Автор: Денис Аветисян
Новое поколение систем взаимодействия с человеком, основанных на больших языковых моделях, ставит перед исследователями вопросы надёжности и стандартов отчётности.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"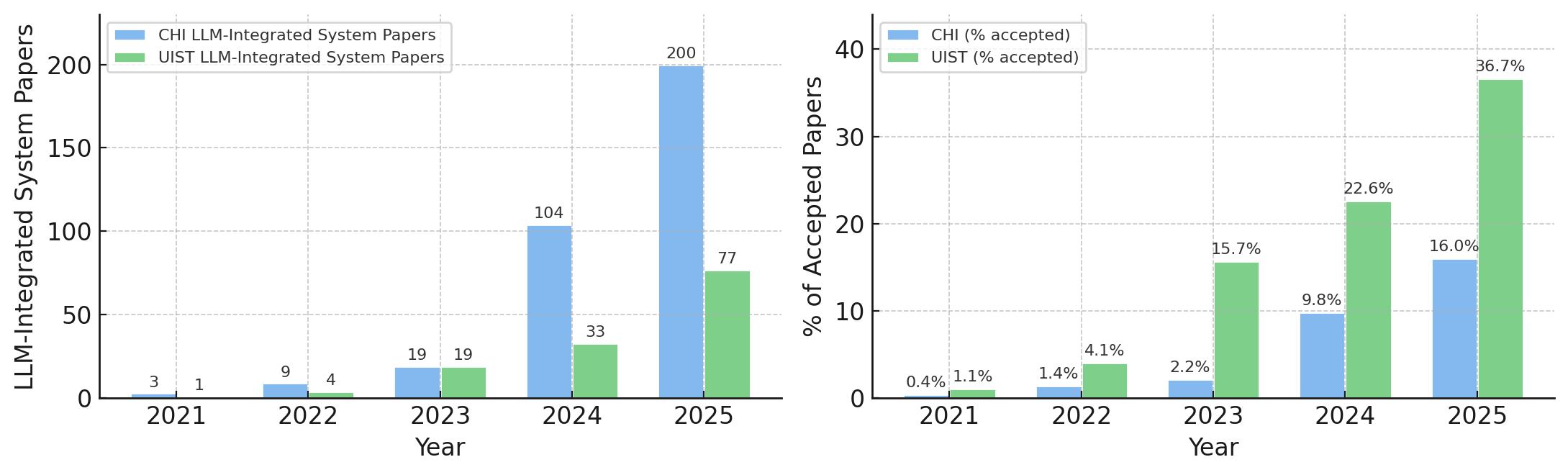
Анализ проблем представления и рецензирования систем, интегрированных с большими языковыми моделями, в контексте исследований взаимодействия человек-компьютер.
Несмотря на растущий интерес к системам, интегрированным с большими языковыми моделями (LLM), их оценка и рецензирование в рамках гуманитарно-ориентированных наук, таких как HCI, сталкивается с новыми вызовами. В своей работе ‘Reporting and Reviewing LLM-Integrated Systems in HCI: Challenges and Considerations’ авторы исследуют эти трудности, выявив снижение доверия между авторами и рецензентами из-за непредсказуемости LLM и преувеличенной риторики вокруг ИИ. Полученные результаты указывают на необходимость пересмотра существующих норм публикации и рецензирования, с акцентом на техническую валидацию и прозрачность, а также на потенциальные разногласия между ценностями сообществ HCI и ML/NLP. Как обеспечить справедливую и эффективную оценку исследований, использующих LLM, и сформировать конструктивный диалог между различными научными дисциплинами?
