Мозг как оркестр: новая модель для декодирования речи по ЭЭГ
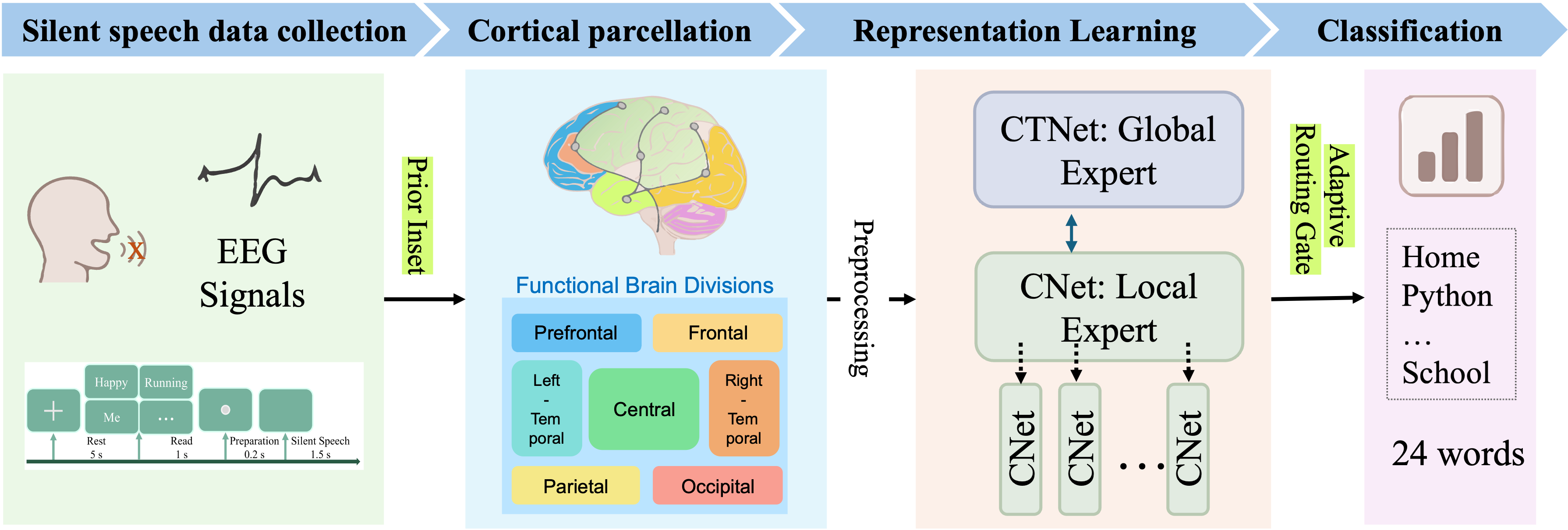
Исследователи разработали инновационную систему, использующую принципы функциональной модульности мозга для более точного распознавания невысказанной речи на основе данных электроэнцефалограммы.
![Наблюдается сравнение производительности предложенных методов с кодеком x265 LDP и подходом на основе NeRF, при этом варианты с использованием несжатой ([latex]UC[/latex]) и сжатой ([latex]C[/latex]) моделями лица, квантованными с точностью 8 и 10 бит, демонстрируют различные уровни эффективности при кодировании видео с частотой 25 кадров в секунду.](https://arxiv.org/html/2601.21269v1/x5.png)