Автор: Денис Аветисян
Исследователи представили комплексный набор данных и провели всесторонний анализ фундаментельных моделей, предназначенных для обработки и интерпретации электрической активности мозга.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
В работе представлен Brain4FMs — эталонный набор данных и методология оценки фундаментельных моделей для электроэнцефалографии, с акцентом на самообучение и обобщающую способность.
Несмотря на стремительное развитие моделей-оснований для анализа электроэнцефалограмм, отсутствует единая методология и стандартизированная платформа для их оценки. В настоящей работе, ‘Brain4FMs: A Benchmark of Foundation Models for Electrical Brain Signal’, представлен комплексный бенчмарк, позволяющий систематизировать и сравнивать различные модели-основания для обработки сигналов мозга. Авторы демонстрируют, что эффективность этих моделей напрямую зависит от состава обучающих данных, стратегий самообучения и архитектурных решений. Какие перспективы открываются для создания более точных и универсальных моделей-оснований, способных расшифровать сложные механизмы работы мозга и улучшить диагностику неврологических заболеваний?
За гранью традиционной обработки сигналов: Необходимость моделей, вдохновлённых мозгом
Традиционные методы обработки сигналов, разработанные для стабильных и предсказуемых данных, зачастую оказываются неэффективными при анализе мозговой активности. Сложность нейронных сетей, их нелинейность и постоянная изменчивость, обусловленная даже незначительными факторами, приводят к тому, что стандартные алгоритмы фильтрации, преобразования и статистического анализа не способны выделить значимые паттерны. Этот феномен особенно ярко проявляется при работе с электроэнцефалограммами (ЭЭГ) и магнитоэнцефалограммами (МЭГ), где слабые сигналы мозга подвержены влиянию множества артефактов и шумов. В результате, попытки интерпретации мозговой активности с помощью этих методов часто приводят к неточным или неполным выводам, ограничивая возможности нейронауки в понимании когнитивных процессов и нейронных механизмов.
Современные методы машинного обучения, несмотря на свою вычислительную мощность, часто сталкиваются с проблемой нехватки размеченных данных в нейробиологических исследованиях. Получение точных и полных меток для сложных нейронных сигналов требует значительных временных и финансовых затрат, а также высокой квалификации специалистов. Этот дефицит размеченных данных ограничивает возможности обучения и валидации алгоритмов машинного обучения, снижая их эффективность и обобщающую способность при анализе новых, ранее не встречавшихся нейрофизиологических данных. В результате, разработка эффективных моделей для расшифровки работы мозга становится сложной и дорогостоящей задачей, требующей поиска альтернативных подходов, не столь зависимых от большого объема размеченных данных.
Необходимость в новой парадигме обработки нейроизображений обусловлена ограничениями существующих методов. Традиционные алгоритмы, разработанные для обработки сигналов, зачастую не способны адекватно справиться с высокой сложностью и изменчивостью мозговой активности. В свою очередь, современные подходы машинного обучения, несмотря на свою мощь, требуют обширных объемов размеченных данных, получение которых в нейронауке является дорогостоящей и трудоемкой задачей. Поэтому, всё больше исследователей обращаются к изучению принципов работы самого мозга, стремясь использовать его внутреннюю структуру и эффективность для создания более совершенных моделей анализа нейроизображений. Такой подход позволит не только извлекать более глубокие и значимые сведения из данных, но и существенно снизить потребность в размеченных данных, открывая новые горизонты в понимании работы мозга и разработке инновационных нейротехнологий.
Модели-основы для мозга: Смена парадигмы в анализе нейроизображений
Модели-основы для анализа мозга представляют собой новый подход к обработке нейроизображений, вдохновленный успехами больших языковых моделей (LLM) в области обработки естественного языка. В отличие от традиционных методов, требующих обучения с нуля для каждой конкретной задачи, модели-основы используют принципы предварительного обучения на огромных объемах неразмеченных данных. Это позволяет им извлекать общие закономерности и представления из сигналов мозга, которые затем могут быть адаптированы и использованы для решения различных задач анализа нейроизображений, таких как классификация состояний мозга, обнаружение аномалий и прогнозирование клинических исходов. Аналогия с LLM заключается в способности модели-основы «понимать» базовые характеристики сигналов мозга, что существенно снижает потребность в больших объемах размеченных данных для обучения конкретным задачам.