Раскрытие Новых Горизонтов: HCI и Большие Языковые Модели
Интегрированные системы на основе больших языковых моделей (LLM) стремительно занимают центральное место в исследованиях в области взаимодействия человека и компьютера (HCI), что требует разработки принципиально новых подходов к их оценке. Традиционные методы, ориентированные на измерение удобства использования и эффективности, оказываются недостаточными для анализа сложных систем, способных к адаптации и генерации контента. Возникающая необходимость в более тонких и комплексных метриках обусловлена тем, что LLM-системы не просто выполняют заданные функции, но и участвуют в диалоге с пользователем, требуя оценки не только функциональности, но и качества взаимодействия, когерентности ответов и способности к обучению. Это влечет за собой переосмысление существующих методологий и поиск инновационных способов оценки, учитывающих динамическую природу и непредсказуемость поведения подобных систем.
Традиционные методы оценки удобства использования и эффективности, такие как юзабилити-тестирование с участием пользователей или эвристическая оценка, зачастую оказываются недостаточными применительно к системам, интегрированным с большими языковыми моделями (LLM). Сложность этих систем обусловлена их вероятностной природой и способностью генерировать разнообразные, контекстно-зависимые ответы, что затрудняет определение четких критериев успеха. В отличие от детерминированных систем, где поведение предсказуемо, LLM-интегрированные интерфейсы могут выдавать неожиданные результаты, требующие более тонких и адаптивных методов оценки, учитывающих не только функциональность, но и качество генерируемого контента, а также его соответствие ожиданиям пользователя. Особенно остро встает вопрос об оценке долгосрочного влияния этих систем на когнитивные процессы и пользовательский опыт, что требует разработки новых метрик и методологий.
В связи с растущей интеграцией больших языковых моделей (LLM) в системы взаимодействия человек-компьютер, возникает необходимость критической переоценки процесса экспертной оценки. Исследования показывают, что традиционные методы оценки юзабилити и эффективности оказываются недостаточными для анализа сложности, присущей этим системам. Отмечается тенденция к усилению контроля и более детальному рассмотрению работ, связанных с LLM, в процессе рецензирования. Это выражается в более взыскательных требованиях к обоснованию новизны, воспроизводимости результатов и тщательности экспериментальной проверки, что свидетельствует об адаптации научного сообщества к новым реалиям и необходимости обеспечения высокого качества исследований в данной области.
Построение Доверия в Мире Непрозрачных Систем
Формирование доверия к системам, интегрированным с большими языковыми моделями (LLM), является критически важным, но сопряжено с трудностями. Неопределенность, присущая самим LLM — в частности, их непредсказуемость в генерации ответов и сложность интерпретации процесса принятия решений — создает значительные препятствия для обеспечения надежности и предсказуемости системы. Дополнительную сложность вносит архитектура LLM-интегрированных систем, которые часто представляют собой комплексные взаимодействия между различными компонентами, что затрудняет отслеживание и понимание причинно-следственных связей и, следовательно, оценку общей надежности и безопасности системы.
Прозрачность системы — степень понимания внутренних механизмов её работы — является ключевым фактором формирования доверия к ней. Это означает, что пользователи должны иметь возможность понять, как система принимает решения, какие данные используются в процессе, и какие факторы влияют на результат. Отсутствие прозрачности приводит к недоверию, особенно в контексте сложных систем, таких как системы на основе больших языковых моделей (LLM), где логика принятия решений может быть неочевидной. Понимание принципов работы системы позволяет пользователям оценить её надёжность, предсказуемость и потенциальные ограничения, что, в свою очередь, способствует повышению уверенности в её использовании и результатах.
Открытые модели больших языковых моделей (LLM) значительно повышают прозрачность системы, поскольку их архитектура, веса и процесс обучения доступны для изучения и аудита. В отличие от них, проприетарные модели, как правило, скрывают эти детали, что затрудняет понимание принципов их работы и выявление потенциальных проблем. Это создает напряженность между производительностью — часто более высокой в проприетарных моделях благодаря оптимизации и большему объему данных — и возможностью объяснить и проверить логику работы системы, что критически важно для построения доверия и обеспечения ответственности.
