Автор: Денис Аветисян
Исследователи разработали интерактивную систему, способную уточнять поиск объектов в реальном времени, основываясь на намерениях пользователя.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"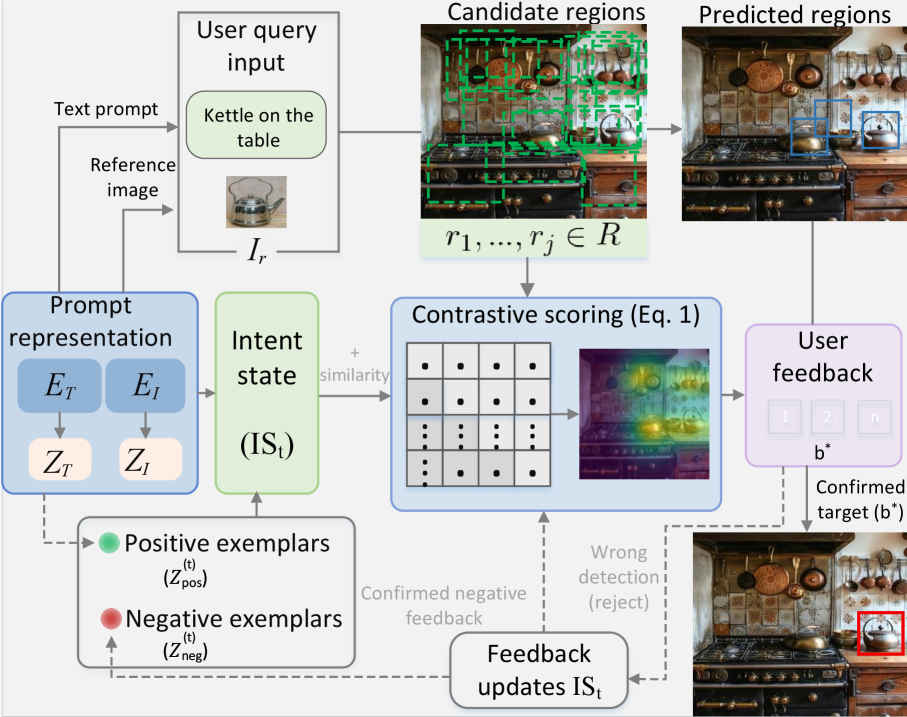
Предложен фреймворк IntRec, использующий контрастное выравнивание и учёт состояния намерений для разрешения неоднозначности при визуальном определении объектов.
Поиск конкретных объектов в сложных сценах остается сложной задачей, особенно при неоднозначных запросах или наличии множества схожих объектов. В данной работе представлена система IntRec: Intent-based Retrieval with Contrastive Refinement, использующая интерактивный подход к поиску объектов, основанный на поддержании «состояния намерения» и контрастном выравнивании. Предложенный фреймворк значительно повышает точность поиска за счет учета обратной связи от пользователя, позволяя уточнять результаты в режиме реального времени. Не станет ли интерактивное уточнение намерения ключевым фактором в решении задач визуального поиска в реальных условиях?
Трудности распознавания: когда теория разбивается о практику
Традиционные методы обнаружения объектов сталкиваются с серьезными трудностями при обработке нечётких запросов и выявлении редких категорий, что значительно ограничивает их применение в реальных условиях. Существующие алгоритмы, как правило, обучаются на заранее определенных наборах объектов и испытывают затруднения при встрече с незнакомыми или малочисленными экземплярами. Например, система, обученная распознавать автомобили и пешеходов, может оказаться неспособной идентифицировать старинный велосипед или редкий вид птицы. Неоднозначность в запросах, такая как «найди красное», без указания конкретного объекта, также представляет проблему, поскольку алгоритм не может точно определить, что именно требуется пользователю. В результате, несмотря на значительные успехи в области компьютерного зрения, существующие системы часто оказываются неэффективными в сложных и динамичных реальных сценариях, требующих гибкости и адаптивности.
Ограничения традиционных систем обнаружения объектов проистекают из их зависимости от заранее определенных, фиксированных наборов категорий. Такой подход затрудняет адаптацию к тонкостям пользовательского запроса и не позволяет эффективно распознавать объекты, не включенные в изначальный список. Вместо гибкого понимания намерений пользователя, система ограничена рамками заданного словаря, что приводит к ошибкам при неоднозначных или неполных описаниях. Неспособность учитывать контекст и нюансы запроса существенно снижает эффективность обнаружения объектов в реальных условиях, где часто встречаются нетипичные или редко встречающиеся предметы.
