Автор: Денис Аветисян
Новая работа показывает, что искусственный интеллект способен достичь человеческого уровня восприятия трехмерных объектов, просто анализируя изображения с разных ракурсов.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"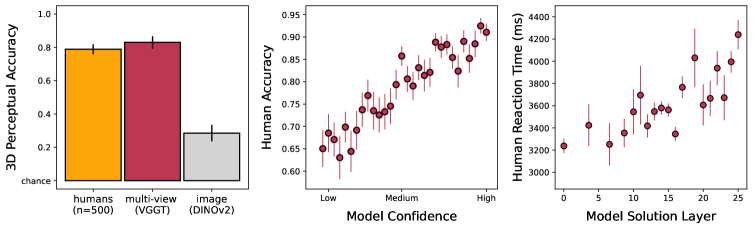
Модель, обученная на естественных визуальных данных, демонстрирует человеческую производительность в задачах восприятия 3D-форм без специальной настройки.
Несмотря на десятилетия исследований, моделирование человеческой способности к восприятию трехмерной формы объектов по двухмерным изображениям оставалось сложной задачей. В работе ‘Human-level 3D shape perception emerges from multi-view learning’ представлена новая модель, демонстрирующая человеческий уровень точности в задачах трехмерного восприятия формы, основанная на обучении по нескольким видам с использованием естественных визуальных данных. Модель, обученная на предсказание пространственной информации, такой как положение камеры и глубина, достигает сопоставимых результатов с человеческим восприятием без какой-либо специфической настройки или обучения. Не является ли это свидетельством того, что общие механизмы обучения могут быть достаточны для развития сложных способностей, таких как трехмерное восприятие, и какие перспективы открываются для создания более реалистичных и эффективных систем компьютерного зрения?
Иллюзия Трехмерности: От Плоского Мира к Глубине
Традиционные методы компьютерного зрения, успешно справляющиеся с анализом двумерных изображений, зачастую сталкиваются с серьезными трудностями при восстановлении трехмерной формы объектов. В то время как распознавание паттернов и текстур на плоской поверхности относительно просто, определение глубины, ориентации и общей геометрии предмета по его изображению требует значительно более сложных алгоритмов. Проблема усугубляется искажениями, вызванными перспективой, освещением и окклюзиями — когда часть объекта скрыта другими предметами. Поэтому, несмотря на значительные успехи в области 2D-анализа, надежное и точное воссоздание трехмерной структуры остается сложной задачей, требующей разработки принципиально новых подходов и методов.
Точное восприятие трехмерного пространства играет ключевую роль в развитии современных технологий и углублении понимания окружающего мира. В робототехнике, способность надежно определять форму и положение объектов необходима для автономной навигации, манипулирования предметами и взаимодействия с окружающей средой. В сфере дополненной реальности, достоверное воссоздание трехмерной структуры позволяет создавать реалистичные и убедительные виртуальные объекты, интегрированные в реальное пространство. Наконец, для научного познания, будь то изучение биологических структур, анализ ландшафтов или исследование космоса, трехмерное восприятие является основой для построения моделей и интерпретации данных, раскрывая сложные закономерности и связи в природе.
Существующие методы трехмерного восприятия зачастую демонстрируют зависимость от огромных объемов обучающих данных, что ограничивает их применимость в реальных условиях. Обучение на конкретном наборе объектов или ракурсов не позволяет системам адекватно интерпретировать новые перспективы или распознавать ранее не встречавшиеся предметы. Это связано с тем, что алгоритмы часто выучивают специфические признаки, связанные с конкретным обучающим набором, вместо того, чтобы формировать обобщенное представление о трехмерной форме. В результате, при изменении угла обзора или появлении незнакомого объекта, точность распознавания резко падает, что препятствует созданию надежных и адаптивных систем компьютерного зрения, способных эффективно функционировать в динамичной среде.
