Автор: Денис Аветисян
Новый подход позволяет генерировать правдоподобные 3D-анимации взаимодействия человека и объектов, опираясь на текстовые описания.
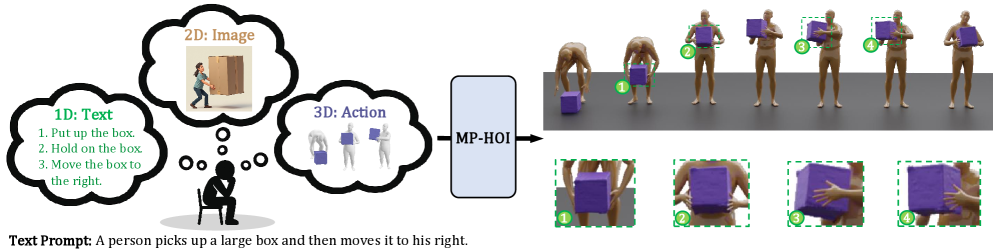
Представлен MP-HOI — фреймворк, использующий мультимодальные знания и каскадные диффузионные модели для генерации реалистичных движений взаимодействия человека и объектов на основе текстовых запросов.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Создание реалистичных и когерентных взаимодействий между человеком и объектом на основе текстового описания представляет собой сложную задачу из-за разрыва между модальностями. В данной работе, посвященной теме ‘Multimodal Priors-Augmented Text-Driven 3D Human-Object Interaction Generation’, предложен новый подход MP-HOI, использующий мультимодальные приоритеты и каскадную диффузию для генерации высококачественных 3D-анимаций взаимодействия человека с объектами. Предложенный фреймворк демонстрирует превосходство над существующими методами в создании детализированных и правдоподобных движений. Какие перспективы открывает дальнейшая интеграция мультимодального обучения и генеративных моделей для создания еще более сложных и реалистичных виртуальных сцен?
Реалистичные взаимодействия: Преодоление сложностей
Создание реалистичных трёхмерных взаимодействий человека с объектами (Human-Object Interaction, HOI) остается сложной задачей для развития виртуальных сред и робототехники. Несмотря на значительный прогресс в области компьютерного зрения и моделирования, воспроизведение естественных и правдоподобных движений, учитывающих физические свойства объектов и намерения человека, требует преодоления серьезных трудностей. Проблема заключается не только в точном отслеживании движений, но и в предсказании, как человек будет взаимодействовать с объектом в различных ситуациях, учитывая его вес, форму, текстуру и предполагаемое назначение. Разработка систем, способных генерировать HOI, неотъемлемо связана с пониманием как кинематики человеческого тела, так и динамики окружающего мира, что делает эту область исследования междисциплинарной и требующей комплексного подхода.
Существующие методы генерации взаимодействия человека с объектами зачастую сталкиваются с трудностями в обеспечении физической правдоподобности движений и семантической согласованности между действиями и их описаниями. Модели нередко демонстрируют неестественные или невозможные траектории, игнорируя законы физики и свойства объектов. Более того, часто наблюдается несоответствие между тем, что изображено визуально, и тем, как это действие описано текстово — например, робот может «держать» предмет, не оказывая на него соответствующего усилия, или описание действия не соответствует фактическому положению объектов. Данные ограничения существенно снижают реалистичность виртуальных сред и затрудняют применение робототехнических систем в реальном мире, где точность и согласованность действий критически важны.
Для создания убедительных взаимодействий в виртуальных средах и робототехнике требуется глубокое понимание как человеческой моторики, так и динамики объектов. Исследования показывают, что реалистичное моделирование требует учитывать не только кинематику движений, но и физические свойства объектов — их массу, форму, трение и упругость. Например, человек инстинктивно адаптирует силу и траекторию движения при взаимодействии с различными предметами — поднятие лёгкой чашки отличается от перемещения тяжёлого ящика. Учёт этих нюансов, а также таких факторов как инерция и гравитация, позволяет создавать правдоподобные и естественные взаимодействия, что критически важно для повышения реалистичности симуляций и эффективности робототехнических систем. Игнорирование этих аспектов приводит к неестественным движениям и нереалистичному поведению, снижая степень погружения и затрудняя выполнение задач.
