Автор: Денис Аветисян
Исследователи представили метод SpectralGCD, позволяющий эффективно выявлять новые категории объектов, используя информацию из разных источников.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"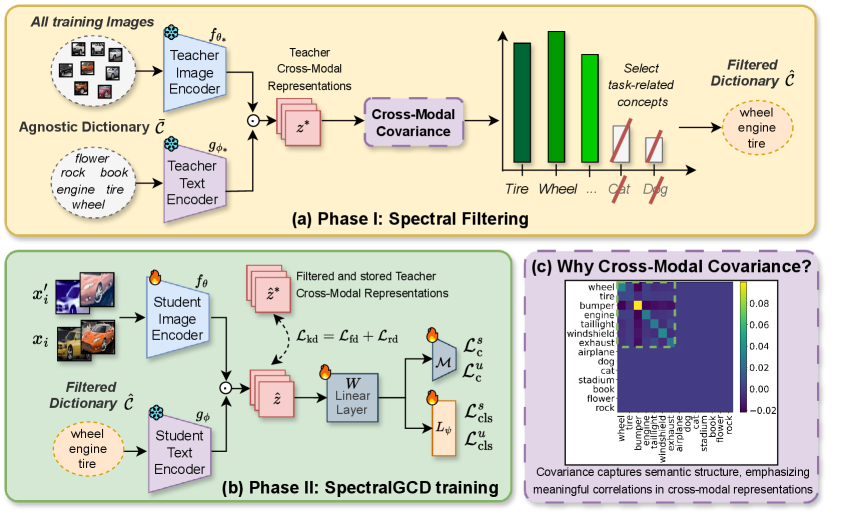
SpectralGCD объединяет спектральную фильтрацию, кросс-модальное представление и контрастное обучение для обобщенного обнаружения категорий.
Обнаружение обобщенных категорий в неразмеченных данных затруднено переобучением на известных классах и вычислительными затратами при использовании мультимодальных подходов. В данной работе представлена методика ‘SpectralGCD: Spectral Concept Selection and Cross-modal Representation Learning for Generalized Category Discovery’, использующая кросс-модальные представления CLIP и спектральную фильтрацию для эффективного выявления новых категорий и поддержания высокой производительности на известных. Предложенный подход позволяет представить каждое изображение как смесь семантических концепций из большого словаря, что снижает зависимость от ложных визуальных признаков и обеспечивает более надежное обучение. Возможно ли дальнейшее повышение эффективности и масштабируемости методов обобщенного обнаружения категорий за счет оптимизации процесса выбора концепций и использования более компактных представлений?
Вызов Неизведанного: Преодолевая Границы Категоризации
Традиционные методы машинного обучения испытывают значительные трудности при выявлении новых категорий в немаркированных данных. Суть проблемы заключается в их зависимости от обширных, предварительно размеченных наборов данных, необходимых для обучения. Алгоритмы, разработанные для классификации на основе известных категорий, оказываются неэффективными при столкновении с неизвестными объектами или ситуациями, поскольку не обладают способностью к самостоятельному определению границ новых классов. Для успешной работы таких систем требуется ручная разметка каждого нового объекта, что является трудоемким, дорогостоящим и часто непрактичным процессом, особенно в условиях постоянно меняющейся информации и больших объемов данных. Это ограничение препятствует развитию действительно адаптивных и интеллектуальных систем, способных самостоятельно учиться и обобщать знания на основе неструктурированной информации.
Существующие методы машинного обучения зачастую демонстрируют ограниченную эффективность при работе с небольшим количеством размеченных данных и сложностью реальных условий. Традиционные алгоритмы, требующие обширных наборов данных для обучения, сталкиваются с трудностями при анализе информации, где количество примеров для каждой категории ограничено. Сложность проявляется и в неоднородности данных, включающих шум, перекрывающиеся признаки и нечеткие границы между категориями. Это приводит к снижению точности классификации, увеличению количества ложных срабатываний и затрудняет автоматическое выявление новых, ранее неизвестных категорий объектов или явлений. В результате, существующие подходы требуют значительных усилий по предварительной обработке данных и ручной настройке параметров, что ограничивает их применимость в динамично меняющихся средах.
