Автор: Денис Аветисян
Исследователи предлагают инновационную систему, использующую обучение с подкреплением для более точного определения и отслеживания объектов в видеорядах.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Предложен фреймворк STVG-R1, улучшающий пространственно-временную привязку объектов в видео посредством объектно-центричного визуального промптинга и формирования вознаграждений.
Несмотря на успехи в области визуально-языковых моделей, проблема несоответствия между текстовыми описаниями и визуальными координатами остается актуальной, особенно в задачах пространственно-временной привязки в видео. В данной работе, представленной в статье ‘STVG-R1: Incentivizing Instance-Level Reasoning and Grounding in Videos via Reinforcement Learning’, предлагается новый подход, основанный на объектно-ориентированном визуальном промптинге и обучении с подкреплением, позволяющий переформулировать задачу предсказания координат в компактную идентификацию экземпляров. Эксперименты на шести бенчмарках демонстрируют, что предложенный фреймворк STVG-R1 превосходит базовую модель Qwen2.5-VL-7B на 20.9% по метрике m_IoU на HCSTVG-v2 и достигает новых результатов в задачах сегментации видео, открывая возможности для более эффективной и обобщенной обработки видеоинформации?
Понимание Визуального Контекста: Задача Точной Локализации
Традиционные модели, объединяющие зрение и язык (Vision-Language Models, VLMs), сталкиваются с существенными трудностями при точном определении местоположения объектов и действий в видеоматериалах. Эта проблема обусловлена фундаментальным несоответствием между визуальной информацией, извлекаемой из кадров, и текстовым описанием, которое должно её интерпретировать. Визуальные признаки и лингвистические представления оперируют в различных модальностях, что приводит к неточностям при сопоставлении объектов и событий в видео с соответствующими словами и фразами. В результате, модели часто не способны определить точные границы объекта во времени и пространстве, что снижает их эффективность в задачах, требующих высокой точности локализации, таких как видео-поиск и автоматическое редактирование видео.
В процессе выполнения задачи видео-локализации, современные модели, объединяющие обработку изображений и естественного языка, нередко демонстрируют феномен, условно называемый «галлюцинациями». Данное явление проявляется в том, что предсказания модели о местоположении объекта или действия в видео выходят за рамки действительной области видимости или разрешения кадра. Иными словами, алгоритм может «увидеть» нечто, чего на самом деле в кадре нет, или указать на область, находящуюся за пределами видео. Такие неточности существенно снижают эффективность системы в задачах, требующих высокой степени локализационной точности, например, в автоматизированном анализе видеоконтента или управлении робототехникой, где надежное определение границ объекта критически важно.
Существующие методы видео-локализации часто демонстрируют недостаточную точность как в пространственном, так и во временном аспектах, что существенно ограничивает их применимость в реальных сценариях. Неспособность четко определить границы объекта или действия во времени и пространстве приводит к неточным результатам, делая невозможным эффективное использование таких систем в задачах, требующих высокой детализации, например, в автономных транспортных средствах или в хирургической робототехнике. Погрешности в определении начала и конца действия, или в определении точного местоположения объекта в кадре, приводят к тому, что системы не могут надежно выполнять поставленные задачи, и требуют дальнейшей доработки для обеспечения необходимой степени достоверности и надежности.
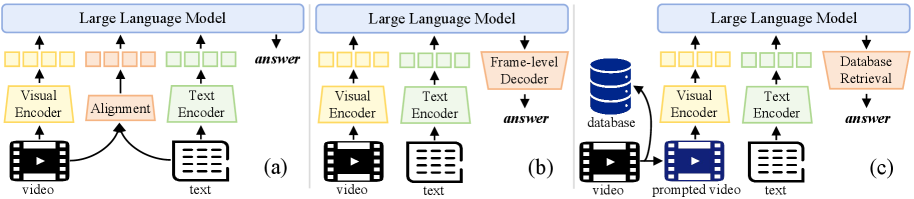
Объектно-Ориентированное Промптирование: Фокусировка Визуального Внимания
Объектно-ориентированное визуальное промптирование напрямую решает проблему межмодального несоответствия, назначая уникальные идентификаторы каждому объекту в каждом кадре видео. Этот подход позволяет модели четко различать и отслеживать отдельные объекты на протяжении всей последовательности, избегая путаницы и неверной локализации, возникающих при использовании традиционных методов, ориентированных на весь кадр. Присвоение уникальных идентификаторов обеспечивает точную привязку текстовых запросов к конкретным визуальным элементам, что существенно повышает точность и надежность процесса визуального обоснования (grounding).