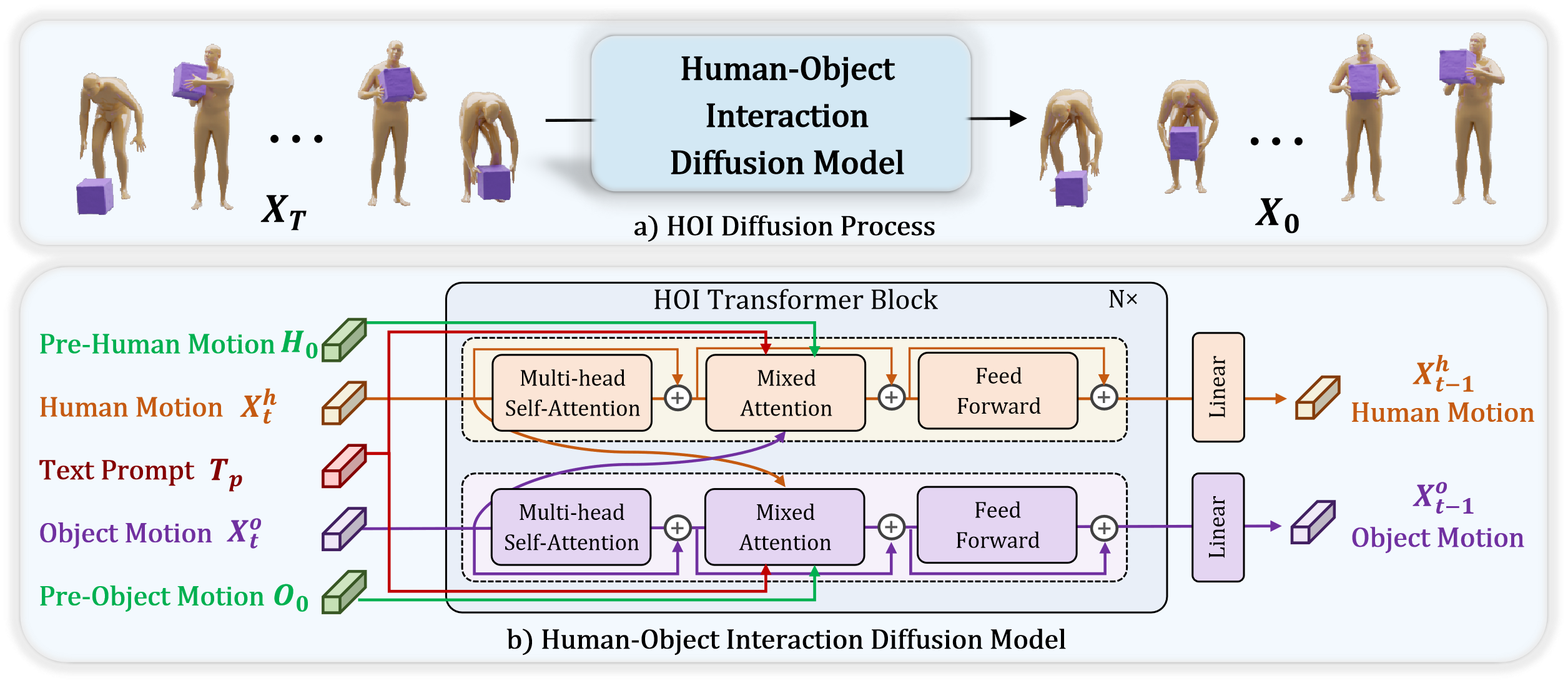
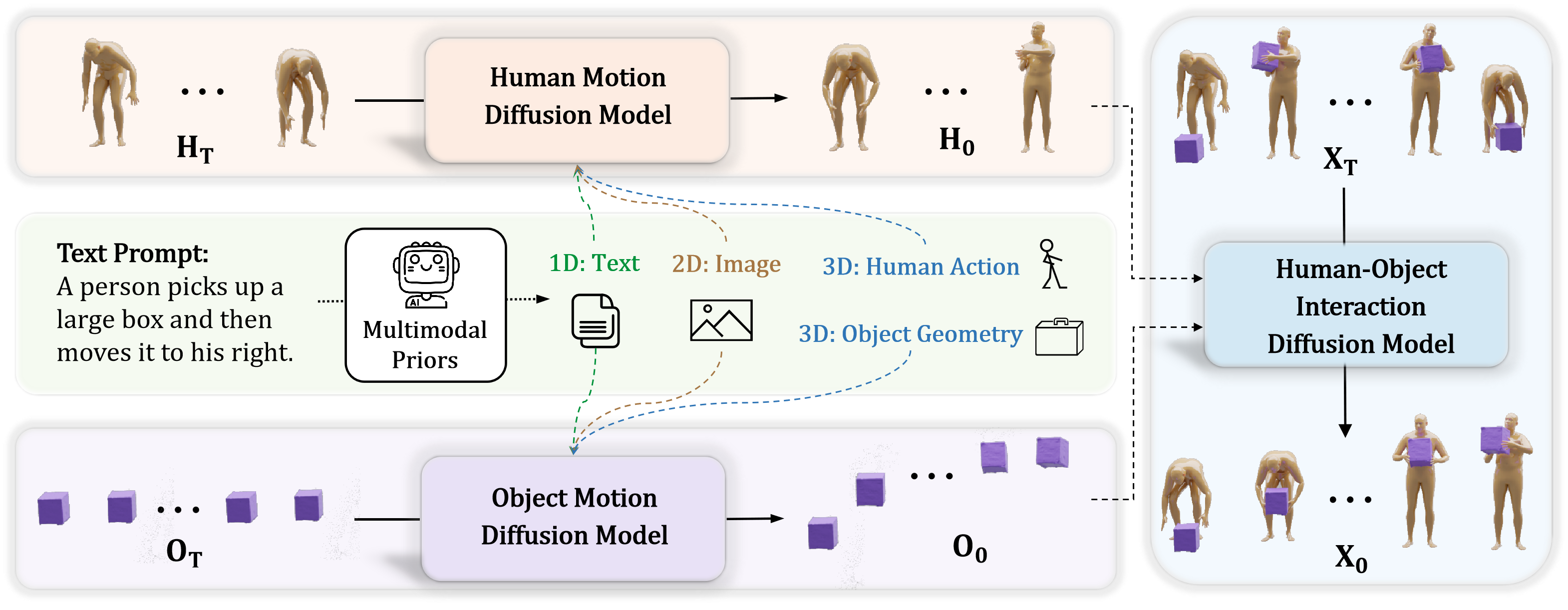
MP-HOI: Многомодальный фундамент для генерации взаимодействий
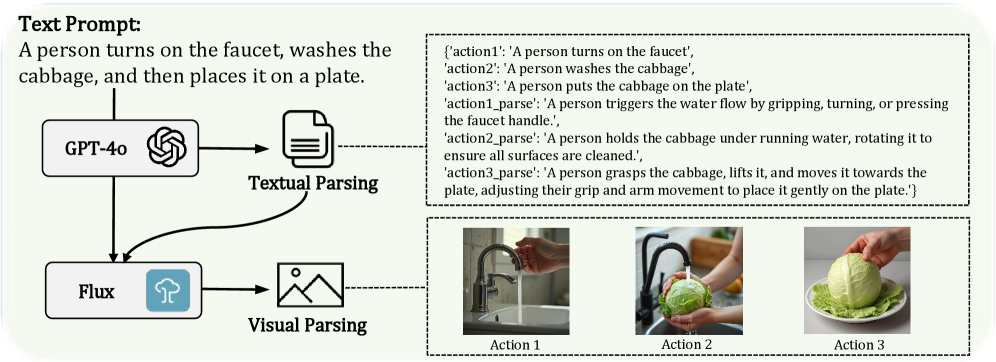
В основе фреймворка MP-HOI лежит использование мультимодальных априорных знаний, объединяющих текстовые описания, визуальные данные и трехмерную информацию для управления процессом генерации. Такой подход позволяет системе учитывать различные типы входных данных, формируя более полное представление о сцене и взаимодействиях. Текстовые описания задают семантические аспекты, визуальные данные — конкретные характеристики объектов и их положения, а трехмерные данные — геометрию и физические свойства, необходимые для реалистичной генерации взаимодействий между объектами. Комбинирование этих модальностей обеспечивает более точное и контекстуально релевантное формирование желаемых результатов.