Основой для обучения моделей, являющихся «фундаментальными моделями мозга», служит самообучение на обширных массивах неразмеченных данных нейроизображений. Этот подход позволяет моделям извлекать и кодировать сложные характеристики мозговой активности без необходимости ручной разметки данных. В процессе самообучения модель решает вспомогательные задачи, такие как предсказание замаскированных участков данных или восстановление искаженного сигнала, что способствует формированию устойчивых и обобщенных представлений о мозговой деятельности. В результате, модель формирует внутреннее представление данных, способное эффективно использоваться для решения различных задач анализа нейроизображений.
Предварительно обученные модели, основанные на нейронных сетях, позволяют эффективно адаптировать их для решения различных задач анализа данных мозга, даже при ограниченном объеме размеченных данных. В ходе исследований, использование таких моделей показало высокую точность и значения метрики AUROC, достигающие 92% на нескольких различных наборах данных. Это свидетельствует о способности моделей к обобщению и эффективной работе в условиях дефицита размеченных данных, что значительно снижает затраты на подготовку данных и упрощает процесс разработки решений в области нейронаук.
Раскрытие сложности мозговых сигналов с помощью продвинутого самообучения
Для обучения устойчивым представлениям немаркированных сигналов мозга применяются методы контрастивного обучения и генеративного моделирования. Контрастивное обучение направлено на сближение представлений схожих сигналов и отдаление представлений различных сигналов. Генеративные модели, такие как автоэнкодеры и VQ-VAE, реконструируют входные данные, вынуждая модель изучать компактные и информативные представления. Автоэнкодеры используют сжатие и восстановление данных для обучения скрытым представлениям, в то время как VQ-VAE применяет векторное квантование для дискретизации скрытого пространства, что позволяет создавать более структурированные представления сигналов мозга.
