Автор: Денис Аветисян
Новая архитектура ULTRA-HSTU демонстрирует значительный прогресс в обработке длинных последовательностей пользовательских данных, открывая путь к более эффективным рекомендациям.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Предлагается модель, основанная на архитектуре Transformer, оптимизированная как на уровне модели, так и на уровне системы, для повышения масштабируемости и эффективности рекомендательных систем.
По мере увеличения объемов данных о взаимодействии пользователей, традиционные подходы к моделированию последовательностей в рекомендательных системах сталкиваются с ограничениями масштабируемости. В работе ‘Bending the Scaling Law Curve in Large-Scale Recommendation Systems’ представлена модель ULTRA-HSTU, разработанная на основе совместного проектирования модели и системы, позволяющая значительно повысить эффективность обработки ультрадлинных последовательностей пользовательских взаимодействий. Инновационный подход к структурированию входных данных, использование разреженных механизмов внимания и оптимизация топологии модели обеспечивают более чем пятикратное ускорение обучения и 21-кратное ускорение инференса по сравнению с традиционными моделями. Возможно ли дальнейшее улучшение масштабируемости и качества рекомендаций за счет более глубокой интеграции аппаратного и программного обеспечения?
Проблема длинных последовательностей в рекомендательных системах
Традиционные модели глубокого обучения, применяемые в системах рекомендаций, часто сталкиваются с трудностями при обработке длительных историй взаимодействия пользователей. Это связано с тем, что стандартные архитектуры, такие как рекуррентные нейронные сети (RNN) или сверточные нейронные сети (CNN), испытывают экспоненциальный рост вычислительной сложности и проблемы с затуханием градиента при увеличении длины последовательности. В результате, модели не могут эффективно улавливать долгосрочные зависимости и нюансы поведения пользователей, что приводит к снижению точности и релевантности рекомендаций. Пользовательские предпочтения и интересы могут меняться со временем, и игнорирование этой динамики из-за ограниченной способности к обработке длинных последовательностей негативно сказывается на персонализации и общей удовлетворенности от использования системы рекомендаций.
Вычислительные затраты, связанные с обработкой длинных последовательностей пользовательских взаимодействий, существенно ограничивают возможности современных рекомендательных систем. По мере увеличения длины истории пользователя, сложность алгоритмов возрастает экспоненциально, требуя значительных ресурсов памяти и процессорного времени. Это препятствует полному учету тонких поведенческих паттернов и контекстуальных нюансов, которые могли бы значительно повысить точность рекомендаций. В результате, системы часто вынуждены обрезать или упрощать историю пользователя, теряя важную информацию о его предпочтениях и интересах, что снижает эффективность персонализации и приводит к менее релевантным предложениям.
Эффективное моделирование длинных последовательностей играет ключевую роль в раскрытии более глубоких закономерностей поведения пользователей и, как следствие, повышении точности рекомендаций. Традиционные методы часто не способны эффективно обрабатывать обширные истории взаимодействия, упуская важные контекстуальные детали и сложные предпочтения. Развитие алгоритмов, способных учитывать всю длительность пользовательского пути, позволяет выявлять неочевидные связи между действиями и формировать более персонализированные предложения. Это особенно важно в динамичных средах, где предпочтения пользователя могут меняться со временем, и учет всей истории позволяет адаптироваться к этим изменениям, предоставляя более релевантные и своевременные рекомендации, что значительно повышает вовлеченность и удовлетворенность пользователей.
HSTU: Трансформерная модель для последовательных рекомендаций
Модель HSTU использует архитектуру Transformer, хорошо зарекомендовавшую себя в задачах обработки последовательностей, и расширяет её функциональность для решения задач последовательной рекомендации. В основе HSTU лежит механизм самовнимания (self-attention), позволяющий модели учитывать взаимосвязи между различными элементами последовательности взаимодействий пользователя. В отличие от традиционных методов, которые рассматривают взаимодействия изолированно, HSTU анализирует всю историю действий пользователя, что позволяет более точно прогнозировать будущие предпочтения и формировать релевантные рекомендации. Модель использует многослойные энкодеры и декодеры Transformer для эффективного извлечения признаков из последовательностей и генерации персонализированных рекомендаций.
