Автор: Денис Аветисян
Новый подход позволяет искусственным агентам непрерывно адаптироваться к меняющимся предпочтениям пользователя, обеспечивая более эффективное взаимодействие в динамичных средах.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
В статье представлена PAHF — платформа для обучения персонализированных агентов, использующая как предварительные уточнения, так и реакцию на действия пользователя для борьбы со смещением предпочтений и поддержания актуальности знаний.
Современные ИИ-агенты, несмотря на свою мощь, часто не учитывают индивидуальные и меняющиеся предпочтения пользователей. В работе ‘Learning Personalized Agents from Human Feedback’ предложен фреймворк PAHF, позволяющий агентам непрерывно обучаться на основе обратной связи от пользователя, используя как проактивные запросы на уточнение, так и реактивные оценки действий. Ключевым результатом является то, что интеграция явной памяти с двухканальной обратной связью значительно ускоряет обучение и позволяет агенту адаптироваться к изменяющимся предпочтениям. Возможно ли создание действительно «умных» агентов, способных предвосхищать и удовлетворять уникальные потребности каждого пользователя в динамичной среде?
Преходящие Предпочтения: Вызов для Персонализации
Традиционные системы рекомендаций часто сталкиваются с проблемой “смещения предпочтений”, заключающейся в неспособности адаптироваться к меняющимся потребностям пользователей. Изначально разработанные для анализа статических профилей, они оказываются неэффективными, когда вкусы и интересы аудитории эволюционируют со временем. Это приводит к снижению релевантности предлагаемого контента, что, в свою очередь, негативно сказывается на пользовательском опыте и может привести к потере интереса к платформе. Постоянное предоставление устаревших или неактуальных рекомендаций не только разочаровывает пользователей, но и подрывает доверие к системе, снижая её ценность и эффективность.
Для достижения эффективной персонализации недостаточно полагаться на статические профили пользователей. Современные системы должны непрерывно обучаться и совершенствовать понимание индивидуальных предпочтений на протяжении времени. Это требует перехода от простого сопоставления шаблонов к сложным алгоритмам, способным отслеживать изменения вкусов и потребностей. Система, способная к динамическому обучению, адаптируется к новым данным и формирует более точные прогнозы, что в конечном итоге приводит к повышению удовлетворенности пользователя и увеличению эффективности рекомендаций. Игнорирование этой необходимости приводит к устареванию профилей и снижению релевантности предлагаемого контента.
Для эффективной персонализации недостаточно простого сопоставления паттернов; системы должны обладать способностью учитывать сложность меняющихся вкусов пользователей. Традиционные алгоритмы, основанные на статических профилях, часто терпят неудачу, поскольку предпочтения со временем эволюционируют. Современные системы стремятся к построению адаптивных моделей, способных не только выявлять текущие интересы, но и предсказывать будущие, учитывая контекст и динамику изменений. Это требует перехода к более сложным методам, таким как рекуррентные нейронные сети и байесовские модели, позволяющие учитывать временные зависимости и неопределенность в предпочтениях. Способность к непрерывному обучению и адаптации становится ключевым фактором успеха в обеспечении релевантности и удовлетворенности пользователей.
Отсутствие надежного механизма отслеживания и реагирования на изменение предпочтений пользователя представляет серьезную угрозу для эффективности персонализированных агентов. Со временем вкусы и потребности индивидуума неизбежно эволюционируют, а статичные профили, лежащие в основе традиционных рекомендательных систем, быстро устаревают. В результате, агенты, не способные адаптироваться к этим изменениям, начинают предлагать нерелевантный контент, что приводит к снижению вовлеченности и, в конечном итоге, к полной утрате доверия со стороны пользователя. Такая неспособность к динамической адаптации не просто снижает качество предоставляемых услуг, но и обесценивает саму концепцию персонализации, превращая её из полезного инструмента в источник раздражения и разочарования.
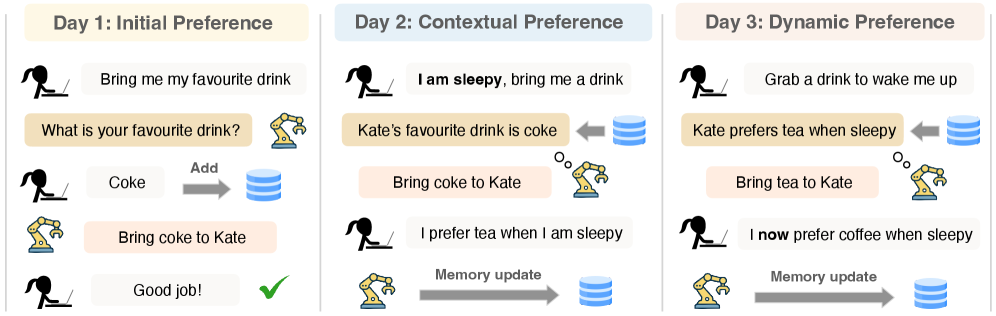
PAHF: Система Непрерывной Персонализации
В основе PAHF лежит решение проблемы смещения предпочтений пользователя (preference drift) посредством непрерывного обучения на взаимодействиях. Система использует два ключевых механизма: проактивную предварительную проверку (pre-action clarification) и интеграцию обратной связи после действия (post-action feedback integration). Предварительная проверка направлена на разрешение неоднозначности до совершения действия, что позволяет системе лучше понять намерения пользователя и минимизировать ошибки. Интеграция обратной связи позволяет PAHF корректировать модель предпочтений пользователя на основе результатов каждого взаимодействия, тем самым повышая точность персонализации с течением времени и адаптируясь к изменяющимся потребностям.