Современные системы обнаружения объектов часто демонстрируют неустойчивую работу при столкновении с незнакомыми предметами или нечеткими запросами. Это обусловлено тем, что большинство алгоритмов полагаются на обширные, но конечные наборы данных для обучения, и испытывают трудности с обобщением на объекты, которые плохо представлены в этих данных. Неоднозначные или неполные запросы, например, фразы вроде «что-то красное» без уточнения конкретного объекта, также приводят к ошибочным результатам. В таких ситуациях системы склонны либо выдавать ложные срабатывания, идентифицируя нерелевантные объекты, либо просто игнорировать запрос, не находя соответствий в своей базе знаний. Подобные ограничения существенно снижают практическую ценность алгоритмов обнаружения объектов в реальных сценариях, где разнообразие и непредсказуемость окружающего мира предъявляют высокие требования к адаптивности и гибкости.
Для преодоления ограничений существующих систем обнаружения объектов, требуется принципиально новый подход, основанный на активном обучении посредством взаимодействия с пользователем. Вместо статических наборов категорий, система должна динамически уточнять свое понимание желаемого объекта, анализируя обратную связь и корректируя свои алгоритмы в реальном времени. Этот процесс включает не только идентификацию объекта, но и уточнение его характеристик, учитывая контекст запроса и нюансы пользовательского намерения. Такая адаптивная система способна эффективно работать с неоднозначными запросами и редкими категориями, значительно расширяя область применения обнаружения объектов в реальных сценариях, где спецификация желаемого результата зачастую неполна или расплывчата.

Интерактивный поиск: взаимодействие с пользователем как ключ к успеху
Интерактивный поиск (Interactive Retrieval) представляет собой структурированный фреймворк, объединяющий возможности обнаружения объектов открытой номенклатуры с итеративным получением обратной связи от пользователя. В отличие от статических моделей, данный подход предполагает динамическое взаимодействие с пользователем на протяжении всего процесса обнаружения. Фреймворк позволяет пользователю уточнять и корректировать результаты обнаружения, предоставляя позитивные и негативные примеры, что способствует повышению точности и релевантности обнаруженных объектов. Ключевой особенностью является поддержка состояния (statefulness), позволяющая системе запоминать предыдущие взаимодействия и использовать их для улучшения последующих итераций поиска.
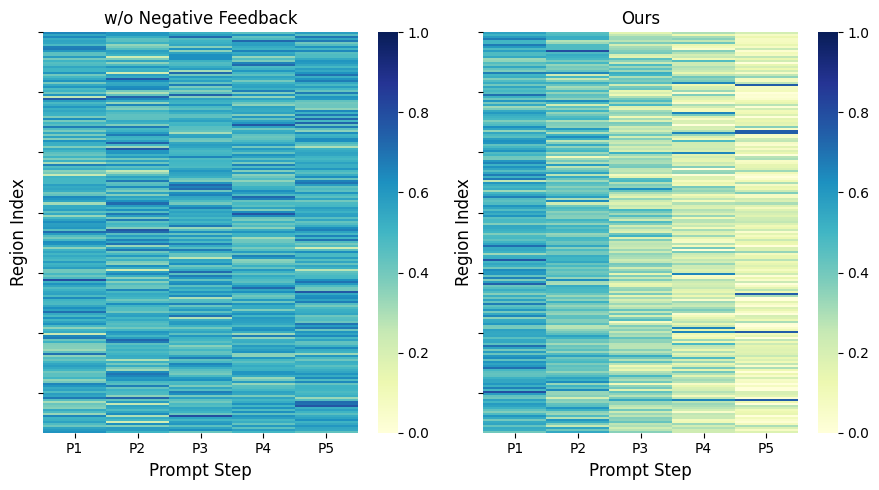
Система поддерживает состояние «Намерение» (Intent State) — динамическую память, которая аккумулирует положительные привязки (positive anchors) и отрицательные ограничения (negative constraints), полученные в результате взаимодействия с пользователем. Положительные привязки фиксируют объекты или области, которые пользователь явно подтверждает как релевантные, в то время как отрицательные ограничения обозначают области, которые пользователь исключает из поиска. Эта информация хранится и последовательно обновляется при каждом новом взаимодействии, формируя контекст для последующих этапов обнаружения и позволяя системе уточнять результаты в соответствии с изменяющимися потребностями пользователя. Фактически, состояние «Намерение» служит оперативной памятью, обеспечивающей адаптивность системы и позволяющей ей отходить от фиксированных шаблонов обнаружения.
