Автор: Денис Аветисян
Новая методика позволяет нейросетям с архитектурой Vision Transformer эффективно осваивать новые знания, не теряя при этом навыки, полученные ранее.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"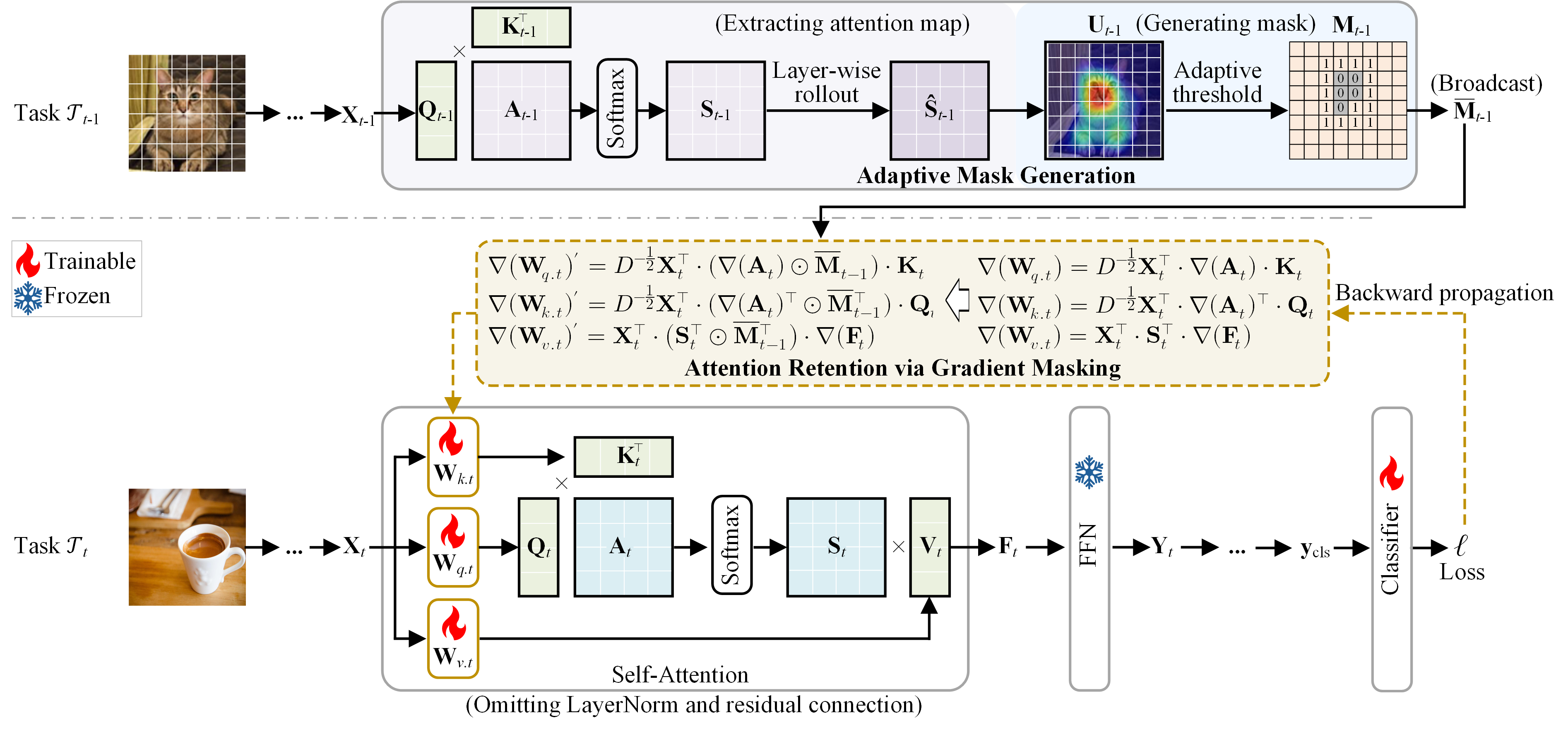
Предложена система маскирования градиентов, сохраняющая важные паттерны внимания в Vision Transformers для решения задачи непрерывного обучения.