Для создания точных визуальных запросов в методе объектно-ориентированного промптинга используются современные модели сегментации, такие как SAM2, и детекторы объектов, например, YOLOv12-x. SAM2 обеспечивает точное выделение границ объектов на изображении, а YOLOv12-x — надежное обнаружение и классификацию объектов. Комбинация этих технологий позволяет получить детальные и специфичные визуальные подсказки, необходимые для эффективного взаимодействия с мультимодальными моделями и точной локализации указанных объектов в видеопотоке.
Ориентация модели на отдельные объекты в кадре значительно снижает вероятность неточной локализации. Традиционные методы визуального промтинга могут приводить к ошибкам, когда модель фокусируется на общей сцене, а не на конкретном целевом объекте. Направляя внимание модели на идентифицированные объекты с помощью уникальных идентификаторов, достигается более точное сопоставление визуальной информации с текстовым запросом. Это, в свою очередь, улучшает процесс «заземления» (grounding), обеспечивая более надежное и релевантное выполнение задач, связанных с визуальным пониманием и взаимодействием.

STVG-R1: Обучение с Подкреплением для Пространственно-Временного Обоснования
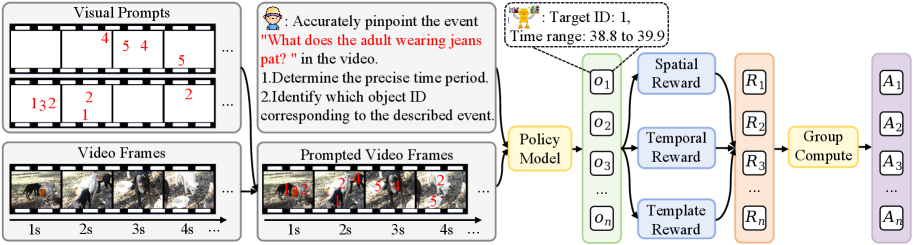
STVG-R1 представляет собой систему, использующую обучение с подкреплением для оптимизации производительности в задачах пространственной и временной привязки объектов в видео. В основе системы лежит разработка специализированного алгоритма GRPO и функции вознаграждения, позволяющих модели уточнять свои прогнозы на основе обратной связи, получаемой при анализе видеоданных. Такой подход направлен на повышение точности определения местоположения и отслеживания объектов во времени, что критически важно для задач понимания видеоконтента и взаимодействия с ним.
В основе обучения модели STVG-R1 лежит алгоритм GRPO (Gradient-based Reward-guided Policy Optimization) и разработанная функция вознаграждения. Алгоритм GRPO позволяет модели итеративно улучшать свои предсказания, используя градиенты, вычисленные на основе полученной обратной связи из видеоданных. Функция вознаграждения оценивает качество предсказаний в пространстве и времени, предоставляя сигнал для корректировки политики модели. Этот процесс обучения с подкреплением позволяет модели STVG-R1 адаптироваться к особенностям видеоданных и повышать точность пространственной и временной привязки объектов, что приводит к улучшению метрик, таких как m_vIoU и J&F на различных датасетах.
Экспериментальные исследования, проведенные на наборах данных HCSTVG, VidSTG, Ego4D и Grounded-VIDSitu, продемонстрировали значительное улучшение как пространственной согласованности, так и временной точности модели STVG-R1. В частности, на наборе данных HCSTVG-v2 при использовании Qwen3-VL-8B достигнут средний m_vIoU в 35.8%, что свидетельствует о высокой эффективности предложенного подхода к решению задачи пространственно-временного обоснования в видео.
Эксперименты показали, что разработанный фреймворк демонстрирует абсолютное улучшение в 4.0% по сравнению с наиболее производительной моделью, обученной методом SFT (SpaceVLLM), на наборе данных HCSTVG-v2. Кроме того, зафиксировано улучшение на 0.6% по сравнению с моделью LLaVA-ST при оценке на наборе данных ST-Align. Данные результаты подтверждают эффективность предложенного подхода к обучению и его способность к более точной пространственно-временной привязке в задачах анализа видео.
В рамках данной работы достигнуты новые передовые результаты в задаче многообъектной референсной сегментации видео, а именно, показатель J&F (Intersection-over-Union и Fidelity) составил 47.3% на наборе данных MeViS. Данный результат на 7.7 процентных пункта превышает показатели второй по эффективности модели LLaVA-ST на наборе данных Charades-STA, что подтверждает превосходство предложенного подхода в задачах точной сегментации и соответствия референсным описаниям в динамических видеосценах.
Расширение Рамок: Выход за Пределы Базовой Производительности
Архитектура STVG-R1 продемонстрировала высокую гибкость, успешно интегрируя специализированные модели для существенного повышения производительности. В частности, применение TubeDETR позволило оптимизировать задачи отслеживания объектов на видео, в то время как SpaceVLLM значительно улучшил понимание пространственных отношений между ними. Модель Time-R1, в свою очередь, способствовала более точному анализу временных зависимостей в видеопотоке. Данные расширения не только увеличивают точность и скорость обработки видеоинформации, но и подтверждают потенциал STVG-R1 как платформы для разработки и внедрения передовых алгоритмов видеоанализа.