Состояние интента, являясь динамической памятью системы, оказывает непосредственное влияние на процесс обнаружения объектов. Накопленные положительные якоря и отрицательные ограничения, полученные в результате взаимодействия с пользователем, формируют критерии фильтрации и приоритезации результатов. Это позволяет системе адаптироваться к сложным и неоднозначным запросам, уточняя область поиска и повышая точность обнаружения объектов, соответствующих текущему намерению пользователя. Изменение состояния интента происходит итеративно, с каждым циклом обратной связи, что обеспечивает непрерывное обучение и улучшение производительности системы в контексте конкретной задачи.
В отличие от статических моделей обнаружения объектов, работающих с фиксированным набором данных и предопределенными критериями, Interactive Retrieval активно использует обратную связь от пользователя для улучшения результатов. Это достигается путем непрерывного сбора и интеграции пользовательских указаний — как положительных подтверждений обнаруженных объектов (анкоров), так и отрицательных ограничений, исключающих нерелевантные результаты. Такой итеративный процесс позволяет системе динамически адаптироваться к конкретному запросу пользователя, преодолевая ограничения статических моделей, которые не способны учитывать нюансы и контекст, не определенные на этапе обучения. По сути, система непрерывно уточняет свою модель обнаружения на основе интерактивного взаимодействия, что повышает точность и релевантность результатов.
Контрастное ранжирование: выявление намерений пользователя
В основе интерактивного поиска лежит функция контрастного ранжирования, оценивающая потенциальные области на изображении на основе их сходства с положительными якорями и различия с отрицательными ограничениями. Положительные якоря представляют собой области, которые пользователь явно подтвердил как релевантные, в то время как отрицательные ограничения обозначают нежелательные области. Функция ранжирования вычисляет степень соответствия каждой потенциальной области этим якорям и ограничениям, используя метрики сходства и различия, такие как косинусное расстояние или евклидово расстояние. Более высокие оценки соответствия положительным якорям и более низкие оценки соответствия отрицательным ограничениям указывают на более высокую релевантность потенциальной области и, следовательно, на более высокое место в ранжированном списке.
Функция контрастного обучения используется для разграничения желаемых и нежелаемых объектов в процессе интерактивного поиска. Этот процесс опирается на постоянно обновляемое состояние интента пользователя (Intent State), которое служит ориентиром для определения релевантности объектов. Контрастное обучение позволяет модели научиться различать позитивные (желаемые) и негативные (нежелаемые) примеры, оптимизируя функцию ранжирования для более точного соответствия потребностям пользователя. По мере развития интента, модель адаптирует критерии разграничения, повышая эффективность поиска и снижая количество ложных срабатываний.
Для повышения точности ранжирования предложений в интерактивном поиске используется метод оптимального транспорта (Optimal Transport, OT). OT позволяет проводить более детальное и эффективное сравнение признаков, чем традиционные метрики расстояния. Вместо простого вычисления расстояния между векторами признаков, OT рассматривает распределения признаков как «массу», которую необходимо оптимально «переместить» от негативных ограничений к положительным якорям. Это позволяет учитывать не только величину различий, но и структуру этих различий, обеспечивая более точное соответствие между результатами поиска и намерениями пользователя. Использование OT способствует максимизации согласованности между предложенными областями и ожиданиями пользователя, повышая точность обнаружения и снижая неоднозначность.
В результате применения описанного подхода к ранжированию, система интеллектуально расставляет приоритеты среди предлагаемых регионов, что приводит к снижению неоднозначности в процессе обнаружения объектов. Оптимизация ранжирования, основанная на контрастном обучении и оптимальном транспорте, позволяет более эффективно отличать желаемые объекты от нежелательных, что напрямую влияет на повышение точности и релевантности результатов.
