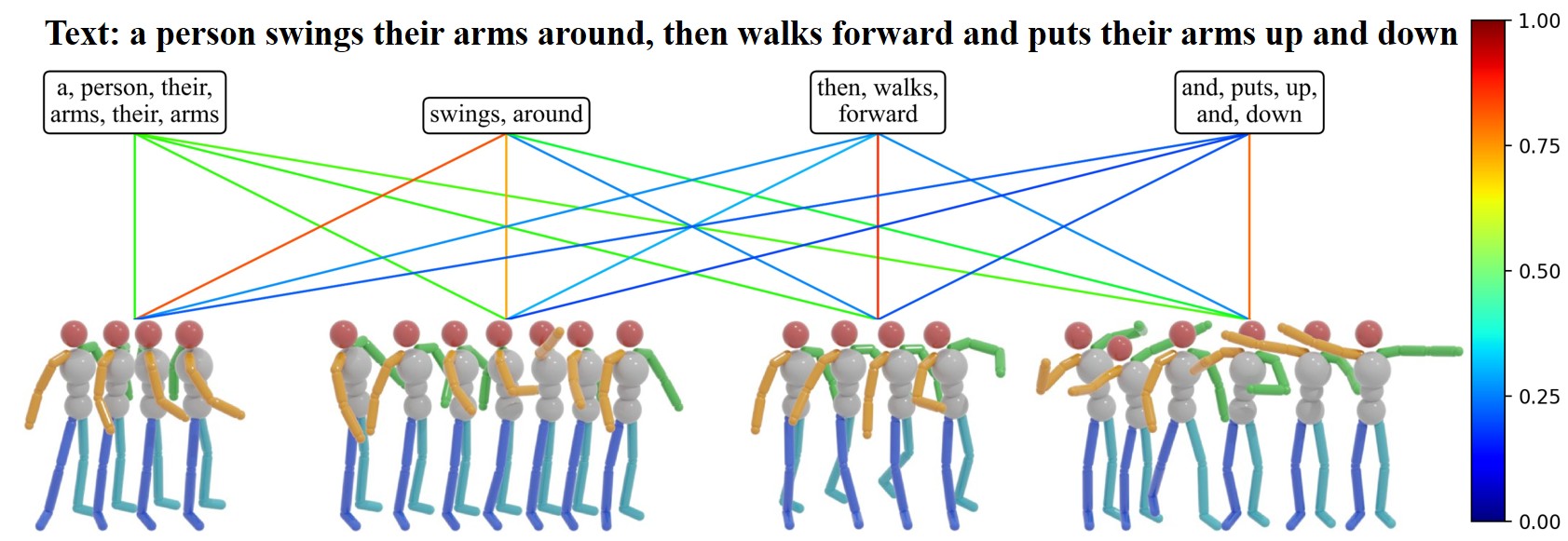
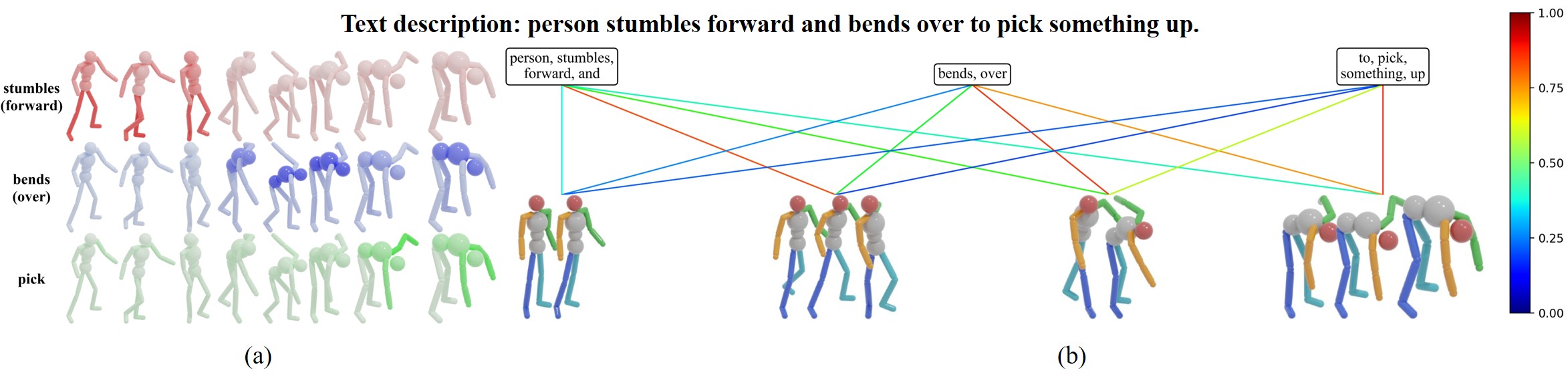
Архитектурная Основа: Vision Transformers и За Ее Пределами
Для кодирования как последовательностей движений (с использованием MotionPatch), так и текстовых описаний используется архитектура Vision Transformer (ViT). MotionPatch преобразует последовательности кадров в патчи, которые затем обрабатываются ViT подобно обработке изображений. Текстовые описания кодируются с помощью стандартного токенизатора и передаются в ViT. В результате как визуальные данные о движении, так и текстовые данные представляются в виде векторов в едином пространстве эмбеддингов, что позволяет модели сопоставлять и анализировать соответствие между ними. Такой подход обеспечивает возможность совместного обучения и извлечения семантически значимых представлений для обоих типов данных.
Компонент Token Compressor является ключевым элементом в процессе Segment-Wise Alignment и предназначен для снижения размерности входных токенов. Это достигается путем применения операций проекции и агрегации, что позволяет уменьшить вычислительные затраты и повысить эффективность обработки последовательностей. Снижение размерности особенно важно при работе с длинными видеопоследовательностями и большими объемами текстовых данных, поскольку уменьшает требования к памяти и ускоряет процесс вычислений без существенной потери информации. Token Compressor позволяет масштабировать модель для работы с более сложными и объемными задачами, сохраняя при этом приемлемую скорость обработки.
