Автор: Денис Аветисян
Новое исследование предлагает подход к обучению компьютерного зрения понимать сложные концепции, выраженные в естественном языке, напрямую связывая слова с конкретными областями на изображениях.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
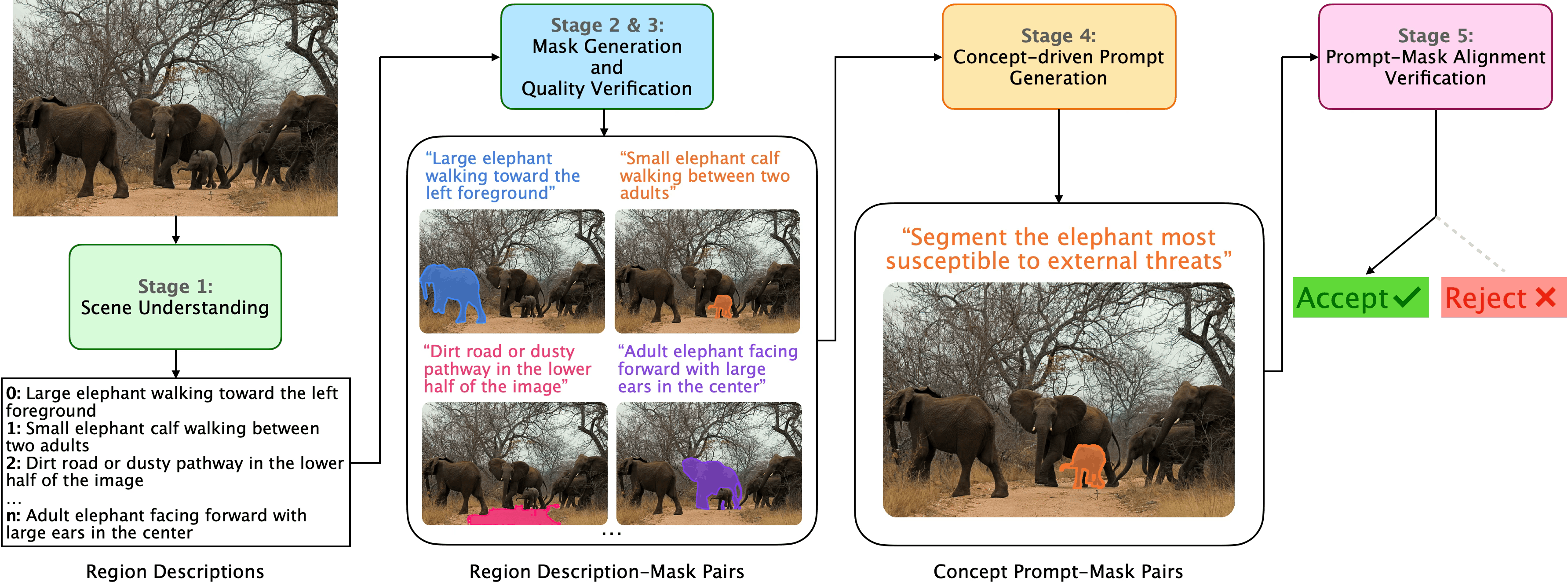
Представлена задача и эталонный набор данных Conversational Image Segmentation (CIS), а также модель ConverSeg-Net для эффективного сопоставления текстовых запросов с сегментацией изображений.
Существующие подходы к сегментации изображений по языковым запросам зачастую не учитывают сложные, абстрактные концепции, выходящие за рамки простых категорий и пространственных отношений. В работе ‘Conversational Image Segmentation: Grounding Abstract Concepts with Scalable Supervision’ предложен новый подход к задаче диалоговой сегментации изображений, направленный на понимание намерений и рассуждений, связанных с функциональностью, безопасностью и физическими свойствами объектов. Авторы представляют новый бенчмарк ConverSeg и модель ConverSeg-Net, демонстрирующую значительное превосходство в понимании подобных запросов благодаря использованию синтезированных данных и объединению сегментационных признаков с лингвистическим анализом. Какие перспективы открывает развитие подобных систем для создания более интуитивных и интеллектуальных интерфейсов взаимодействия человека и компьютера?
За гранью простого распознавания: Диалог с изображением
Традиционные методы сегментации изображений, как правило, концентрируются исключительно на определении что изображено на картинке — например, “автомобиль”, “человек”, или “дерево”. Однако, этот подход зачастую оказывается недостаточным для полноценного понимания сцены. Он не позволяет ответить на вопросы о том, как объекты взаимодействуют друг с другом, или почему они расположены именно таким образом. В результате, классическая сегментация упускает важные нюансы, необходимые для построения действительно осмысленной картины происходящего. Это ограничивает возможности применения в сложных сценариях, где контекст и взаимосвязи играют ключевую роль, например, в робототехнике или автономном вождении.
