Автор: Денис Аветисян
Новая технология позволяет создавать интерактивные виртуальные миры, реагирующие на движения рук и взгляд пользователя, открывая невиданные возможности для иммерсивного опыта.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"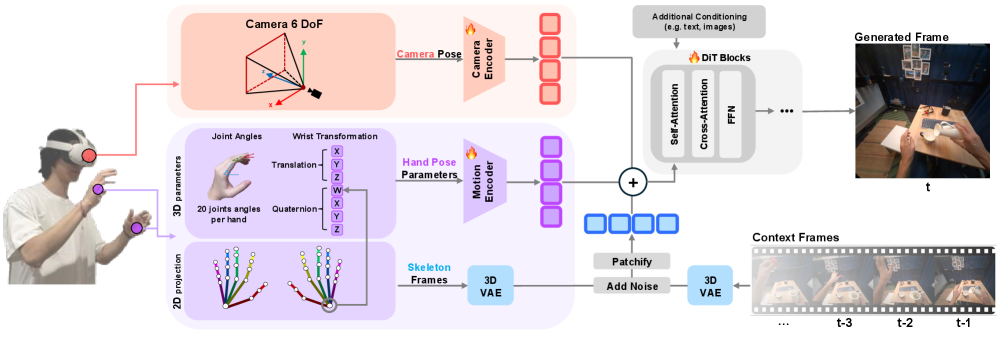
В статье представлена система, использующая модели видео-диффузии, обусловленные отслеживанием поз рук и головы, для создания реалистичных и управляемых виртуальных сред.
Несмотря на растущий интерес к расширенной реальности (XR), современные генеративные модели зачастую ограничены в способности реагировать на сложные движения пользователей в реальном времени. В статье ‘Generated Reality: Human-centric World Simulation using Interactive Video Generation with Hand and Camera Control’ представлена новая система, использующая диффузионные видеомодели, обусловленные отслеживанием положения головы и жестов рук, для создания интерактивных виртуальных сред. Предложенный подход позволяет добиться более реалистичного и контролируемого взаимодействия пользователя с виртуальным миром, значительно превосходя существующие аналоги по качеству генерируемого контента и уровню воспринимаемого контроля. Каковы перспективы дальнейшего развития подобных систем для создания иммерсивных и интуитивно понятных интерфейсов будущего?
Реальность, которую сложно подделать: вызовы интерактивного взаимодействия
Для достижения подлинного погружения в виртуальную реальность, реалистичное взаимодействие рук с объектами является критически важным, однако представляет собой значительную проблему для современных генеративных моделей. Существующие алгоритмы часто не способны достоверно воспроизвести сложные движения кистей и пальцев, необходимые для правдоподобного манипулирования виртуальными предметами. Это ограничение препятствует созданию убедительных виртуальных сред, где взаимодействие ощущается естественным и интуитивным. Разработка моделей, способных генерировать согласованные и высококачественные видеоданные, демонстрирующие правдоподобное взаимодействие рук с различными объектами, остается ключевой задачей для исследователей, стремящихся к созданию действительно иммерсивных виртуальных переживаний.
Существующие методы генерации видео испытывают трудности при создании реалистичной и последовательной анимации сложных движений рук, что является серьезным препятствием для разработки убедительных виртуальных сред. Воспроизведение тонких нюансов хвата, вращения и манипулирования объектами требует высокой точности и согласованности кадров, чего зачастую не удается достичь при использовании современных алгоритмов. Это приводит к неестественным и отвлекающим движениям, разрушающим эффект погружения в виртуальную реальность. Проблема усугубляется необходимостью учитывать сложные взаимодействия между руками, объектами и окружающей средой, что требует значительных вычислительных ресурсов и продвинутых моделей обучения.