Оптимизация обучения модели производится с использованием функции потерь Contrastive Loss, направленной на формирование дискриминативных векторных представлений (embeddings) для последовательностей движений и текстовых описаний. Данный подход способствует сближению представлений семантически схожих пар «движение-текст» в многомерном пространстве, и, наоборот, увеличению расстояния между несвязанными данными. Минимизация Contrastive Loss позволяет модели научиться эффективно сопоставлять визуальные действия с соответствующими лингвистическими описаниями, улучшая качество мультимодального понимания и поиска.
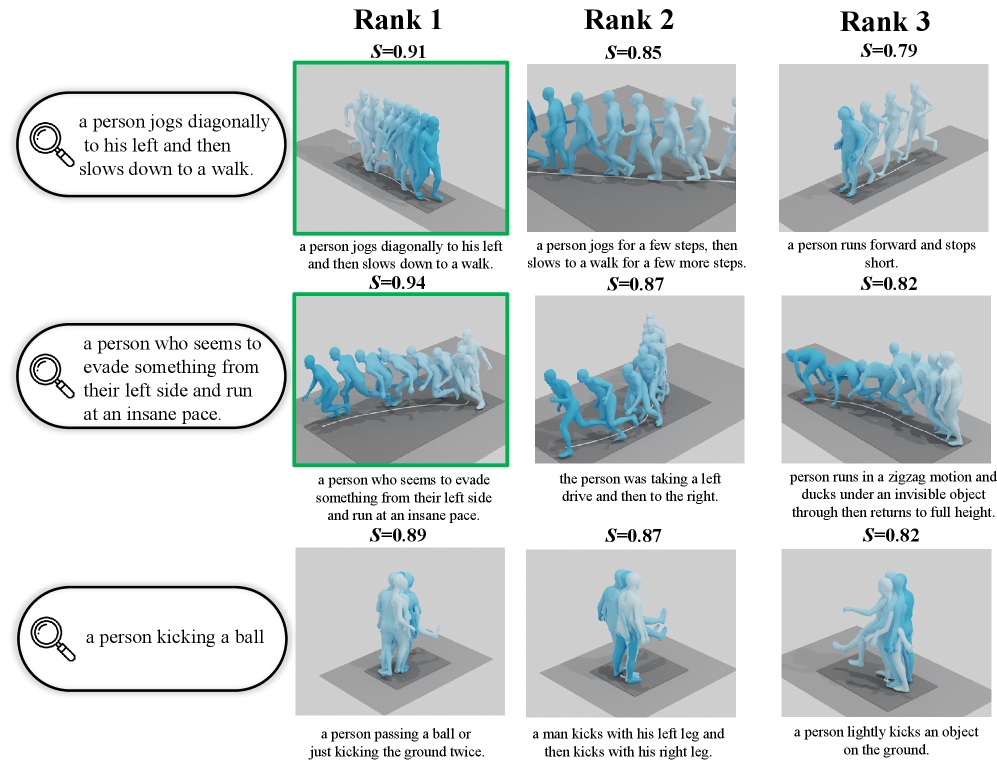
Количественная Оценка и Достигнутые Преимущества
Оценка предложенной модели PST на общедоступных наборах данных HumanML3D и KIT-ML продемонстрировала её превосходство в задаче поиска соответствия между движением и языковым описанием. Результаты показали значительное улучшение ключевых метрик: показатель Recall@1 увеличился на 8.5%, а Recall@5 — на 15.7% по сравнению с существующими методами, основанными на HumanML3D. Такой прирост эффективности подтверждает способность PST более точно извлекать и сопоставлять информацию о движениях, основываясь на предоставленных текстовых запросах, что открывает новые возможности для применения в таких областях, как робототехника и создание анимации.