В основе PAHF лежит механизм «Явное хранилище предпочтений пользователя» (Explicit User Memory), представляющий собой систему хранения и обновления индивидуальных предпочтений каждого пользователя. Это хранилище функционирует как динамическая база данных, в которой фиксируются и корректируются предпочтения на основе истории взаимодействий. В отличие от неявных методов определения предпочтений, PAHF использует прямое представление о потребностях пользователя, что позволяет системе генерировать персонализированные ответы и рекомендации с повышенной точностью. Данные в хранилище предпочтений непрерывно обновляются, отражая изменения во вкусах и потребностях пользователя, обеспечивая адаптивность системы к долгосрочным изменениям.
В рамках PAHF, механизм «Предварительного Уточнения» (Pre-Action Clarification) предназначен для проактивного выявления и разрешения неоднозначности в намерениях пользователя перед выполнением какого-либо действия. Это достигается путем запроса дополнительной информации или подтверждения, если система обнаруживает потенциальную неопределенность в интерпретации запроса. Использование данного механизма позволяет минимизировать вероятность ошибок, вызванных неверной интерпретацией, и гарантирует, что выполняемые действия соответствуют фактическим потребностям и ожиданиям пользователя, повышая общую эффективность и точность системы.
Интеграция обратной связи после действия (Post-Action Feedback Integration) в PAHF позволяет системе корректировать свои решения на основе анализа результатов выполненных действий и реакции пользователя. После каждого взаимодействия система получает явный или неявный сигнал об успехе или неудаче предпринятого шага. Этот сигнал используется для обновления модели предпочтений конкретного пользователя в Explicit User Memory. Механизм включает в себя анализ полученной обратной связи для выявления неточностей в предсказаниях и последующую корректировку весов соответствующих параметров модели, что приводит к повышению точности персонализации в будущем и минимизации повторных ошибок.

Под Капотом: Память и Рассуждения
Явное хранение пользовательской памяти в PAHF может быть реализовано с использованием высокопроизводительных векторных баз данных, таких как FAISS, или легковесных SQL-движков, например, SQLite. Выбор между этими подходами обеспечивает гибкость и масштабируемость системы, позволяя адаптировать решение к конкретным требованиям и ресурсам. FAISS оптимизирован для быстрого поиска ближайших соседей в векторном пространстве, что эффективно для хранения и извлечения семантически связанных данных. SQLite, в свою очередь, представляет собой автономную, сервер-не требующую базу данных, подходящую для приложений с ограниченными ресурсами или для локального хранения пользовательских данных. Оба варианта позволяют эффективно управлять и использовать историю взаимодействия с пользователем для персонализации и улучшения качества ответов.
Фреймворк ReAct обеспечивает процесс рассуждений, позволяя агенту чередовать этапы обдумывания и действия, что способствует принятию обоснованных решений с учетом контекста пользователя. Данный подход заключается в итеративном цикле, где агент генерирует цепочку мыслей (Thought), затем предпринимает действие (Action) и, наконец, наблюдает за результатом (Observation). Чередование этих этапов позволяет агенту адаптировать свою стратегию в реальном времени, основываясь на полученной информации, что повышает эффективность решения задач и обеспечивает более гибкое взаимодействие с пользователем.
Рассуждения в системе обеспечиваются мощными большими языковыми моделями (LLM), такими как GPT-4o, которые являются ключевым компонентом, определяющим возможности взаимодействия агента. GPT-4o используется для обработки входных данных, генерации ответов и планирования действий на основе контекста и доступной информации. Его архитектура и параметры позволяют эффективно выполнять сложные задачи, требующие понимания естественного языка и генерации связных и релевантных ответов, что обеспечивает более естественное и эффективное взаимодействие с пользователем.
Проведенная оценка с использованием больших языковых моделей, таких как GPT-4.1, и человеческих симуляторов, включая Llama-4-Scout, подтверждает способность разработанной системы адаптироваться и поддерживать точность персонализации. В ходе третьей фазы тестирования, PAHF демонстрирует 70.5%-ный уровень успешности в задачах, связанных с манипулированием объектами в виртуальной среде, и 68.1% в задачах онлайн-шоппинга. Эти результаты превосходят показатели, достигнутые при использовании подходов, основанных исключительно на предварительных действиях или исключительно на последующих действиях.