Непрерывное обучение, позволяющее моделям адаптироваться к потоку данных, часто сталкивается с проблемой катастрофического забывания ранее полученных знаний. В работе ‘Attention Retention for Continual Learning with Vision Transformers’ выявлено, что значительным источником этой проблемы является смещение внимания в архитектурах Vision Transformer при обучении новым задачам. Предлагаемый авторами механизм удержания внимания позволяет смягчить забывание, ограничивая изменения в картах внимания посредством маскирования градиентов в процессе обратного распространения ошибки. Способны ли подобные методы, вдохновленные принципами селективного внимания в человеческом мозге, обеспечить устойчивое и эффективное непрерывное обучение в сложных реальных сценариях?
Искусственный интеллект и проблема забывания: вечная борьба с энтропией
Искусственные нейронные сети, демонстрирующие впечатляющие успехи в различных областях, зачастую сталкиваются с проблемой, известной как “катастрофическое забывание”. Суть явления заключается в резкой потере ранее усвоенной информации при обучении на новых данных. Представьте, что сеть, отлично распознающая кошек, внезапно “забывает” об этом, начав изучать собак; прежние знания стираются, что препятствует эффективной работе в динамично меняющейся среде. Это ограничение особенно критично для приложений, требующих непрерывного обучения и адаптации, поскольку сеть не может эффективно накапливать знания, а вынуждена постоянно переобучаться, теряя предыдущий опыт.
Ограничение, заключающееся в склонности искусственных нейронных сетей к «катастрофическому забыванию», существенно препятствует их эффективному применению в динамичных реальных условиях. В ситуациях, требующих непрерывной адаптации и накопления знаний — например, в робототехнике, автономном вождении или персонализированной медицине — сети часто оказываются неспособны сохранять предыдущий опыт при обучении новым задачам. Это приводит к необходимости постоянной переподготовки или использования сложных вспомогательных механизмов, что значительно усложняет и замедляет процесс обучения. В конечном итоге, способность к непрерывному обучению становится критическим фактором для создания действительно интеллектуальных систем, способных функционировать в постоянно меняющемся окружении и эффективно использовать накопленный опыт.
Традиционные подходы к непрерывному обучению сталкиваются с фундаментальной дилеммой: необходимо найти баланс между пластичностью и стабильностью. Пластичность, или способность к усвоению новой информации, часто достигается за счет перестройки существующих связей в нейронной сети, что, в свою очередь, может привести к искажению или полной потере ранее приобретенных знаний. В результате, попытки адаптироваться к изменяющимся условиям нередко сопровождаются «забыванием» старых навыков и умений. Ученые активно исследуют различные стратегии — от регуляризации весов до использования архитектур, имитирующих процессы консолидации памяти в биологических системах — чтобы решить эту задачу и создать искусственные нейронные сети, способные к долгосрочному и эффективному обучению без потери накопленного опыта. Именно поиск оптимального сочетания этих двух взаимоисключающих свойств является ключевым препятствием на пути к созданию действительно интеллектуальных систем.
Вижн-трансформеры и дрейф внимания: новая головная боль
Вижн-трансформер (ViT) зарекомендовал себя как передовая модель в области распознавания изображений, использующая архитектуру Transformer, изначально разработанную для обработки последовательностей в задачах обработки естественного языка. В отличие от традиционных сверточных нейронных сетей (CNN), ViT разбивает изображение на последовательность патчей, которые затем обрабатываются как «токены» в Transformer. Это позволяет модели улавливать глобальные зависимости между различными частями изображения, что приводит к улучшению результатов в задачах классификации и обнаружения объектов. Успех ViT демонстрирует эффективность подхода, основанного на механизме внимания, для задач компьютерного зрения и открывает новые возможности для разработки более мощных и гибких моделей.