Фундамент реализма: генерация и обусловленность видео
В основе нашей системы лежит мощная модель диффузии для генерации видео, Wan2.2, разработанная для создания высококачественных видеопоследовательностей. Модель Wan2.2 использует архитектуру диффузии, постепенно преобразуя случайный шум в структурированное видеоизображение. Она способна генерировать видео с разрешением до 768×768 пикселей и частотой 30 кадров в секунду, демонстрируя высокую степень детализации и реалистичности. Внутренняя структура модели включает в себя большое количество параметров, что позволяет ей захватывать сложные зависимости в видеоданных и генерировать разнообразный и правдоподобный контент.
Для обеспечения точного управления процессом генерации видео используется обусловленность модели Wan2.2 на основе данных о положении рук и головы. Данные о позе рук и головы, полученные из входных данных, служат дополнительными входными сигналами для модели диффузии, позволяя ей генерировать видео, в котором движения и действия соответствуют заданной позе. Использование как данных о положении рук, так и головы позволяет контролировать как общие движения актера, так и более тонкие выражения и жесты, что обеспечивает детальное управление генерируемым контентом и повышает степень реалистичности.
Для повышения пространственной согласованности и реалистичности генерируемого видео в нашей системе используются такие методы, как ControlNet и адаптивная нормализация слоев. ControlNet позволяет модели учитывать дополнительные входные данные, такие как карты глубины или эскизы, что обеспечивает более точное следование заданной структуре сцены. Адаптивная нормализация слоев (Adaptive Layer Normalization — ALN) динамически регулирует статистические параметры каждого слоя нейронной сети, улучшая стабильность обучения и позволяя модели лучше обобщать полученные знания, что приводит к более правдоподобным и детализированным видеопоследовательностям.
Точное определение позы: отслеживание и представление движений
Для получения точных оценок 3D-позы руки из входных данных используется комбинация WiLoR и UmeTrack Hand Model. WiLoR (Weakly-supervised Localization with Regression) позволяет эффективно локализовать ключевые точки руки, даже при ограниченном количестве размеченных данных. UmeTrack Hand Model, в свою очередь, представляет собой нейросетевую модель, обученную на большом наборе данных, что обеспечивает высокую точность и устойчивость оценки 3D-позы. Совместное использование этих двух подходов позволяет добиться высокой точности и надежности в сложных сценариях, включая случаи частичной видимости руки или быстрых движений.
Оцениваемые трехмерные позы руки кодируются посредством представления на уровне суставов (joint-level representation). Этот метод предполагает представление позы как набора координат, соответствующих каждому суставу руки в трехмерном пространстве. Такое представление обеспечивает высокую точность, поскольку позволяет детально зафиксировать положение и ориентацию каждого сустава. Эффективность достигается за счет компактности данных — вместо хранения информации о всей геометрии руки, хранится лишь ограниченный набор параметров, описывающих положение и ориентацию ключевых суставов, что снижает вычислительную нагрузку и требования к памяти.
Для повышения точности оценки позы головы мы используем GLOMAP и Plücker Embedding. GLOMAP (Globally Optimized Map) обеспечивает глобальную оптимизацию соответствий между признаками, улучшая устойчивость оценки. Plücker Embedding, представляющий собой алгебраический подход к представлению линий и плоскостей, позволяет эффективно кодировать ориентацию головы в пространстве. Комбинация этих методов обеспечивает точную синхронизацию движений рук и головы, что критически важно для реалистичной генерации видео и уменьшения ошибок, связанных с несоответствием поз.
Интегрированный подход к оценке и представлению позы рук позволяет использовать высокоточные и согласованные данные для управления моделью видеодиффузии. В результате тестирования на наборе данных GigaHands зафиксировано снижение среднеквадратичной ошибки проекции суставов (MPJPE) на 10%, среднеквадратичной ошибки проекции вершин (MPVPE) на 11%, а также уменьшение двумерной ошибки на 34%. Данные показатели демонстрируют значительное улучшение точности и реалистичности генерируемых видео с учетом движений рук.

