Автор: Денис Аветисян
В статье представлена архитектура CAViT, усовершенствование Vision Transformer, позволяющее динамически смешивать признаки для повышения эффективности и точности.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"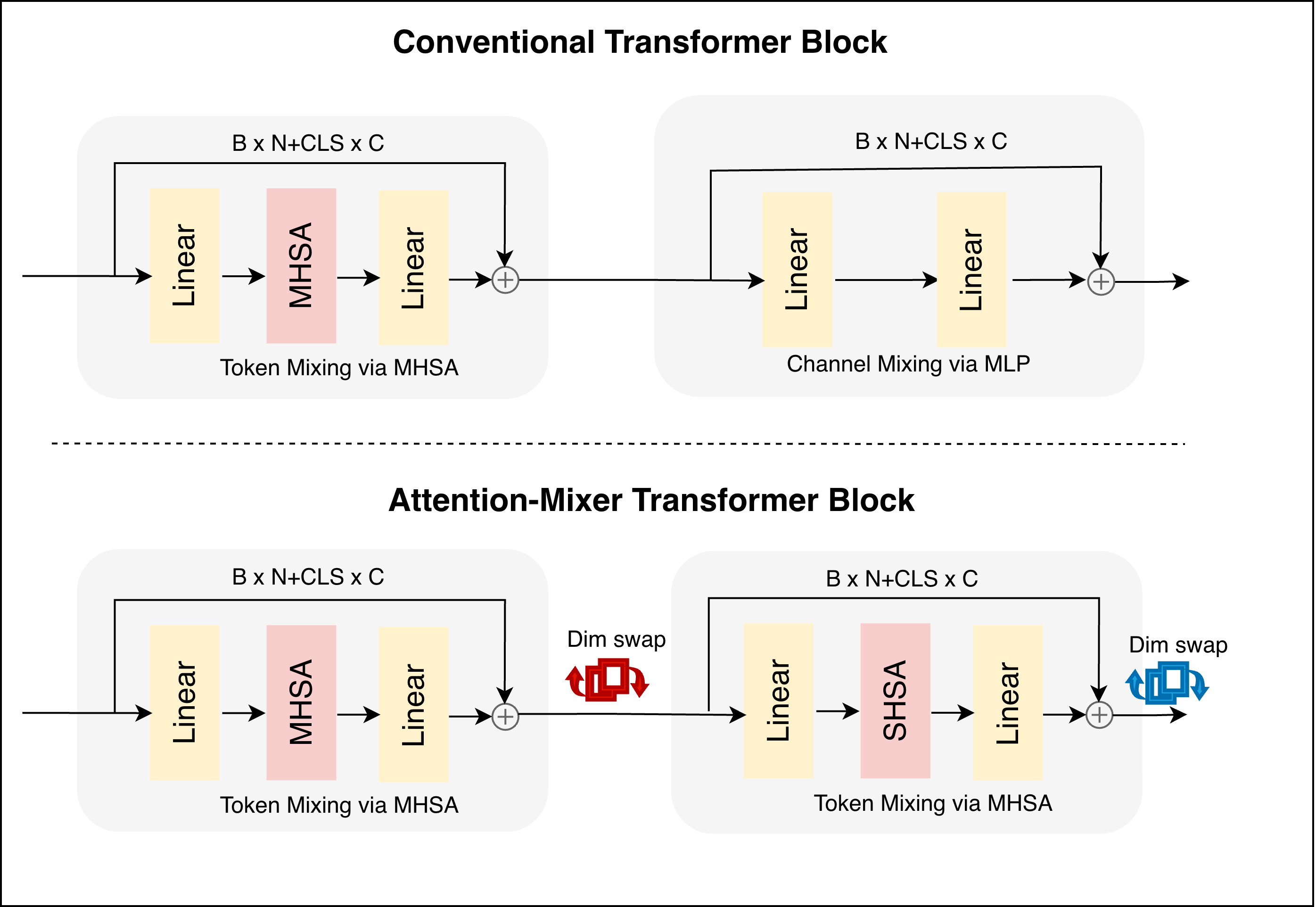
CAViT заменяет стандартные MLP слои в Vision Transformer механизмом канального внимания, использующим переключение размерности, что улучшает производительность без увеличения сложности модели.