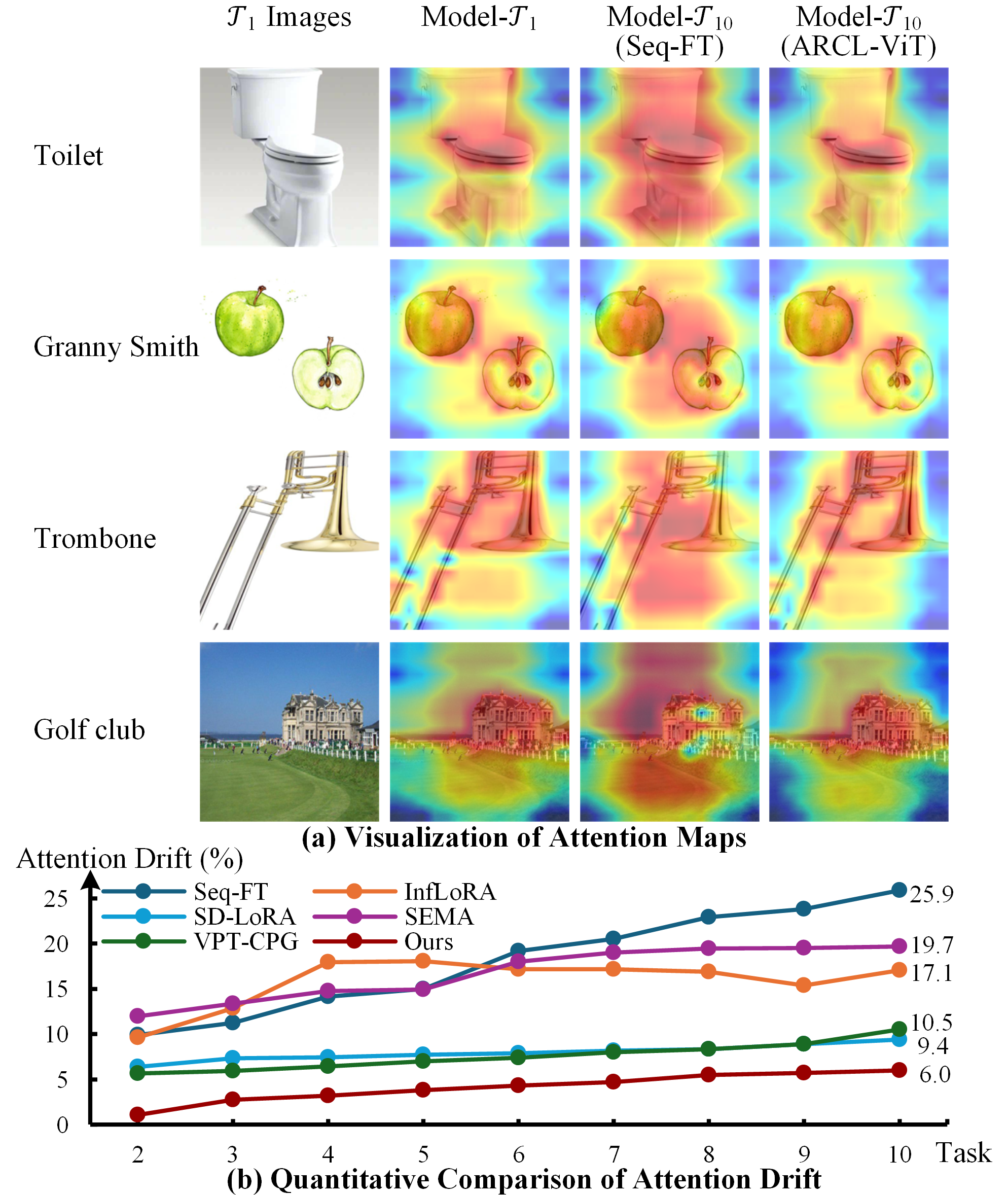
При обучении Vision Transformer (ViT) в сценариях непрерывного обучения наблюдается явление, известное как “смещение внимания” (attention drift). Данное явление характеризуется значительным изменением областей изображения, на которые модель концентрирует свое внимание при обработке последовательных задач. В результате этого смещения, модель склонна «забывать» информацию, полученную на предыдущих этапах обучения, поскольку ее фокус смещается на новые данные, что приводит к ухудшению производительности при решении старых задач. Это особенно заметно при последовательной тонкой настройке (Seq-FT), где смещение внимания может достигать значительных значений, негативно влияя на способность модели к обобщению и сохранению знаний.