В основе MP-HOI лежит интеграция двух ключевых моделей: GPT-4o и Flux. GPT-4o отвечает за обработку и понимание текстовых запросов, предоставляя семантическое понимание желаемого взаимодействия. Модель Flux, в свою очередь, специализируется на анализе и интерпретации визуальных данных, извлекая информацию об объектах и их окружении. Совместное использование этих моделей позволяет эффективно преобразовывать как текстовые описания, так и визуальные входные данные в структурированное представление, необходимое для генерации правдоподобных и контекстно-зависимых взаимодействий между объектами.
Улучшенное представление объектов играет ключевую роль в определении их свойств, включая геометрию, характеристики контакта и динамику. Геометрическое описание включает в себя точные размеры и форму объекта. Характеристики контакта определяют, как объект взаимодействует с другими объектами и поверхностями, учитывая трение и другие физические параметры. Динамика описывает поведение объекта во времени, включая его массу, инерцию и реакцию на внешние силы. Точное определение этих свойств необходимо для генерации правдоподобных и физически корректных взаимодействий между объектами в виртуальной среде, что позволяет создавать реалистичные сценарии взаимодействия человек-объект (HOI).
Понимание мультимодальных данных позволяет генерировать взаимодействия объектов (Human-Object Interaction, HOI) с повышенной контекстуальной осведомленностью и физической правдоподобностью. Использование текстовых описаний, визуальных данных и трехмерной информации совместно обеспечивает более точное определение взаимосвязей между объектами и участниками взаимодействия. Это приводит к созданию HOI, которые соответствуют реальным физическим ограничениям и логике, учитывая не только что происходит, но и где, как и почему. В результате генерируемые взаимодействия становятся более реалистичными и полезными для различных приложений, таких как робототехника, виртуальная реальность и создание контента.
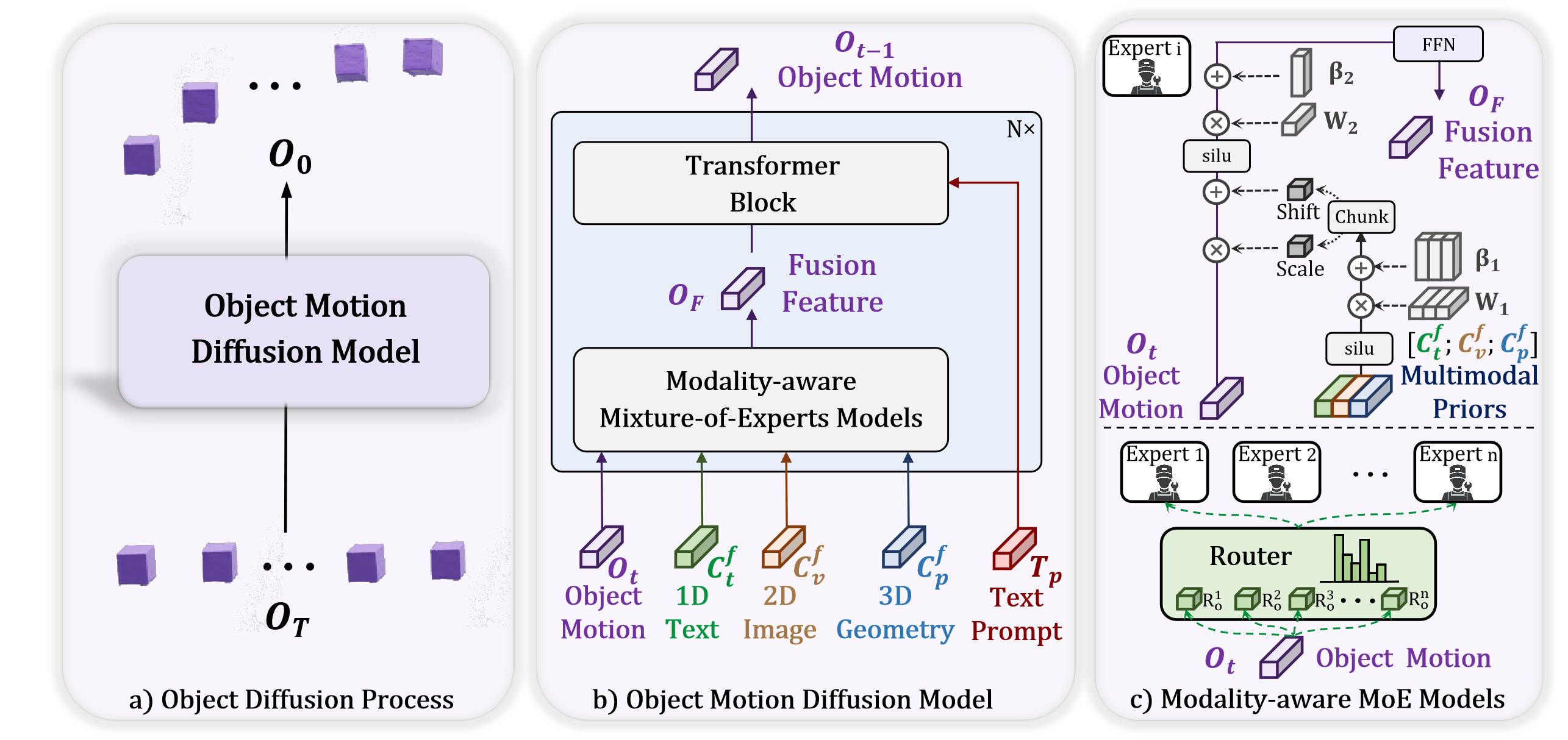
Каскадная диффузия: Уточнение и синтез движений