Несмотря на успехи Vision Transformers (ViT) в задачах компьютерного зрения, статичные механизмы смешивания каналов ограничивают их адаптивность к входным данным. В данной работе представлена архитектура ‘CAViT — Channel-Aware Vision Transformer for Dynamic Feature Fusion’, заменяющая традиционные многослойные перцептроны динамичным механизмом, основанным на внимании, для взаимодействия признаков. CAViT использует двойное внимание и переключение размерностей, позволяя модели динамически перекалибровать представления признаков, повышая выразительность без увеличения глубины или сложности. Может ли предложенный подход стать основой для создания более эффективных и адаптивных моделей компьютерного зрения в различных областях?
Визуальные Трансформеры: Новый Взгляд на Зрение Машин
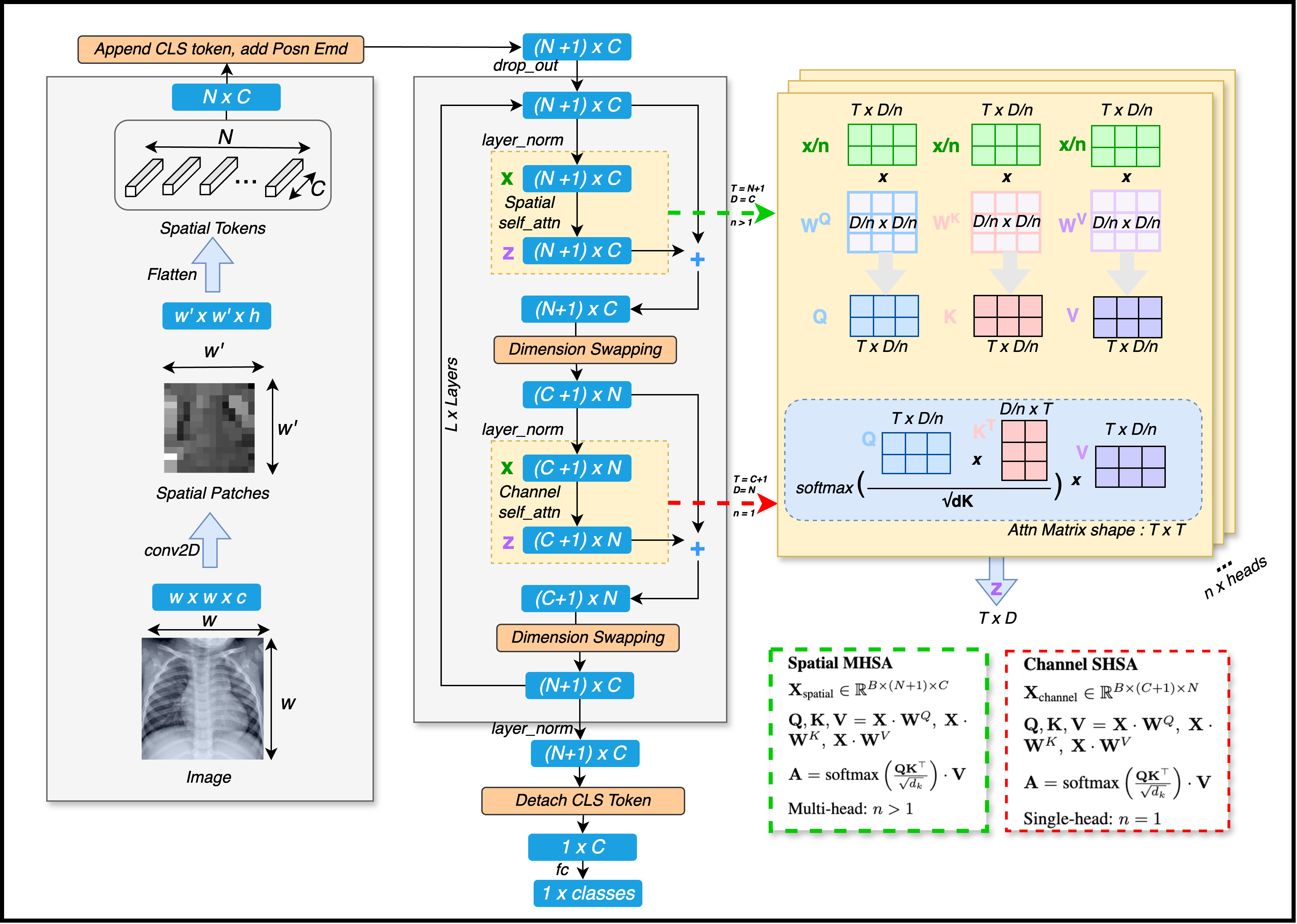
Визуальные трансформаторы (ViT) стремительно завоевали признание в области компьютерного зрения, предложив альтернативу традиционным свёрточным нейронным сетям. Этот новый подход заключается в адаптации архитектуры трансформаторов, изначально разработанной для обработки последовательностей в задачах обработки естественного языка, к анализу изображений. Вместо использования свёрточных слоёв для извлечения признаков, ViT рассматривает изображение как последовательность небольших фрагментов, что позволяет применять механизм самовнимания для установления взаимосвязей между различными частями изображения. Такой подход позволяет моделям лучше улавливать глобальный контекст и сложные зависимости в визуальных данных, открывая новые возможности для решения широкого спектра задач компьютерного зрения, включая классификацию изображений, обнаружение объектов и сегментацию.