В задачах непрерывного обучения (continual learning) Vision Transformers (ViT) демонстрируют склонность к “смещению внимания” (attention drift), что существенно ухудшает способность модели сохранять знания при освоении новых задач. Экспериментальные данные показывают, что при последовательной тонкой настройке (Sequential Fine-Tuning, Seq-FT) наблюдается значительное смещение внимания в размере 25.9%. Данный показатель указывает на серьезную проблему, поскольку существенное изменение фокуса внимания приводит к катастрофической потере ранее приобретенных знаний и снижению общей производительности модели. Минимизация данного смещения является критически важной для обеспечения эффективного непрерывного обучения ViT без значительной деградации производительности.
ARCL-ViT: удерживая внимание, чтобы не забыть прошлое
Механизм удержания внимания (attention-retention) в ARCL-ViT разработан для смягчения эффекта “дрейфа внимания” (attention drift) в Vision Transformers в процессе непрерывного обучения. Проблема дрейфа внимания возникает, когда модель постепенно смещает фокус с важных признаков, усвоенных на предыдущих задачах, на менее значимые при обучении новым данным. Данный механизм направлен на стабилизацию карт внимания (attention maps) и предотвращение их резких изменений, что позволяет модели сохранять знания, полученные ранее, и эффективно обобщать информацию при решении последовательных задач. Это достигается путем регулирования градиентов, влияющих на паттерны внимания, и фокусировки на поддержании существующих важных областей внимания.
Механизм градиентной маскировки в ARCL-ViT предназначен для подавления градиентов, вызывающих смещение паттернов внимания в Vision Transformer. Это достигается путем идентификации и блокировки градиентов, которые значительно изменяют существующие карты внимания, тем самым закрепляя фокус модели на наиболее релевантных признаках. По сути, градиентная маскировка предотвращает катастрофическое забывание, стабилизируя области внимания, критически важные для ранее изученных задач, и позволяя модели эффективно учиться новым задачам без потери производительности на старых.
Механизм ARCL-ViT использует комбинацию методов для точной идентификации и сохранения значимых областей внимания. Техника ‘layer-wise rollout’ позволяет проследить распространение активаций через слои сети, выявляя наиболее важные признаки, влияющие на выходные данные. В сочетании с ‘adaptive thresholding’ — адаптивным порогом — система динамически определяет границы значимых регионов внимания, отсекая менее важные активации. Это позволяет ARCL-ViT фокусироваться на ключевых особенностях входного изображения и сохранять их в процессе непрерывного обучения, предотвращая смещение внимания и обеспечивая стабильную производительность.
В ходе экспериментов с использованием набора данных ImageNet-R, состоящего из 10 подмножеств для оценки способности к непрерывному обучению, модель ARCL-ViT продемонстрировала способность сохранять высокую точность при изучении новых задач, достигая до 95.1%. Этот показатель свидетельствует об эффективности предложенного механизма удержания внимания в предотвращении катастрофического забывания, позволяя Vision Transformer успешно накапливать знания и адаптироваться к новым данным без существенной потери производительности на ранее изученных задачах.
Оценка ARCL-ViT на стандартных наборах данных: подтверждение эффективности
Для оценки производительности ARCL-ViT использовались стандартные бенчмарк-наборы данных, такие как ‘ImageNet-R’ и ‘DomainNet’. ‘ImageNet-R’ представляет собой модифицированную версию ImageNet, предназначенную для оценки способности алгоритмов к непрерывному обучению при последовательном добавлении новых классов. ‘DomainNet’ включает в себя изображения из шести различных доменов (Clipart10k, Painting, Real, Sketch, Quickdraw, Infographic), что позволяет оценить устойчивость модели к смене домена и ее способность к обобщению знаний в новых условиях. Использование этих наборов данных позволяет проводить объективное сравнение ARCL-ViT с другими алгоритмами непрерывного обучения и демонстрировать ее эффективность в различных сценариях.
