Автор: Денис Аветисян
Исследователи представили InfoSculpt — инновационную систему, способную эффективно выявлять и структурировать категории данных даже в незнакомых условиях.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"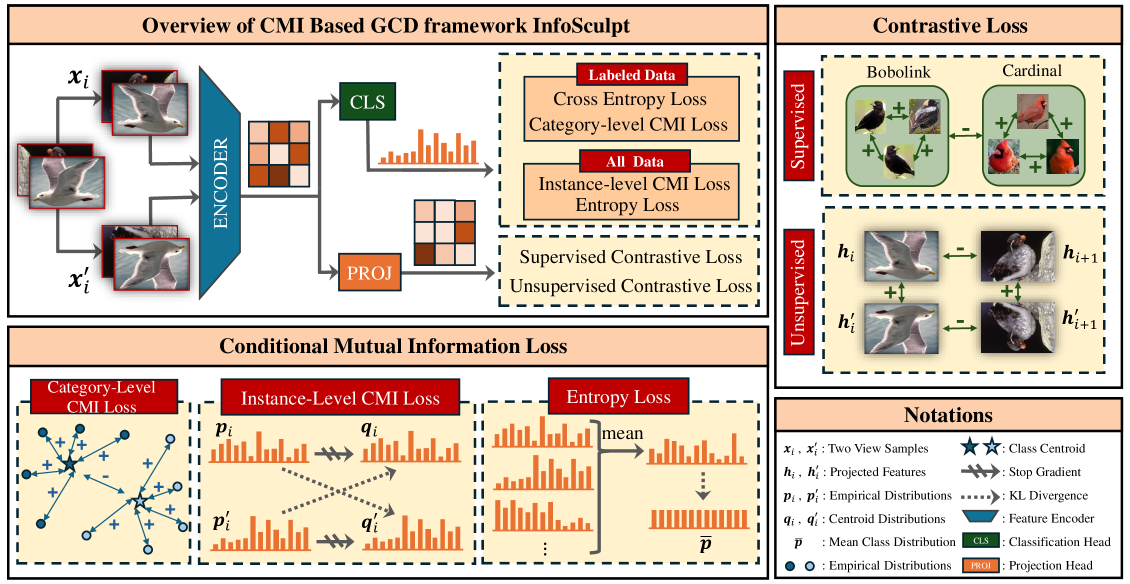
Предложен фреймворк InfoSculpt, использующий двойную цель на основе условной взаимной информации для создания устойчивого и разделенного скрытого пространства, что улучшает обобщающую способность в задачах открытого обучения.
Обнаружение обобщенных категорий в неразмеченных данных представляет собой сложную задачу, особенно в условиях открытого мира, где заранее неизвестны все категории. В данной работе представлена новая методика ‘InfoSculpt: Sculpting the Latent Space for Generalized Category Discovery’, основанная на принципах информационного «бутылочного горлышка» и направленная на формирование латентного пространства, устойчивого к шумам и специфическим деталям экземпляров. Предложенный фреймворк InfoSculpt использует двойную оптимизацию взаимной информации, позволяя эффективно разделять категориальную информацию и отбрасывать нерелевантные признаки. Способна ли такая «скульптура» латентного пространства открыть новые горизонты в задачах обучения без учителя и адаптации к меняющимся данным?
Преодолевая Границы: Открывая Новые Категории в Данных
Традиционные методы обучения с учителем демонстрируют высокую эффективность при работе с размеченными данными, однако испытывают значительные трудности в решении задачи открытия новых, ранее неизвестных категорий. Эти алгоритмы, будучи оптимизированы для классификации объектов по предопределенным меткам, не способны самостоятельно выявлять скрытые закономерности и формировать новые концепции. В ситуациях, когда данные поступают без предварительной разметки или содержат неожиданные кластеры, производительность таких систем резко снижается, поскольку они не приспособлены к работе с неопределенностью и требуют постоянного вмешательства человека для расширения базы знаний. Данное ограничение существенно препятствует автоматизации процесса анализа данных и исследованию сложных, неструктурированных наборов информации.
Обобщенное обнаружение категорий (GCD) представляет собой перспективное направление в машинном обучении, стремящееся преодолеть ограничения традиционных подходов, требующих предварительно размеченных данных. В отличие от них, GCD нацелено на выявление как известных, так и ранее не встречавшихся категорий внутри сложных наборов данных. Это достигается путем разработки алгоритмов, способных самостоятельно структурировать информацию и выделять значимые кластеры, не полагаясь на внешние метки. Такой подход особенно важен в ситуациях, когда размеченные данные ограничены или недоступны, например, при анализе больших объемов неструктурированной информации или в задачах, требующих адаптации к новым, неожиданным категориям. В перспективе GCD может значительно расширить возможности машинного обучения в различных областях, от автоматической классификации изображений до обнаружения аномалий и анализа научных данных.