Строгая Оценка в Эпоху LLM
Техническая оценка, основанная на количественных показателях, становится все более востребованной при анализе систем, интегрированных с большими языковыми моделями (LLM). Однако, традиционные метрики и подходы нуждаются в адаптации, поскольку LLM вносят элемент вероятностного поведения и генерации, что требует новых способов измерения производительности. Оценка должна включать метрики, специфичные для LLM, такие как перплексия, BLEU, ROUGE, а также учитывать контекст и качество генерируемого текста. Важно оценивать не только точность, но и такие характеристики, как когерентность, релевантность и отсутствие предвзятости, используя автоматизированные методы и ручную проверку результатов. Кроме того, необходимо учитывать вычислительные затраты и время отклика системы, интегрированной с LLM, для оценки ее общей эффективности.
Несмотря на возрастающую роль технических оценок производительности больших языковых моделей (LLM), методологии пользовательских исследований остаются критически важными для оценки реальной применимости и влияния LLM-интегрированных систем. Пользовательские исследования позволяют выявить проблемы юзабилити, не обнаруживаемые при автоматизированном тестировании, и оценить, насколько эффективно система удовлетворяет потребности конечных пользователей в реальных сценариях использования. Такие исследования включают в себя как количественные методы, такие как сбор данных о времени выполнения задач и количестве ошибок, так и качественные методы, такие как интервью и фокус-группы, направленные на понимание пользовательского опыта и выявление областей для улучшения. Полученные данные необходимы для комплексной оценки системы и обеспечения ее успешного внедрения.
Итеративный подход к разработке компонентов на основе больших языковых моделей (LLM) часто характеризуется отсутствием общепринятых методологических стандартов. Это затрудняет воспроизводимость результатов и оценку надежности разработанных систем. Наш качественный анализ фокусируется на необходимости разработки четких руководств по отчетности, включающих детальное описание этапов итеративной разработки, используемых метрик оценки, конфигурации LLM и данных, используемых для обучения и тестирования. Внедрение таких руководств позволит обеспечить прозрачность процесса разработки, облегчит верификацию результатов другими исследователями и инженерами, а также повысит общую надежность и воспроизводимость LLM-интегрированных систем.
Развитие Систем: Ограничения и Перспективы
Понимание режимов отказа в системах, интегрированных с большими языковыми моделями (LLM), является основополагающим для создания надежных и устойчивых решений. Тщательный анализ потенциальных точек отказа — от ошибок в обработке входных данных и генерации ответов до проблем с интеграцией различных компонентов системы — позволяет выявить слабые места и разработать стратегии смягчения рисков. Исследования показывают, что предвидение и моделирование различных сценариев сбоев, включая непредсказуемые реакции LLM на необычные запросы или некачественные данные, значительно повышает общую стабильность и предсказуемость системы. Игнорирование возможных режимов отказа может привести к серьезным последствиям, включая предоставление неверной информации, нарушение конфиденциальности или полную неработоспособность системы, что подчеркивает критическую важность проактивного подхода к обеспечению надежности LLM-интегрированных решений.
В стремлении к созданию эффективных систем, интегрированных с большими языковыми моделями, часто возникает столкновение между подходами, основанными на позитивистских установках и методами качественного изучения взаимодействия человека и компьютера (HCI). Позитивизм, с его акцентом на количественные данные и стремлением к обобщениям, может упускать из виду нюансы пользовательского опыта, которые выявляются посредством качественных исследований, таких как интервью и наблюдения. Например, строгое измерение времени выполнения задачи может не отражать когнитивную нагрузку или эмоциональное состояние пользователя. Поэтому, для всесторонней оценки и оптимизации подобных систем, необходим комбинированный подход, который интегрирует строгость количественного анализа с глубиной качественного понимания. Такой синергетический метод позволяет не только измерить эффективность системы, но и понять, как и почему пользователи взаимодействуют с ней определенным образом, что критически важно для разработки действительно удобных и полезных инструментов.