Влияние и Перспективы Развития
Разработанный фреймворк PAHF демонстрирует высокую эффективность в различных областях применения, включая персонализированные рекомендации в сфере онлайн-торговли и адаптацию к предпочтениям пользователя в задачах управления физическими объектами. В онлайн-магазинах PAHF позволяет значительно улучшить качество предлагаемых товаров, предвосхищая потребности покупателя на основе анализа его предыдущих действий. В задачах, связанных с управлением роботами или виртуальными агентами в физическом мире, фреймворк успешно адаптируется к индивидуальным манерам и желаниям пользователя, обеспечивая более интуитивное и комфортное взаимодействие. Эта универсальность подчеркивает потенциал PAHF как основы для создания интеллектуальных агентов, способных к эффективной работе в широком спектре сценариев.
Архитектура PAHF демонстрирует исключительную гибкость, выходящую за рамки конкретных применений, и служит надежным фундаментом для создания персонализированных агентов в широком спектре областей. В отличие от систем, ориентированных на узкий набор задач, PAHF позволяет адаптировать поведение агента к индивидуальным предпочтениям пользователя в различных контекстах — от рекомендаций товаров в интернет-магазинах до управления физическими манипуляциями. Такая универсальность достигается благодаря способности системы к обучению на разнообразных данных и динамической адаптации к меняющимся требованиям, что открывает возможности для внедрения персонализированных агентов в такие сферы, как образование, здравоохранение и даже творчество. В результате, PAHF не просто решает отдельные задачи, а формирует основу для создания действительно интеллектуальных систем, способных предугадывать и удовлетворять потребности пользователя в различных аспектах жизни.
Дальнейшие исследования направлены на оптимизацию компонента памяти и внедрение передовых методов рассуждения для повышения точности персонализации. В ходе третьей фазы тестирования, система PAHF продемонстрировала среднюю кумулятивную ошибку персонализации (ACPE) в 0.15 при управлении воплощенными агентами и 0.18 в сфере онлайн-шоппинга. Эти показатели значительно превосходят результаты, полученные с использованием одноканальных подходов, где ACPE составлял 0.22-0.24. Подобное улучшение свидетельствует о потенциале системы в создании действительно адаптивных агентов, способных эффективно учитывать индивидуальные предпочтения пользователей.
Представляется, что разработанная система PAHF способна стать основой для нового поколения действительно интеллектуальных агентов, способных бесшовно адаптироваться к постоянно меняющимся потребностям и предпочтениям пользователей. Благодаря способности к динамическому формированию и использованию персональных профилей, эти агенты смогут предвосхищать желания, предлагать наиболее релевантные решения и обеспечивать индивидуальный подход в самых разнообразных областях — от оптимизации онлайн-шопинга до управления сложными манипуляциями в физическом мире. Перспективы использования PAHF простираются далеко за рамки текущих приложений, открывая путь к созданию универсальных помощников, способных к обучению и адаптации на протяжении всего жизненного цикла взаимодействия с человеком.

Исследование демонстрирует стремление к созданию агентов, способных адаптироваться к изменчивым предпочтениям пользователя. В основе подхода PAHF лежит непрерывное обучение с подкреплением на основе обратной связи, что позволяет агенту уточнять свои действия и избегать ошибок. Как однажды заметил Давид Гильберт: «Мы должны знать. Мы должны знать. Это единственное, что имеет значение». Эта фраза отражает суть работы: постоянное стремление к пониманию предпочтений пользователя и их точное отражение в поведении агента. Сложность, возникающая при адаптации к индивидуальным предпочтениям, требует четкости и ясности в реализации алгоритмов, что, в свою очередь, способствует созданию надежных и эффективных интерактивных агентов.
Что дальше?
Предложенный фреймворк, стремящийся к персонализации агентов посредством обратной связи, не решает, а лишь обнажает главную сложность: непостоянство самого пользователя. Захват «предпочтений» — занятие, по сути, иллюзорное, поскольку эти предпочтения подвержены влиянию времени, контекста и, что самое главное, самообмана. Идея «проактивного уточнения» выглядит разумной, но она лишь откладывает неизбежное: необходимость агенту признать собственное неведение.
Наиболее интересным направлением представляется не столько совершенствование алгоритмов обучения, сколько разработка механизмов, позволяющих агенту «честно» сообщать о своей неуверенности. Вместо того чтобы упорно «угадывать» желания пользователя, агенту следует научиться задавать правильные вопросы и признавать границы своей компетенции. Это потребует отказа от наивной веры в возможность создания «идеального» профиля пользователя.
В конечном счете, успех в этой области зависит не от сложности алгоритмов, а от их простоты и прозрачности. Агент, который умеет признать, что чего-то не знает, окажется гораздо полезнее, чем тот, который пытается казаться всезнающим. Ибо в погоне за «персонализацией» легко забыть о главном: уважении к свободе воли и непредсказуемости человеческой природы.
Оригинал статьи: https://arxiv.org/pdf/2602.16173.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Неважно, на что вы фотографируете!
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Infinix Note 40 Pro+ выставлен на обзор
- Выпущено приложение NVIDIA 11.0.7 с поддержкой DLSS Dynamic Multi Frame Generation и Automatic Shader Compilation
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- Обзор объектива Fujinon XF60mm F2.4 R Macro
- vivo iQOO Z11 Turbo ОБЗОР: огромный накопитель, отличная камера, много памяти
2026-02-19 20:19