Эффект на практике: обнаружение редких объектов и масштабируемость
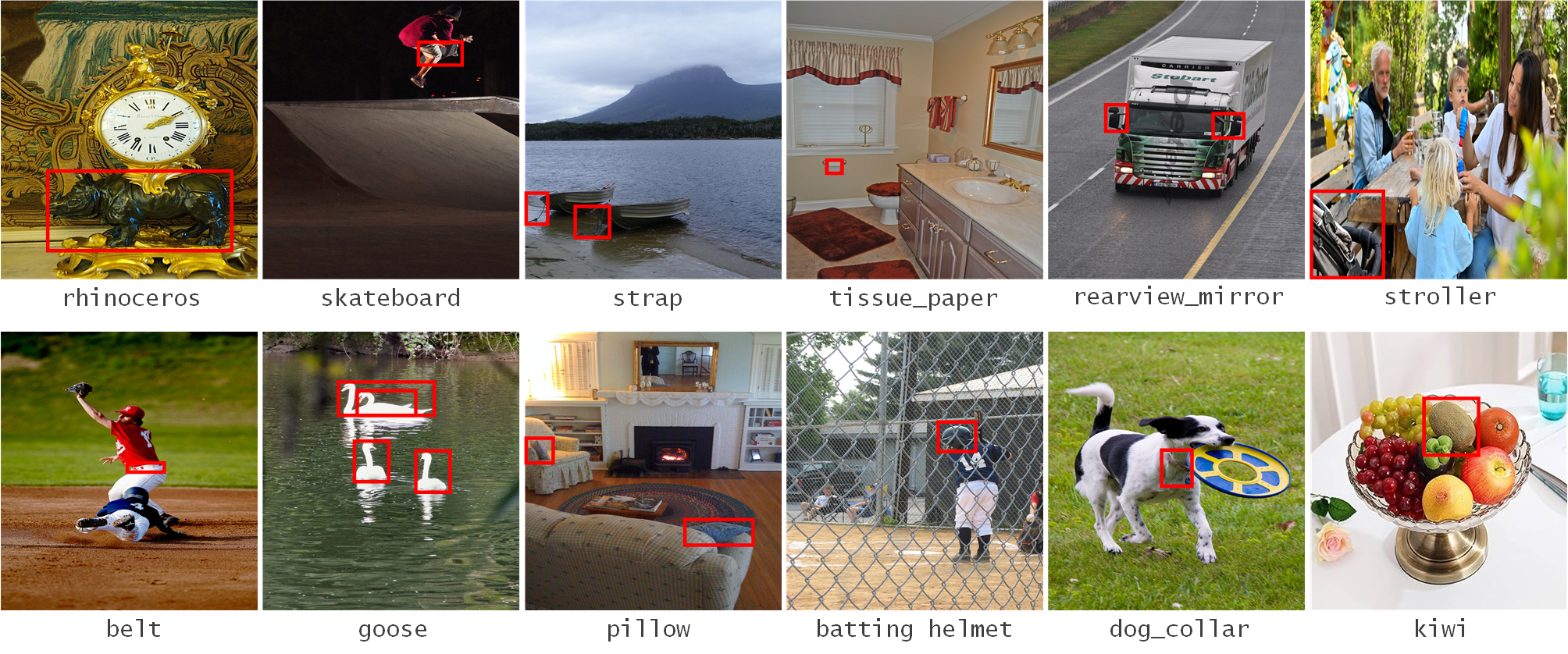
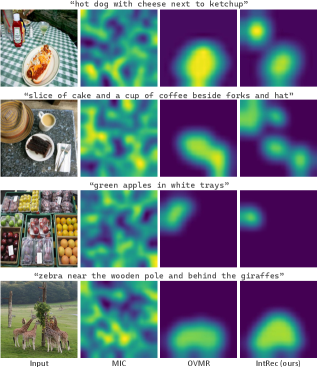
Оценки, проведенные на датасетах LVIS и Objects365, продемонстрировали заметные улучшения в обнаружении редких категорий объектов и разрешении неоднозначных запросов. Система эффективно справляется с задачами, где стандартные алгоритмы испытывают трудности из-за недостаточного количества обучающих примеров или нечетких формулировок запросов. В частности, наблюдается значительное повышение точности обнаружения объектов, относящихся к малочисленным классам, что особенно важно для приложений, требующих детального анализа сложных сцен. Способность системы эффективно обрабатывать неоднозначные запросы указывает на ее продвинутые возможности в понимании контекста и интерпретации намерений пользователя, что открывает перспективы для создания более интуитивно понятных и удобных систем компьютерного зрения.