Визуальные трансформаторы (ViT) достигают обработки изображений посредством инновационного подхода, рассматривающего каждое изображение как последовательность дискретных фрагментов, именуемых “patch tokens”. Вместо традиционного анализа пикселей, изображение разбивается на небольшие, неперекрывающиеся участки, каждый из которых преобразуется в векторное представление. Эта последовательность токенов затем подается на вход механизма самовнимания (self-attention), аналогичного тому, что используется в обработке естественного языка. Само внимание позволяет модели устанавливать связи между различными фрагментами изображения, выявляя зависимости и контекст, что обеспечивает эффективное извлечение признаков и понимание общей картины, представленной изображением. Таким образом, ViT эффективно применяет принципы, успешно зарекомендовавшие себя в лингвистике, к задаче компьютерного зрения, открывая новые возможности в области анализа и интерпретации визуальной информации.
Стандартные Vision Transformers (ViT) демонстрируют высокую эффективность, однако их вычислительная сложность представляет собой значительное ограничение. Основная причина кроется в использовании механизма Multi-Head Self-Attention, требующего огромных ресурсов для обработки взаимосвязей между каждым «патчем» изображения. Кроме того, для смешивания признаков в ViT традиционно применяются статические многослойные персептроны (MLP), которые, хотя и просты в реализации, не позволяют динамически адаптироваться к особенностям входного изображения и вносят вклад в общую вычислительную нагрузку. В результате, для достижения высокой производительности ViT зачастую требуется значительное количество вычислительных ресурсов и памяти, что затрудняет их применение на устройствах с ограниченными возможностями и в задачах, требующих обработки больших объемов данных в реальном времени.
Узкое Горлышко Смешивания Признаков
В традиционных Vision Transformer (ViT) для смешивания каналов используется статический многослойный персептрон (MLP). Этот MLP выполняет линейное преобразование признаков по каналам, однако не обладает способностью динамически адаптироваться к сложным взаимосвязям между этими каналами. В отличие от механизмов, способных к контекстно-зависимому взаимодействию, статический MLP применяет одни и те же веса ко всем входным данным, ограничивая его способность моделировать нелинейные зависимости и учитывать семантическую роль различных компонентов изображения. Это приводит к снижению выразительности модели и затрудняет эффективное представление сложных визуальных сцен.
Эффективное взаимодействие признаков играет ключевую роль в представлении семантической роли различных компонентов изображения и повышении выразительности модели. Способность модели правильно интерпретировать взаимосвязи между признаками позволяет ей более точно определять объекты, их атрибуты и контекст, что критически важно для задач компьютерного зрения. Недостаточное взаимодействие признаков ограничивает способность модели к обобщению и снижает точность распознавания, особенно в сложных сценах с перекрывающимися объектами или при наличии шума. Повышение эффективности взаимодействия признаков позволяет модели лучше понимать структуру изображения и, как следствие, повышает ее производительность в различных задачах, таких как классификация, обнаружение объектов и сегментация изображений.