Модель HSTU, ориентируясь на последовательное моделирование, учитывает временные зависимости в поведении пользователей, что позволяет повысить точность прогнозирования. В отличие от методов, рассматривающих взаимодействия пользователей как независимые события, HSTU анализирует порядок этих взаимодействий, выявляя закономерности и тенденции, обусловленные временем. Это особенно важно для рекомендательных систем, где недавние действия пользователя оказывают большее влияние на его текущие предпочтения. Анализ последовательностей позволяет модели учитывать, например, что пользователь, просмотревший несколько товаров определенной категории подряд, вероятно, заинтересован в дальнейших предложениях из этой же категории. Такой подход позволяет более эффективно прогнозировать будущие действия пользователя и предоставлять более релевантные рекомендации.
Модель HSTU анализирует последовательность взаимодействий пользователя, учитывая порядок этих действий для формирования более точного представления о его предпочтениях. В отличие от методов, рассматривающих взаимодействия как неупорядоченный набор, HSTU извлекает информацию из временной зависимости между событиями, такими как просмотры товаров или совершение покупок. Это позволяет модели выявлять паттерны в поведении пользователя, например, последовательное изучение определенных категорий товаров или предпочтение определенных брендов после ознакомления с другими. Использование информации о порядке взаимодействий способствует более детальному пониманию динамики предпочтений и повышает точность прогнозирования будущих действий пользователя.