Разработка эффективных запросов, или prompt engineering, представляет собой критическую зависимость и оказывает влияние на все компоненты систем, интегрированных с большими языковыми моделями. В то время как возможности prompt engineering позволяют существенно улучшить производительность и точность таких систем, их чувствительность к формулировкам запросов требует особого внимания при оценке. Незначительные изменения в тексте запроса могут приводить к значительным колебаниям в выходных данных, что подчеркивает необходимость комплексного подхода к валидации и тестированию. Игнорирование этой зависимости может привести к непредсказуемому поведению системы и затруднить обеспечение её надежности и воспроизводимости. Поэтому, при оценке LLM-интегрированных систем, необходимо учитывать не только сами модели, но и качество разработанных запросов, а также их влияние на все этапы обработки информации.
Исследование поднимает вопрос о доверии к системам, интегрированным с большими языковыми моделями. Неопределенность в работе этих моделей подрывает уверенность пользователей и требует пересмотра методологий оценки. Наблюдается закономерность: каждое уязвимое место начинается с вопроса, а не с намерения. Как точно определить, что система функционирует предсказуемо, если сама основа её работы — вероятностная модель? Блез Паскаль заметил: «Все проблемы человечества происходят от того, что люди не умеют спокойно сидеть в комнате». В контексте данной работы, эта мысль перекликается с необходимостью спокойного и методичного анализа систем, чтобы выявить скрытые недостатки и обеспечить их надежность. Недостаток прозрачности в работе LLM-интегрированных систем порождает недоверие, требуя разработки новых стандартов отчетности и технической валидации.
Что дальше?
Анализ представленных систем, интегрированных с большими языковыми моделями, неизбежно наталкивает на вопрос: не является ли сама вера в «интеллект» этих систем — лишь очередным удобным самообманом? Упор на прозрачность, предложенный в данной работе, — не просто методологическая рекомендация, но признание того, что мы имеем дело с системами, чья внутренняя работа зачастую непрозрачна даже для их создателей. Требование технической валидации — это попытка не столько оценить эффективность, сколько хотя бы частично реконструировать логику, скрытую за завесой вероятностных вычислений.
Очевидно, что традиционные методы оценки, ориентированные на «черные ящики», становятся все менее применимыми. Будущие исследования должны быть сосредоточены на разработке инструментов, позволяющих не просто тестировать результат, но и исследовать процесс принятия решений внутри LLM. Необходимо сместить акцент с оценки «интеллекта» на понимание ограничений и предвзятостей этих систем, а также на разработку методов смягчения их негативного влияния.
В конечном итоге, истинный прогресс в области взаимодействия человека и компьютера с использованием LLM заключается не в создании все более сложных и непрозрачных систем, а в разработке инструментов, которые позволяют человеку контролировать и понимать эти системы, а не подчиняться им. Иначе говоря, задача состоит не в том, чтобы «взломать» человеческий мозг с помощью искусственного, а в том, чтобы использовать искусственный интеллект для расширения возможностей человеческого разума.
Оригинал статьи: https://arxiv.org/pdf/2602.05128.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Acer Aspire 5 Spin 14 ОБЗОР
- Huawei nova 15 Max ОБЗОР
- 10 лучших OLED ноутбуков. Что купить в мае 2026.
- Tecno Pova 7 ОБЗОР: беспроводная зарядка, плавный интерфейс, большой аккумулятор
- Honor 600 ОБЗОР: отличная камера, объёмный накопитель, плавный интерфейс
- Российский рынок: дефляция, рубль и геополитика – обзор ключевых событий недели (06.05.2026 19:32)
- Xiaomi Redmi 10C ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков
- Oppo Find X9s Pro ОБЗОР: скоростная зарядка, современный дизайн, замедленная съёмка видео
- Wiko Hi Enjoy 60s ОБЗОР: быстрый сенсор отпечатков, большой аккумулятор
- ВИ.РУ акции прогноз. Цена VSEH
2026-02-06 17:36