Автор: Денис Аветисян
Исследователи представили масштабный набор данных и методологию оценки реалистичности моделей, имитирующих поведение пользователей в системах диалоговых рекомендаций.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"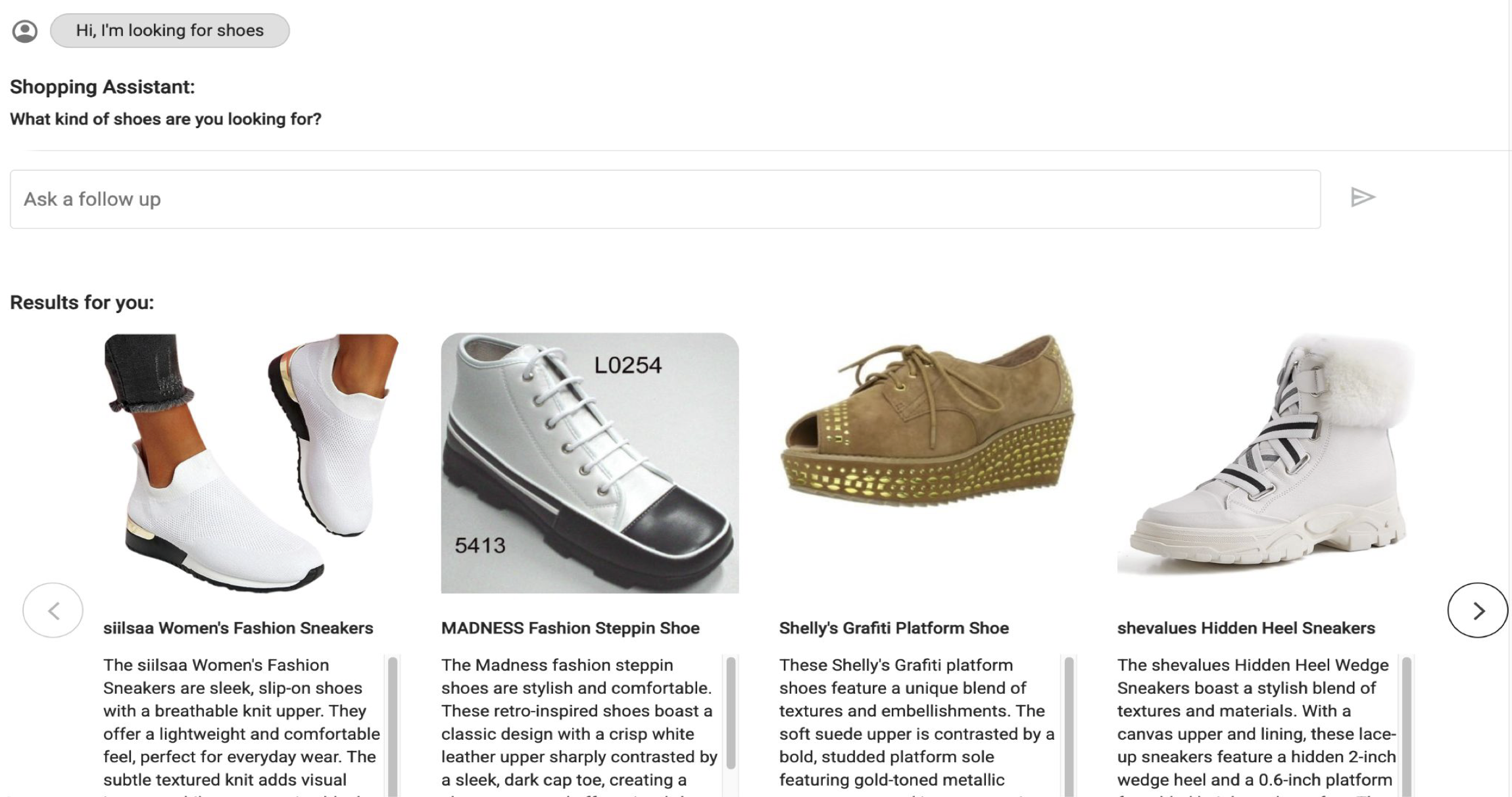
Представлен набор данных ConvApparel и фреймворк для валидации реализма и надежности пользовательских симуляторов на основе генеративных моделей.