В нашей системе используется каскадная диффузионная модель (Cascaded Diffusion Model) для последовательной генерации движений человека, движений объектов и их взаимодействия. Этот подход предполагает многоступенчатый процесс, где на первом этапе генерируется базовая кинематика человека, затем — движение объектов в сцене, и, наконец, происходит уточнение движений с учетом взаимного влияния человека и объектов. Последовательная генерация позволяет обеспечить временную согласованность и плавные переходы между различными этапами движения, предотвращая артефакты и неестественные переходы, которые могут возникнуть при одновременной генерации всех компонентов движения.
Последовательная генерация движения в рамках каскадной диффузионной модели обеспечивает временную согласованность и плавные переходы между действиями за счет поэтапной обработки и уточнения. Каждый этап генерации учитывает результаты предыдущих, что позволяет избежать резких скачков или несоответствий в траекториях движения. Данный подход позволяет создавать реалистичные анимации, в которых каждое действие логично вытекает из предыдущего, формируя непрерывную и правдоподобную последовательность. Использование диффузионных моделей способствует созданию разнообразных и естественных движений, избегая типичных для традиционных методов роботизированности или неестественных переходов.
В архитектуре нашей системы используется подход Mixture-of-Experts (MoE) для эффективного объединения многомодальных признаков. MoE предполагает использование нескольких «экспертов» — отдельных нейронных сетей, специализирующихся на обработке определенных типов входных данных или аспектов задачи. Механизм «gate network» динамически определяет, какие эксперты наиболее релевантны для конкретного входного примера, и взвешивает их вклад в итоговый результат. Это позволяет модели адаптироваться к различным комбинациям входных данных (текст, данные о движении человека и объектов) и повышает точность синтеза движения за счет использования специализированных модулей обработки информации.
