Автор: Денис Аветисян
Новая система SparseVideoNav позволяет роботам уверенно перемещаться в незнакомой среде, предсказывая развитие событий на основе коротких видеофрагментов.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Исследование представляет метод генерации разреженных видеоданных для улучшения навигации в задачах взаимодействия с реальным миром на основе языка и зрения.
Обычно навигация, основанная на визуальных и языковых командах, требует подробных инструкций, что противоречит принципам автономности в реальном мире. В работе ‘Sparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation’ предложен новый подход к задаче навигации «за пределами видимости» (Beyond-the-View Navigation), использующий генерацию разреженных видео для планирования траектории. Показано, что предложенная система SparseVideoNav, благодаря генерации разреженного видеопрогноза на горизонте в 20 секунд, обеспечивает 27-кратное ускорение по сравнению с существующими решениями и в 2.5 раза повышает успешность навигации в ночных условиях. Возможно ли дальнейшее расширение возможностей автономной навигации в сложных реальных сценариях за счет более эффективного использования видеопрогнозирования?
Пределы Пошагового Руководства
Современные системы навигации, основанные на анализе изображений и языка, зачастую функционируют по принципу детального следования инструкциям, напоминая предоставление пошаговых указаний. Такой подход, хотя и позволяет успешно выполнять задачи в контролируемых условиях, сталкивается с ограничениями при решении более сложных и протяжённых задач. Системы, ориентированные на точное выполнение каждой команды, испытывают трудности с пониманием общей цели и адаптацией к непредвиденным обстоятельствам, что снижает их надёжность в реальных сценариях. Вместо формирования целостного представления о маршруте, они концентрируются на немедленном выполнении указаний, что делает их уязвимыми к ошибкам и неспособными к самостоятельному планированию.
Несмотря на свою функциональность, существующие системы навигации, основанные на обработке визуальной информации и языка, испытывают трудности при выполнении задач, требующих планирования на длительный горизонт. В реальных условиях, где окружающая среда динамична и непредсказуема, точное следование пошаговым инструкциям часто оказывается недостаточным. Небольшие отклонения от заданного маршрута или неожиданные препятствия приводят к сбоям, поскольку системы не обладают достаточной устойчивостью и способностью адаптироваться к изменяющимся обстоятельствам. Такая хрупкость существенно ограничивает их применимость в реальном мире, где надежность и гибкость являются ключевыми требованиями к навигационным системам.
Несмотря на впечатляющие возможности, большие языковые модели (LLM) демонстрируют ограничения, связанные с кратковременной зависимостью при решении задач, требующих долгосрочного планирования, таких как навигация. В процессе обработки последовательностей информации, LLM склонны отдавать предпочтение ближайшим элементам, что затрудняет формирование целостной стратегии для достижения отдаленной цели. Это проявляется в сложностях с удержанием в памяти ключевых ориентиров и построением последовательности действий, необходимых для успешного выполнения сложного маршрута. В результате, при навигации, модели могут испытывать трудности с выбором оптимального пути, совершать ошибки в планировании и терять ориентацию, особенно в незнакомой среде или при наличии большого количества возможных вариантов.
За Пределы Непосредственных Шагов: Принятие Прогностического Видения
Перспективной альтернативой для улучшения навигации является наделение агентов способностью предсказывать будущие состояния окружающей среды. Такой подход позволяет повысить эффективность и надежность ориентирования, особенно в задачах навигации за пределами прямой видимости (beyond-the-view navigation). Способность предвидеть последующие сцены позволяет агенту планировать маршрут и избегать препятствий более эффективно, чем при непосредственном реагировании на текущую ситуацию. Это достигается за счет моделирования возможных будущих состояний и выбора наиболее оптимального пути, учитывающего предсказанные изменения в окружении.
Модели генерации видео предоставляют возможность для реализации предсказания будущих состояний, путем предварительного обучения на долгосрочных горизонтах будущего, сопоставленных с языковыми инструкциями. В процессе предварительного обучения модели анализируют большие объемы данных, включающих последовательности действий и соответствующие им языковые описания, что позволяет им научиться прогнозировать наиболее вероятные будущие состояния среды на основе полученных инструкций. Это обучение позволяет агенту не просто реагировать на текущую ситуацию, но и планировать свои действия, основываясь на прогнозируемом развитии событий, что существенно повышает эффективность навигации и устойчивость к неопределенности. Использование языковых инструкций в процессе обучения обеспечивает согласованность между целями агента и его предсказываемыми действиями.
Традиционные методы генерации непрерывного видео, применяемые для прогнозирования будущих состояний в задачах навигации по визуальным инструкциям (VLN), характеризуются высокой вычислительной сложностью и требуют значительных ресурсов. В качестве более эффективной альтернативы, появляется стратегия разреженной (sparse) генерации видео, которая фокусируется на создании лишь ключевых кадров или состояний, необходимых для понимания и прогнозирования траектории. Такой подход позволяет существенно снизить вычислительные затраты и время обработки, сохраняя при этом достаточный уровень точности и эффективности в задачах VLN, где требуется предвидеть будущие сцены для оптимальной навигации.

