Автор: Денис Аветисян
Исследователи представили инновационную систему, способную лучше понимать видеоконтент благодаря одновременной обработке видео- и аудиоинформации и учету намерений пользователя.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"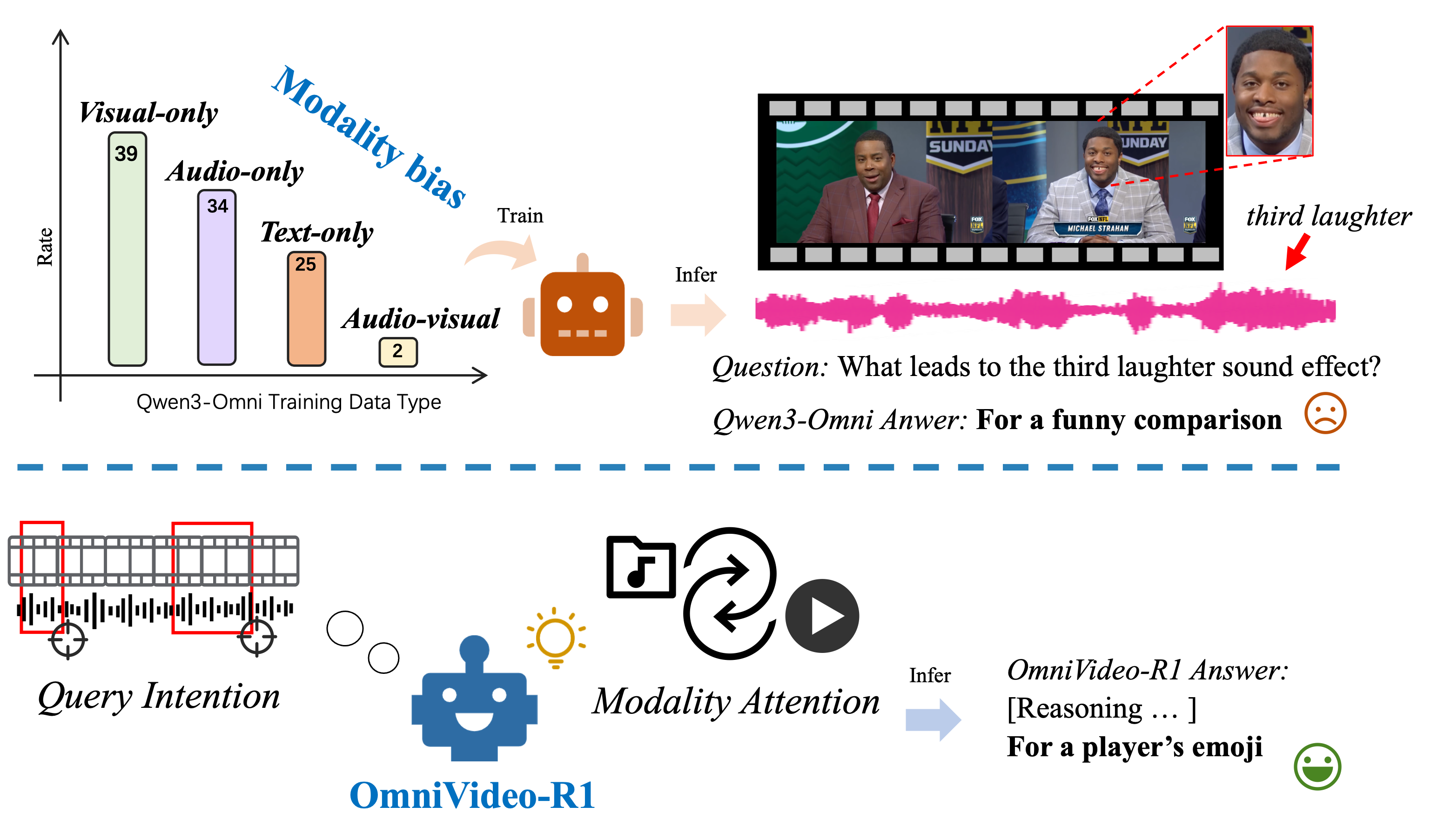
Представленный фреймворк OmniVideo-R1 использует обучение с подкреплением, внимание к модальности и учет запросов пользователя для улучшения аудиовизуального рассуждения в больших языковых моделях.
