Автор: Денис Аветисян
Исследование предлагает переосмыслить задачу выделения значимых объектов, моделируя человеческое восприятие и учитывая индивидуальные предпочтения наблюдателя.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"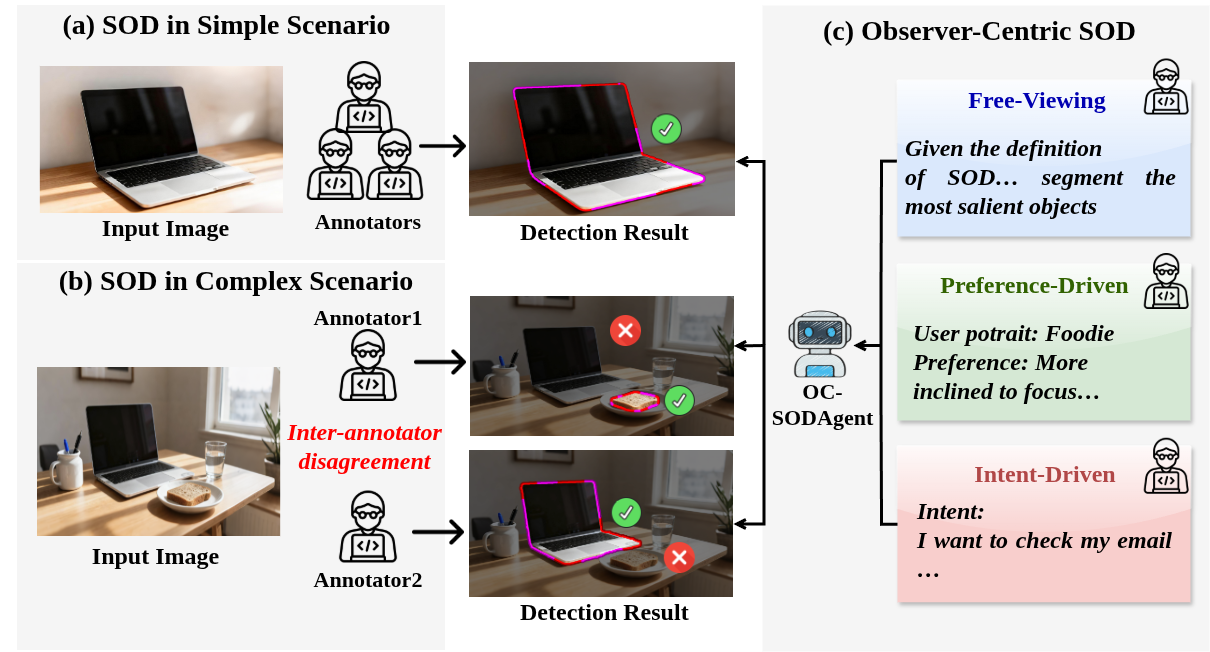
В статье представлен новый датасет и агентская структура, позволяющие более реалистично моделировать визуальное внимание и контекстуальное рассуждение.
Существующие подходы к выделению заметных объектов часто рассматривают задачу как объективное предсказание, игнорируя субъективность человеческого восприятия. В данной работе, ‘Revisiting Salient Object Detection from an Observer-Centric Perspective’, предложен новый подход, учитывающий индивидуальные предпочтения и намерения наблюдателя при определении заметности объектов. Для реализации этой концепции разработан датасет OC-SODBench, включающий 33 тысячи изображений с 152 тысячами текстовых подсказок, и агентский фреймворк OC-SODAgent, имитирующий процесс «Восприятие-Отражение-Корректировка». Не позволит ли это переосмысление принципов выделения заметных объектов создать более реалистичные и гибкие модели, приближенные к человеческому зрению?
За пределами Пикселей: Понимание Субъективного Зрения
Традиционные методы обнаружения заметных объектов в компьютерном зрении часто рассматривают сцену как нечто универсально значимое, игнорируя фундаментальную роль наблюдателя. Вместо того чтобы учитывать индивидуальные потребности, намерения или предшествующие знания, эти системы стремятся выделить объекты, которые статистически отличаются от окружения. Однако, человеческое зрение принципиально контекстуально — внимание избирательно фокусируется на элементах, релевантных текущей задаче или внутренним предпочтениям. Подобный подход, не учитывающий субъективность восприятия, ограничивает эффективность существующих алгоритмов в реальных приложениях, где требуется не просто обнаружить объект, а понять его значимость в конкретной ситуации для конкретного наблюдателя. Поэтому, разработка систем, способных моделировать observer-centric vision, является ключевым шагом к созданию более интеллектуальных и адаптивных систем компьютерного зрения.