Иммерсивная реальность и производительность системы
Разработанная система генерации реальности, при интеграции с технологией виртуальной реальности, позволяет создавать принципиально новые, захватывающие и интерактивные пользовательские опыты. Она выходит за рамки пассивного наблюдения, предлагая пользователю возможность не просто видеть виртуальный мир, но и активно взаимодействовать с ним, манипулируя объектами и получая мгновенную обратную связь. Это достигается за счет динамической генерации реалистичных сцен и объектов, которые реагируют на действия пользователя в реальном времени, создавая ощущение полного погружения и присутствия в виртуальной среде. Такой подход открывает широкие возможности для применения в различных областях, от развлечений и игр до обучения и профессиональной подготовки.
Система генерирует видеоизображения высокого качества, что обусловлено надежной системой обуславливания по позе. В основе лежит способность точно соотносить изменения в позе с соответствующими изменениями в генерируемом видео, что позволяет создавать реалистичные и правдоподобные сцены. Этот подход позволяет системе эффективно учитывать взаимосвязь между движением и визуальным представлением, обеспечивая высокую степень детализации и плавности в генерируемом контенте. Благодаря этому, система способна достоверно воспроизводить сложные взаимодействия, сохраняя визуальную согласованность даже при динамичных изменениях позы объекта или человека.
Для оценки эффективности системы в обработке сложных взаимодействий рук и объектов проводились испытания с использованием специализированных наборов данных, таких как HOT3D и GigaHands. Эти наборы данных содержат разнообразные сценарии, включающие захват, манипулирование и использование различных предметов, что позволило продемонстрировать способность системы реалистично и точно воспроизводить эти взаимодействия. Результаты тестов показали, что система успешно справляется с задачами, требующими детального понимания геометрии объектов и динамики движений рук, что является ключевым фактором для создания убедительных и интерактивных виртуальных опытов.
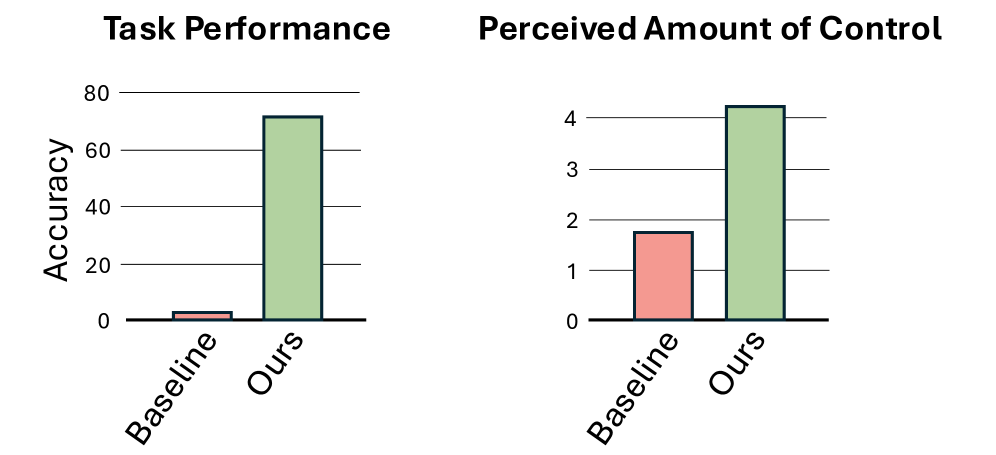
В ходе пользовательского тестирования разработанная система продемонстрировала впечатляющую эффективность: точность выполнения задач составила 71.2%, что значительно превосходит показатель базового уровня в 3.0%. Оценка пользователями ощущения контроля над системой достигла 4.21 балла из 5, в то время как базовая система получила всего 1.74 балла. При этом, система обеспечила задержку обработки в 1.4 секунды при частоте обновления кадров 11 FPS, что свидетельствует о возможности создания плавного и отзывчивого взаимодействия в виртуальной реальности. Полученные результаты подтверждают потенциал системы для широкого спектра приложений, требующих высокой точности и реалистичного взаимодействия с виртуальным окружением.