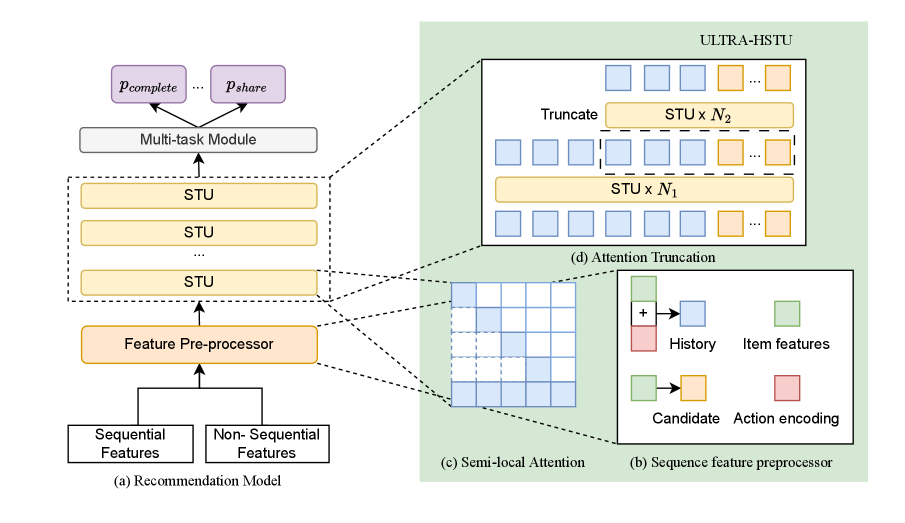
ULTRA-HSTU: Масштабирование для сверхдлинных последовательностей
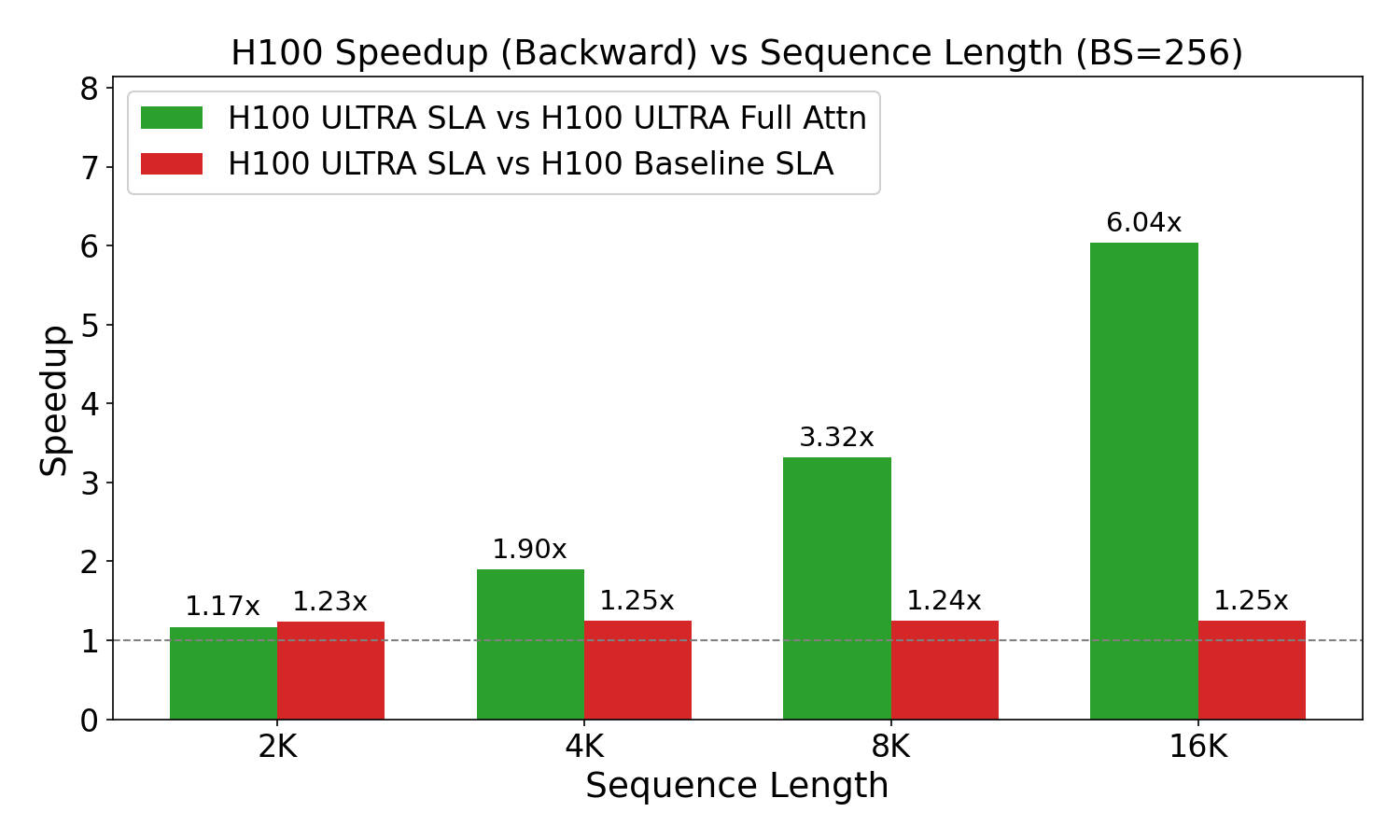
ULTRA-HSTU является значительной эволюцией архитектуры HSTU, разработанной специально для эффективной обработки чрезвычайно длинных последовательностей данных. В отличие от базовой версии HSTU, ULTRA-HSTU использует ряд оптимизаций, направленных на снижение вычислительной сложности и потребления памяти при работе с увеличенными объемами данных. Это достигается за счет применения таких методов, как Semi-Local Attention, усечение внимания (Attention Truncation) и балансировка вероятности длины (Load-Balanced Stochastic Length), позволяющих обрабатывать последовательности, значительно превышающие возможности стандартного HSTU без существенного снижения производительности.
Эффективная обработка ультра-длинных последовательностей в ULTRA-HSTU достигается за счет ряда ключевых оптимизаций механизма внимания. В частности, используется Semi-Local Attention, ограничивающий область вычислений внимания, что снижает вычислительную сложность. Дополнительно применяются методы Attention Truncation, обрезающие длину последовательности для уменьшения потребления памяти, и Load-Balanced Stochastic Length, динамически регулирующий длину последовательности для обеспечения баланса нагрузки между вычислительными узлами. Эти методы в совокупности позволяют снизить вычислительные затраты и повысить пропускную способность при работе с очень длинными последовательностями данных.