Несмотря на способность человека к целостному восприятию мира через различные модальности, современные модели обработки мультимедийных данных все еще испытывают трудности в эффективном понимании аудиовизуальной информации. В данной работе представлена модель ‘OmniVideo-R1: Reinforcing Audio-visual Reasoning with Query Intention and Modality Attention’ — новый метод обучения с подкреплением, направленный на улучшение рассуждений, основанных на анализе аудио- и видеоданных. Ключевой особенностью OmniVideo-R1 является акцент на понимании намерения запроса и внимании к различным модальностям, что позволяет достичь значительного прироста производительности на ряде бенчмарков. Сможет ли предложенный подход стать основой для создания более интеллектуальных систем, способных к комплексному пониманию окружающего мира?
Проблема Холистического Восприятия
Современные модели искусственного интеллекта зачастую испытывают трудности при выполнении задач, требующих одновременной обработки и интеграции аудио- и визуальной информации. Вместо полноценного аудиовизуального рассуждения, системы склонны анализировать каждый канал данных по отдельности, что приводит к упущению важного контекста и взаимосвязей. Неспособность эффективно объединять звуковые и визуальные сигналы ограничивает возможности систем в распознавании сложных событий, например, понимании происходящего в динамичных сценах или интерпретации человеческой речи в шумной обстановке. Это несоответствие между принципами работы моделей и сложностью реального мира представляет собой значительный вызов для развития действительно интеллектуальных систем.
Ограничение в эффективной интеграции аудио- и визуальной информации существенно снижает производительность систем в сложных сценариях, требующих понимания контекста и взаимодействия между звуком и изображением. Например, при анализе видео с городской улицы, система может неверно интерпретировать происходящее, если игнорирует звуки сирены или голоса, указывающие на чрезвычайную ситуацию. Подобные недостатки особенно заметны в задачах, где контекст играет ключевую роль, таких как распознавание действий, понимание эмоционального состояния людей или навигация в динамичной среде. Неспособность учитывать взаимосвязь между звуком и визуальными сигналами приводит к ошибкам в принятии решений и снижает общую надежность систем искусственного интеллекта в реальных условиях.
Существующие методы обработки аудиовизуальной информации часто демонстрируют предвзятость к одному из каналов восприятия — так называемый “модальный уклон”. Это означает, что система может чрезмерно полагаться на визуальные данные, игнорируя важные звуковые сигналы, или наоборот. Такое поведение приводит к ошибкам в ситуациях, когда полноценное понимание требует интеграции информации из обоих источников. Например, при распознавании событий в шумной обстановке, система, ориентирующаяся преимущественно на визуальные данные, может неверно интерпретировать происходящее, упуская ключевые звуковые подсказки. Преодоление модального уклона является важной задачей для создания действительно интеллектуальных систем, способных к комплексному и достоверному восприятию окружающего мира.