Разработка эффективных и устойчивых методов обобщенного обнаружения категорий (GCD) имеет первостепенное значение для дальнейшего развития приложений искусственного интеллекта. Существующие алгоритмы часто испытывают трудности при анализе данных, которые не соответствуют заранее заданным категориям, что ограничивает их способность адаптироваться к новым и непредсказуемым ситуациям. GCD позволяет системам не только распознавать известные классы объектов, но и самостоятельно выделять новые, ранее не встречавшиеся категории, основываясь на внутренних характеристиках данных. Это открывает возможности для создания более гибких и интеллектуальных систем, способных к самостоятельному обучению и адаптации, что особенно важно в таких областях, как робототехника, автономное вождение и анализ больших данных, где постоянно возникают новые типы информации и задач.
Решение задачи обнаружения новых категорий открывает путь к созданию действительно адаптируемых и интеллектуальных систем. Способность искусственного интеллекта самостоятельно выявлять и классифицировать ранее неизвестные объекты и явления принципиально отличается от традиционных подходов, требующих предварительной разметки данных. Такая адаптивность позволяет создавать системы, способные эффективно функционировать в динамично меняющихся условиях, обучаться на неструктурированных данных и решать задачи, для которых изначально не были предусмотрены алгоритмы. Это особенно важно для приложений в области робототехники, автономного вождения, анализа медицинских изображений и многих других сферах, где требуется гибкость и способность к обучению в реальном времени. Разработка эффективных методов обобщенного обнаружения категорий — это ключевой шаг к созданию искусственного интеллекта, способного не просто выполнять заданные инструкции, а понимать и адаптироваться к окружающему миру.
Кросс-Модальное Обучение: Расширяя Горизонты Распознавания
Использование моделей, объединяющих зрение и язык, таких как CLIP, позволяет установить связь между визуальной и текстовой информацией посредством обучения в общем многомерном пространстве признаков. CLIP обучается сопоставлять изображения и текстовые описания, формируя векторные представления (эмбеддинги) для обоих типов данных таким образом, чтобы соответствующие друг другу изображения и текст находились близко друг к другу в этом пространстве. Это достигается за счет использования контрастивного обучения, где модель учится максимизировать сходство между правильными парами изображение-текст и минимизировать сходство между неправильными парами. В результате, модель способна оценивать семантическую близость между изображениями и текстом, что позволяет выполнять такие задачи, как поиск изображений по текстовому запросу и наоборот.
Создание кросс-модальных представлений позволяет установить соответствие между изображениями и понятиями, выраженными на естественном языке. Этот процесс включает в себя преобразование как визуальных, так и текстовых данных в общее векторное пространство, где семантическая близость между ними отражается в близости векторов. В результате, изображение и его текстовое описание становятся представимыми в виде сопоставимых векторов, что позволяет алгоритмам оценивать релевантность между ними. Такое представление является основой для задач, как поиск изображений по текстовому запросу и наоборот, а также для понимания контекста визуального контента на основе текстовых метаданных.
Перенос знаний между визуальными и текстовыми данными позволяет обнаруживать новые категории объектов и концепций. Используя модели, обученные на больших корпусах изображений и текста, можно установить соответствия между визуальными признаками и текстовыми описаниями. Это позволяет, например, идентифицировать изображения, соответствующие ранее неизвестным текстовым запросам, или, наоборот, генерировать текстовые описания для визуальных данных, относящихся к новым категориям. В процессе обучения модель формирует общие представления, которые позволяют ей обобщать знания, полученные из одной модальности, на другую, тем самым расширяя возможности классификации и поиска.
Для снижения вычислительной сложности при работе с обширными словарями концепций, применяется метод спектральной фильтрации. Данный подход основан на анализе спектральной плотности корреляций между визуальными и текстовыми представлениями. Суть метода заключается в выделении наиболее релевантных концепций из словаря путем отсеивания тех, чьи спектральные характеристики значительно отличаются от доминирующих. Это позволяет сократить количество анализируемых концепций, сохраняя при этом точность и эффективность процесса обучения и поиска, особенно в задачах, требующих обработки больших объемов данных и высокой скорости обработки.