Для обеспечения плавного и отзывчивого взаимодействия с системой, особое внимание уделяется оптимизации ключевых показателей, таких как интерактивная частота кадров и задержка. Высокая интерактивная частота кадров, измеряемая в кадрах в секунду (FPS), позволяет пользователю воспринимать виртуальную реальность как непрерывную и реалистичную. Одновременно с этим, минимальная задержка — время между действием пользователя и отображением соответствующего ответа в системе — критически важна для предотвращения головокружения и дискомфорта. Тщательная настройка алгоритмов и аппаратного обеспечения направлена на достижение баланса между качеством визуализации и скоростью обработки данных, что позволяет создать действительно погружающий и удобный пользовательский опыт.

Представленная работа демонстрирует очередную попытку создать иллюзию реализма в виртуальной среде. Система, использующая диффузионные видеомодели и отслеживание положения рук и головы, лишь усложняет неизбежное: любые интерактивные симуляции — это компромисс между вычислительными затратами и степенью убедительности. Как заметил Джеффри Хинтон: «Иногда я думаю, что вся наша работа — это просто создание более изощренных способов обмана мозга». В конечном счете, реалистичность взаимодействия не отменяет того факта, что система всегда будет аппроксимацией, а не полноценной заменой реальности. Элегантная теория, безусловно, интересна, но прод всегда найдёт способ заставить её работать с ограниченными ресурсами и причудливыми запросами пользователей.
Куда Поведёт Нас Эта Симуляция?
Представленная работа, безусловно, элегантна в своей постановке. Однако, за каждым новым уровнем интерактивности в сгенерированной реальности, неминуемо вырастет и сложность отладки. Всё это «управление руками и камерой» прекрасно, пока пользователь не решит, что физика мира должна хоть как-то соответствовать здравому смыслу. Заманчиво говорить о «человеко-ориентированной симуляции», но стоит помнить: человечество быстро адаптируется к любым косякам, если они происходят достаточно предсказуемо. А вот непредсказуемость — это всегда головная боль для разработчиков.
Вопрос не в том, насколько реалистично можно сгенерировать видеоряд, а в том, как масштабировать эту систему без потери контроля. Каждый новый «улучшенный» алгоритм 3D-реконструкции рук будет требовать всё больше вычислительных ресурсов. Скоро станет ясно, что дешевле и надёжнее просто нанять аниматора. И не стоит забывать о старом добром «legacy»: иногда лучше монолит, чем сто микросервисов, каждый из которых врёт.
В конечном итоге, успех этой области будет зависеть не от гениальности алгоритмов, а от способности найти баланс между интерактивностью, реализмом и, что самое главное, практичностью. Пока же, это лишь ещё один шаг на пути к созданию идеальной иллюзии, которая, как известно, рано или поздно лопается.
Оригинал статьи: https://arxiv.org/pdf/2602.18422.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Фотографируем муравьёв с Андреем Павловым
- Обзор объектива Tokina 11-16mm f/2.8 AF
- Что купить фотографу. Рекомендации
- Неважно, на что вы фотографируете!
- Honor 600 Pro ОБЗОР: чёткое изображение, отличная камера, плавный интерфейс
- Honor 600 ОБЗОР: лёгкий, плавный интерфейс, скоростная зарядка
- Realme 16T ОБЗОР: яркий экран, плавный интерфейс, большой аккумулятор
- Huawei Mate 80 Pro ОБЗОР: много памяти, большой аккумулятор, огромный накопитель
- Xiaomi 17T ОБЗОР: скоростная зарядка, плавный интерфейс, замедленная съёмка видео
- Калькулятор глубины резкости. Как рассчитать ГРИП.
2026-02-23 11:57