Автор: Денис Аветисян
Новый подход позволяет воссоздавать реалистичные 3D-модели взаимодействия рук с предметами, используя возможности искусственного интеллекта и компьютерного зрения.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
AGILE: фреймворк для реконструкции 3D-взаимодействий рук и объектов из монокулярного видео с использованием агентной генерации и многовидовой согласованности.
Восстановление динамических взаимодействий рук и объектов из монокулярного видео остается сложной задачей, ограничивающей возможности сбора данных для манипуляций и создания реалистичных цифровых двойников. В данной работе, представленной под названием ‘AGILE: Hand-Object Interaction Reconstruction from Video via Agentic Generation’, предложен новый подход, смещающий парадигму с реконструкции на агентурную генерацию для обучения взаимодействиям. AGILE использует Vision-Language Model для синтеза полных, водонепроницаемых 3D-моделей объектов с высококачественными текстурами, обходя ограничения, связанные с окклюзиями и нестабильной инициализацией Structure-from-Motion. Сможет ли подобный подход, основанный на физической достоверности, открыть новые горизонты для применения в робототехнике и виртуальной реальности?
Воссоздание Реальности: Сложность Взаимодействия Руки и Объекта
Точное воссоздание динамических взаимодействий руки и объекта — задача, имеющая первостепенное значение для развития робототехники и технологий дополненной и виртуальной реальности, однако представляющая собой значительную сложность. Восприятие и анализ этих взаимодействий требует не просто определения положения руки и объекта в пространстве, но и понимания намерений, силы воздействия и тонких изменений в форме объекта. Несмотря на прогресс в области компьютерного зрения, существующие методы часто сталкиваются с трудностями при обработке быстрых движений, окклюзий и сложных текстур, что ограничивает возможности создания реалистичных и функциональных систем. Преодоление этих ограничений необходимо для разработки роботов, способных к эффективному манипулированию объектами в реальном мире, а также для создания иммерсивных виртуальных сред, в которых взаимодействие пользователя с цифровыми объектами ощущается естественным и интуитивным.
Традиционные методы трехмерной реконструкции, включая нейронный рендеринг и NeRF (Neural Radiance Fields), часто сталкиваются с проблемами обеспечения согласованности изображения при просмотре с разных углов и не способны полноценно интерпретировать семантическое значение сцены. Эти подходы, хотя и демонстрируют впечатляющие результаты в статичных сценах, испытывают затруднения при реконструкции динамичных взаимодействий, таких как манипуляции с объектами, поскольку им сложно учитывать изменения геометрии и текстуры во времени. Недостаток понимания семантики приводит к тому, что система может точно восстановить форму объекта, но не распознать его функцию или роль во взаимодействии, что ограничивает применение в робототехнике и дополненной реальности. Таким образом, для создания реалистичных и функциональных виртуальных сред, а также для надежного управления роботами, необходимы новые методы, сочетающие геометрическую точность с семантическим пониманием происходящего.
Несмотря на значительный вклад существующих наборов данных, таких как HO3D и DexYCB, в развитие исследований взаимодействия рук и объектов, они не в полной мере отражают всю сложность и многообразие реальных сценариев. Эти наборы данных, как правило, ограничены определенным набором объектов и действий, а также часто используют контролируемые условия съемки, что снижает их применимость к более реалистичным и непредсказуемым ситуациям. Реальные взаимодействия рук с объектами характеризуются значительным разнообразием поз рук, быстрым изменением освещения, частичной окклюзией объектов и сложными траекториями движения, которые трудно адекватно представить в существующих наборах данных. Таким образом, для достижения действительно надежного и универсального решения в области реконструкции взаимодействия рук и объектов требуется создание более масштабных и детализированных наборов данных, способных охватить весь спектр возможных сценариев и обеспечить более реалистичные условия для обучения алгоритмов.

AGILE: Интеллектуальный Подход к 3D-Реконструкции
AGILE представляет собой новый подход к 3D-реконструкции, основанный на парадигме агентного моделирования. В отличие от традиционных методов, где процесс реконструкции является пассивным и автоматическим, AGILE использует языковую модель зрения (Vision-Language Model, VLM) в качестве агента, активно управляющего этапами реконструкции. Этот агент не просто обрабатывает входные данные, но и принимает решения о выборе ключевых кадров и координации синтеза изображений из различных точек зрения, что позволяет добиться более точных и детализированных 3D-моделей. Агентская парадигма предполагает итеративный процесс, в котором VLM-агент анализирует промежуточные результаты и корректирует стратегию реконструкции для достижения оптимального качества.