Продвинутые Методы GCD: SimGCD, TextGCD и SpectralGCD
SimGCD использует комбинацию контролируемого и неконтролируемого контрастного обучения для повышения различимости категорий. Контрастное обучение позволяет модели изучать представления, где экземпляры одной категории сближаются, а экземпляры разных категорий — отдаляются. Для повышения эффективности, SimGCD дополняет этот процесс параметрическими функциями потерь классификации, которые напрямую оптимизируют способность модели правильно классифицировать входные данные. Сочетание контрастного обучения и параметрических потерь позволяет SimGCD эффективно извлекать признаки, улучшая производительность в задачах категоризации и кластеризации, особенно при ограниченном количестве размеченных данных.
Методы TextGCD и SpectralGCD усовершенствуют процесс распознавания категорий путем интеграции текстовой информации, получаемой с помощью больших языковых моделей (LLM). TextGCD использует LLM для анализа и включения семантических описаний категорий, что улучшает точность кластеризации. SpectralGCD, в свою очередь, применяет спектральную фильтрацию для эффективного отбора наиболее релевантных концепций, снижая вычислительную сложность и повышая производительность при работе с многомерными данными. Оба подхода направлены на улучшение дискриминации категорий, особенно в условиях ограниченного количества размеченных данных.
Методы, такие как GET, используют энкодеры изображений CLIP и инверсионные сети для автоматического назначения псевдо-описаний (pseudo-captions) к изображениям. CLIP (Contrastive Language-Image Pre-training) кодирует изображения в векторное пространство, а инверсионные сети позволяют реконструировать изображение из этого вектора. Назначение псевдо-описаний, основанное на векторном представлении, позволяет обогатить данные для обучения моделей, особенно в условиях ограниченного количества размеченных данных, и, как следствие, повысить производительность при задачах кластеризации и идентификации новых категорий.
Методы SimGCD, TextGCD и SpectralGCD демонстрируют существенное повышение точности идентификации новых категорий при ограниченном количестве размеченных данных. Согласно результатам тестирования на шести стандартных наборах данных, эти методы достигают до 92% точности кластеризации. Это указывает на их эффективность в задачах, где получение большого объема размеченных данных затруднено или невозможно, позволяя проводить более точную категоризацию и классификацию объектов на основе ограниченной информации.
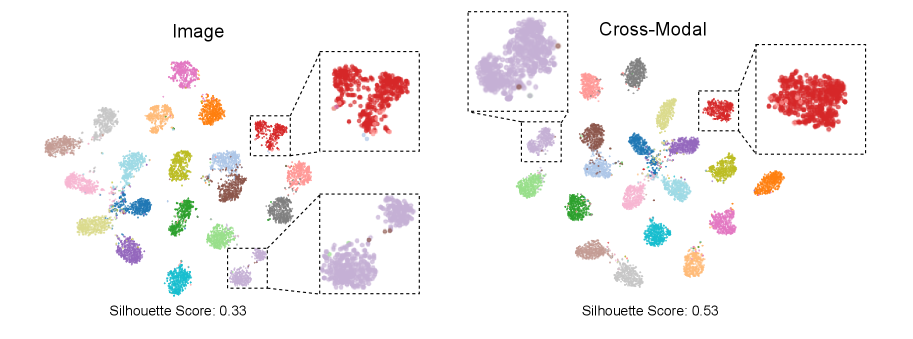
Дистилляция Знаний: Усиление Обобщающей Способности
Методы прямой и обратной дистилляции знаний позволяют эффективно передавать опыт от крупных, предварительно обученных «учительских» моделей к более компактным «студенческим». Этот процесс заключается в обучении студенческой модели не только правильно классифицировать данные, но и воспроизводить вероятностное распределение, которое генерирует учительская модель. В результате, студенческая модель, даже при ограниченном количестве данных, приобретает способность к обобщению и демонстрирует повышенную устойчивость к новым, ранее не встречавшимся ситуациям. Прямая дистилляция фокусируется на передаче знаний от учителя к студенту, в то время как обратная дистилляция использует студенческую модель для улучшения производительности учительского экземпляра, создавая симбиотический процесс обучения и оптимизации.