Мульти-Вид: Новый Взгляд на Пространство
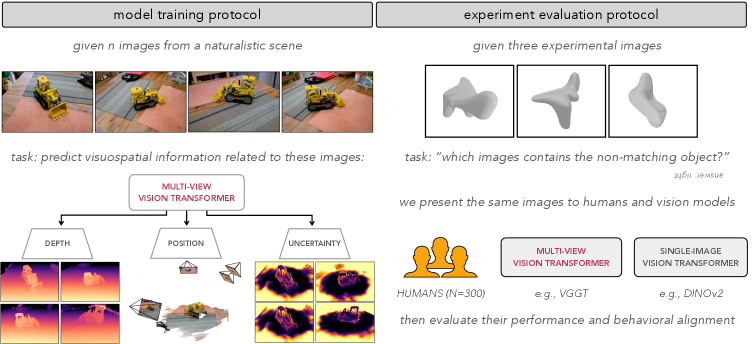
Многовидовые Визуальные Трансформеры (MVVT) представляют собой перспективное решение для задач, требующих понимания пространственных отношений, за счет одновременной обработки нескольких изображений объекта. В отличие от традиционных подходов, работающих с отдельными изображениями, MVVT используют набор изображений, снятых с разных точек обзора, для формирования более полного представления о трехмерной структуре объекта. Одновременная обработка позволяет модели напрямую устанавливать корреляции между признаками, наблюдаемыми на разных изображениях, что существенно повышает точность выявления и анализа пространственных связей. Такая архитектура особенно эффективна в задачах 3D-реконструкции, робототехнике и автономной навигации.
Многовидовые Трансформеры (MVVTs) развивают архитектуру Трансформеров, изначально успешную в задачах обработки естественного языка, для решения задач трехмерного восприятия. В отличие от традиционных подходов, MVVTs интегрируют принципы визуально-пространственного обучения, что позволяет модели эффективно обрабатывать информацию, поступающую из нескольких изображений одновременно. Это достигается за счет модификации механизма внимания, позволяющего учитывать не только признаки внутри каждого изображения, но и их пространственные взаимосвязи, что критически важно для точного понимания трехмерной структуры объектов. Внедрение этих принципов позволяет MVVTs превосходить существующие методы в задачах 3D-реконструкции и распознавания объектов.
Механизм кросс-внимания в Multi-View Vision Transformers (MVVTs) позволяет модели устанавливать взаимосвязи между признаками, полученными из изображений с разных точек зрения. Этот процесс предполагает вычисление весов внимания, определяющих вклад каждого пикселя из каждого изображения в формирование представления о 3D-форме объекта. По сути, модель динамически фокусируется на наиболее релевантных участках изображения, игнорируя шум и отвлекающие факторы. В результате, кросс-внимание значительно повышает точность и надежность вывода о 3D-структуре, поскольку учитывает информацию из нескольких источников и эффективно интегрирует ее для более полного понимания геометрии объекта.