Появление диалоговой сегментации изображений (CIS) знаменует собой существенный шаг вперед по сравнению с традиционными подходами. В отличие от простого определения что изображено на картинке, CIS требует от моделей понимания не только объектов, но и их пространственных взаимосвязей, а также потенциальных возможностей использования этих объектов — их аффордансов. Это означает, что модель должна не просто выделить объект, но и осознавать, как он взаимодействует с окружением и какие действия с ним возможны. Например, CIS способна определить не просто «стул», а «стул, на котором можно сидеть» или «стул, который можно передвинуть», что открывает возможности для более сложных и осмысленных взаимодействий с изображениями и создания действительно интеллектуальных систем компьютерного зрения.
В отличие от традиционной сегментации изображений, которая сосредотачивается исключительно на идентификации объектов, разговорная сегментация изображений (CIS) требует от моделей более глубокого понимания контекста и способности к рассуждению о сцене. Речь идет не просто о том, что изображено, но и о как эти объекты взаимодействуют друг с другом и почему они расположены именно таким образом. Для успешного выполнения задач, требующих CIS, модели должны уметь учитывать пространственные отношения, функциональные возможности объектов и общую ситуацию, представленную на изображении. Такой подход позволяет преодолеть ограничения простой классификации и приблизиться к пониманию изображений на уровне, сопоставимом с человеческим восприятием, что открывает новые возможности для взаимодействия человека и компьютера.

Автоматизированная генерация данных: Ускорение прогресса CIS
Обучение надежных моделей компьютерного зрения (CIS) требует значительных объемов размеченных данных, что часто является ограничивающим фактором. Необходимость в больших размеченных наборах данных обусловлена потребностью в обобщении модели и обеспечении ее устойчивости к различным условиям и вариациям в данных. Процесс ручной разметки данных является трудоемким, дорогостоящим и подвержен ошибкам, что затрудняет масштабирование и развитие моделей CIS. Для решения этой проблемы разработаны автоматизированные системы генерации данных, способные создавать размеченные данные с минимальным участием человека, тем самым снижая затраты и ускоряя процесс обучения моделей.
Автоматизированный генератор данных использует возможности моделей «Зрение-Язык» (Vision-Language Models, VLMs) и SAM2 для создания пар «запрос-маска» высокого качества. VLMs позволяют генерировать текстовые запросы, описывающие целевые объекты на изображениях, а SAM2 (Segment Anything Model 2) использует эти запросы для автоматической генерации соответствующих масок сегментации. Этот процесс значительно снижает потребность в ручной аннотации данных, так как большая часть процесса сегментации выполняется автоматически, что приводит к существенной экономии затрат и времени на создание размеченных наборов данных.
Автоматизированный движок генерации данных обучается на наборе данных COCO, что обеспечивает прочную основу для понимания разнообразных сцен и обобщения полученных знаний. В результате обучения и автоматической генерации сформирован набор из 106 тысяч пар «изображение-маска». Использование COCO в качестве обучающей выборки позволяет движку эффективно работать с широким спектром объектов, сложных композиций и различных условий освещения, что необходимо для создания реалистичных и разнообразных синтетических данных.
ConverSeg-Net: Модель для диалогового понимания
Модель ConverSeg-Net, построенная на базе мультимодальной языковой модели Qwen2.5-VL-3B, демонстрирует передовые результаты на бенчмарке ConverSeg, предназначенном для оценки понимания диалогов и сегментации изображений. Набор данных SAM-seeded split был использован для оценки, где модель достигла показателя gIoU (Intersection over Union) в 70.8%. Данный результат подтверждает эффективность архитектуры и используемых методов обучения для решения задач, требующих понимания контекста диалога и точной сегментации соответствующих объектов на изображении.
Для адаптации к задачам понимания диалогов в модели ConverSeg-Net применяется метод LoRA (Low-Rank Adaptation), позволяющий проводить параметро-эффективную тонкую настройку. Вместо обновления всех параметров предобученной модели Qwen2.5-VL-3B, LoRA вводит небольшое количество обучаемых параметров, что значительно снижает вычислительные затраты и требования к объему видеопамяти. Это позволяет эффективно адаптировать модель к специфике диалоговых данных, сохраняя при этом большую часть знаний, полученных в процессе предварительного обучения, и избегая переобучения.
Обучение модели на наборе данных RefCOCO значительно улучшило её способность к пониманию референциальных выражений в контексте диалога. Это позволило достичь превосходства над моделью Seg-Zero с отрывом в +1.6% на SAM-seeded подмножестве тестового набора данных ConverSeg, что подтверждает эффективность использования RefCOCO для улучшения понимания диалоговых запросов, требующих идентификации объектов по описаниям.