Процесс дистилляции знаний значительно повышает способность студенческой модели к обобщению на новые, ранее не встречавшиеся категории. Это достигается за счет передачи опыта от более крупной и обученной «учительской» модели, позволяя «студенту» эффективно использовать ограниченные объемы данных. В результате, даже при недостатке обучающих примеров, студенческая модель демонстрирует улучшенную производительность и способность к адаптации к новым задачам, что особенно ценно в условиях ограниченных вычислительных ресурсов и необходимости быстрого развертывания систем машинного обучения. Такой подход позволяет создавать более устойчивые и гибкие модели, способные эффективно работать в различных условиях и с разнообразными данными.
Выравнивание представлений моделей «Учитель» и «Ученик» является ключевым фактором создания эффективных и устойчивых систем GCD (Generalized Cross-Domain). Этот процесс позволяет «Ученику» не просто имитировать выходные данные «Учителя», но и усвоить лежащие в их основе знания и способы представления информации. В результате, даже меньшие по размеру модели «Ученик» способны демонстрировать высокую производительность и обобщающую способность, эффективно работая с новыми данными и задачами, что особенно важно в условиях ограниченных вычислительных ресурсов и необходимости быстрой адаптации к меняющимся условиям. Такое согласование представлений обеспечивает более надежную и точную работу системы, повышая её устойчивость к шумам и неполноте данных.
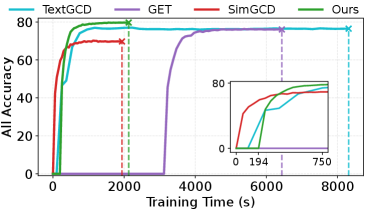
В отличие от других мультимодальных подходов, таких как GET и TextGCD, требующих значительно больше времени на обучение, разработанная система SpectralGCD демонстрирует сопоставимую скорость обучения с унимодальными методами. Это важное преимущество позволяет эффективно внедрять SpectralGCD в практические приложения, где время является критическим фактором. Достижение подобной эффективности стало возможным благодаря оптимизированной архитектуре и алгоритмам обучения, позволяющим системе быстро адаптироваться к новым данным и эффективно использовать вычислительные ресурсы. Таким образом, SpectralGCD предлагает оптимальное сочетание производительности и скорости обучения, делая её привлекательным решением для широкого спектра задач обработки информации.
Перспективы Развития: К Адаптивному Интеллекту
В будущем исследования будут направлены на интеграцию разработанных методов генерации контрастных данных (GCD) с архитектурой Vision Transformers. Это позволит использовать мощные возможности Vision Transformers в области извлечения признаков и представления данных, значительно улучшая качество обучения и обобщающую способность моделей. Сочетание GCD с Vision Transformers открывает перспективы для создания систем, способных эффективно извлекать и использовать информацию из визуальных данных, даже при ограниченном количестве размеченных образцов. Ожидается, что подобный подход позволит достичь существенного прогресса в задачах компьютерного зрения, включая распознавание изображений, обнаружение объектов и семантическую сегментацию, создавая более адаптивные и интеллектуальные системы.
Разработка более эффективных и масштабируемых методов дистилляции знаний представляется ключевым фактором для успешного внедрения GCD-методов в практические приложения. Современные подходы к дистилляции часто требуют значительных вычислительных ресурсов и времени, что ограничивает их применение в сценариях с ограниченными ресурсами или необходимостью обработки больших объемов данных в реальном времени. Поэтому, исследования, направленные на оптимизацию алгоритмов дистилляции, снижение вычислительной сложности и повышение скорости обучения, имеют первостепенное значение. Успешная реализация таких методов позволит не только снизить затраты на развертывание и эксплуатацию GCD-систем, но и расширить область их применения, открывая новые возможности в областях компьютерного зрения, обработки естественного языка и робототехники.