Агент VLM, работающий на базе Gemini 3 Pro, осуществляет интеллектуальный отбор ключевых кадров для построения 3D-реконструкции. Этот процесс включает в себя анализ входных данных и выбор наиболее информативных кадров, необходимых для синтеза нескольких видов изображения. Оркестровка мульти-видового синтеза выполняется с использованием Gemini 2.5 Flash, что позволяет эффективно генерировать изображения с различных точек обзора. Выбранные ключевые кадры служат основой для создания когерентного и детализированного 3D-представления объекта, обеспечивая оптимальное использование вычислительных ресурсов и повышение качества реконструкции.
Процесс преобразования многовидовых изображений в 3D-модели осуществляется посредством Hunyuan 3D, который генерирует трехмерные сетки на основе входных данных. Для обеспечения физической достоверности результирующих моделей AGILE использует оптимизацию с учетом контактов (Contact-Aware Optimization). Данный подход позволяет учитывать физические ограничения и взаимодействия между частями объекта, предотвращая появление нереалистичных или невозможных конфигураций в итоговой 3D-модели и обеспечивая ее соответствие законам физики.
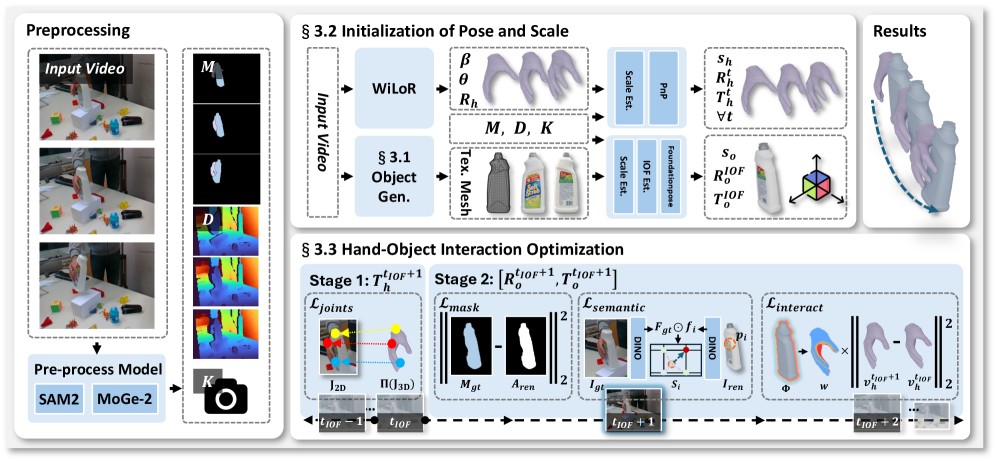
Компоненты Pipeline и Основа для Работы
AGILE использует SAM2 (Segment Anything Model 2) для точной сегментации рук и объектов, что обеспечивает создание масок, необходимых для последующей обработки данных. SAM2, благодаря своей архитектуре, позволяет выделять объекты на изображениях с высокой точностью, даже в сложных условиях освещения и при наличии перекрытий. Полученные маски служат основой для различных задач, включая отслеживание движения рук, распознавание жестов и взаимодействие с объектами, обеспечивая надежную информацию о границах и форме объектов в кадре. Это критически важно для повышения эффективности и точности алгоритмов, используемых в AGILE.
Первоначальная оценка позы объекта осуществляется с использованием FoundationPose, представляющего собой модель, обеспечивающую надежную отправную точку для последующей доработки. FoundationPose использует глубокую нейронную сеть, обученную на обширном наборе данных изображений и соответствующих 3D-моделей, что позволяет эффективно определять пространственное положение и ориентацию объекта в кадре. Полученные результаты служат основой для более точной и детализированной оценки позы, выполняемой на последующих этапах обработки, и позволяют уменьшить вычислительную нагрузку при уточнении параметров позы.
Предварительная обработка данных в AGILE включает в себя использование MoGe-2 для получения надежной метрической оценки глубины. MoGe-2 обеспечивает устойчивую оценку глубины даже в сложных условиях, что значительно повышает качество входных данных для последующих этапов обработки. Алгоритм позволяет получить точные карты глубины, необходимые для сегментации объектов и оценки их положения в пространстве, что критически важно для корректной работы всей системы. Надежность оценки глубины, обеспечиваемая MoGe-2, способствует повышению точности и стабильности работы AGILE в различных сценариях применения.

Подтверждение и Количественные Результаты
Система AGILE демонстрирует беспрецедентный уровень успешности в реконструкции взаимодействий человека и объектов (HOI), достигая 100% результата на сложных эталонных наборах данных, включая HO3D, DexYCB и видеозаписи из реальных условий. Это значительно превосходит показатели существующих решений и устанавливает новый стандарт в области, обеспечивая повышенную геометрическую точность и устойчивость к различным условиям съемки. Достигнутый прорыв указывает на эффективность предложенного подхода, основанного на принципах агентного моделирования, и открывает новые перспективы для развития технологий, связанных с пониманием и анализом визуальной информации.