Несмотря на многообещающие возможности языковых моделей (LLM) в улучшении диалоговых систем, их оценка затруднена из-за существенного расхождения между симулируемой и реальной пользовательской реакцией. В данной работе представлена ‘ConvApparel: A Benchmark Dataset and Validation Framework for User Simulators in Conversational Recommenders’ — новый набор данных и комплексная методика валидации, предназначенные для оценки реалистичности и надежности LLM-основанных симуляторов пользователей в системах рекомендаций. Эксперименты выявили значительный разрыв между симулируемыми и реальными взаимодействиями, однако показали, что модели, обученные на данных, превосходят модели, использующие только промпты, особенно в задачах контрфактической валидации. Сможем ли мы преодолеть этот разрыв и создать действительно адаптивные и реалистичные диалоговые системы, способные эффективно взаимодействовать с пользователями в реальном мире?
Эволюция Кода: От Ручного Труда к Автоматизации
Традиционная разработка программного обеспечения исторически основывалась на ручном кодировании, что представляет собой трудоемкий и подверженный ошибкам процесс. Каждая строка кода, каждая функция и каждый модуль создавались программистом вручную, требуя значительных затрат времени и усилий. Эта ручная работа не только замедляет процесс разработки, но и увеличивает вероятность внесения ошибок, которые могут привести к сбоям в работе программного обеспечения или уязвимостям в системе безопасности. Особенно сложными оказываются крупные проекты, где координация работы над большим объемом кода и отслеживание изменений требуют высокой степени дисциплины и организации. В результате, исправление ошибок и внесение изменений в существующий код часто оказываются более затратными, чем первоначальная разработка.
Появление больших языковых моделей (LLM) знаменует собой новую эру в разработке программного обеспечения. Эти модели демонстрируют впечатляющую способность генерировать код на основе текстовых инструкций, открывая перспективы для автоматизации значительной части жизненного цикла разработки. Вместо ручного написания каждой строки кода, LLM способны создавать целые фрагменты, функции и даже приложения, существенно сокращая время и ресурсы, необходимые для реализации проектов. Это позволяет разработчикам сосредоточиться на более сложных задачах, таких как проектирование архитектуры и тестирование, а также снижает вероятность ошибок, свойственных ручному кодированию. Возможности LLM простираются от генерации шаблонного кода и автоматического заполнения функций до создания прототипов и даже полноценных рабочих приложений, что делает их мощным инструментом для повышения производительности и инноваций в сфере разработки программного обеспечения.
Эффективность генерации кода с использованием больших языковых моделей (LLM) напрямую зависит от их способности точно интерпретировать поставленные задачи и преобразовывать их в рабочий программный код. По сути, LLM выступают в роли своеобразных “переводчиков” между человеческим языком и языком программирования, и малейшие неточности в понимании инструкций могут привести к созданию кода, содержащего ошибки или не соответствующего требуемой функциональности. Достижение высокой точности в этом процессе требует не только огромных объемов обучающих данных, но и усовершенствованных алгоритмов, способных учитывать контекст, неоднозначность и тонкости человеческого языка, чтобы генерировать код, который не просто компилируется, но и эффективно решает поставленную задачу.
Стратегии Обучения для Генерации Кода
Большинство современных языковых моделей (LLM), используемых для генерации кода, не обучаются с нуля. Вместо этого, они предварительно обучаются на огромных объемах текстовых данных, включающих как естественный язык, так и исходный код. Этот этап предварительного обучения позволяет модели усвоить общие закономерности языка и структуры кода. После этого следует этап тонкой настройки (fine-tuning), на котором модель обучается на специализированном наборе данных, состоящем из примеров кода и соответствующих инструкций или описаний. Такой подход позволяет значительно сократить время и вычислительные ресурсы, необходимые для обучения модели, а также повысить качество генерируемого кода.
Методы обучения с небольшим количеством примеров (few-shot learning) и без примеров (zero-shot learning) позволяют большим языковым моделям (LLM) обобщать знания и решать новые задачи кодирования, не требуя обширных наборов данных для обучения. В обучении с небольшим количеством примеров модель получает лишь ограниченное число примеров решения задачи, достаточных для выявления закономерностей и адаптации к новым условиям. Обучение без примеров идет еще дальше, позволяя модели решать задачи, для которых она не получала никаких обучающих примеров, опираясь на общие знания, полученные в процессе предварительного обучения на больших объемах текста и кода. Эффективность этих методов зависит от качества предварительного обучения модели и ее способности к обобщению.