SparseVideoNav: Система для Прогностической Навигации
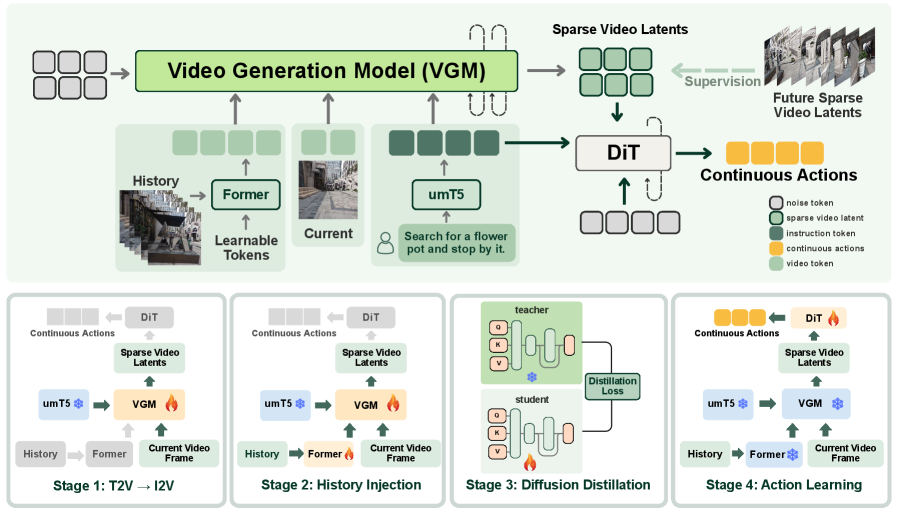
Система SparseVideoNav использует генерацию разреженных видеопоследовательностей для предсказания будущих визуальных наблюдений, что позволяет осуществлять навигацию без необходимости в плотных промежуточных ориентирах. Вместо генерации каждого кадра видео, система предсказывает лишь ключевые кадры, обеспечивая значительное снижение вычислительных затрат и задержек. Этот подход позволяет агенту ориентироваться в среде, опираясь на предсказанные состояния, а не на непрерывный поток визуальной информации, что повышает эффективность и устойчивость навигации в сложных условиях.
Оптимизация производительности системы достигается за счет четырехэтапного процесса обучения. На первом этапе происходит извлечение признаков из видеоданных. Далее, для эффективной компрессии этих признаков и снижения вычислительной нагрузки, используются архитектуры Q-Former и Video-Former, позволяющие выделить наиболее значимую информацию. Третий этап посвящен обучению модели предсказания действий, а заключительный — тонкой настройке и валидации всей системы. Использование Q-Former позволяет сжимать последовательности визуальных признаков, а Video-Former оптимизирует представление видеоданных, что критически важно для работы в реальном времени и снижения требований к вычислительным ресурсам.
Для предсказания действий и генерации непрерывных траекторий используется архитектура Diffusion Transformer. В основе лежит принцип обратной динамики (inverse dynamics), позволяющий, исходя из желаемого будущего состояния, определить необходимые для достижения этого состояния действия. Diffusion Transformer преобразует задачу предсказания действий в задачу генерации, используя диффузионные модели для создания вероятностных распределений над возможными траекториями. Это позволяет системе генерировать не только наиболее вероятные, но и разнообразные, реалистичные траектории движения, учитывая неопределенность окружающей среды и динамику агента. Применение диффузионных моделей обеспечивает плавность и естественность генерируемых действий.
Система обучается на крупномасштабном наборе данных реальной навигации, собранном в различных средах. Для обеспечения точного понимания сцены используется модель Depth Anything 3, позволяющая получать карты глубины из визуальных данных. Это позволяет системе эффективно оценивать геометрию окружающего пространства и планировать траектории движения, избегая препятствий и ориентируясь в сложных условиях. Набор данных включает широкий спектр сценариев навигации, обеспечивая обобщающую способность системы и ее адаптацию к новым, ранее не встречавшимся локациям.

Валидация и Перспективы Развития
Система SparseVideoNav демонстрирует передовые результаты в задачах навигации за пределами видимого диапазона, превосходя современные языковые модели (LLM) в 2,5 раза по показателю успешности. Данный прирост эффективности был подтвержден с использованием метрики FVD, позволяющей оценить качество сгенерированных траекторий. Достигнутое улучшение указывает на значительный прогресс в создании более надежных и точных систем навигации, способных эффективно ориентироваться в незнакомых окружениях и успешно выполнять поставленные задачи даже при ограниченной видимости. Результаты подтверждают, что предложенный подход является перспективным направлением для развития технологий автономной навигации.
Система SparseVideoNav демонстрирует значительное увеличение скорости вычисления траектории движения — в 27 раз по сравнению с существующими подходами. Это достигается благодаря оптимизированной архитектуре, позволяющей прогнозировать путь на 20 секунд вперёд с высокой точностью. Такое ускорение открывает новые возможности для применения в задачах, требующих оперативного реагирования и планирования, например, в робототехнике и системах дополненной реальности, где важна быстрая и эффективная навигация в динамично меняющейся среде. Возможность прогнозирования на 20 секунд позволяет системе более уверенно ориентироваться и избегать препятствий, повышая надежность и безопасность перемещения.