В нашей системе используется генерация движения на основе текстовых запросов, позволяющая преобразовывать текстовое описание в реалистичные трехмерные движения. Этот процесс включает в себя анализ текстового ввода для определения намерений и действий, а затем синтез соответствующей последовательности движений для виртуального персонажа или объекта. Текстовые запросы служат входными данными для модели, которая генерирует последовательность ключевых кадров или непосредственно траекторию движения в трехмерном пространстве, обеспечивая соответствие между текстовым описанием и визуальным представлением движения. Используемые алгоритмы позволяют учитывать контекст запроса и генерировать движения, соответствующие физическим ограничениям и естественным моделям поведения.
Валидация и производительность: Оценка реализма и согласованности
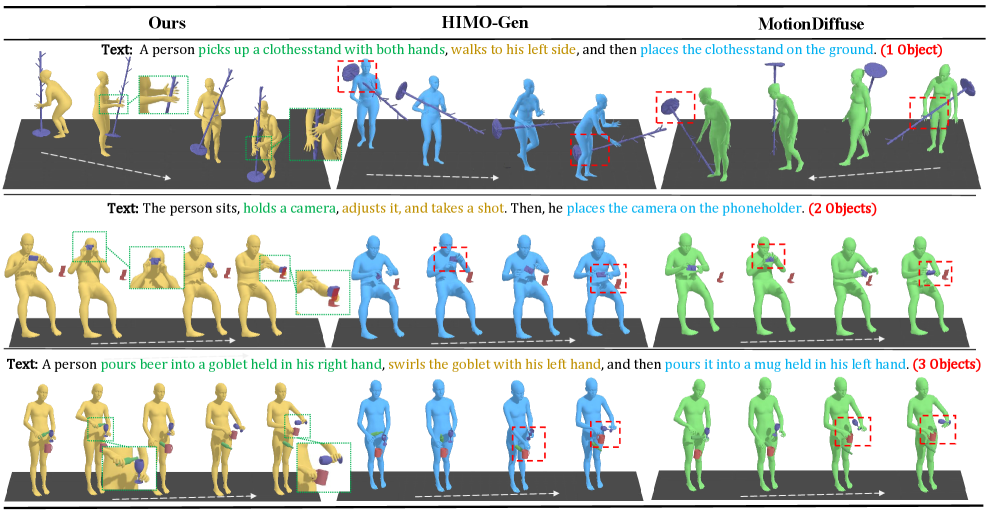
Проведенные эксперименты на наборах данных HIMO и FullBodyManipulation продемонстрировали существенное превосходство разработанного подхода над существующими аналогами. Полученные результаты указывают на значительное улучшение качества генерируемых движений, что подтверждается сравнительным анализом с передовыми методами в данной области. Достигнутые улучшения касаются не только визуальной реалистичности, но и семантической согласованности, что делает сгенерированные взаимодействия более естественными и правдоподобными. Эти улучшения открывают новые возможности для применения в различных областях, включая робототехнику, виртуальную реальность и создание анимации.
Для оценки реалистичности и семантической согласованности генерируемых движений использовался комплекс количественных метрик. В частности, рассчитывался показатель FID (Fréchet Inception Distance), позволяющий оценить сходство распределения сгенерированных и реальных данных. Дополнительно применялись метрики R-TOP, оценивающая разнообразие генерируемых движений, и MM-Dist (Motion Matching Distance), измеряющая соответствие между сгенерированными и целевыми траекториями. Использование данных метрик позволило объективно сравнить качество генерируемых движений с результатами, полученными другими современными подходами, и продемонстрировать значительное улучшение в реалистичности и правдоподобии взаимодействий.
Исследования показали, что разработанная методика MP-HOI демонстрирует значительное превосходство в генерации реалистичных и естественных взаимодействий, особенно в работе с деформируемыми объектами. Визуальная оценка сгенерированных движений подтверждает способность системы создавать правдоподобные сценарии манипулирования, где взаимодействие с мягкими и податливыми предметами выглядит физически обоснованным и соответствует ожиданиям человека. В отличие от существующих подходов, MP-HOI позволяет создавать более плавные и когерентные движения, избегая неестественных артефактов и обеспечивая более убедительное визуальное восприятие взаимодействия человека с окружающей средой, что открывает широкие возможности для применения в областях, требующих высокой степени реализма, таких как робототехника, виртуальная реальность и анимация.