OmniVideo-R1: Рамки Интегрированного Рассуждения
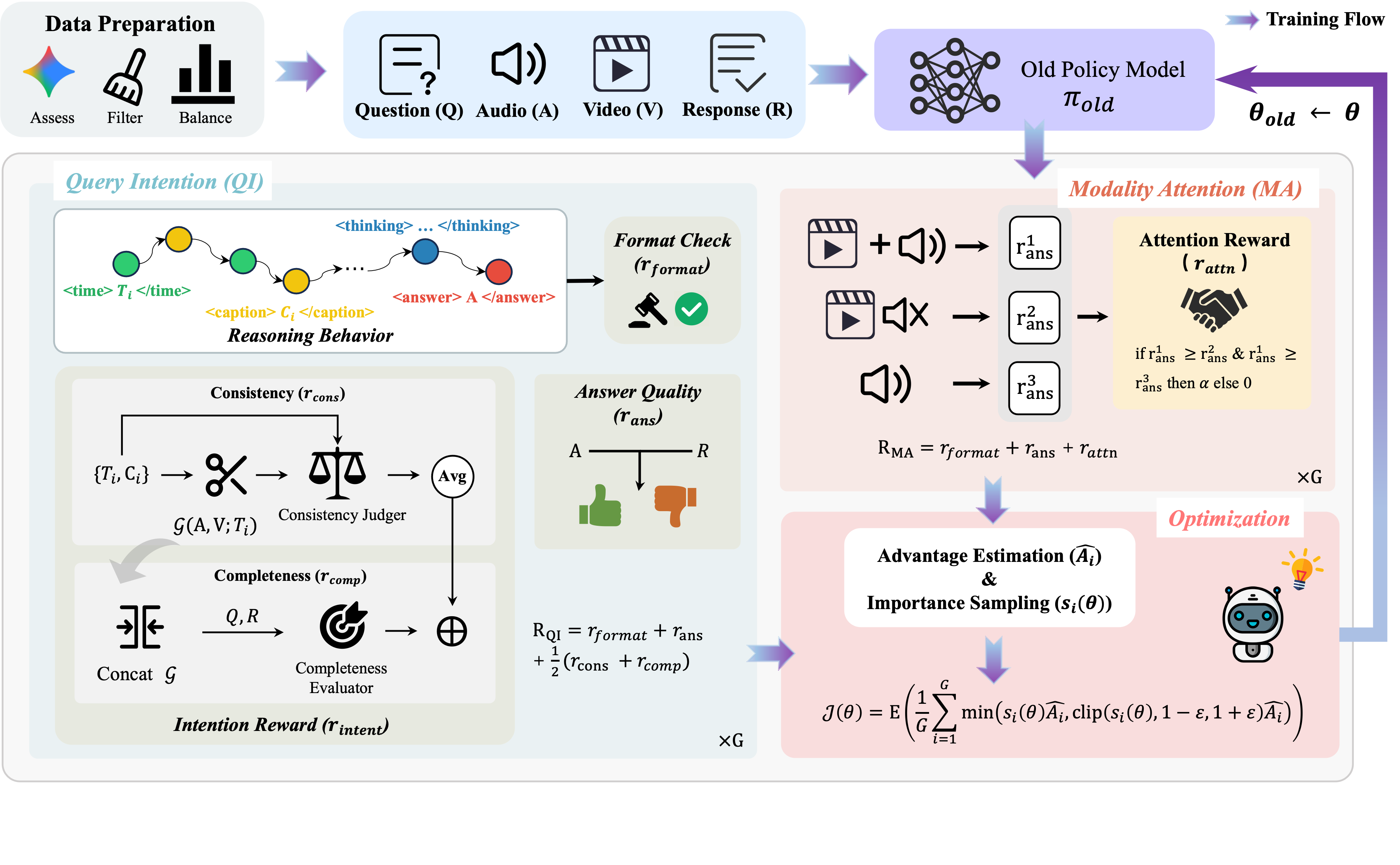
OmniVideo-R1 использует обучение с подкреплением для оптимизации интеграции аудио- и визуальных сигналов, что способствует повышению возможностей модели в области логического мышления. Процесс обучения с подкреплением позволяет модели динамически адаптировать веса, придаваемые различным модальностям, в зависимости от контекста и сложности задачи. Это достигается путем определения функции вознаграждения, которая оценивает качество ответов модели на основе согласованности между аудио, видео и предложенным решением. Посредством итеративного процесса проб и ошибок, модель учится эффективно комбинировать информацию из обоих источников, максимизируя точность и надежность своих выводов, особенно в сложных сценариях, где требуется сопоставление и интерпретация разнородных данных.