Для анализа пространственной структуры мозговой активности используются графовые нейронные сети (Graph Neural Networks, GNN). Эти сети моделируют взаимосвязи между различными областями мозга, представляя каждую область как узел графа, а связи между ними — как ребра. Такой подход позволяет учитывать не только активность в отдельных областях, но и паттерны взаимодействия между ними, что критически важно для понимания сложных когнитивных процессов. GNN способны эффективно обрабатывать данные, представленные в виде графов, и извлекать признаки, отражающие топологию и функциональные связи в мозговой сети. Применение GNN позволяет учитывать пространственную информацию, которую традиционные методы анализа сигналов могут упускать.
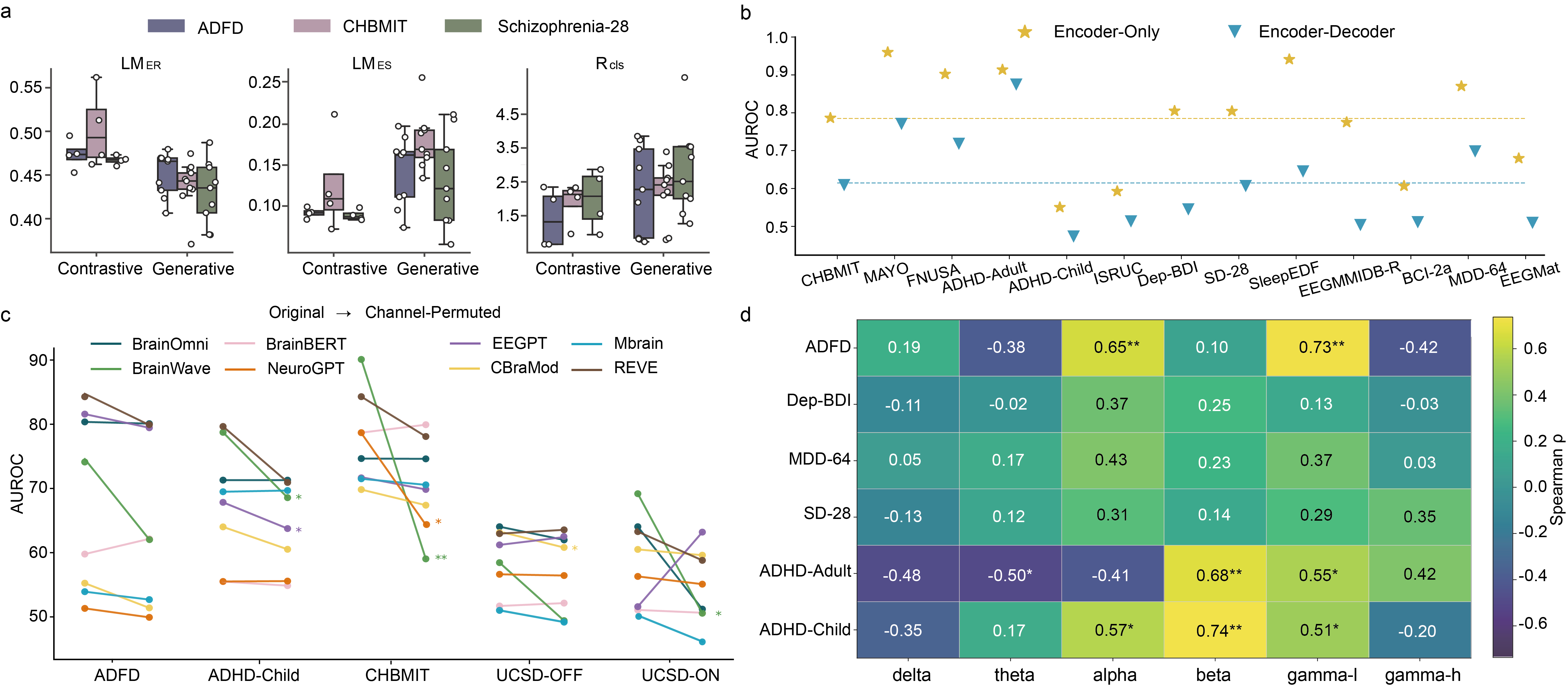
Оценка разработанных методов самообучения проводилась с использованием двух метрик: коэффициента Коэна Каппа и ошибки границы принятия решений (LMER). Значения коэффициента Коэна Каппа достигали 0.80 в задачах многоклассовой классификации, что свидетельствует о высокой степени согласованности результатов, превышающей уровень случайного совпадения. Ошибка границы принятия решений (LMER) варьировалась в диапазоне от 0.2 до 0.6, позволяя провести сравнительный анализ эффективности контрастивного обучения и генеративных моделей в контексте обработки сигналов мозга. Более низкие значения LMER указывают на лучшую способность модели к разграничению классов.
Бенчмаркинг и решение реальных задач в нейроимиджинге
Тщательное бенчмаркинг, использующее такие платформы, как Brain4FMs, играет решающую роль в оценке производительности и надежности моделей-оснований для нейровизуализации. Объективное сравнение различных архитектур и методов обучения на стандартизированных наборах данных позволяет выявить сильные и слабые стороны каждой модели, а также обеспечить воспроизводимость результатов. Использование комплексных бенчмарков, охватывающих широкий спектр задач и условий, необходимо для того, чтобы гарантировать, что модели-основания действительно обладают обобщающей способностью и могут быть успешно применены в реальных клинических и исследовательских сценариях. Такой подход не только способствует прогрессу в области нейронаук, но и позволяет формировать доверие к новым технологиям в сфере анализа изображений мозга.