Интеграция передовых визуально-языковых моделей (VLM), таких как InternVL3-8B, Qwen2.5-VL-7B, Qwen2.5-VL-72B и Qwen3-VL-8B, наглядно демонстрирует гибкость и масштабируемость разработанной STVG-R1. Успешное взаимодействие с этими разнообразными моделями подтверждает, что фреймворк не ограничен конкретной архитектурой VLM, а способен адаптироваться к различным подходам и уровням сложности. Это обеспечивает возможность использования наиболее подходящей модели для конкретной задачи видеопонимания, а также открывает перспективы для дальнейшего улучшения производительности и расширения области применения фреймворка за счет интеграции новых, перспективных VLM.
Гибкость разработанной STVG-R1 позволяет не только постоянно совершенствовать её производительность за счёт интеграции новых моделей, таких как TubeDETR и SpaceVLLM, но и значительно расширяет сферу применения. Благодаря совместимости с передовыми визуально-языковыми моделями, включая InternVL3-8B, Qwen2.5 и Qwen3-VL, платформа способна адаптироваться к разнообразным задачам анализа видео, от распознавания объектов и действий до понимания сложных сцен и событий. Эта адаптивность открывает перспективы для использования STVG-R1 в областях, требующих углубленного понимания видеоконтента, например, в автономных системах, робототехнике и интеллектуальном видеонаблюдении, способствуя развитию более эффективных и интеллектуальных систем анализа видеоданных.

Исследование, представленное в статье, фокусируется на улучшении пространственно-временной привязки в видео посредством обучения с подкреплением и объектно-ориентированного визуального промптинга. Этот подход позволяет системе более точно идентифицировать конкретные экземпляры объектов во времени. Как однажды заметил Джеффри Хинтон: «Наши модели учатся, когда мы заставляем их делать что-то сложное, а не просто предсказывать следующий пиксель». Подобно этому, STVG-R1 не просто предсказывает координаты, а определяет конкретные объекты, что способствует развитию более глубокого понимания видео и, как следствие, повышению обобщающей способности модели. Ключевым элементом является переформулировка задачи предсказания координат в задачу идентификации экземпляров, что позволяет системе лучше ориентироваться в сложных визуальных сценах и устанавливать более точные связи между визуальными данными и языковыми описаниями.
Что дальше?
Представленная работа, безусловно, продвигает область пространственно-временной привязки в видео, переосмысливая задачу как идентификацию экземпляров. Однако, подобно любому элегантному решению, оно лишь отодвигает некоторые проблемы на второй план. Необходимо внимательно исследовать границы данных, чтобы избежать ложных закономерностей, возникающих при упрощении координатного предсказания до идентификации объектов. Очевидно, что текущие модели остаются уязвимыми к изменениям в освещении, окклюзиям и нестандартным ракурсам съемки — ограничения, которые, как показывает практика, трудно обойти даже самым изощренным алгоритмам.
Будущие исследования могли бы сосредоточиться на разработке более устойчивых метрик вознаграждения в рамках обучения с подкреплением. Простое улучшение точности идентификации недостаточно; необходимо учитывать контекст и семантическую согласованность действий. Более того, представляется перспективным изучение возможностей переноса знаний из других модальностей, таких как звук и текст, для повышения обобщающей способности моделей. В конечном счете, истинный прогресс требует не только улучшения алгоритмов, но и глубокого понимания принципов, лежащих в основе визуального восприятия.
Вполне вероятно, что за кажущейся простотой идентификации объектов скрываются более сложные закономерности, которые еще предстоит раскрыть. Подобно алхимикам, стремящимся к философскому камню, исследователи в этой области должны продолжать экспериментировать и искать новые пути к более интеллектуальным и адаптивным системам.
Оригинал статьи: https://arxiv.org/pdf/2602.11730.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обзор Motorola Razr 50 Ultra
- Фотографируем муравьёв с Андреем Павловым
- Nikon D7200
- Преодолевая границы масштабируемости рекомендательных систем
- Как правильно обрабатывать портрет в фотошоп
- OnePlus 15T ОБЗОР: большой аккумулятор, беспроводная зарядка, замедленная съёмка видео
- Обзор Moto G Stylus 5G (2024)
- Xiaomi Redmi R70 ОБЗОР: большой аккумулятор, плавный интерфейс
- Лучшие ноутбуки с матовым экраном. Что купить в мае 2026.
- vivo Y19s Pro ОБЗОР: удобный сенсор отпечатков, большой аккумулятор, яркий экран
2026-02-15 13:42