MOCHI: Испытание для Машин и Людей
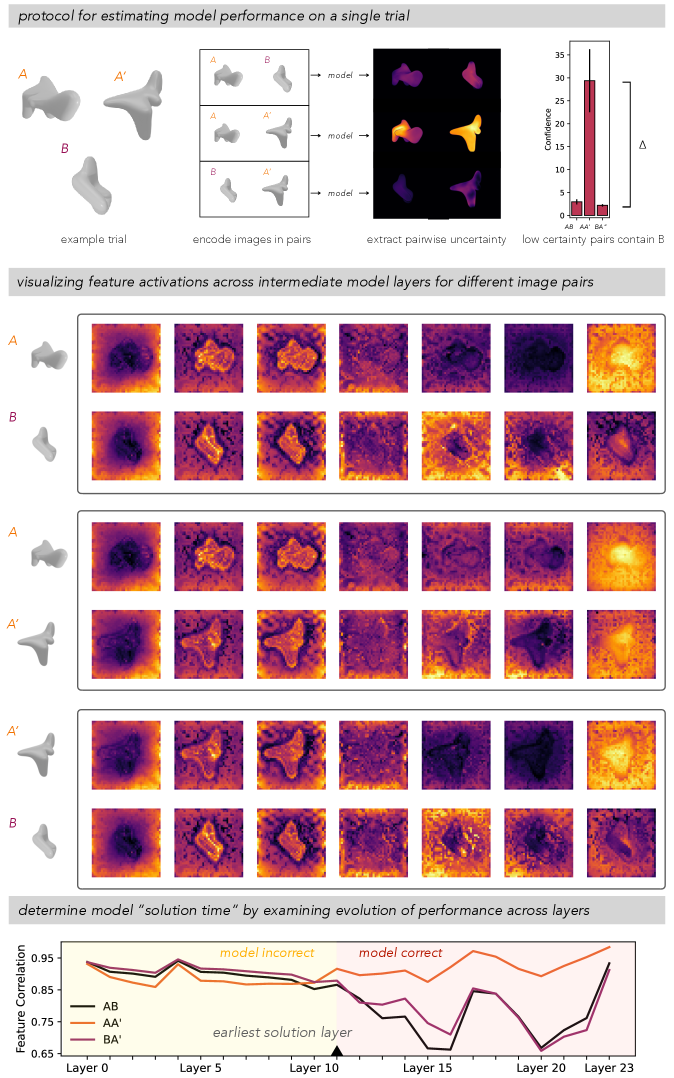
Бенчмарк MOCHI представляет собой стандартизированную платформу для оценки способностей к восприятию трехмерной формы как у моделей искусственного интеллекта, так и у людей. Эта платформа позволяет проводить сравнительный анализ, используя единый набор данных и метрик оценки, что обеспечивает объективное сопоставление производительности различных систем и алгоритмов. MOCHI включает в себя широкий спектр трехмерных объектов и сценариев, предназначенных для проверки различных аспектов восприятия формы, включая распознавание объектов, оценку их размеров и ориентации в пространстве. Стандартизация процесса оценки, предоставляемая MOCHI, существенно упрощает процесс валидации и сравнения различных подходов к трехмерному зрению.
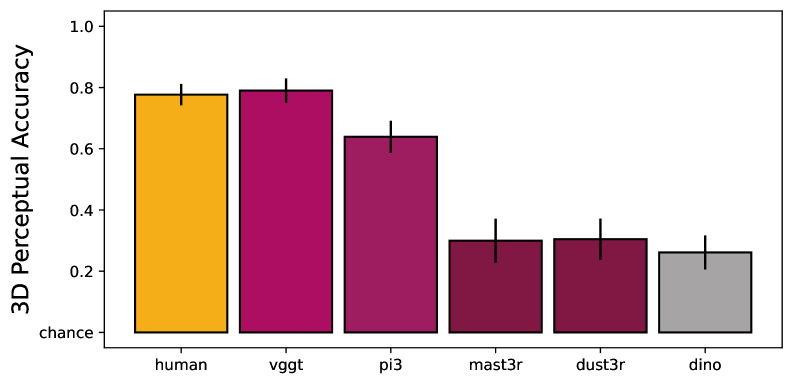
Модель VGGT, являющаяся передовой архитектурой MVVT (Multi-View Visual Transformer), продемонстрировала производительность, сопоставимую с человеческой, на бенчмарке MOCHI, предназначенном для оценки восприятия 3D-форм. Достигнутая моделью точность составила 83.0%, что соответствует результату, полученному в ходе тестирования людей — 78.9%. Данный показатель подтверждает высокую эффективность VGGT в задачах 3D-инференса и её способность к точному восстановлению формы объектов по многовидовым изображениям.
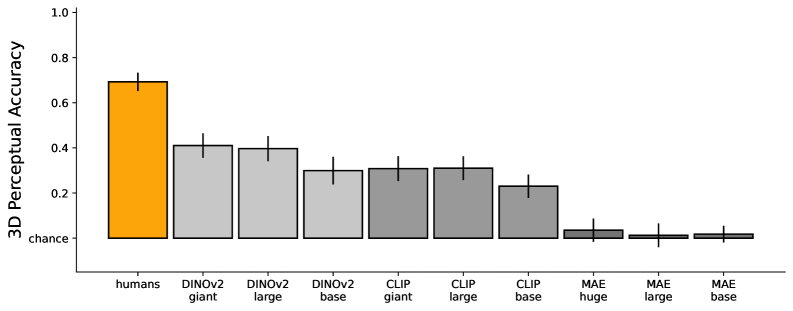
Результаты тестирования показали, что VGGT демонстрирует значительное превосходство над существующими методами, в частности, над DINOv2, в задачах 3D-восприятия. На специализированном бенчмарке для оценки 3D-восприятия, VGGT показал более высокие результаты, что указывает на улучшенные возможности модели в области 3D-инференса по сравнению с DINOv2 и другими ранее существующими решениями. Данное превосходство подтверждается количественными показателями, демонстрирующими более высокую точность и эффективность VGGT в задачах 3D-восприятия.