Существенная проблема в нейроимиджинге заключается в расхождении между данными, используемыми для обучения моделей, и данными, получаемыми в реальных условиях, что известно как «смещение данных» (Dataset Shift). Это несоответствие может значительно снизить производительность моделей, поскольку они сталкиваются с изображениями, отличными от тех, на которых они были обучены. Необходимо разрабатывать модели, способные адаптироваться к различным условиям сканирования, различным протоколам сбора данных и вариациям в характеристиках пациентов. Устойчивость к смещению данных становится критически важным показателем эффективности моделей машинного обучения в нейронауке, поскольку гарантирует их надежность и применимость в клинической практике и исследовательских проектах, где данные постоянно меняются.
Исследование, проведенное с использованием эталонного набора данных Brain4FMs, включающего оценку 15 моделей на 18 различных наборах данных нейроизображений, выявило превосходство генеративных моделей в задачах анализа мозга. Особое внимание было уделено роли пространственного и частотного кодирования, которые оказались критически важными для достижения высокой производительности. Показатель разделения классов в пространстве вложений (R_{cls}) варьировался от 1.5 до 4.0, что указывает на способность моделей эффективно различать различные состояния и характеристики мозга. Результаты демонстрируют, что качественное кодирование пространственной информации и частотных характеристик нейроизображений является ключевым фактором для разработки эффективных и надежных моделей анализа мозга.
Исследование Brain4FMs закономерно подчеркивает важность не только архитектуры моделей, но и состава данных, используемых для обучения. Авторы демонстрируют, что даже самые изящные алгоритмы самообучения теряют эффективность, если данные не репрезентативны. Это подтверждает старую истину: «Всё, что оптимизировано, рано или поздно оптимизируют обратно». Иначе говоря, погоня за совершенством модели бессмысленна, если не уделять достаточного внимания качеству и разнообразию входных данных. В конечном итоге, нейронные сети — это лишь отражение тех закономерностей, которые заложены в обучающем наборе. А эти закономерности, как показывает практика, всегда сложнее, чем кажется на первый взгляд.
Что дальше?
Представленный анализ «фундаментальных моделей мозга» (Brain Foundation Models) неизбежно наталкивает на вопрос: а действительно ли это что-то принципиально новое? Или же это просто переименованный набор тех же самых сверточных сетей, только обученных на большем количестве данных и с более пафосным названием? История показывает, что каждая «революционная» технология завтра станет техдолгом. Данные, конечно, важны, но состав данных, как справедливо показано, — это ещё не гарантия стабильной работы. Если система стабильно выдаёт бессмысленные результаты, значит, она хотя бы последовательна.
Очевидно, что проблема обобщения между субъектами остаётся камнем преткновения. Самообучение (self-supervised learning) — это, безусловно, интересно, но пока что это больше похоже на попытку заставить алгоритм угадывать, что имел в виду другой человек, а не на реальное понимание мозговой активности. Иронично, но мы тратим годы на создание сложных моделей, чтобы потом удивляться, когда они не работают в реальном мире.
В конечном счете, кажется, что вся эта работа — это просто попытка оставить комментарии для будущих археологов, которые будут копаться в нашем коде и пытаться понять, что мы вообще пытались сделать. И пусть они нас простят, если окажется, что всё это было бессмысленно. Ведь в конечном итоге, главное — это не результат, а процесс… или хотя бы ощущение, что что-то делается.
Оригинал статьи: https://arxiv.org/pdf/2602.11558.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обзор Motorola Razr 50 Ultra
- Realme 12 Pro+ ОБЗОР: большой аккумулятор, плавный интерфейс, современный дизайн
- Как правильно закрепить ремень на фотокамере
- vivo iQOO Z11x ОБЗОР: яркий экран, плавный интерфейс, удобный сенсор отпечатков
- Фотографируем муравьёв с Андреем Павловым
- Преодолевая границы масштабируемости рекомендательных систем
- Cooler Master запускает комплект вертикального крепления видеокарты PCIe 5.0 за около 70 долларов в Китае.
- Warhammer 40,000: Space Marine 2 — Список всех врагов и боссов на данный момент
- 20 основных команд командной строки Windows 11, которые должен знать каждый пользователь
- ZTE nubia Focus 2 ОБЗОР: плавный интерфейс, большой аккумулятор, отличная камера
2026-02-13 23:15