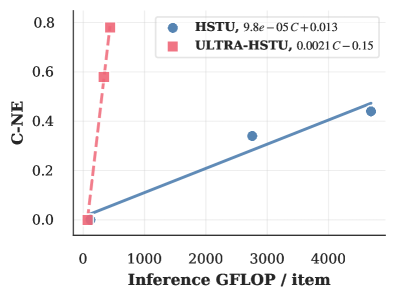
Внедрение FlashAttention V3 в ULTRA-HSTU позволило существенно ускорить вычисления и снизить потребление памяти. Согласно результатам тестирования, данная оптимизация привела к 5.3-кратному увеличению эффективности масштабирования при обучении и 21.4-кратному увеличению эффективности масштабирования при инференсе по сравнению со стандартным HSTU. Данный прирост производительности обусловлен оптимизациями в FlashAttention V3, направленными на эффективное использование памяти и параллелизации вычислений, что критически важно при работе с последовательностями большой длины.
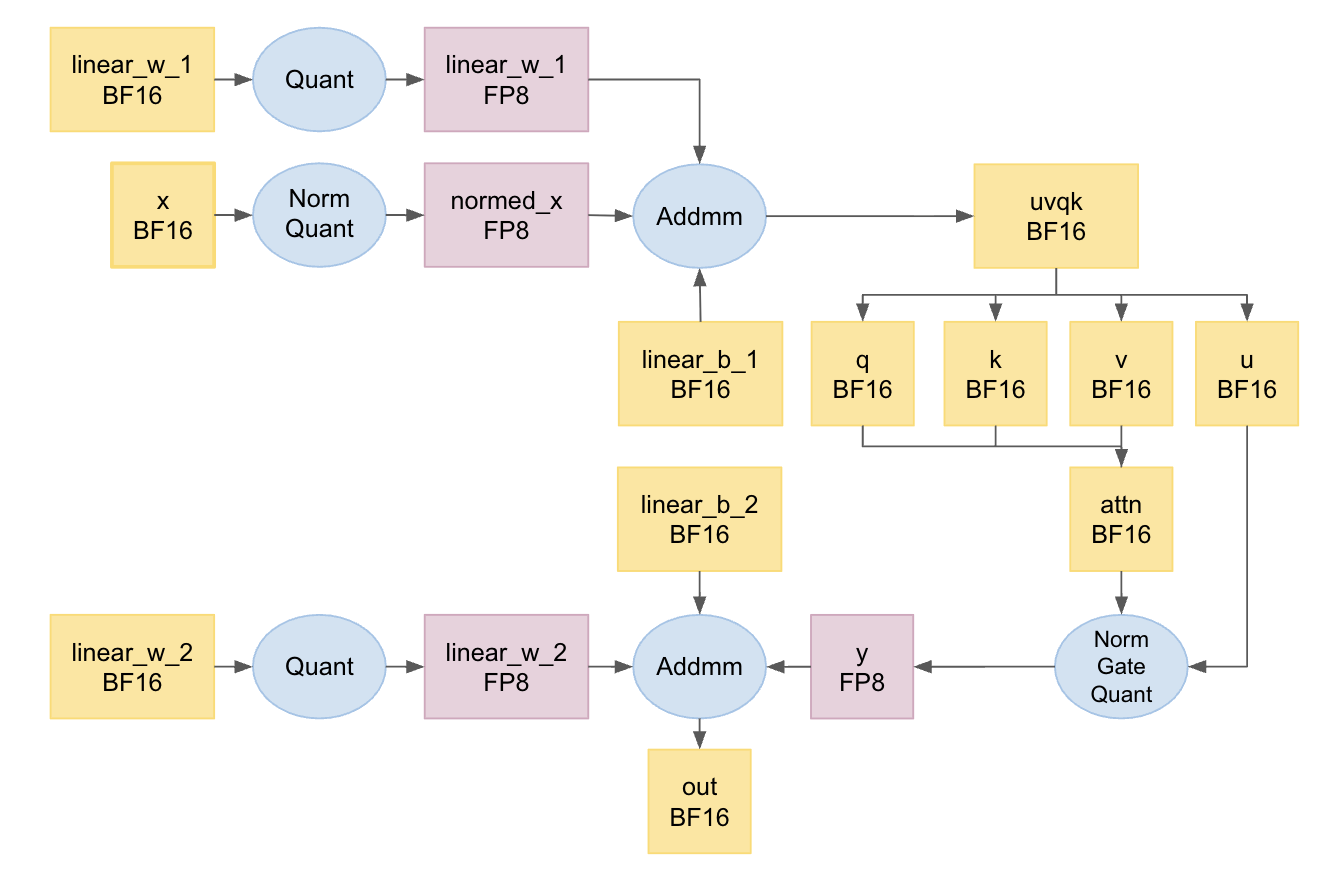
Оптимизация эффективности: Точность и квантование
В архитектуре ULTRA-HSTU применяются передовые методы пониженной точности, такие как BF16 и FP8, для существенного уменьшения объема занимаемой памяти и ускорения вычислений. BF16 (Brain Floating Point) использует 16 бит для представления чисел с плавающей точкой, что позволяет снизить требования к памяти вдвое по сравнению с FP32, сохраняя при этом приемлемую точность. FP8, в свою очередь, еще более агрессивно снижает точность до 8 бит, обеспечивая дальнейшее уменьшение объема памяти и увеличение скорости вычислений, особенно в задачах, не требующих высокой точности. Эти методы позволяют эффективно использовать ресурсы оборудования и повысить пропускную способность модели.
Квантизация INT4 позволяет значительно уменьшить размер таблиц встраиваний (embedding tables) без существенной потери производительности модели. Данный метод предполагает снижение точности представления параметров модели до 4 бит, что приводит к пропорциональному снижению объема необходимой памяти для их хранения. Применение INT4 квантизации особенно эффективно для больших моделей, где таблицы встраиваний занимают значительную часть общего объема памяти. Несмотря на снижение точности, тщательная реализация и калибровка позволяют минимизировать влияние на конечные метрики качества, обеспечивая приемлемый компромисс между размером модели и ее производительностью.