Уверенность в Зрении: Когда Машина «Понимает»
Оценка уверенности, с которой модель делает прогнозы, является фундаментальным аспектом при определении её надёжности и устойчивости к различным входным данным. Высокий уровень уверенности в правильном ответе указывает на то, что модель не просто угадала, а действительно выявила закономерность в данных. И наоборот, низкая уверенность может сигнализировать о неясности или неоднозначности входных данных, либо о том, что модель столкнулась с ситуацией, выходящей за рамки её обучения. Понимание этой уверенности позволяет не только оценивать вероятность ошибки, но и выявлять случаи, когда модель требует дополнительной проверки или вмешательства человека, что критически важно для применения в ответственных областях, таких как медицина или автономное управление.
Метод Confidence-Based Readout использует концепцию алеаторической неопределенности для получения информации о внутреннем процессе принятия решений в моделях искусственного интеллекта. Алеаторическая неопределенность, в отличие от эпистемической, связана с присущей случайностью данных и шумом, что позволяет модели оценивать степень своей уверенности в предсказании, даже если данные неполны или зашумлены. Этот подход позволяет не просто получить ответ, но и понять, насколько модель уверена в его правильности, что критически важно для оценки надежности и применимости модели в реальных условиях. Анализ этой неопределенности предоставляет ценные сведения о том, как модель интерпретирует входные данные и формирует свои решения, открывая возможности для улучшения ее работы и повышения доверия к ее результатам.
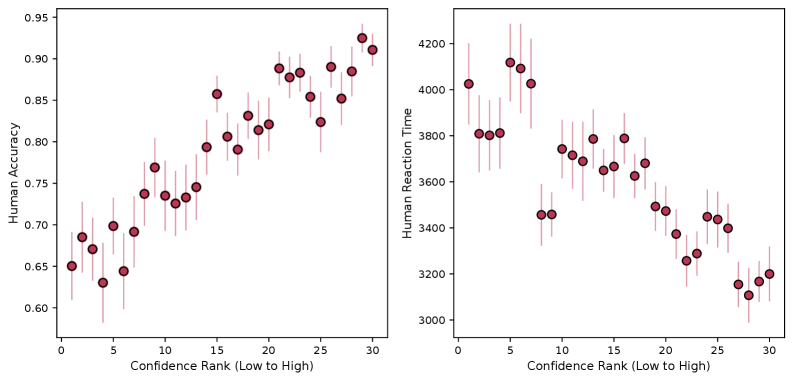
Исследования показали удивительное сходство в способах обработки пространственной информации человеком и продвинутыми моделями искусственного интеллекта. Сравнивая время реакции испытуемых при определении трехмерной формы объектов и время, необходимое модели для решения аналогичной задачи, ученые обнаружили высокую корреляцию, достигшую значения 0.796. Более того, уровень уверенности модели в правильности своего ответа тесно связан с точностью, которую демонстрируют люди, о чем свидетельствует коэффициент корреляции Пирсона, равный 0.830. Эти данные позволяют предположить, что модели, способные оценивать свою уверенность, не просто выдают ответы, но и демонстрируют аналогичные когнитивные процессы, что открывает новые возможности для понимания механизмов человеческого восприятия и создания более “человекоподобного” искусственного интеллекта.
Будущее Трехмерного Зрения: К Воплощенному Пониманию
Интеграция проприоцепции — чувства положения тела в пространстве — представляется ключевым шагом к улучшению способности модели понимать пространственные взаимосвязи и взаимодействовать с окружающим миром. В отличие от систем, полагающихся исключительно на визуальные данные, включение информации о положении и движении собственных «конечностей» модели позволит ей более точно оценивать расстояния, глубину и ориентацию объектов. Подобный подход, имитирующий восприятие тела у живых существ, способствует формированию более надежного и интуитивно понятного представления о трехмерном пространстве, что особенно важно для решения задач манипулирования объектами, навигации и взаимодействия с динамической средой. В результате, система получит возможность не только «видеть» мир, но и «чувствовать» свое место в нем, что приведет к более эффективным и реалистичным взаимодействиям.
