Прикосновение, которое слышно: новая эра тактильных сенсоров
Исследователи разработали инновационный метод тактильного восприятия, основанный на анализе звука, возникающего при колебании натянутых струн.
Исследователи разработали инновационный метод тактильного восприятия, основанный на анализе звука, возникающего при колебании натянутых струн.
Инфляция, кстати, поползла вниз – население уже не ждет 13,7%, а довольствуется 13,1% – это отличный знак для ЦБ! Скоро они начнут снижать ставку, а это значит, что деньги станут дешевле, и у нас появится больше возможностей для инвестиций! В общем, геополитика – это конечно, страшно, но и выгодно, если правильно подходить к делу!
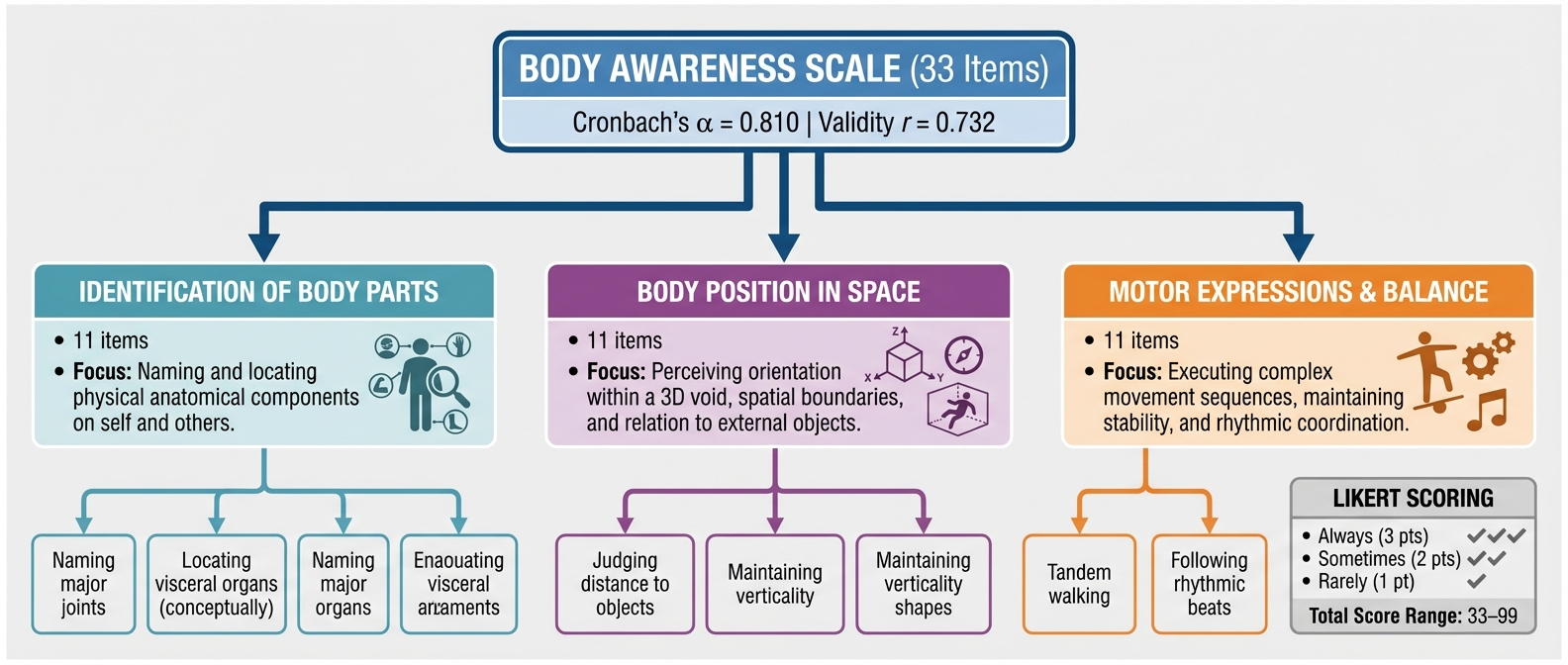
Новое исследование показывает, что специально разработанная программа виртуальной реальности эффективно улучшает осознание тела и психомоторные навыки у детей с синдромом дефицита внимания и гиперактивности.
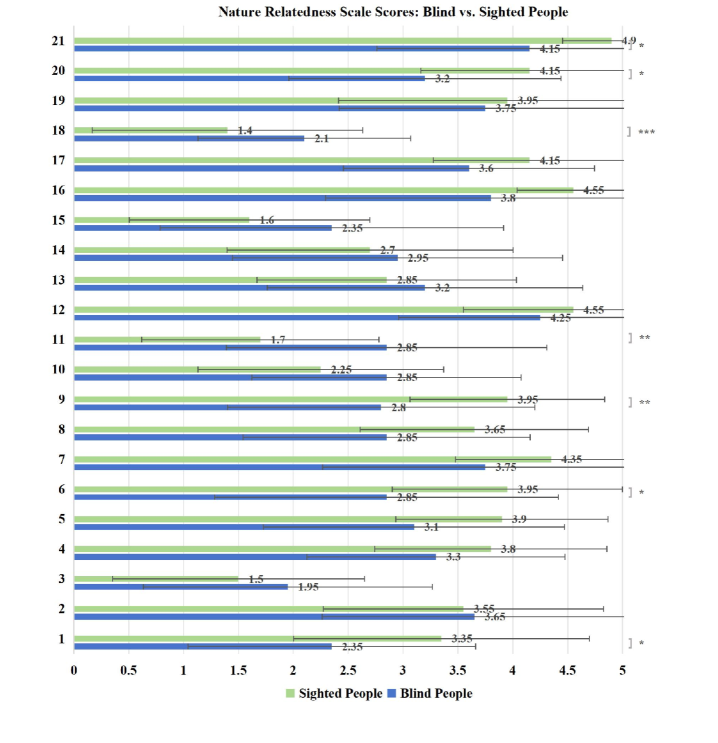
Новое исследование раскрывает особенности взаимодействия незрячих людей с природой и возможности технологий для расширения их сенсорного опыта.