Исследования в области самообучающихся методов представляются весьма перспективным направлением для снижения зависимости от размеченных данных. Такой подход позволяет моделям извлекать полезные представления из немаркированной информации, используя внутренние сигналы и структуру самих данных. Вместо трудоемкой и дорогостоящей ручной разметки, алгоритмы самообучения могут самостоятельно генерировать «псевдо-метки» или использовать контрастивное обучение для выявления схожих и различных примеров. Это особенно актуально для задач компьютерного зрения, где объемы неразмеченных изображений значительно превосходят размеченные. Дальнейшее развитие этих техник позволит создавать более адаптивные и эффективные системы, способные обучаться на больших объемах неструктурированных данных и достигать высокой точности без значительных затрат на разметку.
Представленный метод демонстрирует значительное улучшение показателей точности в задачах поиска изображений. В частности, достигнут показатель mAP в 87.6% на наборе данных CUB, что свидетельствует о высокой эффективности в распознавании мелких деталей и сложных объектов. Более того, по сравнению с использованием только признаков изображений, наблюдается улучшение на 14% в точности поиска по набору данных Cars, что подчеркивает способность метода к более глубокому и комплексному пониманию визуальной информации и более точному сопоставлению изображений.

Исследование, представленное в данной работе, демонстрирует элегантный подход к задаче обобщенного обнаружения категорий. SpectralGCD, используя возможности кросс-модальных представлений CLIP и спектральной фильтрации, позволяет эффективно идентифицировать новые категории, не жертвуя при этом производительностью на известных. Это подтверждает высказывание Яна ЛеКуна: «Машинное обучение — это, по сути, обучение представлений». В данном случае, ключевым является создание компактных и информативных представлений, позволяющих эффективно различать и обобщать категории. Тщательно подобранные фильтры и контрастивное обучение демонстрируют стремление к гармонии между формой и функцией, что делает систему не только эффективной, но и понятной.
Куда же дальше?
Представленная работа, безусловно, демонстрирует элегантность подхода к задаче обобщенного открытия категорий. Однако, подобно тщательно выточенной статуе, она оставляет ощущение незавершенности. Эффективность метода, зависящая от предварительно обученных представлений CLIP, наводит на мысль о хрупкости подобной конструкции. Вопрос о робастности к изменениям в данных, к сдвигам в распределениях, остается открытым. Нельзя ли создать систему, которая не просто «узнает» новое, но и понимает его суть, не опираясь на внешние артефакты?
Перспективы кажутся очевидными, но требуют глубокого осмысления. Необходимо исследовать возможности отказа от жесткой привязки к конкретной модели CLIP, перейти к более гибким механизмам формирования кросс-модальных представлений. Интересно было бы изучить возможность интеграции принципов активного обучения, позволяющих системе самостоятельно формировать запрос на получение информации, необходимой для уточнения границ новых категорий. В конечном итоге, необходимо стремиться к созданию систем, которые не просто «работают», но и обладают внутренней гармонией, отражающей глубину понимания задачи.
И, пожалуй, самое важное — не забывать о простоте. Сложность ради сложности — признак непродуманности. Элегантное решение всегда лаконично и понятно, подобно хорошо написанному стихотворению. Пусть дальнейшие исследования будут направлены на поиск этой внутренней красоты, этой гармонии между формой и функцией.
Оригинал статьи: https://arxiv.org/pdf/2602.17395.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Российский рынок: от инфляции к инвестициям: что ждет инвесторов? (11.06.2026 02:32)
- Как сделать фотографию резкой.
- Xiaomi Redmi R70m ОБЗОР: большой аккумулятор, плавный интерфейс
- Прогнозы цен на CC: анализ криптовалюты CC
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Обзор Motorola Edge 50 Fusion
- 10 лучших OLED ноутбуков. Что купить в июне 2026.
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Что купить фотографу. Рекомендации
- Синхронизация вспышки. Что такое Sync speed и режим FP.
2026-02-22 14:01