Автор: Денис Аветисян
Исследователи представили архитектуру RI-Mamba, позволяющую находить 3D-модели по текстовому описанию, вне зависимости от их ориентации в пространстве.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"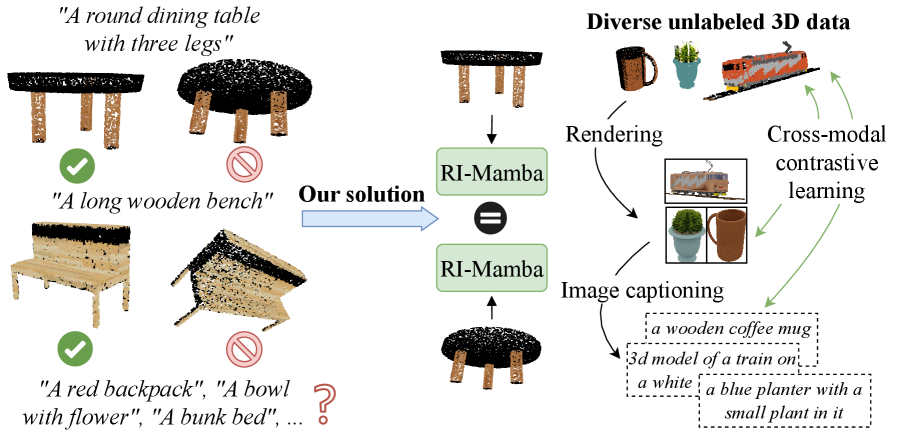
Предлагается модель RI-Mamba, основанная на state-space моделях и контрастивном обучении, для надежного поиска 3D-форм в больших наборах данных.
Несмотря на стремистый рост объемов и разнообразия 3D-активов, задача поиска по тексту в больших базах данных остается сложной из-за чувствительности существующих методов к ориентации объектов и ограниченной поддержки различных категорий. В данной работе, представленной под названием ‘RI-Mamba: Rotation-Invariant Mamba for Robust Text-to-Shape Retrieval’, предлагается RI-Mamba — первая модель на основе state-space, обладающая инвариантностью к поворотам, для эффективного поиска 3D-моделей по текстовому запросу. RI-Mamba использует глобальные и локальные системы координат, а также упорядочение Гильберта для обеспечения устойчивости к изменениям ориентации и сохранения геометрической структуры, что позволяет достичь передовых результатов на бенчмарке OmniObject3D, охватывающем более 200 категорий объектов. Сможет ли предложенный подход стать основой для создания интеллектуальных систем поиска и манипулирования 3D-объектами в виртуальной реальности и других приложениях?
Постижение Трехмерных Форм: Вызов для Алгоритмов
Точное распознавание трехмерных форм является ключевым элементом для широкого спектра современных технологий, включая робототехнику и системы дополненной и виртуальной реальности. Однако, существующие методы часто демонстрируют значительную зависимость от угла обзора, что существенно ограничивает их практическое применение. Проблема заключается в том, что один и тот же объект, представленный с разных точек зрения, может интерпретироваться алгоритмами как различные сущности. Это создает серьезные трудности для роботов, которым необходимо надежно идентифицировать объекты независимо от их ориентации, а также для AR/VR приложений, стремящихся к реалистичному и стабильному отображению трехмерных сцен. Разработка методов, устойчивых к изменениям точки зрения, представляет собой важную задачу в области компьютерного зрения и машинного обучения.
Традиционные методы анализа трехмерных объектов часто демонстрируют ограниченную способность к обобщению при изменении ориентации. Это означает, что система, успешно распознающая предмет в одном положении, может испытывать затруднения при его повороте или наблюдении с другого угла. Данное ограничение существенно препятствует внедрению технологий компьютерного зрения в практические приложения, такие как робототехника и дополненная реальность, где объекты постоянно меняют свое положение в пространстве. Неспособность к адаптации к различным точкам обзора требует разработки новых подходов, обеспечивающих устойчивость к вращениям и позволяющих системам понимать геометрию объектов независимо от их ориентации. В конечном итоге, преодоление этой проблемы является ключевым шагом к созданию действительно интеллектуальных систем, способных надежно взаимодействовать с окружающим миром.