Использование архитектуры Wan2.1 в качестве основы системы позволило продемонстрировать высокую степень адаптивности к существующим моделям генерации видео. В ходе экспериментов было зафиксировано значительное улучшение показателей успешности навигации — на 15.0% выше, чем у StreamVLN — как в задачах Indoor Fine-Grained Navigation (IFN), так и в Beyond-View Navigation (BVN). Данный результат подчеркивает потенциал системы для интеграции с различными платформами видео-воспроизведения и создания более эффективных и гибких решений в области визуальной навигации, не требующих существенной переработки существующей инфраструктуры.
Разработанная система открывает перспективы для создания более надёжных и эффективных систем навигации, находящих применение в широком спектре областей. От робототехники, где точное и быстрое ориентирование необходимо для автономной работы, до технологий дополненной реальности, позволяющих пользователям взаимодействовать с виртуальными объектами в реальном мире, — возможности практически безграничны. Ускорение траекторий и повышение точности, продемонстрированные в ходе исследований, позволяют представить, что в будущем роботы смогут перемещаться в сложных условиях с большей уверенностью, а приложения дополненной реальности обеспечат более реалистичные и интуитивно понятные пользовательские интерфейсы. Данная работа закладывает основу для нового поколения интеллектуальных систем, способных эффективно ориентироваться и взаимодействовать с окружающим миром.
Дальнейшие исследования направлены на расширение возможностей системы в отношении обобщения опыта на незнакомые среды и преодоления сложных навигационных задач. Ученые планируют усовершенствовать алгоритмы, чтобы обеспечить устойчивую работу в условиях, существенно отличающихся от тех, на которых система обучалась. Особое внимание будет уделено разработке методов, позволяющих эффективно адаптироваться к новым визуальным ландшафтам, непредсказуемым препятствиям и динамически меняющимся условиям. Ожидается, что такие улучшения позволят создать более надежные и универсальные навигационные системы, способные функционировать в широком спектре реальных сценариев, от автономной робототехники до приложений дополненной реальности, требующих мгновенной адаптации к новым окружениям.

Представленная работа демонстрирует элегантность подхода к задаче навигации, где ключевым элементом является генерация разреженных видеофрагментов. Этот метод позволяет системе предвидеть траекторию движения и адаптироваться к невидимым участкам окружения, что принципиально отличает его от существующих решений, ограниченных краткосрочным планированием. Как заметил Эндрю Ын: «Мы должны стремиться к тому, чтобы алгоритмы были доказуемы, а не просто работали на тестах». Это особенно актуально здесь, поскольку предсказание поведения в реальном мире требует высокой степени надёжности и прозрачности, а не просто статистической правдоподобности. По сути, система демонстрирует математическую чистоту в решении сложной задачи.
Куда Ведет Этот Путь?
Представленная работа, безусловно, демонстрирует элегантность подхода к проблеме навигации, используя разреженную генерацию видео. Однако, не стоит обманываться кажущейся простотой. Истинная проверка алгоритма — это не его успех на ограниченном наборе тестовых сцен, а его способность к обобщению, к адаптации к непредсказуемости реального мира. Очевидное ограничение — зависимость от качества обучающих данных. Даже самое изящное математическое построение бессильно перед лицом неполноты или предвзятости исходных данных.
Следующим шагом видится не просто увеличение объема данных, а разработка алгоритмов, способных к самообучению, к построению внутренней модели мира, не требующей постоянного внешнего подкрепления. Важно сместить фокус с генерации «правдоподобных» видео на генерацию доказуемо корректных траекторий. Необходимо строгое математическое обоснование каждого шага, исключающее возможность появления неопределенностей или противоречий.
В конечном счете, успех этого направления зависит не от скорости генерации видео, а от точности прогнозирования. Истинная красота алгоритма проявляется не в его способности имитировать реальность, а в его способности предсказывать будущее. Задача не в том, чтобы «научить» робота видеть, а в том, чтобы научить его понимать. И это, как известно, гораздо сложнее.
Оригинал статьи: https://arxiv.org/pdf/2602.05827.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обзор Motorola Razr 50 Ultra
- Huawei nova 15 Max ОБЗОР
- Что купить фотографу. Рекомендации
- ВИ.РУ акции прогноз. Цена VSEH
- Российский рынок: дефляция, рубль и геополитика – обзор ключевых событий недели (06.05.2026 19:32)
- Ремонтная мастерская обнаружила раннюю ревизию GeForce RTX 4090 Founders Edition с неисправным чипом, отсутствующим на более новых платах.
- Обзор фотокамеры Nikon D7000
- Nikon D7200
- Honor 600 ОБЗОР: отличная камера, объёмный накопитель, плавный интерфейс
- Как фотографировать огонь.
2026-02-08 18:22