Вычислительная сложность как многослойного персептрона (MLP), так и механизма многоголового самовнимания (Multi-Head Self-Attention) оказывает существенное влияние на общую вычислительную нагрузку, измеряемую в операциях с плавающей точкой (FLOPs). Анализ показывает, что вклад этих компонентов может составлять значительную долю от общего числа FLOPs, особенно при обработке изображений высокого разрешения или больших объемов данных. Увеличение числа параметров в MLP и количества голов в механизме самовнимания напрямую увеличивает вычислительные затраты, что ограничивает масштабируемость и эффективность модели на ограниченных аппаратных ресурсах. Оптимизация архитектуры и применение методов квантизации и прунинга направлены на снижение вычислительной сложности этих компонентов для повышения производительности и снижения энергопотребления.
CAViT: Канальное Внимание для Эффективных ViT
В архитектуре CAViT традиционный статический многослойный персептрон (MLP) заменен механизмом внимания, работающим по каналам. Этот подход позволяет динамически смешивать признаки, в отличие от фиксированных весов в MLP. Вместо применения MLP к каждому токену независимо, CAViT использует внимание для определения важности каждого канала признаков относительно других, что позволяет модели адаптировать процесс смешивания признаков в зависимости от входных данных и улучшает способность к обобщению. Это динамическое смешивание признаков позволяет более эффективно использовать вычислительные ресурсы и достигать сравнимой или более высокой производительности, чем при использовании стандартных MLP слоев.
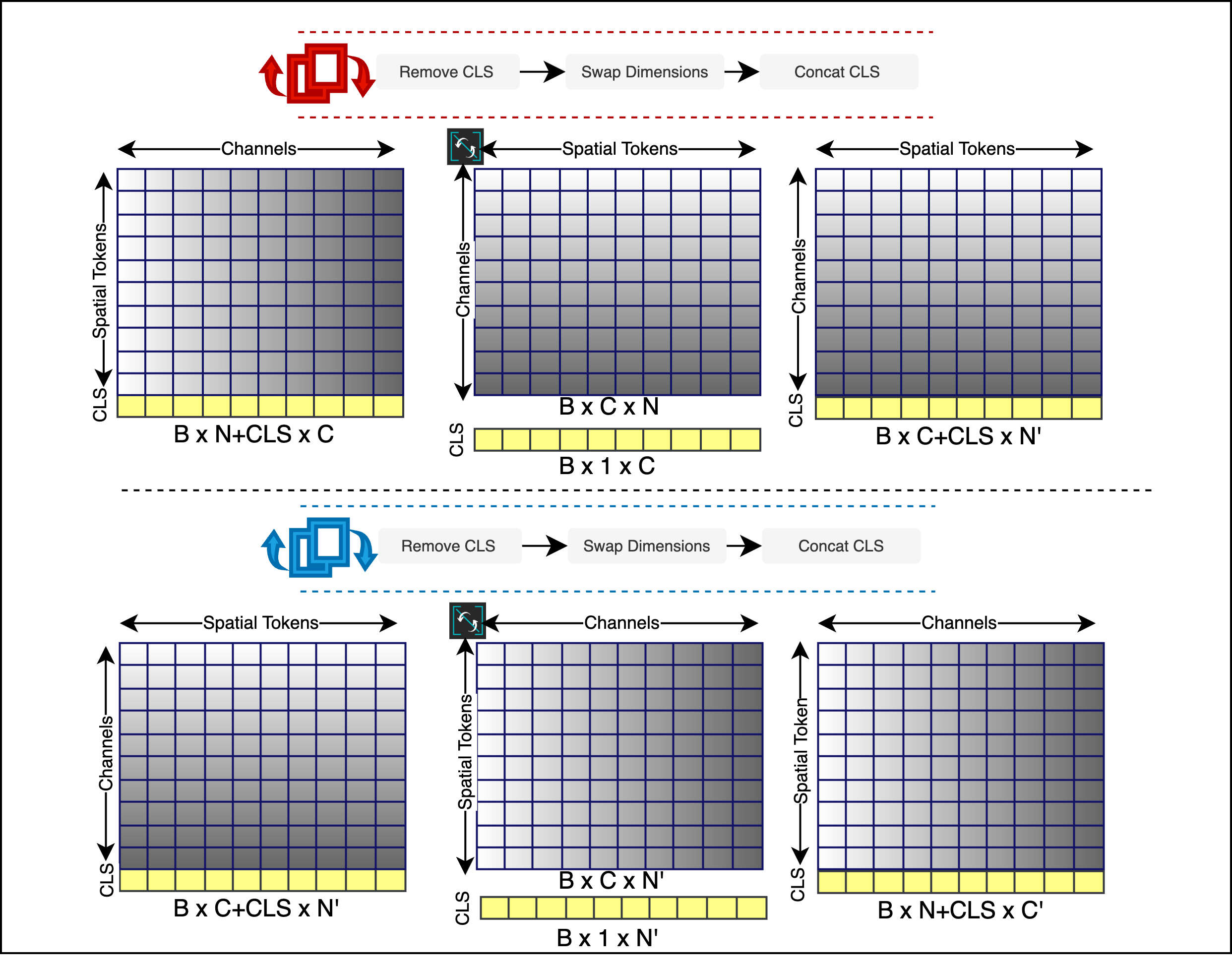
В основе реализации CAViT лежит механизм перестановки размерностей (dimension swapping), который заключается в переупорядочивании тензорных данных перед применением одноканального самовнимания. Данный процесс позволяет преобразовать исходный тензор X \in R^{C \times H \times W} в тензор X' \in R^{H \times W \times C}, где C — количество каналов, H — высота, W — ширина. Такая перестановка позволяет рассматривать каналы как последовательность, к которой можно применить одноканальное самовнимание, что снижает вычислительную сложность по сравнению со стандартным многоканальным самовниманием, сохраняя при этом возможность моделировать взаимосвязи между различными каналами признаков.
В CAViT используется механизм одиночной головы самовнимания (Single-Head Self-Attention) для снижения вычислительных затрат при сохранении высокой производительности. Вместо традиционных многоголовых механизмов, применяющих несколько параллельных операций внимания, CAViT использует одну голову, что значительно уменьшает количество параметров и операций умножения матриц. Это достигается за счет эффективной обработки информации по каналам признаков, позволяя модели динамически взвешивать вклад каждого канала в процесс взаимодействия признаков, сохраняя при этом способность к моделированию сложных зависимостей и улучшая общую эффективность модели по сравнению со стандартными Vision Transformers.
Влияние и Результаты CAViT
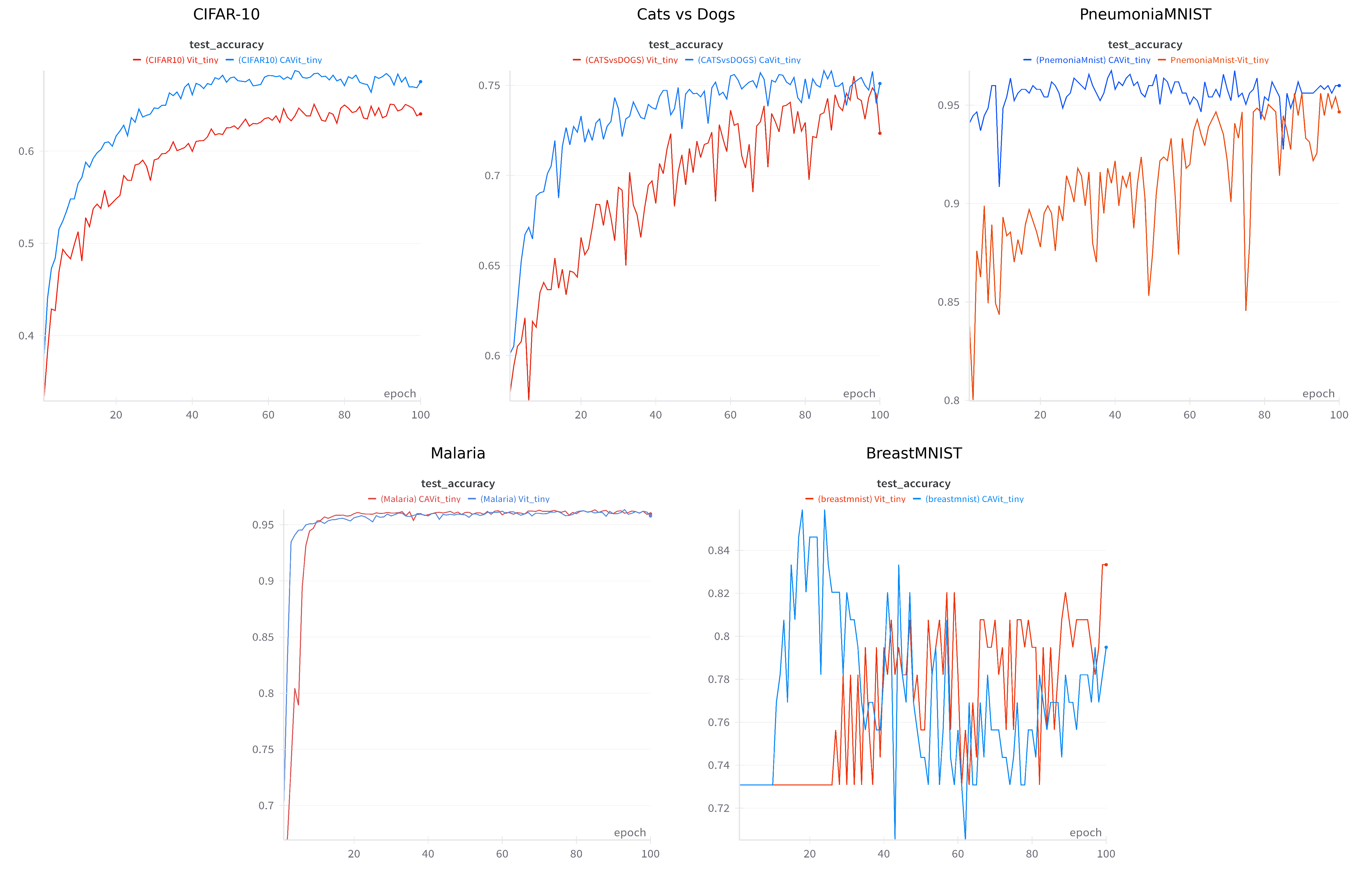
Исследования показали, что архитектура CAViT демонстрирует повышенную выразительность и конкурентоспособную производительность по сравнению со стандартными Vision Transformers (ViT). В частности, на широко используемом наборе данных CIFAR-10, CAViT достиг точности Top-1 в 92.88%, что на 3.64% превосходит результаты стандартной модели ViT-tiny. Данный прирост точности указывает на улучшенную способность CAViT к извлечению и обобщению признаков, что делает её перспективным решением для задач компьютерного зрения, требующих высокой точности классификации изображений.