Результаты тестирования ARCL-ViT на стандартных наборах данных демонстрируют значительное превосходство над существующими методами в отношении пластичности и стабильности. Алгоритм эффективно сохраняет ранее полученные знания при адаптации к новым задачам, обеспечивая средний прирост точности в 1.8% по всем используемым бенчмаркам. Данный показатель свидетельствует о способности ARCL-ViT эффективно балансировать между освоением новых данных и предотвращением «забывания» старых, что является ключевым требованием к системам непрерывного обучения.
На 10-разбивочном наборе данных DomainNet, ARCL-ViT демонстрирует точность в 92.4%, что на 3.3% превосходит предыдущий лучший результат. Этот набор данных, состоящий из изображений, полученных из различных доменов (например, реалистичные фотографии, картины, эскизы), предназначен для оценки способности модели к обобщению и адаптации к новым, ранее не встречавшимся условиям. Превосходство ARCL-ViT на DomainNet подтверждает эффективность предложенного подхода в решении задач непрерывного обучения и переноса знаний между различными визуальными доменами.
В ходе тестирования было установлено, что ARCL-ViT значительно снижает отклонение внимания (attention drift) до 6.0%, что существенно ниже, чем у метода Seq-FT и других конкурирующих моделей, демонстрирующих показатель в 25.9%. Данный параметр измеряет степень изменения паттернов внимания модели в процессе обучения новым задачам; более низкое значение указывает на лучшую способность сохранять релевантную информацию и избегать потери знаний при адаптации к новым данным. Минимизация отклонения внимания является ключевым фактором для обеспечения стабильности и эффективности модели в задачах непрерывного обучения.
Полученные результаты подтверждают эффективность механизма удержания внимания (attention-retention) в задачах непрерывного обучения для Vision Transformers. Эксперименты на стандартных бенчмарках, таких как ImageNet-R и DomainNet, демонстрируют, что применение данного механизма позволяет значительно повысить стабильность и пластичность модели, минимизируя потерю ранее приобретенных знаний при адаптации к новым задачам. В частности, зафиксировано снижение «дрейфа внимания» до 6.0% по сравнению с 25.9% у конкурирующих методов, что свидетельствует о более эффективном сохранении релевантных признаков и предотвращении переобучения на новых данных.
Перспективы развития: самообучение и за его пределами
Интеграция архитектуры ARCL-ViT с методами самообучения, такими как ‘DINO’ и ‘iBOT’, представляет собой перспективный путь для значительного повышения ее возможностей. Эти техники позволяют модели извлекать полезные признаки из немаркированных данных, что особенно ценно в условиях ограниченности размеченных выборок. Вместо прямой зависимости от ручной разметки, модель обучается понимать структуру данных самостоятельно, выявляя внутренние закономерности и зависимости. Такой подход не только расширяет спектр решаемых задач, но и способствует созданию более устойчивых и обобщающих представлений, что критически важно для адаптации к новым, ранее не встречавшимся ситуациям и для снижения риска “катастрофического забывания” при переходе между задачами.
Самообучение представляет собой перспективный подход к созданию более надежных и адаптивных систем искусственного интеллекта. В отличие от традиционных методов, требующих больших объемов размеченных данных, самообучение позволяет модели извлекать полезные представления из неразмеченных данных, что значительно расширяет возможности обучения. Этот процесс способствует формированию более глубокого понимания данных и, как следствие, улучшает перенос знаний между различными задачами. Особенно важным является потенциал самообучения в смягчении проблемы «катастрофического забывания», когда освоение новой информации приводит к потере ранее полученных знаний. Использование самообучения позволяет модели сохранять и интегрировать новую информацию, не забывая при этом старые навыки, что является ключевым шагом на пути к созданию систем, способных к непрерывному обучению и накоплению знаний.