Новое исследование показывает, как незрячие пользователи адаптируют системы визуального вопросно-ответного ИИ для более эффективного взаимодействия с окружающим миром.
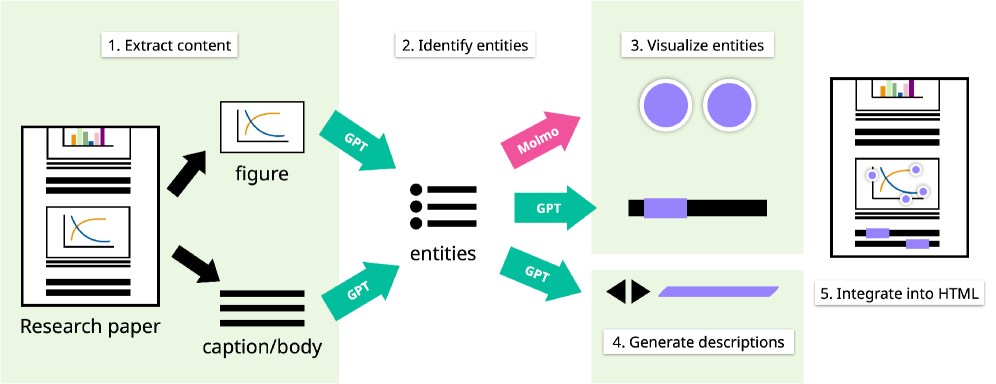
Новая система позволяет находить скрытые связи в сложных документах, значительно улучшая понимание и навигацию по информации.
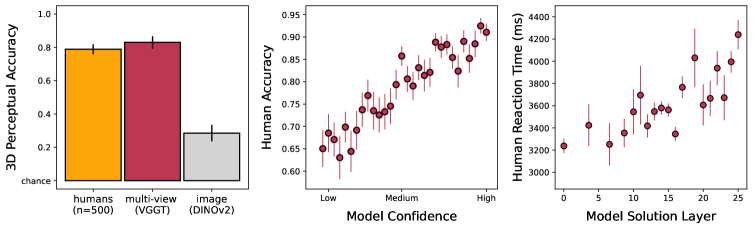
Новая работа показывает, что искусственный интеллект способен достичь человеческого уровня восприятия трехмерных объектов, просто анализируя изображения с разных ракурсов.

Новая система позволяет человеку интуитивно управлять гибридным жестко-мягким роботом, используя возможности дополненной реальности и точную калибровку параметров.
И знаете что? Это не только про Украину. Это про всю мировую экономику. Геополитика, санкции, торговые войны – все это создает туман неопределенности, который мешает росту. Все эти «позитивные» новости – это просто попытки заливают в уши сказки о том, что все хорошо. На самом деле, все гораздо хуже. Мы видим, как инфляция продолжает расти, как процентные ставки повышаются, как долги накапливаются. И что самое главное, никто не предпринимает никаких серьезных мер для решения этих проблем. Все просто надеются, что как-то само собой уладится. Наивные.
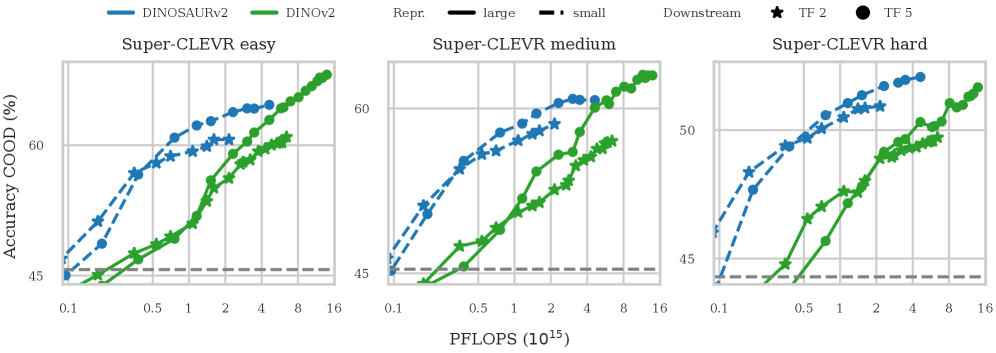
Новое исследование показывает, что представление изображений как отдельных объектов значительно улучшает способность моделей обобщать новые комбинации элементов, особенно при ограниченных данных и вычислительных ресурсах.