Расширяя горизонты: Влияние на интеллектуальные системы
Слияние автоматической генерации данных и передовых визуально-языковых моделей, таких как ConverSeg-Net, значительно расширяет горизонты понимания изображений. Автоматизированное создание разнообразных и тщательно размеченных наборов данных позволяет обучать модели, способные к более тонкому и комплексному анализу визуальной информации. ConverSeg-Net, благодаря своей архитектуре, демонстрирует впечатляющую способность к сегментации изображений на основе текстовых запросов, превосходя традиционные подходы и открывая новые возможности для взаимодействия человека с машиной. Такое сочетание позволяет не только распознавать объекты на изображениях, но и понимать их взаимосвязи, контекст и даже потенциальные действия, что является ключевым шагом на пути к созданию действительно интеллектуальных систем.
Система комплексного понимания изображений (CIS) значительно превосходит традиционную сегментацию изображений по запросу (RIS), предлагая более глубокий и тонкий подход к взаимодействию изображения и языка. В то время как RIS фокусируется исключительно на выделении конкретных объектов, указанных в текстовом запросе, CIS стремится к полному пониманию сцены, включая отношения между объектами, их атрибуты и контекст. Это достигается за счет интеграции различных модальностей данных и использования сложных алгоритмов, позволяющих системе не просто идентифицировать объекты, но и интерпретировать их роль и значение в общей картине. Благодаря этому, CIS способна отвечать на более сложные вопросы, выполнять более детализированные инструкции и демонстрировать более естественное и интуитивно понятное взаимодействие с пользователем, открывая новые возможности для интеллектуальных систем.
Способность систем к анализу сцен, пониманию возможностей взаимодействия с объектами и интерпретации инструкций открывает новые горизонты для практического применения в различных областях. В робототехнике это позволяет создавать более автономных и адаптивных роботов, способных выполнять сложные задачи в реальных условиях. В дополнение, в сфере дополненной реальности, подобное понимание позволяет создавать более реалистичные и интерактивные виртуальные среды, реагирующие на действия пользователя. Особенно значимым представляется применение в ассистивных технологиях, где системы могут предоставлять поддержку и помощь людям с ограниченными возможностями, например, описывая окружение или помогая в выполнении повседневных задач, основываясь на полученных инструкциях и понимании контекста окружающей среды.

Исследование Conversational Image Segmentation (CIS) подтверждает, что даже самые сложные модели — это лишь попытки упорядочить хаос визуальной информации. Подобно тому, как алхимик пытается извлечь суть из материи, авторы статьи стремятся связать абстрактные концепции, выраженные в диалоге, с конкретными объектами на изображении. Этот процесс требует не просто распознавания объектов, но и понимания их взаимосвязей и потенциальных действий — affordances, как их называют. Фей-Фей Ли однажды заметила: «Технологии должны расширять возможности человека, а не заменять его». Данная работа как раз и направлена на расширение возможностей моделей компьютерного зрения, позволяя им не просто видеть, но и понимать контекст, что приближает их к человеческому восприятию мира. Модель ConverSeg-Net, представленная в статье, — это заклинание, которое работает, пока не встретит новую, непредсказуемую ситуацию, и тогда потребуется новая жертва — новые данные для обучения.
Куда же дальше?
Представленная работа, конечно, призывает к разговору с изображениями, но стоит помнить: любая «разговорчивость» — это лишь искусно подобранные заклинания, призванные заставить пиксели подчиниться воле исследователя. Задача «привязки» абстрактных понятий к конкретным областям изображения — не более чем иллюзия контроля над хаосом, и наивное ожидание, что данные «сами всё расскажут». Ведь, по сути, эта «привязка» — всего лишь утончённая форма предвзятости, замаскированная под объективность.
Следующим шагом, вероятно, станет усложнение заклинаний, создание моделей, способных поддерживать более длинные и запутанные «разговоры». Но стоит помнить: чем сложнее заклинание, тем тоньше грань между пониманием и имитацией. Вопрос не в том, чтобы научить машину «видеть» абстракции, а в том, чтобы научиться интерпретировать её ошибки как новые формы информации — ведь именно в них, в этих «сбоях», и кроется истинное откровение.
Истинный вызов — не в создании «разговорчивых» изображений, а в признании того, что любое изображение — это всегда лишь фрагмент реальности, отражённый в кривом зеркале вероятности. И любая «привязка» — это лишь временное перемирие с этой неуловимой истиной.
Оригинал статьи: https://arxiv.org/pdf/2602.13195.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Неважно, на что вы фотографируете!
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- vivo iQOO Z11 Turbo ОБЗОР: огромный накопитель, отличная камера, много памяти
- MSI Katana 17 HX B14WGK ОБЗОР
- Как правильно фотографировать ночью
- Что такое глубина резкости в фотографии?
- КАЛЕЙНАР-5Н
2026-02-16 21:44