Обучение с подкреплением на основе инструкций (Instruction Tuning) играет ключевую роль в повышении способности больших языковых моделей (LLM) точно интерпретировать и выполнять запросы, что напрямую влияет на качество генерируемого кода. Этот процесс предполагает дообучение предварительно обученной модели на наборе данных, состоящем из пар «инструкция-код», что позволяет LLM лучше понимать намерения пользователя, выраженные в текстовом запросе, и, следовательно, генерировать более релевантный и функциональный код. Эффективность Instruction Tuning проявляется в улучшении метрик, таких как точность синтаксиса, семантическая корректность и соответствие кода поставленной задаче, что делает его важным этапом в создании надежных систем генерации кода.
Архитектурные Основы и Оценка Эффективности
Модели CodeT5, CodeGen и StarCoder представляют собой прочную основу для генерации кода на базе больших языковых моделей (LLM). Их эффективность обусловлена предварительным обучением на обширных наборах данных, содержащих исходный код и связанные с ним тексты. Этот процесс позволяет моделям усвоить синтаксис, семантику и распространенные шаблоны программирования, что существенно повышает их способность генерировать функциональный и корректный код. Предварительное обучение на данных, специфичных для кода, является ключевым фактором, отличающим эти модели от LLM общего назначения и обеспечивающим их превосходство в задачах, связанных с кодом.
Для оценки производительности моделей генерации кода, таких как CodeT5, CodeGen и StarCoder, применяются стандартизированные наборы данных HumanEval и MBPP. HumanEval предназначен для проверки функциональной корректности сгенерированного кода, требуя решения задач программирования с использованием предоставленных сигнатур функций и юнит-тестов. MBPP (Mostly Basic Programming Problems) фокусируется на оценке способности моделей обобщать знания и решать более простые, но разнообразные задачи. Использование этих бенчмарков позволяет количественно оценить способность моделей генерировать код, который не только компилируется, но и выполняет поставленную задачу в различных сценариях, обеспечивая оценку их способности к обобщению.
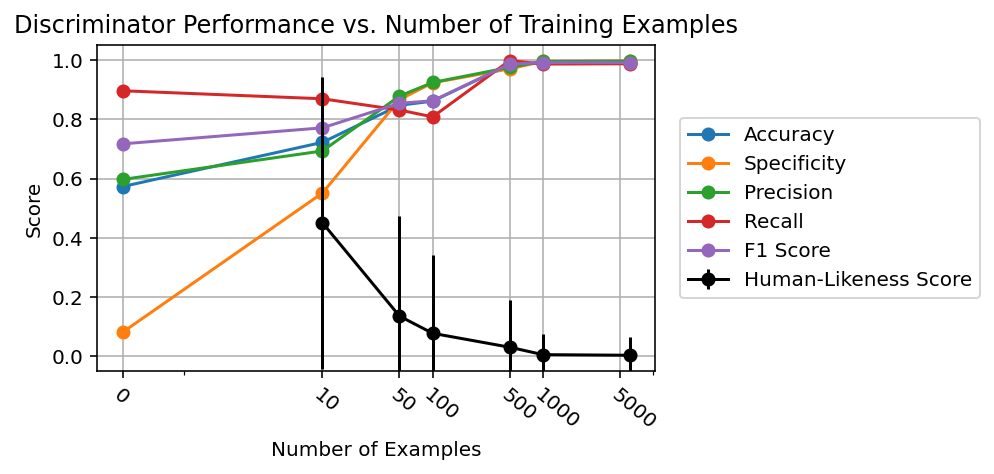
Метрика Pass@K предоставляет количественную оценку качества генерации кода, определяя долю сгенерированных образцов кода, которые успешно проходят все тесты в заданном наборе. Наша новая система валидации, использующая дискриминатор, демонстрирует точность 0.99 на независимом наборе данных, содержащем человеческие диалоги. Это указывает на высокую способность системы различать сгенерированные (синтетические) и реальные (человеческие) беседы, что является критически важным для оценки реалистичности и полезности сгенерированного кода и сопутствующей документации.
Масштабирование и Эффективность в Генерации Кода LLM
По мере увеличения масштаба языковых моделей, наблюдается закономерное повышение их производительности в решении различных задач. Однако, этот прогресс неизбежно сопровождается экспоненциальным ростом вычислительных затрат и требований к ресурсам. Увеличение числа параметров модели требует всё больше памяти, энергии и времени для обучения и развертывания, что создает серьезные ограничения для разработчиков и пользователей. В результате, возникает необходимость в поиске баланса между производительностью и эффективностью, а также в разработке методов, позволяющих достигать высоких результатов с использованием более компактных и управляемых моделей. Данная тенденция подталкивает исследователей к поиску инновационных архитектур и алгоритмов, направленных на оптимизацию использования ресурсов и снижение вычислительной сложности.