Стратегия прогрессивного выравнивания, реализованная в PST, позволяет эффективно улавливать тонкие взаимосвязи между движением и языковым описанием. В отличие от существующих подходов, PST не просто сопоставляет общие признаки, а последовательно уточняет соответствия на разных уровнях детализации, что приводит к более точному пониманию семантического содержания движений. Это проявляется в значительном улучшении метрики Median Rank, указывающей на то, что релевантные движения находятся в начале списка результатов поиска чаще, чем при использовании альтернативных методов. Таким образом, система демонстрирует способность не только идентифицировать соответствующие движения, но и ранжировать их по степени соответствия запросу, обеспечивая более удобный и интуитивно понятный пользовательский опыт.
Внедрение больших языковых моделей, таких как Qwen2.5-7B-Instruct, позволило значительно улучшить результаты поиска движений, соответствующих текстовому описанию. В ходе экспериментов было зафиксировано увеличение показателя Recall@1 на 8.5% и Recall@5 на 15.7% по сравнению с предыдущими методами. Это стало возможным благодаря обогащению текстовых описаний, что позволило модели более точно сопоставлять язык и движения. По сути, LLM расширяют возможности понимания и интерпретации текстовых запросов, что приводит к более релевантным результатам поиска и повышает эффективность всей системы.