Основная сложность в обработке трехмерных форм заключается в отсутствии встроенной инвариантности к вращению во многих существующих алгоритмах. Это означает, что незначительное изменение угла обзора объекта может приводить к существенно отличающимся результатам анализа, что делает систему неспособной надежно распознавать один и тот же объект в различных ориентациях. Такая чувствительность к вращению ограничивает применимость методов трехмерной обработки в реальных условиях, где объекты постоянно меняют свое положение в пространстве. Вследствие этого, роботы могут испытывать трудности с захватом объектов, а системы дополненной реальности — с корректным наложением виртуальных элементов на реальный мир, поскольку алгоритм не может последовательно интерпретировать один и тот же объект при различных углах обзора.
RI-Mamba: Новая Архитектура, Нечувствительная к Вращениям
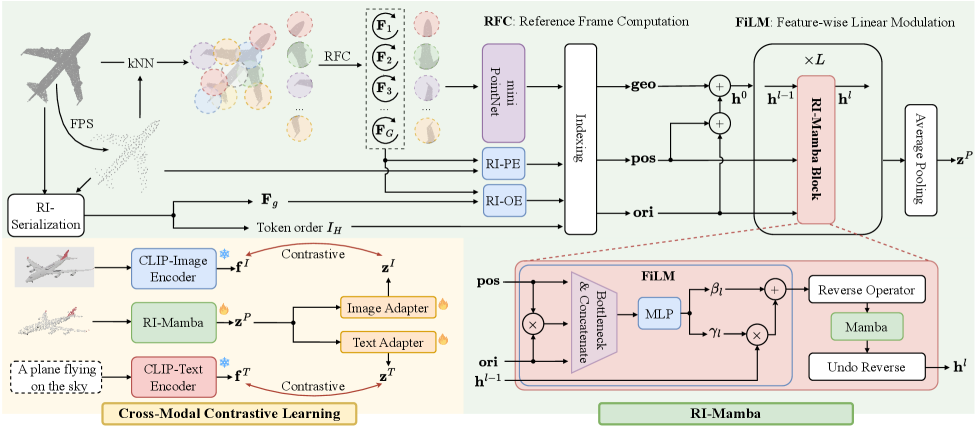
RI-Mamba представляет собой новую архитектуру, использующую модель пространства состояний (state-space model, SSM) специально для обработки 3D облаков точек с обеспечением инвариантности к вращениям. В отличие от традиционных подходов, которые требуют больших вычислительных затрат для обработки всех возможных ориентаций, RI-Mamba позволяет эффективно извлекать признаки, не зависящие от положения и ориентации облака точек в пространстве. Ключевым аспектом является способность модели представлять и обрабатывать данные, сохраняя инвариантность к вращениям, что критически важно для задач, где ориентация объекта не является определяющей, например, распознавание объектов или сегментация сцены. Использование SSM позволяет модели эффективно улавливать временные зависимости в последовательностях точек, представляя их в виде скрытого состояния, что способствует повышению производительности и снижению вычислительной сложности.
Архитектура RI-Mamba обеспечивает разделение формы и позы в обработке 3D-облаков точек за счет комбинирования локальной системы координат и кривой Гильберта. Локальная система координат позволяет привязать признаки каждой точки к ее непосредственному окружению, что обеспечивает инвариантность к глобальным поворотам. Кривая Гильберта, будучи пространственно-заполняющей, обеспечивает эффективное кодирование пространственного расположения точек, позволяя модели учитывать их относительное положение и, таким образом, отделить информацию о форме от информации о позе. Такое разделение позволяет модели более эффективно обобщать данные и улучшает ее производительность в задачах, требующих инвариантности к поворотам.
Модуляция признаков с помощью линейных преобразований (FiLM) в RI-Mamba используется для адаптации признаков точек в зависимости от их пространственного контекста. В рамках данной архитектуры, FiLM применяет аффинные преобразования к признакам, параметры которых зависят от положения точки в пространстве. Это позволяет модели динамически изменять представление признаков в зависимости от локальной геометрии, что приводит к улучшению производительности при обработке 3D-облаков точек. По сути, FiLM позволяет сети учитывать взаимосвязи между точками и более эффективно извлекать значимые признаки, зависящие от контекста.