В ходе исследований, направленных на повышение точности медицинской диагностики, архитектура CAViT продемонстрировала значительное превосходство над стандартными ViT-tiny моделями в задачах классификации медицинских изображений. В частности, при анализе набора данных BreastMNIST, CAViT достигла точности в 96.51%, что на 2.50% выше показателей стандартной модели. Аналогичные результаты были получены и на наборе данных PneumoniaMNIST, где точность CAViT составила 91.87%, превзойдя ViT-tiny на 1.14%. Эти улучшения свидетельствуют о потенциале CAViT для более эффективного и точного анализа медицинских изображений, что может способствовать ранней диагностике и улучшению результатов лечения.
Архитектура CAViT демонстрирует значительные улучшения в эффективности вычислений по сравнению со стандартными ViT. В ходе исследований было установлено, что CAViT требует на 32% меньше параметров и на 33% меньше операций с плавающей точкой (FLOPs) для достижения сопоставимых или даже более высоких результатов. Это снижение вычислительной нагрузки открывает возможности для развертывания моделей на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые системы, а также для ускорения процессов обучения и инференса. Данные показатели свидетельствуют о том, что CAViT представляет собой перспективное решение для приложений, требующих высокой производительности и энергоэффективности.
Будущее Развитие: К Адаптивным Системам Зрения
Перспективные исследования направлены на интеграцию CAViT с другими методами повышения эффективности, такими как квантизация и прунинг, с целью дальнейшего снижения вычислительных затрат. Квантизация, путем уменьшения разрядности весов и активаций, и прунинг, удаляющий наименее значимые соединения в нейронной сети, могут значительно уменьшить размер модели и ускорить вычисления. Комбинирование этих методов с адаптивной архитектурой CAViT позволит создать системы компьютерного зрения, способные работать в условиях ограниченных ресурсов, например, на мобильных устройствах или встраиваемых системах, сохраняя при этом высокую точность и скорость обработки изображений. Такой подход открывает возможности для разработки более энергоэффективных и доступных решений в области искусственного интеллекта.