Человеческое зрительное внимание не является пассивным процессом регистрации света, а активно формируется контекстом, личными предпочтениями и предшествующим опытом. Исследования показывают, что восприятие одного и того же визуального стимула существенно различается в зависимости от текущих намерений наблюдателя и его багажа знаний. Например, человек, ищущий определенный объект, будет избирательно фокусироваться на признаках, связанных с этим объектом, игнорируя остальную информацию. Более того, предшествующий опыт и ожидания формируют предсказующие модели, которые влияют на то, какие области изображения привлекают внимание. Таким образом, зрительное восприятие является динамическим процессом, в котором мозг активно конструирует реальность, а не просто ее отражает, что делает понимание этой контекстуальности критически важным для создания действительно интеллектуальных систем компьютерного зрения.
Существующие методы обнаружения заметных объектов зачастую оказываются недостаточно эффективными в практических приложениях, требующих глубокого понимания контекста. Это связано с тем, что они игнорируют ключевую роль наблюдателя и его индивидуальных особенностей восприятия. В то время как человек автоматически фокусируется на элементах, соответствующих его намерениям и предыдущему опыту, алгоритмы машинного зрения обрабатывают сцену как универсальную и объективную реальность. В результате, системы могут выделять несущественные детали или упускать из виду критически важные, что существенно ограничивает их применимость в областях, таких как автономное вождение, робототехника или анализ медицинских изображений, где нюансы восприятия играют решающую роль. Неспособность учитывать субъективный фактор, таким образом, является серьезным препятствием для создания действительно интеллектуальных систем компьютерного зрения.

OC-SOD: Моделирование Перспективы Наблюдателя
Традиционные методы выделения заметных объектов (SOD) часто предполагают единую, объективную перспективу. Observer-Centric SOD (OC-SOD) расширяет этот подход, вводя концепцию режимов наблюдения, отражающих различные точки зрения наблюдателя. Выделяются три основных режима: режим, обусловленный намерением (intent-driven), когда внимание сосредоточено на конкретной цели или задаче; режим, обусловленный предпочтениями (preference-driven), учитывающий индивидуальные визуальные предпочтения; и режим свободного просмотра (free-viewing), имитирующий естественное, неструктурированное восприятие. Включение этих режимов позволяет моделировать субъективность восприятия и получать более реалистичные результаты выделения заметных объектов, учитывая контекст и мотивацию наблюдателя.
Для обеспечения эффективной разработки и оценки моделей, ориентированных на точку зрения наблюдателя, был создан крупномасштабный датасет OC-SODBench. Он состоит из 33 тысяч изображений и 152 тысяч пар «инструкция-маска», что позволяет проводить надежное обучение и всестороннюю оценку производительности алгоритмов сегментации объектов, учитывающих различные режимы наблюдения и пользовательские предпочтения. Наличие большого количества размеченных данных критически важно для повышения точности и обобщающей способности моделей в задачах, связанных с пониманием и интерпретацией визуальной информации с учетом контекста и намерений наблюдателя.
Для эффективной аннотации масштабного набора данных OC-SODBench была разработана автоматизированная система, основанная на больших мультимодальных языковых моделях (MLLM). Данный конвейер позволяет существенно снизить трудозатраты на разметку, используя MLLM для генерации инструкций и соответствующих масок сегментации изображений. В процессе автоматической аннотации MLLM анализирует изображение и генерирует текстовое описание, которое затем используется для создания маски, выделяющей объекты, соответствующие описанию. Такой подход обеспечивает высокую скорость и масштабируемость процесса разметки, необходимые для создания и поддержания больших наборов данных для обучения и оценки моделей компьютерного зрения.