Для успешного применения в реальных условиях, модели трехмерного понимания должны быть способны эффективно обрабатывать динамические сцены и неполные данные. Исследования показывают, что большинство реальных окружений постоянно меняются, а сенсорные данные часто бывают зашумлены или частично отсутствуют из-за окклюзий и ограничений датчиков. Поэтому, разработка алгоритмов, позволяющих модели реконструировать недостающую информацию и адаптироваться к изменяющейся обстановке, является ключевой задачей. Способность к прогнозированию изменений и экстраполяции данных позволит системе не только воспринимать текущую реальность, но и предвидеть будущие события, обеспечивая более надежное и эффективное взаимодействие с окружающим миром. Такая адаптивность необходима для широкого спектра приложений, включая робототехнику, автономное вождение и дополненную реальность.
Данная работа открывает перспективы для создания более устойчивых и интеллектуальных систем, способных воспринимать, понимать и взаимодействовать с трехмерным миром подобно человеку. Развитие представленного подхода позволит создать устройства и программное обеспечение, способные не просто анализировать визуальные данные, но и активно действовать в пространстве, адаптируясь к менящимся условиям и неполной информации. Это открывает возможности для широкого спектра применений, включая робототехнику, дополненную и виртуальную реальность, а также системы автономной навигации, которые смогут функционировать в сложных и непредсказуемых средах, приближая нас к созданию действительно “умных” машин, способных к полноценному взаимодействию с окружающим миром.
Исследование демонстрирует, что многовидовое обучение может достигать человеческого уровня восприятия 3D-форм без специализированной подготовки. Это закономерно. Всегда находился способ обойти необходимость в сложных, специально разработанных решениях. Как отмечал Джеффри Хинтон: «Я думаю, что я совершил большую ошибку в своей карьере, потратив слишком много времени на попытки улучшить алгоритмы обучения, а не на сбор больших объемов данных». Данная работа подтверждает эту мысль: не архитектура нейронной сети, а объем и естественность данных определяют результат. В конечном итоге, любое «прорывное» решение окажется лишь очередным способом обойти ограничения, наложенные реальным миром. И прод всегда найдет способ сломать эту «элегантную» конструкцию.
Что Дальше?
Представленная работа демонстрирует, что модель, обученная на естественных изображениях с разных точек зрения, способна достигать человеческого уровня в восприятии трёхмерных форм без какой-либо специализированной настройки. Однако, стоит помнить: каждая «революция» в области машинного зрения неизбежно порождает новый уровень технического долга. Продуктив всегда найдёт способ сломать элегантную теорию, подсунув неожиданную комбинацию освещения, текстур или, что вероятнее, просто некачественные данные.
Иллюзия «общего» интеллекта, возникающая при таких результатах, опасна. Успешное выполнение на синтетических или тщательно отобранных наборах данных — лишь первый шаг. Настоящая проверка ждёт в условиях реального мира, где данные шумные, неполные и противоречивые. Документация, как обычно, останется мифом, созданным менеджерами, и любой, кто попытается внедрить подобную систему, быстро поймёт, что «zero-shot learning» — это красивый термин для «мы понятия не имеем, как это будет работать в продакшене».
В конечном итоге, вопрос не в достижении человеческого уровня восприятия, а в создании систем, которые будут устойчивы к неизбежному хаосу реального мира. CI — это храм, в котором мы молимся, чтобы ничего не сломалось, и, судя по всему, эта молитва будет длиться вечно. Следующим шагом, вероятно, станет поиск способов добавить в эти модели немного «здравого смысла» — или, по крайней мере, возможность выдавать предсказуемые ошибки.
Оригинал статьи: https://arxiv.org/pdf/2602.17650.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Обзор Motorola Razr 50 Ultra
- Фотографируем муравьёв с Андреем Павловым
- Warhammer 40,000: Space Marine 2 — Список всех врагов и боссов на данный момент
- Преодолевая границы масштабируемости рекомендательных систем
- Nikon D7200
- Лучшие ноутбуки с матовым экраном. Что купить в мае 2026.
- vivo iQOO Z7 ОБЗОР: тонкий корпус, скоростная зарядка, чёткое изображение
- vivo S50 Pro mini ОБЗОР: чёткое изображение, беспроводная зарядка, скоростная зарядка
- Обзор Moto G Stylus 5G (2024)
- vivo iQOO Z11x ОБЗОР: яркий экран, плавный интерфейс, удобный сенсор отпечатков
2026-02-20 08:11