Проведенные эксперименты демонстрируют значительное превосходство разработанного подхода в генерации реалистичных движений. В частности, наблюдается снижение метрики FID на 23.92% при работе с набором данных FullBodyManipulation и на впечатляющие 66.02% с набором HIMO, содержащим три объекта, по сравнению с существующими методами. Кроме того, достигнуты более высокие показатели R-TOP и MM-Dist, свидетельствующие о семантической согласованности генерируемых движений. Набор данных HIMO, состоящий из двух объектов, показал улучшение точности, полноты и F1-меры на 2.25%, 4.10% и 4.12% соответственно, в сравнении с алгоритмом CHOIS. Эти количественные результаты подтверждают способность подхода генерировать движения, которые не только визуально правдоподобны, но и соответствуют ожидаемым взаимодействиям.
Разработанная платформа демонстрирует впечатляющую способность моделировать сложные взаимодействия, что открывает новые перспективы в различных областях. В робототехнике это позволяет создавать более реалистичные и адаптивные системы, способные эффективно взаимодействовать с окружающим миром и выполнять сложные манипуляции. В сфере виртуальной реальности платформа обеспечивает создание более правдоподобных и иммерсивных сред, где пользователи могут взаимодействовать с виртуальными объектами и персонажами естественным образом. Кроме того, в области анимации, платформа значительно упрощает процесс создания реалистичных движений и взаимодействий персонажей, сокращая время и ресурсы, необходимые для достижения высокого качества визуализации. Возможность точного моделирования сложных взаимодействий делает данную разработку ценным инструментом для специалистов, работающих в этих и смежных областях.
Взаимодействие будущего: Направления развития и расширение
Разработка системы, способной обрабатывать взаимодействие в реальном времени и обратную связь, открывает возможности для создания принципиально новых виртуальных сред. Вместо заранее запрограммированных сценариев, система сможет динамически адаптироваться к действиям пользователя, мгновенно реагируя на его ввод и изменяя виртуальную реальность соответствующим образом. Это достигается за счет интеграции датчиков и алгоритмов, позволяющих системе анализировать действия пользователя, предсказывать его намерения и генерировать реалистичные ответы. Такой подход не только повышает степень погружения в виртуальный мир, но и делает взаимодействие более естественным и интуитивным, что особенно важно для обучения, развлечений и профессиональных симуляций. В результате, виртуальные среды становятся не просто пассивными окружениями, а активными участниками взаимодействия, способными к обучению и адаптации.
Для повышения универсальности разработанной системы, особое внимание уделяется методам обучения на ограниченном объеме данных и адаптации к новым типам объектов. Исследования направлены на разработку алгоритмов, способных эффективно обобщать знания, полученные на небольшом наборе примеров, и быстро адаптироваться к незнакомым объектам без необходимости повторного обучения с нуля. Это достигается за счет использования техник переноса обучения и мета-обучения, позволяющих системе извлекать полезную информацию из существующих знаний и применять её к новым задачам. Успешная реализация этих методов позволит значительно расширить сферу применения системы, сделав её способной генерировать реалистичные взаимодействия с объектами различной природы даже при отсутствии обширных обучающих данных.
Интеграция разработанной системы с алгоритмами обучения с подкреплением открывает перспективы для создания автономных агентов, способных выполнять сложные задачи, связанные с взаимодействием объектов. Такой подход позволяет агентам не просто распознавать и манипулировать объектами, но и обучаться оптимальным стратегиям выполнения задач посредством проб и ошибок, получая вознаграждение за успешные действия. В результате, система способна генерировать реалистичные и правдоподобные сценарии взаимодействия, где агенты адаптируются к изменяющимся условиям и учатся решать новые задачи без явного программирования. Это значительно расширяет возможности применения системы в виртуальных средах, робототехнике и симуляциях, позволяя создавать интеллектуальных помощников и автономных роботов, способных к сложным действиям и взаимодействию с окружающим миром.