Ключевым компонентом OmniVideo-R1 является механизм ‘Query-Intensive Grounding’, предназначенный для повышения эффективности обработки мультимодальных данных. Данный механизм фокусирует внимание модели на релевантных сегментах аудио- и видеопотока до генерации ответа. Это достигается за счет явного выделения и анализа только тех участков данных, которые соответствуют текущему запросу, что позволяет избежать обработки избыточной информации и снизить вычислительную нагрузку. В процессе ‘Query-Intensive Grounding’ модель идентифицирует наиболее важные аудио- и видеофрагменты, формируя контекст для последующего логического вывода и генерации ответа.
Механизм “Модально-внимательного слияния” в OmniVideo-R1 использует контрастное обучение для максимизации использования как аудио-, так и видеоданных. Этот процесс заставляет модель различать и эффективно использовать уникальную информацию, содержащуюся в каждой модальности. Контрастное обучение заключается в обучении модели отличать релевантные аудиовизуальные сегменты от нерелевантных, а также различать уникальные признаки, присутствующие только в аудио или только в видео. Это достигается путем формирования пар положительных и отрицательных примеров, где положительные примеры — это согласованные аудиовизуальные фрагменты, а отрицательные — несогласованные или нерелевантные. В результате модель учится создавать более надежные и точные представления, используя сильные стороны обеих модальностей.
Валидация OmniVideo-R1: Бенчмаркинг Производительности
Для оценки производительности модели OmniVideo-R1 был проведен комплексный набор тестов, включающий в себя бенчмарки OmniVideoBench, Daily-Omni, WorldSense и IntentBench. Данные бенчмарки были выбраны для всесторонней проверки возможностей модели в различных сценариях, охватывающих понимание видео, распознавание действий и интерпретацию намерений. Использование этих стандартизированных тестов позволило объективно сравнить производительность OmniVideo-R1 с существующими решениями и выявить её сильные стороны в области мультимодального анализа видео.
В ходе оценки, модель OmniVideo-R1 продемонстрировала превосходство над существующими решениями на наборе данных Daily-Omni, достигнув точности в 82.8%. Этот показатель на 2.1% выше, чем у модели Gemini3-Pro, что подтверждает более высокую эффективность OmniVideo-R1 в задачах, представленных в данном бенчмарке. Результаты свидетельствуют о значительном улучшении способности модели к точному пониманию и обработке повседневных видеоданных.
Модель OmniVideo-R1 демонстрирует превосходные результаты в задачах анализа видео, достигая точности в 82.8% на бенчмарке Daily-Omni, что на 4.3% выше, чем у модели Video-SALMONN 2+-72B. Кроме того, на бенчмарке IntentBench модель достигла точности 74.2%, опережая Gemini3-Pro на 3.8%. Данные результаты подтверждают эффективность OmniVideo-R1 в задачах, требующих понимания намерений и контекста в видеоматериалах.
В ходе тестирования на наборе данных WorldSense, модель OmniVideo-R1 продемонстрировала точность 44.8%, что на 21.1% выше, чем у модели Qwen3-Omni-30B-A3B. Дополнительно, на наборах данных Video-MME и LVBench были достигнуты показатели точности в 73.6% и 51.9% соответственно, что представляет собой улучшение на 4.4% и 3.4% по сравнению с базовой моделью.

За Пределами Бенчмарков: К Надёжному Мультимодальному Искусственному Интеллекту
Разработанный подход OmniVideo-R1 к мультимодальному рассуждению открывает широкие перспективы для различных областей применения. В робототехнике это позволит создавать более адаптивные и надежные системы, способные эффективно взаимодействовать с окружающей средой, используя данные из нескольких источников. Автономные транспортные средства смогут точнее оценивать дорожную обстановку, объединяя визуальную информацию с данными лидаров и радаров. В сфере анализа видео OmniVideo-R1 предоставляет инструменты для более глубокого понимания содержания, например, для автоматического поиска и классификации объектов или действий. Кроме того, технология может быть использована для создания вспомогательных технологий, улучшающих качество жизни людей с ограниченными возможностями, обеспечивая более точное распознавание речи, жестов и визуальных сигналов.