Оптимизации, включающие использование BF16 и FP8, а также INT4 квантизацию, позволяют значительно повысить эффективность модели, что критически важно для развертывания на устройствах с ограниченными ресурсами и для проведения обучения больших масштабов. В ходе A/B тестирования зафиксировано увеличение онлайн-потребления на 4.11%, а также повышение показателей онлайн-вовлеченности пользователей на 2-8%, что подтверждает практическую значимость предложенных оптимизаций и их положительное влияние на производительность и масштабируемость модели.
Будущее персонализированных рекомендаций
Разработка ULTRA-HSTU открывает новые возможности для создания по-настоящему персонализированных рекомендаций, основанных на всестороннем анализе истории действий пользователя. Благодаря повышенной масштабируемости, система способна эффективно обрабатывать огромные объемы данных, охватывающие длительные периоды взаимодействия, и выявлять сложные поведенческие закономерности, которые остаются незамеченными при использовании традиционных подходов. Это позволяет учитывать мельчайшие нюансы предпочтений и контекста, обеспечивая более точные и релевантные рекомендации, что, в свою очередь, способствует повышению вовлеченности и удовлетворенности пользователей. Улучшенная эффективность масштабирования позволяет системе адаптироваться к постоянно меняющимся потребностям каждого отдельного пользователя, создавая уникальный и персонализированный опыт взаимодействия.
Модель демонстрирует способность эффективно обрабатывать чрезвычайно длинные последовательности пользовательских данных, что позволяет выявлять тонкие поведенческие паттерны и контекстуальные нюансы, часто упускаемые из виду традиционными системами рекомендаций. Благодаря этому, система способна учитывать не только недавние действия пользователя, но и его долгосрочные предпочтения, а также учитывать контекст, в котором эти действия происходили. Такой детальный анализ поведения приводит к повышению релевантности рекомендаций, что, в свою очередь, способствует увеличению вовлеченности пользователей и повышению их удовлетворенности от использования сервиса. Более точные и персонализированные рекомендации стимулируют более активное взаимодействие с платформой и укрепляют лояльность пользователей.