Предвидится, что генерация взаимодействий человека и объектов (HOI) на основе искусственного интеллекта сыграет ключевую роль в стирании границ между физическим и цифровым мирами. Эта технология позволит создавать виртуальные окружения, неотличимые от реальности, где цифровые объекты реагируют на действия человека интуитивно и правдоподобно. В будущем, благодаря развитию данной области, станет возможным обучение, проектирование и даже удаленное управление физическими системами посредством виртуальных интерфейсов, открывая беспрецедентные возможности для взаимодействия человека с технологиями и окружающим пространством. Такой подход не только расширит возможности симуляций и обучения, но и позволит создавать новые формы развлечений, коммуникации и совместной работы, делая цифровой мир более доступным и интегрированным в повседневную жизнь.
Исследование, представленное в статье, как обычно, демонстрирует, что элегантная теория генерации взаимодействий человека и объектов из текстовых запросов быстро сталкивается с суровой реальностью. Авторы предлагают MP-HOI, каскадный подход с мультимодальными приоритетами, который, вероятно, покажет хорошие результаты на синтетических данных. Однако, как показывает опыт, любое «улучшение качества» неизбежно сопровождается увеличением вычислительных затрат и сложностью развертывания. Как точно подметил Ян Лекун: «Глубокое обучение — это хорошее программное обеспечение, но не наука». В данном случае, это очередное доказательство того, что мы не создаём искусственный интеллект, а просто компилируем статистические закономерности. И, конечно, все эти «объекты» и «взаимодействия» будут стабильно падать в продакшене, что, в принципе, последовательно.
Что дальше?
Представленная работа, несомненно, продвигает границу генерации движений человека и взаимодействия с объектами. Однако, стоит помнить: элегантная архитектура — это лишь начало. Скоро появятся первые случаи, когда промпт, казавшийся безобидным, породит физически невозможные или абсурдные взаимодействия. Багтрекер быстро пополнится новыми тикетами. Успех этой работы, как и любого другого подобного подхода, неизбежно столкнётся с суровой реальностью продакшена: несогласованностью данных, неполнотой обучающих выборок и, конечно же, желанием пользователей выжать максимум из системы, даже если это потребует «небольшой» эксплуатации.
Похоже, что фокус сместится от улучшения качества генерации к обеспечению её контролируемости и предсказуемости. Просто генерировать «реалистичные» движения недостаточно; необходимо, чтобы эти движения были полезными и безопасными. Ключевым станет разработка методов, позволяющих верифицировать и корректировать сгенерированные траектории, учитывая ограничения физического мира и потенциальные риски. В конце концов, мы не просто «деплоим» модели — мы отпускаем их в мир.
И, вероятно, мы скоро увидим, что «скрам» — это всего лишь способ убедить людей, что хаос управляем, даже когда речь идет о сложных системах, генерирующих трёхмерные анимации. У нас не DevOps-культура, у нас культ DevOops. И это, к сожалению, неизбежно.
Оригинал статьи: https://arxiv.org/pdf/2602.10659.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обзор Motorola Razr 50 Ultra
- Фотографируем муравьёв с Андреем Павловым
- Nikon D7200
- Warhammer 40,000: Space Marine 2 — Список всех врагов и боссов на данный момент
- Преодолевая границы масштабируемости рекомендательных систем
- vivo iQOO Z7 ОБЗОР: тонкий корпус, скоростная зарядка, чёткое изображение
- vivo S50 Pro mini ОБЗОР: чёткое изображение, беспроводная зарядка, скоростная зарядка
- Лучшие ноутбуки с матовым экраном. Что купить в мае 2026.
- vivo iQOO Z11x ОБЗОР: яркий экран, плавный интерфейс, удобный сенсор отпечатков
- Realme Neo8 ОБЗОР: яркий экран, плавный интерфейс, чёткое изображение
2026-02-12 11:40