OC-SODAgent: Агентный Подход к Динамической Заметности
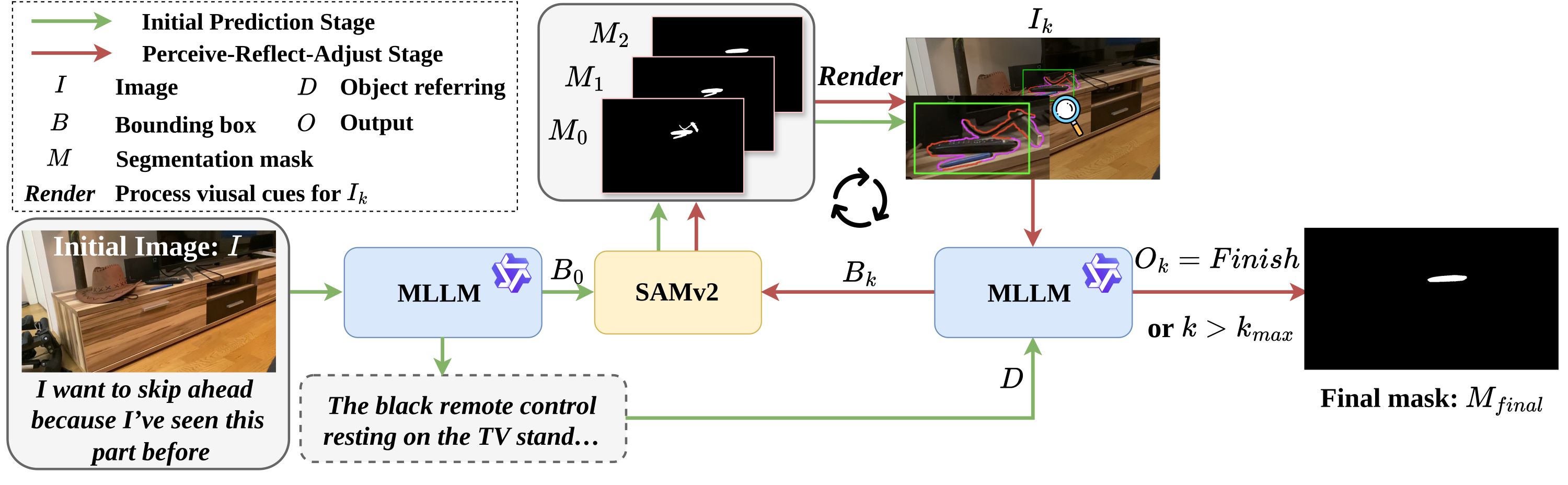
OC-SODAgent использует мультимодальную большую языковую модель (MLLM) и SAMv2 для итеративной доработки прогнозов заметности. MLLM выступает в роли управляющего агента, интерпретирующего инструкции и генерирующего запросы к SAMv2 для сегментации изображения. В процессе итераций, SAMv2 производит сегментацию, а MLLM анализирует результаты и формирует новые инструкции для уточнения сегментации. Этот цикл повторяется до достижения желаемого уровня точности определения заметных областей на изображении, позволяя системе динамически адаптироваться к различным сценариям и входным данным.
В основе уточнения предложений по заметности лежит цикл «Восприятие-Размышление-Корректировка», в котором многомодальная большая языковая модель (MLLM) интерпретирует инструкции и направляет сегментацию с помощью SAMv2. MLLM анализирует текущее изображение и задачу, генерируя команды для SAMv2, определяющие область сегментации. Результат сегментации возвращается в MLLM для оценки и итеративной корректировки, позволяя агенту динамически адаптировать свою стратегию выделения заметных объектов. Этот цикл повторяется до достижения оптимального результата сегментации, соответствующего заданным инструкциям и контексту изображения.
В ходе экспериментов, агентный подход OC-SODAgent продемонстрировал превосходство в задачах динамической заметности в различных режимах работы. В режиме свободного просмотра (free-viewing), при заданных намерениях (intent-driven) и с учетом предпочтений пользователя (preference-driven), OC-SODAgent показал улучшенные результаты по сравнению с базовыми моделями. Улучшения были количественно оценены по метрикам точности: SmS (Saliency Metric Score), Fm (F-measure) и Em (Earth Mover’s Distance), что подтверждает эффективность предложенного агентного подхода в задачах определения заметности.