Для подтверждения качества и физической достоверности трехмерных реконструкций, созданных AGILE, были использованы стандартные метрики, такие как расстояние Чемфера и средняя ошибка проекции суставов (MPJPE). Результаты показали, что AGILE демонстрирует значительно более высокую точность в восстановлении геометрии объектов и положения суставов, чем существующие аналоги. В частности, расстояние Чемфера, равное 0.27 см², свидетельствует о минимальных отклонениях между реконструированной моделью и реальным объектом, а MPJPE в 81.55° указывает на высокую точность определения ключевых точек скелета. Эти количественные показатели подтверждают, что AGILE способна создавать реалистичные и физически правдоподобные трехмерные модели, открывая новые возможности для применения в различных областях, включая робототехнику и компьютерное зрение.
В ходе количественной оценки AGILE продемонстрировал выдающиеся результаты в реконструкции объектов. В частности, метрика Chamfer Distance у AGILE составила всего 0.27 см², что значительно ниже показателя SAM3D, равного 1.35 см². Аналогичным образом, средняя погрешность в предсказании ключевых точек (MPJPE) у AGILE составила 81.55°, что существенно превосходит результат SAM3D — 118.71°. Эти показатели свидетельствуют о высокой точности и надежности AGILE в процессе 3D-реконструкции, подтверждая его способность создавать более реалистичные и физически правдоподобные модели.
Полученные результаты убедительно демонстрируют преимущества парадигмы генерации на основе агентов, реализованной в AGILE, и открывают новые перспективы в области реконструкции взаимодействий человек-объект (HOI). Достигнутая система не только превзошла существующие аналоги по ключевым метрикам, таким как расстояние Чамфера и MPJPE, но и показала исключительную точность и надежность в сложных сценариях, включая реальные видеозаписи. Это свидетельствует о том, что подход, основанный на активном, целеустремленном агенте, способен эффективно решать сложные задачи 3D-реконструкции, что, в свою очередь, может значительно продвинуть исследования в областях робототехники, компьютерного зрения и создания реалистичных виртуальных сред. Подобные достижения укрепляют уверенность в том, что парадигма генерации на основе агентов станет ключевым направлением развития в сфере HOI-реконструкции.

Представленная работа демонстрирует элегантный подход к реконструкции взаимодействия руки и объекта, используя возможности агентной генерации и многовидового синтеза. Эта система, названная AGILE, стремится к созданию высокоточных 3D-моделей, что особенно ценно для последующего физического моделирования. Ян Лекун однажды заметил: «Машинное обучение — это программирование, где вы не программируете, а обучаете». Эта фраза точно отражает суть AGILE, поскольку система не опирается на жестко заданные правила, а обучается на видеоданных, чтобы понять и воссоздать сложные взаимодействия. Такой подход позволяет добиться большей гибкости и реалистичности в реконструкции, чем традиционные методы, подчеркивая гармонию между формой и функцией в машинном обучении.
Куда же дальше?
Представленная работа, несомненно, демонстрирует изящный подход к реконструкции взаимодействия руки и объекта. Однако, подобно любому элегантному решению, она обнажает глубинные вопросы. Настоящая сложность не в достижении фотореалистичной визуализации, а в понимании причинности. Реконструкция — это лишь описание, а предсказание — истинный вызов. Будущие исследования должны сместить фокус с простого воспроизведения наблюдаемого на моделирование скрытых сил и намерений, стоящих за движением.
Подобно тому, как скульптор не просто копирует форму, но и улавливает внутреннюю динамику, так и будущие системы должны стремиться к пониманию физики взаимодействия. Ограничения текущих подходов очевидны: зависимость от больших объемов данных, сложность обобщения на новые сценарии и, что наиболее важно, неспособность к осмысленному планированию. Простая точность — недостаточный критерий; необходима интеллектуальная точность.
Следующим шагом представляется интеграция принципов активного обучения и обратной связи. Система, способная не только воспринимать, но и экспериментировать, задавать вопросы и уточнять свои модели, станет по-настоящему полезным инструментом. И тогда, возможно, мы увидим не просто красивые реконструкции, а системы, способные к осмысленному взаимодействию с миром.
Оригинал статьи: https://arxiv.org/pdf/2602.04672.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Макросъемка
- Космос в деталях: Навигация по астрономическим данным на иммерсивных дисплеях
- vivo S50 Pro mini ОБЗОР: объёмный накопитель, портретная/зум камера, большой аккумулятор
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
- MINISFORUM добавляет опцию Ryzen 9 8945HX в линейку мини-ПК MS-A2
2026-02-06 00:46