Исследования в области внимания в нейронных сетях активно направлены на разработку альтернативных стратегий регуляризации, позволяющих повысить устойчивость и обобщающую способность моделей. Ученые стремятся к созданию более эффективных методов выявления наиболее значимых признаков, отсеивая несущественный шум и фокусируясь на ключевой информации. В частности, изучаются новые подходы к штрафованию внимания, способствующие формированию более разреженных и интерпретируемых карт внимания. Разработка алгоритмов, способных динамически адаптировать степень регуляризации в зависимости от сложности входных данных, представляется перспективным направлением. Эти усилия направлены на создание моделей, способных не только точно классифицировать данные, но и объяснять принятые решения, что особенно важно для приложений, требующих высокой степени надежности и прозрачности.
В конечном итоге, представленные усовершенствования в области обучения моделей машинного зрения открывают перспективы создания принципиально новых, по-настоящему адаптивных и интеллектуальных систем. Эти системы смогут не просто выполнять поставленные задачи, но и непрерывно обучаться на новых данных, аккумулировать знания и эффективно применять их в различных контекстах. Способность к постоянному обучению без “катастрофического забывания” позволит создавать искусственный интеллект, который со временем становится всё более компетентным и универсальным, приближаясь к уровню когнитивных способностей человека и находя применение в самых разнообразных сферах — от автономной робототехники до сложных систем анализа данных и принятия решений.
Исследование, посвящённое удержанию внимания в Vision Transformers для непрерывного обучения, закономерно сталкивается с проблемой катастрофического забывания. Авторы предлагают маскирование градиентов, связанных с ранее изученными паттернами внимания, что, конечно, звучит элегантно. Но, как показывает практика, элегантность часто оборачивается новым уровнем сложности, который рано или поздно придётся расхлёбывать. Как метко заметил Ян Лекун: «Простота — высшая степень изощренности». Хотя, судя по всему, в мире машинного обучения эту простую истину предпочитают игнорировать, добавляя всё новые и новые слои абстракции. В итоге, сложная система, которая когда-то была простым bash-скриптом, превращается в чёрный ящик, где даже авторы не всегда понимают, что происходит.
Что дальше?
Предложенный подход к удержанию внимания в трансформерах для непрерывного обучения, безусловно, демонстрирует эффективность в смягчении катастрофического забывания. Однако, как обычно, решение одной проблемы неизбежно порождает другие. Маскирование градиентов, хоть и элегантно, представляет собой компромисс: защита старых знаний — это, по сути, ограничение способности к адаптации к принципиально новым данным. Всегда найдётся задача, где такая «заморозка» внимания станет узким местом.
Очевидно, что внимание — лишь один из аспектов проблемы непрерывного обучения. Вполне вероятно, что истинный прогресс потребует не просто сохранения старых паттернов, а разработки механизмов для их перекомбинации и переосмысления. Архитектура, в конце концов, — это не схема, а компромисс, переживший деплой. Оптимизация внимания — это хорошо, но рано или поздно всё, что оптимизировано, оптимизируют обратно.
Будущие исследования, вероятно, сосредоточатся на поиске более тонких методов регулирования «пластичности» нейронной сети, возможно, используя мета-обучение для автоматической адаптации стратегий удержания внимания к конкретным задачам. Не исключено, что потребуется взглянуть за пределы внимания и исследовать другие аспекты представления знаний, ведь мы не рефакторим код — мы реанимируем надежду.
Оригинал статьи: https://arxiv.org/pdf/2602.05454.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обзор Motorola Razr 50 Ultra
- Huawei nova 15 Max ОБЗОР
- Что купить фотографу. Рекомендации
- ВИ.РУ акции прогноз. Цена VSEH
- Honor 600 ОБЗОР: отличная камера, объёмный накопитель, плавный интерфейс
- Как фотографировать огонь.
- Обзор фотокамеры Nikon D7000
- Nikon D7200
- Ремонтная мастерская обнаружила раннюю ревизию GeForce RTX 4090 Founders Edition с неисправным чипом, отсутствующим на более новых платах.
- Realme 15T ОБЗОР: плавный интерфейс, лёгкий, скоростная зарядка
2026-02-08 09:56