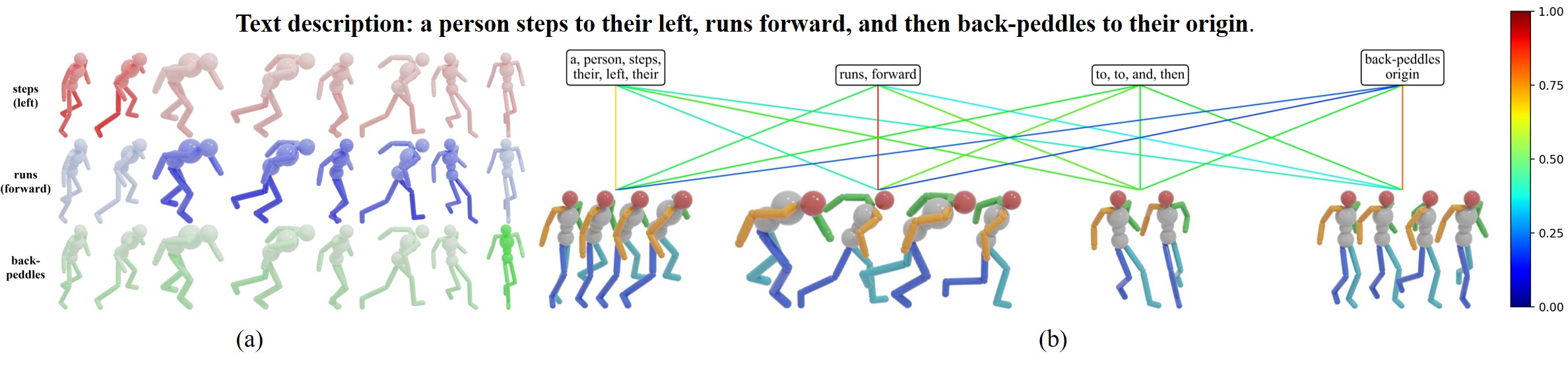
Исследование демонстрирует элегантный подход к задаче извлечения информации о движении на основе языка, переходя от грубого глобального выравнивания к детальному, многоуровневому анализу. Предложенная пирамидальная структура, использующая принцип Shapley-Taylor Interaction, позволяет улавливать тонкие соответствия между визуальными и лингвистическими данными. Как заметил Ян ЛеКун: «Машинное обучение — это искусство позволить компьютерам учиться на опыте». Этот принцип находит свое отражение в способности модели к прогрессивному уточнению понимания взаимосвязей между движением и языком, что является признаком глубокого понимания и гармонии между формой и функцией.
Куда Дальше?
Представленная работа, стремясь к более тонкому сопоставлению движения и языка, подобна настройке сложного музыкального инструмента. Каждый интерфейс звучит, если настроен с вниманием, но даже самая точная настройка не устраняет фундаментальные ограничения самого инструмента. Несмотря на прогресс в улавливании соответствий на различных уровнях — от суставов до целостных движений — остается вопрос о том, насколько адекватно текущие модели отражают истинную сложность взаимосвязи между визуальным и лингвистическим мирами.
Будущие исследования, вероятно, потребуют смещения акцента с простого сопоставления признаков на моделирование намерения и контекста. Очевидно, что недостаточно просто найти соответствие между «поднять руку» и «рука поднимается»; необходимо понимать, почему рука поднимается, и как это действие вписывается в более широкий сценарий. Плохой дизайн кричит, хороший шепчет, но действительно элегантное решение — это когда инструмент исчезает, позволяя слушателю (или наблюдателю) полностью погрузиться в исполняемое.
Стоит также задуматься о расширении спектра данных. Обучение на синтетических или лабораторных данных, безусловно, полезно, но истинное понимание потребует работы с «сырыми», нефильтрованными данными из реального мира — шумными, неполными, противоречивыми. Именно в этой хаотичности и кроется истинная красота, и именно ее модели должны научиться улавливать.
Оригинал статьи: https://arxiv.org/pdf/2601.21904.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Acer Aspire 5 Spin 14 ОБЗОР
- Tecno Pova 7 ОБЗОР: беспроводная зарядка, плавный интерфейс, большой аккумулятор
- Как установить SteamOS на игровые портативные устройства ROG Ally и Legion Go под управлением Windows
- Интервью с создателями фильма «Пятая группа крови»
- Как обновить Windows 10 до 11, используя локальную учётную запись — пошаговое руководство по обходу требования к учётной записи Microsoft.
- Финальное обновление Minecraft года официально здесь — Mounts of Mayhem добавляет сражения верхом в Overworld.
- Motorola Moto G77 ОБЗОР: яркий экран, лёгкий, чёткое изображение
- 10 лучших OLED ноутбуков. Что купить в мае 2026.
- Motorola Edge 70 Ultra ОБЗОР: современный дизайн, скоростная зарядка, огромный накопитель
- Что такое глубина резкости в фотографии?
2026-02-01 03:11