Система продемонстрировала передовые результаты на бенчмарке LVIS, достигнув показателя средней точности AP в 35.6. Этот результат подтверждает высокую эффективность разработанного подхода в задачах обнаружения объектов, особенно в сложных сценариях, характерных для данного набора данных. Достижение такого уровня точности указывает на способность системы надежно идентифицировать и локализовать объекты даже в условиях ограниченного количества обучающих примеров и высокой степени визуального разнообразия, что делает ее перспективной для широкого спектра практических приложений, требующих точного и надежного анализа изображений.
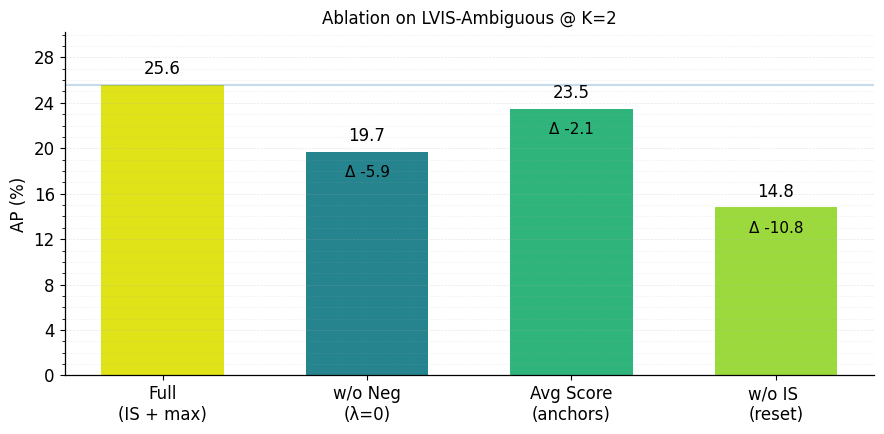
Исследования на бенчмарке LVIS-Ambiguous продемонстрировали значительное повышение точности системы при обработке неоднозначных запросов. В частности, после всего одного раунда обратной связи от пользователя, средняя точность (AP) системы увеличилась на 7.9 процентных пункта. Это свидетельствует о высокой способности системы к адаптации и коррекции ошибок на основе минимального количества данных от человека, что делает её особенно эффективной в сценариях, где требуется быстрое и точное распознавание объектов даже при нечётких или двусмысленных запросах. Данный результат подчеркивает перспективность использования интерактивной обратной связи для улучшения производительности систем компьютерного зрения.
Модель продемонстрировала выдающиеся результаты в обнаружении редких категорий объектов, достигнув показателя Average Precision (AP) в 25.0 / 26.0. Этот результат превосходит предыдущие самые современные методы, такие как CAKE (25.0) и CoDet (24.5), что указывает на значительный прогресс в обработке задач компьютерного зрения, связанных с обнаружением малопредставленных классов. Достижение более высокой точности при работе с редкими категориями особенно важно для приложений, где необходимо выявлять объекты, встречающиеся нечасто, например, в областях мониторинга окружающей среды или анализа медицинских изображений, где обнаружение редких аномалий имеет решающее значение.
Взгляд в будущее: адаптация, коллаборация и интеллектуальные системы
В дальнейшем исследовании планируется уделить особое внимание расширению возможностей получения обратной связи от пользователя, переходя от простых сигналов к более сложным формам, таким как описания объектов на естественном языке и визуальные корректировки. Такой подход позволит системе не просто фиксировать наличие или отсутствие объекта, но и понимать его характеристики, указанные пользователем, например, цвет, размер или состояние. Визуальные корректировки, в свою очередь, предоставят возможность точной настройки обнаружения, позволяя пользователю быстро и интуитивно исправить неточности. Внедрение подобных механизмов обратной связи значительно повысит адаптивность системы и позволит ей эффективно взаимодействовать с пользователем в различных сценариях, обеспечивая более точное и релевантное обнаружение объектов.
Представляется система, способная активно запрашивать обратную связь, предвосхищая потребности пользователя и уточняя понимание желаемого объекта. Вместо пассивного ожидания указаний, система будет анализировать контекст задачи и самостоятельно определять, какая информация необходима для повышения точности обнаружения. Например, при поиске автомобилей определенного цвета, система может спросить о предпочтительном оттенке или модели, если первоначальный результат не соответствует ожиданиям. Такой проактивный подход позволяет не только улучшить результаты обнаружения объектов, но и значительно сократить время, необходимое для достижения желаемого результата, делая взаимодействие более интуитивным и эффективным.