Эффективность использования параметров становится ключевым фактором в разработке больших языковых моделей (LLM), позволяя достигать высокой производительности при использовании более компактных и управляемых моделей. Вместо простого увеличения масштаба, что неизбежно ведет к росту вычислительных затрат и требований к ресурсам, современные исследования направлены на оптимизацию архитектуры и методов обучения. Это позволяет создавать модели, способные выполнять сложные задачи генерации кода с меньшим количеством параметров, что существенно снижает затраты на обучение, развертывание и эксплуатацию. Такой подход открывает возможности для использования LLM на устройствах с ограниченными ресурсами и делает их более доступными для широкого круга разработчиков и пользователей.
Результаты валидации демонстрируют высокую точность дискриминатора — 0.978 при обучении на диалогах, инициированных запросами, и значительное снижение этого показателя до 0.041 при обучении на диалогах, полученных в результате SFT (Supervised Fine-Tuning). Такое различие наглядно свидетельствует об эффективности предложенных методов в снижении артефактов, возникающих при моделировании. Дополнительно, анализ с использованием U-критерия Манна-Уитни выявил p-значения менее 0.05 для ряда метрик, что подтверждает статистическую согласованность результатов с характеристиками поведения человека и указывает на реалистичность генерируемых диалогов.
Исследование, представленное в работе, демонстрирует, что, несмотря на прогресс в создании пользовательских симуляторов для диалоговых систем, значительный разрыв в реалистичности сохраняется. Данный факт подчеркивает неизбежность компромиссов при упрощении сложных систем. Как заметил Бертран Рассел: «Страх — это главный источник заблуждений». В контексте диалоговых рекомендательных систем, страх перед сложностью может привести к принятию нереалистичных моделей пользователей, что, в свою очередь, снижает эффективность системы. Работа над ConvApparel направлена на преодоление этой сложности, предоставляя инструменты для более тщательной оценки и валидации пользовательских симуляторов, а также осознания цены упрощения в долгосрочной перспективе.
Куда Ведет Дорога?
Представленный труд, подобно любому картографированию неизведанной территории, скорее обнажает пропасти, чем заполняет их. Создание набора данных ConvApparel и валидационной рамки — это не фиксация достижения, а признание того, насколько далеки существующие модели пользовательских симуляторов от истинного отражения сложности человеческого диалога. Преимущество, демонстрируемое методами, основанными на данных, над простым промптингом, лишь подчеркивает, что «разумность» симуляции — это не вопрос изобретательности архитектуры, а вопрос объема памяти — объема данных, необходимых для хотя бы приблизительного воссоздания контекста.
Ведь версионирование, как и любое машинное обучение, — это форма памяти. Но память, как известно, несовершенна, склонна к искажениям и упущениям. Стрела времени всегда указывает на необходимость рефакторинга, на переосмысление тех предположений, которые лежат в основе любой модели. Следующий этап — это не столько улучшение алгоритмов, сколько поиск способов более эффективного улавливания и хранения той эфемерной сущности, которую мы называем «пользовательским намерением».
В конечном счете, задача состоит не в том, чтобы создать идеальную симуляцию, а в том, чтобы признать ее неизбежную неполноту. Именно в этом несовершенстве и заключается возможность дальнейшего развития — в постоянном стремлении к более тонкому пониманию той сложной системы, которой является человеческое общение. Все системы стареют — вопрос лишь в том, делают ли они это достойно.
Оригинал статьи: https://arxiv.org/pdf/2602.16938.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Фотографируем муравьёв с Андреем Павловым
- Обзор объектива Tokina 11-16mm f/2.8 AF
- Что купить фотографу. Рекомендации
- Неважно, на что вы фотографируете!
- Honor 600 Pro ОБЗОР: чёткое изображение, отличная камера, плавный интерфейс
- Honor 600 ОБЗОР: лёгкий, плавный интерфейс, скоростная зарядка
- Realme 16T ОБЗОР: яркий экран, плавный интерфейс, большой аккумулятор
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Xiaomi 17T ОБЗОР: скоростная зарядка, плавный интерфейс, замедленная съёмка видео
- Калькулятор глубины резкости. Как рассчитать ГРИП.
2026-02-23 03:28