Разработанная модель демонстрирует существенные улучшения в масштабируемости, что открывает новые возможности для создания персонализированных рекомендательных систем. Благодаря применению механизма Semi-Local Attention, показатель масштабируемости обучения увеличился на 1.39x, а показатель масштабируемости вывода — на 1.69x. Дальнейшая оптимизация, реализованная посредством усечения внимания (Attention Truncation), позволила добиться еще более значительного улучшения масштабируемости вывода — на 1.8x. Эти достижения позволяют создавать системы, способные эффективно обрабатывать большие объемы данных о пользователях, учитывать тонкие поведенческие особенности и динамично адаптироваться к изменяющимся предпочтениям, что в конечном итоге приводит к повышению вовлеченности пользователей и улучшению их опыта.
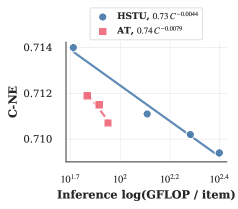
Исследование демонстрирует, что эффективность масштабирования в рекомендательных системах напрямую зависит от продуманного проектирования как самой модели, так и лежащей в её основе системы. Авторы, представляя ULTRA-HSTU, подчеркивают необходимость целостного подхода, где оптимизация внимания к сверхдлинным последовательностям пользователей неразрывно связана с аппаратной реализацией. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что можно логически доказать, а не о том, что можно наблюдать». В данном случае, логическая структура модели и системы, спроектированные совместно, позволяют добиться значительного улучшения масштабируемости, что подтверждает важность элегантного дизайна, рожденного из простоты и ясности.
Куда двигаться дальше?
Представленная работа, стремясь к оптимизации масштабируемости рекомендательных систем, неизбежно наталкивается на фундаментальный вопрос: достаточно ли вообще оптимизировать существующую архитектуру? Подобно алхимикам, стремящимся превратить свинец в золото, исследователи тратят усилия на шлифовку деталей, в то время как, возможно, принципиально иной подход к организации информации окажется более плодотворным. В конечном счете, увеличение длины обрабатываемых последовательностей — лишь симптом, а не причина. Необходимо понимать, что именно в этих последовательностях представляет ценность, и какие структуры информации действительно важны для формирования релевантных рекомендаций.
Оптимизация внимания, представленная в данной работе, — безусловно, шаг вперед, однако она лишь маскирует проблему экспоненциального роста вычислительных затрат. Следующим этапом представляется поиск принципиально новых механизмов агрегации информации, способных улавливать долгосрочные зависимости без необходимости хранения и обработки всей истории взаимодействий. Возможно, вдохновение следует искать в биологических системах, где информация кодируется и обрабатывается чрезвычайно эффективно благодаря сложной иерархической организации и механизмам отбора.
В конечном счете, успех в этой области будет зависеть не только от совершенствования алгоритмов, но и от понимания того, что сама концепция «рекомендации» нуждается в переосмыслении. Недостаточно просто предсказывать, что пользователь захочет увидеть; необходимо создавать системы, которые помогают пользователю открывать новое, расширять кругозор и формировать собственные предпочтения. И в этом, вероятно, кроется настоящая сложность и подлинная ценность исследования.
Оригинал статьи: https://arxiv.org/pdf/2602.16986.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Фотографируем муравьёв с Андреем Павловым
- Обзор Motorola Razr 50 Ultra
- Обзор объектива Tokina 11-16mm f/2.8 AF
- Nikon D7200
- Обзор Moto G Stylus 5G (2024)
- Что купить фотографу. Рекомендации
- Как правильно обрабатывать портрет в фотошоп
- Обзор Nikon D5500 DX
- OnePlus 15T ОБЗОР: большой аккумулятор, беспроводная зарядка, замедленная съёмка видео
- Realme 16T ОБЗОР: яркий экран, плавный интерфейс, большой аккумулятор
2026-02-21 12:47