Исследование возможностей графовых представлений открывает новые перспективы для повышения аналитических способностей систем обнаружения объектов. Вместо анализа каждого объекта изолированно, предлагается моделировать взаимосвязи между ними посредством графов, где узлы представляют объекты, а ребра — их отношения. Такой подход позволяет системе не просто идентифицировать объекты, но и понимать контекст их взаимодействия, например, различать «человек, держащий чашку» и «человек, сидящий за столом с чашкой». Использование графов позволяет учитывать сложные пространственные и семантические связи, что особенно важно в перегруженных сценах, и значительно улучшает точность и надежность обнаружения, а также способствует более глубокому пониманию изображений и видео.
В перспективе разрабатываемая система обнаружения объектов стремится к бесшовной интеграции в существующие рабочие процессы человека. Речь идет о создании интеллектуального помощника, способного не просто находить интересующие объекты на изображениях или видео, но и адаптироваться к индивидуальным потребностям пользователя в режиме реального времени. Система будет активно учиться на взаимодействии с человеком, запоминая предпочтения и корректируя свои алгоритмы для повышения точности и релевантности результатов. Это позволит существенно сократить время, затрачиваемое на ручную обработку данных, и повысить эффективность работы в различных областях, от автоматизированного анализа изображений в медицине до контроля качества на производстве. В конечном итоге, система должна стать незаменимым инструментом, расширяющим возможности человека и позволяющим ему сосредоточиться на более сложных и творческих задачах.
В работе, посвященной интерактивному поиску объектов, авторы предлагают подход, который, как и многие другие «революционные» решения, в конечном итоге сводится к управлению техническим долгом. Система, использующая состояние намерения и контрастное выравнивание для разрешения неоднозначности, лишь откладывает неизбежное: необходимость ручной корректировки и уточнения результатов. Как отмечал Джеффри Хинтон: «Я считаю, что, вероятно, через пять лет глубокое обучение будет совершенно другим». Эта фраза, как нельзя лучше отражает суть происходящего: даже самые сложные алгоритмы рано или поздно нуждаются в доработке, особенно когда дело касается реальных, неидеальных данных и неоднозначных запросов пользователей. Иллюзия автоматизации, кажется, всегда разбивается о суровую реальность продакшена.
Что Дальше?
Представленный подход к интерактивному поиску объектов, несомненно, элегантен в своей концепции. Однако, как показывает опыт, любое усложнение системы рано или поздно найдёт способ обернуться новым вектором сбоев. Контрастивное выравнивание, призванное разрешить неоднозначность, неизбежно столкнётся с ситуациями, когда сама неоднозначность является фундаментальной характеристикой реального мира. Заманчиво полагать, что пользовательская обратная связь — это панацея, но история знает множество примеров, когда даже самая точная спецификация не спасает от неожиданных краевых случаев.
В перспективе, вероятно, стоит переосмыслить саму концепцию «интента». Разве возможно полностью формализовать человеческое намерение? Или же любая попытка сведётся к созданию ещё одной абстракции, обречённой на столкновение с непредсказуемостью реального мира? Будущие исследования, вероятно, сосредоточатся на разработке более робастных механизмов обработки ошибок и адаптации к неполной или противоречивой информации. Ведь всё, что можно задеплоить — однажды упадёт, вопрос лишь в том, как изящно это произойдёт.
И, конечно, нельзя забывать о масштабируемости. Решение, работающее в лабораторных условиях, часто оказывается непрактичным при обработке больших объёмов данных и взаимодействии с тысячами пользователей. Каждая «революционная» технология завтра станет техдолгом. Продакшен всегда найдёт способ сломать элегантную теорию.
Оригинал статьи: https://arxiv.org/pdf/2602.17639.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Как сделать фотографию резкой.
- Российский рынок: от инфляции к инвестициям: что ждет инвесторов? (11.06.2026 02:32)
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Обзор Motorola Edge 50 Fusion
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Прогнозы цен на CC: анализ криптовалюты CC
- 10 лучших OLED ноутбуков. Что купить в июне 2026.
- Что купить фотографу. Рекомендации
- Синхронизация вспышки. Что такое Sync speed и режим FP.
2026-02-21 01:01