Превосходство в Поиске 3D-Моделей по Текстовому Запросу
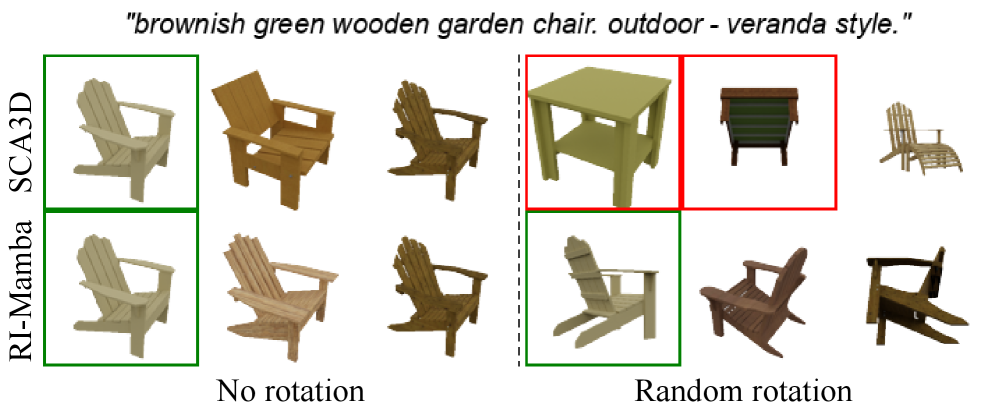
Модель RI-Mamba демонстрирует значительное превосходство над существующими передовыми (state-of-the-art, SOTA) трансформаторами, инвариантными к вращению, в задачах поиска 3D-моделей по текстовому запросу. Экспериментальные результаты показывают, что RI-Mamba обеспечивает более высокую точность извлечения релевантных 3D-моделей по сравнению с альтернативными подходами, использующими аналогичные механизмы инвариантности к вращению. Это превосходство проявляется в улучшенных метриках оценки, таких как средняя точность (mAP) и частота попадания в топ-k релевантных результатов (Recall Rate @k), что подтверждает эффективность архитектуры RI-Mamba в задачах text-to-shape retrieval.
Модель RI-Mamba демонстрирует наивысший показатель средней точности (mAP) в задачах извлечения 3D-моделей на наборе данных OmniObject3D в условиях zero-shot 3D-to-3D поиска. Результаты показывают стабильное превосходство над существующими методами во всех конфигурациях вращения 3D-моделей, что подтверждает эффективность подхода RI-Mamba в задачах, требующих устойчивости к изменениям ориентации объектов. Достигнутый уровень mAP свидетельствует о высокой точности ранжирования релевантных 3D-моделей в ответ на входные запросы, что является ключевым показателем эффективности системы извлечения.
Оценка модели RI-Mamba на наборах данных OmniObject3D и Text2Shape подтверждает её эффективность при работе с разнообразными коллекциями 3D-моделей. В частности, на Text2Shape RI-Mamba демонстрирует более высокую метрику Recall Rate @k (RR@k) по сравнению с методами, требующими обучения с использованием информации об отдельных частях объектов. Это указывает на способность модели эффективно извлекать и сопоставлять 3D-формы непосредственно из текстовых запросов, без необходимости в детальной разметке компонентов объектов.

Раскрытие Потенциала Кросс-Модального Обучения
Интеграция RI-Mamba с обучением контрастному сопоставлению различных модальностей, использующая CLIP для создания надежных векторных представлений текста и изображений, значительно расширяет возможности модели по установлению связи между языком и трехмерными формами. Этот подход позволяет модели не просто распознавать объекты, но и понимать их описание на естественном языке, а также генерировать трехмерные модели на основе текстовых запросов. Используя CLIP, система эффективно сопоставляет визуальные признаки с семантическим значением слов, обеспечивая более точное и интуитивное взаимодействие между человеком и компьютером в задачах, связанных с трехмерным пространством. Такое сочетание технологий открывает новые перспективы для создания интеллектуальных систем, способных к сложному анализу и генерации трехмерного контента.