Рассуждающая Сегментация: К Контекстуальному Пониманию
OC-SODAgent представляет собой воплощение принципов Рассуждающей Сегментации — инновационного подхода, объединяющего обработку естественного языка и компьютерное зрение для более глубокого понимания сцены. В отличие от традиционных методов, фокусирующихся исключительно на обнаружении объектов, данная система стремится к комплексному осмыслению визуальной информации, учитывая не только что изображено, но и почему это конкретное изображение является значимым. Используя лингвистические подсказки и контекстную информацию, OC-SODAgent способен формировать более полное и детализированное представление о сцене, выходя за рамки простого определения объектов и приближаясь к уровню человеческого восприятия и понимания. Такой подход открывает новые возможности для развития систем компьютерного зрения, способных не просто «видеть», но и «понимать» окружающий мир.
Сравнительный анализ OC-SODAgent с существующими моделями, такими как LISA и MMR, выявил значительные преимущества, связанные с учетом контекста наблюдателя. В отличие от традиционных подходов, фокусирующихся исключительно на выявлении заметных объектов, данная разработка позволяет моделировать восприятие сцены с точки зрения конкретного наблюдателя. Это достигается за счет интеграции информации о положении, целях и даже предполагаемых знаниях наблюдателя, что приводит к более точному определению значимости объектов в контексте конкретной ситуации. Полученные результаты демонстрируют, что учет контекста наблюдателя существенно повышает эффективность выделения наиболее релевантных элементов сцены, что открывает новые возможности для применения в таких областях, как робототехника, компьютерное зрение и анализ изображений.
Данный подход выходит за рамки простого определения заметных объектов на изображении, стремясь к пониманию причин их заметности с конкретной точки зрения. Вместо констатации факта «что» привлекает внимание, система анализирует «почему» данный объект выделяется именно для наблюдателя, находящегося в определенной позиции и с определенной целью. Это достигается путем моделирования контекста наблюдения, что позволяет учитывать не только визуальные характеристики объекта, но и его значимость в текущей ситуации. Такой уровень понимания позволяет создавать более интеллектуальные и адаптивные системы компьютерного зрения, способные не просто «видеть», но и «интерпретировать» окружающий мир подобно человеку.

Исследование, представленное в статье, фокусируется на моделировании человеческого внимания посредством нового подхода к обнаружению заметных объектов. Авторы предлагают агентскую структуру и соответствующий набор данных, чтобы преодолеть ограничения существующих методов, основанных на объективных метриках. Данная работа подчеркивает важность учета индивидуальных предпочтений и намерений наблюдателя при анализе визуальной информации. Как однажды заметил Джеффри Хинтон: «Я думаю, что мы находимся в начале пути к созданию машин, которые действительно могут понимать мир так, как это делаем мы». Эта мысль особенно актуальна в контексте данного исследования, поскольку оно стремится приблизить машины к пониманию субъективной значимости объектов для конкретного наблюдателя, тем самым расширяя возможности контекстуального рассуждения и визуального внимания.
Что дальше?
Представленная работа, хотя и предлагает свежий взгляд на обнаружение заметных объектов, лишь подчёркивает сложность моделирования субъективного восприятия. Замена объективных метрик на попытки имитации намерений наблюдателя — шаг, безусловно, интересный, но требующий дальнейшей верификации. Неизбежно возникает вопрос: насколько адекватно созданный агент отражает реальную сложность человеческого внимания? Полагаться на аннотации, даже полученные с учётом индивидуальных предпочтений, — всё равно что пытаться уловить ускользающую тень.
Перспективы развития, очевидно, лежат в области расширения наборов данных и углубления моделей агентской логики. Необходимо исследовать, как контекстуальные факторы, выходящие за рамки визуальной информации, влияют на восприятие заметности. Впрочем, не стоит забывать, что сама идея “заметности” может быть иллюзией, порожденной ограничениями когнитивных возможностей.
В конечном итоге, истинный прогресс, возможно, заключается не в создании идеального алгоритма обнаружения заметных объектов, а в более глубоком понимании того, что вообще означает “видеть” и как субъективный опыт формирует наше представление о реальности. Наблюдение за наблюдателем — задача, требующая не только вычислительной мощности, но и философской проницательности.
Оригинал статьи: https://arxiv.org/pdf/2602.06369.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Макросъемка
- Российский рынок: между ставкой ЦБ, геополитикой и отчетами компаний (25.03.2026 17:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Мозг и Искусственный Интеллект: Общая Система Координат
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
- От фотографий к фильмам: полное руководство по переходу на видеосъемку
2026-02-10 02:23