Снижение предвзятости к отдельным модальностям данных является ключевым фактором повышения надёжности и устойчивости систем искусственного интеллекта в реальных условиях. Исследования показывают, что модели, склонные к чрезмерной зависимости от одной модальности — например, только от визуальной информации или только от звука — демонстрируют снижение производительности при изменении условий или наличии шумов. Устранение этой предвзятости позволяет создавать системы, способные более эффективно интегрировать информацию из различных источников, что критически важно для таких приложений, как автономное вождение, робототехника и анализ видеоконтента. Более сбалансированный подход к обработке мультимодальных данных обеспечивает более точные и надёжные результаты, особенно в сложных и непредсказуемых сценариях, приближая искусственный интеллект к решению практических задач.
Предстоящие исследования направлены на расширение возможностей разработанного подхода, в частности, за счет применения к более сложным наборам данных и включения большего числа модальностей. Особое внимание уделяется интеграции с большими языковыми моделями, такими как Qwen3-Omni-30B-A3B, что позволит значительно улучшить способность системы к комплексному анализу и принятию решений в различных сценариях. Успешная реализация этих направлений позволит создать действительно универсальные и надежные мультимодальные системы искусственного интеллекта, способные эффективно функционировать в реальном мире и решать широкий спектр задач.

Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных к комплексному аудиовизуальному рассуждению. Авторы, фокусируясь на намерении запроса и внимании к модальности, фактически пытаются выявить те устойчивые характеристики, которые остаются актуальными при увеличении сложности задачи. Как однажды заметил Клод Шеннон: «Теория коммуникации должна быть математически строгой». Этот принцип находит отражение в подходе, предложенном в статье, где акцент делается на формализации процессов обработки аудиовизуальной информации и построении алгоритмов, способных к доказуемой корректности. По сути, предлагается решение, которое не просто «работает», но и демонстрирует свою устойчивость к изменениям и возрастающей сложности входных данных, что соответствует фундаментальному стремлению к математической чистоте и элегантности в проектировании систем искусственного интеллекта.
Что Дальше?
Представленная работа, хотя и демонстрирует улучшение в области аудиовизуального рассуждения, лишь подчёркивает фундаментальную сложность задачи. Успех, достигаемый за счёт внимания к намерениям запроса и модальному вниманию, не является принципиальным решением, а скорее тонкой настройкой существующего аппарата. Следует признать, что истинное понимание мультимодальной информации требует не просто корреляции сигналов, а построения непротиворечивой внутренней модели мира. Любое решение, опирающееся на эмпирические наблюдения, неминуемо столкнётся с граничными случаями, в которых статистическая закономерность рушится.
Перспективы дальнейших исследований, следовательно, лежат в плоскости формализации семантических связей. Необходимо разработать алгоритмы, способные не просто «видеть» и «слышать», но и «понимать» причинно-следственные связи, контекст и намерения. Использование формальных методов, таких как логика и теория категорий, может предоставить инструменты для построения доказуемо корректных систем, свободных от присущей современным моделям хрупкости. Любая оптимизация, не подкреплённая математической строгостью, — это лишь временное облегчение симптомов, а не излечение болезни.
В конечном итоге, оценка прогресса в данной области должна основываться не на показателях точности на отдельных датасетах, а на способности системы обобщать знания и адаптироваться к принципиально новым ситуациям. Истинная элегантность решения заключается в его минимализме и математической чистоте. Всё лишнее — потенциальная ошибка.
Оригинал статьи: https://arxiv.org/pdf/2602.05847.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обзор Motorola Razr 50 Ultra
- Huawei nova 15 Max ОБЗОР
- Acer Aspire 5 Spin 14 ОБЗОР
- ВИ.РУ акции прогноз. Цена VSEH
- Realme 15T ОБЗОР: плавный интерфейс, лёгкий, скоростная зарядка
- Honor 600 ОБЗОР: отличная камера, объёмный накопитель, плавный интерфейс
- Российский рынок: от оттока наличных к смешанной динамике и ожиданиям ЦБ (07.05.2026 20:32)
- Как фотографировать огонь.
- Nikon D7200
- Что купить фотографу. Рекомендации
2026-02-07 20:28