Разработанный подход открывает возможности для создания принципиально новых 3D-поисковых систем и инструментов для создания контента. Благодаря способности модели эффективно связывать текстовые запросы с 3D-формами, пользователи смогут находить нужные объекты в трехмерном пространстве, используя естественный язык, что значительно упрощает процесс поиска по сравнению с традиционными методами, основанными на ключевых словах или сложных параметрах. Более того, эта технология позволяет автоматизировать процесс создания 3D-моделей на основе текстовых описаний, предоставляя дизайнерам и художникам инструменты для быстрого прототипирования и реализации сложных проектов. В результате, становится возможным создание интерактивных 3D-сред, где пользователи могут исследовать и манипулировать объектами, используя интуитивно понятные текстовые команды.
Исследования показали, что архитектура RI-Mamba демонстрирует значительно более эффективное масштабирование при увеличении количества входных токенов, представляющих 3D-формы. В частности, для обработки 2048 токенов RI-Mamba требует всего около 2 ГБ оперативной памяти, в то время как RI-Transformer в аналогичных условиях потребляет более 20 ГБ. Такая экономия ресурсов открывает новые возможности для применения в требовательных областях, таких как робототехника, где обработка сложных 3D-моделей в реальном времени критически важна, а также в виртуальной реальности и цифровом дизайне, где требуется работа с огромными массивами данных и создание детализированных объектов.

Исследование представляет собой элегантное применение принципов математической чистоты к задаче извлечения трехмерных форм по текстовому описанию. Архитектура RI-Mamba, основанная на инвариантности к вращению и моделях пространства состояний, демонстрирует стремление к созданию алгоритма, предсказуемого и устойчивого к вариациям входных данных. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть разработан таким образом, чтобы он не просто выполнял задачи, но и понимал их суть». Данная работа подтверждает эту мысль, поскольку RI-Mamba не просто сопоставляет текст с формой, а стремится к глубокому пониманию геометрических преобразований и семантической связи между ними, что особенно важно для работы с большими 3D-датасетами.
Что дальше?
Представленная работа, несомненно, демонстрирует элегантность подхода к задаче извлечения 3D-форм по текстовому запросу, но истинная строгость алгоритма проявляется лишь в его способности справляться с непредсказуемостью реальных данных. Инвариантность к поворотам — важный шаг, но он лишь смягчает, а не устраняет проблему неоднозначности. Будущие исследования должны сосредоточиться на более глубоком понимании семантической информации, заключенной в текстовом описании, и её точной привязке к геометрическим особенностям 3D-модели. Недостаточно просто «видеть» объект; необходимо понимать его назначение и контекст.
Особенно актуальным представляется вопрос о масштабируемости предложенного подхода к действительно крупным и разнообразным наборам данных. Современные архитектуры, даже такие изящные, как Mamba, сталкиваются с экспоненциальным ростом вычислительной сложности. Истинное решение лежит не в увеличении вычислительных ресурсов, а в разработке более эффективных алгоритмов, способных к самообучению и адаптации к новым условиям. В хаосе данных спасает только математическая дисциплина.
В конечном итоге, задача извлечения 3D-форм по тексту — это лишь частный случай более общей проблемы — построения искусственного интеллекта, способного к пониманию и интерпретации информации. И пока алгоритмы не смогут продемонстрировать истинное понимание, а не просто статистическую корреляцию, все достижения в этой области останутся лишь красивыми, но хрупкими иллюзиями.
Оригинал статьи: https://arxiv.org/pdf/2602.11673.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Фотографируем муравьёв с Андреем Павловым
- Обзор Motorola Razr 50 Ultra
- Nikon D7200
- Преодолевая границы масштабируемости рекомендательных систем
- Как правильно обрабатывать портрет в фотошоп
- OnePlus 15T ОБЗОР: большой аккумулятор, беспроводная зарядка, замедленная съёмка видео
- Обзор Moto G Stylus 5G (2024)
- vivo iQOO Z11x ОБЗОР: яркий экран, плавный интерфейс, удобный сенсор отпечатков
- Обзор телеобъектива Nikkor 70-300 VR AF-S
- Oppo A5 ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, большой аккумулятор
2026-02-15 12:05