Дальнейшее развитие механизма внимания в CAViT предполагает интеграцию пространственного внимания, что может существенно повысить надежность и точность понимания изображений. В текущей реализации акцент делается на взвешивание каналов признаков, однако добавление способности модели фокусироваться на наиболее релевантных областях изображения позволит более эффективно выделять ключевые объекты и игнорировать несущественные детали. Такой подход, сочетающий анализ признаков по каналам и пространственное внимание, имитирует принципы работы человеческого зрения, позволяя системе лучше адаптироваться к различным условиям освещения, изменениям масштаба и частичной окклюзии объектов. Предполагается, что подобное усовершенствование позволит создавать более устойчивые и точные алгоритмы компьютерного зрения, способные решать широкий спектр задач, от распознавания образов до автономной навигации.
Перспективы адаптации принципов CAViT к другим модальностям данных, таким как видео и облака точек, открывают путь к созданию действительно адаптивных и универсальных систем искусственного интеллекта. В то время как текущая реализация фокусируется на обработке изображений, лежащая в основе концепция — динамическая настройка вычислительных ресурсов в зависимости от сложности входных данных — имеет потенциал для значительного повышения эффективности в задачах, связанных с обработкой временных рядов видеоданных или трёхмерных структур, представленных в виде облаков точек. Подобный подход позволит системам более эффективно использовать доступные ресурсы, избегая избыточных вычислений в простых сценах и фокусируясь на сложных областях, требующих повышенного внимания. Реализация CAViT для видео и облаков точек потребует разработки новых механизмов внимания, учитывающих специфику этих данных, но потенциальные выгоды в виде снижения вычислительной нагрузки и повышения точности делают данное направление крайне перспективным для дальнейших исследований.
Исследование представляет собой очередную попытку обуздать хаос визуальных данных, заменяя статичные блоки машинного обучения динамическим механизмом внимания. Авторы предлагают CAViT — архитектуру, в которой каналы внимания играют роль алхимических сосудов, смешивающих и перестраивающих признаки. Это не просто улучшение производительности, а способ уговорить данные раскрыть свои тайны. Как говорил Дэвид Марр: «Любая модель — это заклинание, которое работает до первого продакшена». Иными словами, даже самая изящная архитектура, вроде CAViT, остаётся лишь временным перемирием с непредсказуемостью реального мира, требующим постоянной адаптации и пересмотра.
Куда же всё это ведёт?
Предложенная модификация, CAViT, заменяет статичные многослойные персептроны в Vision Transformer механизмами канального внимания. Это, безусловно, элегантное решение, но не стоит обманываться кажущейся простотой. Данные — это лишь отголоски прошедшего, и любое «улучшение» — лишь попытка примирить их с нашими ожиданиями. Вопрос в том, насколько устойчиво это примирение к шуму реальности. Высокая корреляция между улучшениями и тщательно подобранными датасетами заставляет задуматься: не является ли прогресс лишь иллюзией, созданной искусственным отбором?
Очевидным направлением дальнейших исследований представляется отказ от жёсткой структуры Transformer-блоков. Возможно, истинный путь лежит через динамическое изменение размерности признаков, адаптацию к специфике каждого канала, или даже отказ от самовнимания в пользу более хаотичных, но правдивых механизмов. Ведь шум — это не ошибка, а просто правда, которой не хватает бюджета на чёткое проявление.
В конечном итоге, CAViT — это лишь ещё один шаг в бесконечном танце с данными. Истинный прогресс потребует не только улучшения алгоритмов, но и переосмысления самой природы зрения, понимания того, что мы видим не мир, а лишь его бледное отражение, искажённое нашими собственными ожиданиями и ограничениями.
Оригинал статьи: https://arxiv.org/pdf/2602.05598.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обзор Motorola Razr 50 Ultra
- Huawei nova 15 Max ОБЗОР
- Acer Aspire 5 Spin 14 ОБЗОР
- ВИ.РУ акции прогноз. Цена VSEH
- Honor 600 ОБЗОР: отличная камера, объёмный накопитель, плавный интерфейс
- Как фотографировать огонь.
- Nikon D7200
- Realme 15T ОБЗОР: плавный интерфейс, лёгкий, скоростная зарядка
- Российский рынок: от оттока наличных к смешанной динамике и ожиданиям ЦБ (07.05.2026 20:32)
- Что купить фотографу. Рекомендации
2026-02-07 22:06