Существующие методы обобщенного обнаружения категорий (GCD) часто демонстрируют ограниченную эффективность из-за недостаточного качества представления данных и слабой способности к обобщению. В частности, многие алгоритмы испытывают трудности с извлечением значимых признаков, позволяющих четко разграничить известные и неизвестные классы объектов, что приводит к высокой частоте ложных срабатываний и упущению новых категорий. Это связано с тем, что существующие подходы зачастую полагаются на предварительно заданные параметры или не учитывают сложность и многомерность реальных данных. В результате, модели, обученные на ограниченном наборе данных, не способны эффективно адаптироваться к новым, ранее не встречавшимся ситуациям, что снижает их практическую ценность и ограничивает возможности применения в задачах, требующих автоматического обнаружения и классификации неизвестных объектов.
InfoSculpt: Формируя Представления с Помощью Условной Взаимной Информации
Метод InfoSculpt использует принцип минимизации условной взаимной информации (УВI) I(X;Y|Z) для извлечения существенной информации в пространствах признаков. Минимизация УВI позволяет отфильтровать избыточные детали и сконцентрироваться на наиболее значимых аспектах данных. В контексте InfoSculpt, это достигается путем уменьшения зависимости между признаками и нерелевантными деталями входных данных, тем самым улучшая обобщающую способность модели и ее устойчивость к шуму. В процессе обучения, алгоритм стремится к тому, чтобы представление данных содержало только ту информацию, которая необходима для решения поставленной задачи, отбрасывая все остальное.
Методика InfoSculpt использует комбинированный подход к минимизации условной взаимной информации (CMI). Объектив CMI на уровне категорий заставляет модель абстрагироваться от специфических деталей отдельных экземпляров данных, фокусируясь на общих признаках внутри каждой категории. Параллельно, объектив CMI на уровне экземпляров позволяет использовать немаркированные данные для улучшения обобщающей способности модели, расширяя возможности обучения за счет информации, содержащейся в неразмеченных примерах. Такое сочетание позволяет добиться обучения представлений, которые одновременно дискриминируют различные категории и хорошо обобщаются на новые, ранее не встречавшиеся данные.
Двойная минимизация взаимной информации (CMI) способствует обучению представлений, обладающих как дискриминационными, так и обобщающими способностями. Сочетание категорийного и экземплярного уровней CMI позволяет модели одновременно извлекать признаки, релевантные для классификации (дискриминация), и игнорировать детали, специфичные для отдельных экземпляров (обобщение). Категорийный уровень CMI фокусируется на уменьшении информации об экземпляре, сохраняя при этом информацию о его категории, что стимулирует абстракцию. Экземплярный уровень CMI, расширяемый на неразмеченные данные, дополнительно способствует извлечению полезных признаков, повышая устойчивость модели к новым, ранее не встречавшимся данным. Таким образом, одновременная минимизация на обоих уровнях позволяет получить представления, эффективно работающие в задачах классификации и обладающие высокой способностью к обобщению.
Подтверждение Эффективности: Превосходя Существующие Подходы
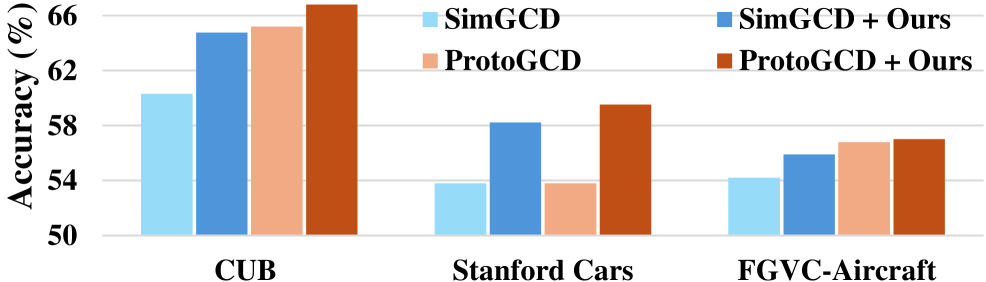
В ходе экспериментов InfoSculpt продемонстрировал передовую точность на 8 стандартных наборах данных для задачи обобщенного обнаружения категорий (Generalized Category Discovery), значительно превзойдя существующие методы, такие как SimGCD и ProtoGCD. Результаты показывают существенное улучшение производительности по сравнению с альтернативными подходами в данной области, подтверждая эффективность предложенной архитектуры и алгоритмов обучения. Данное превосходство наблюдается на различных наборах данных, что свидетельствует об устойчивости и обобщающей способности InfoSculpt.
В основе InfoSculpt используется Vision Transformer (ViT), предварительно обученный с помощью самообучающегося алгоритма DINO. Предварительное обучение DINO позволяет ViT извлекать высококачественные и репрезентативные визуальные признаки из входных изображений. Эти признаки затем служат входными данными для разработанной нами системы CMI (Category Mining and Inference), что обеспечивает более эффективное обнаружение и классификацию обобщенных категорий. Использование предварительно обученной модели ViT значительно повышает производительность системы InfoSculpt по сравнению с подходами, использующими случайные или непредварительно обученные модели.
В экспериментах на наборе данных Stanford Cars, InfoSculpt продемонстрировал точность в 59.5%, что превосходит результаты, показанные предыдущими передовыми методами в области Generalized Category Discovery. Данный результат подтверждает эффективность предложенного подхода в задачах, требующих высокой точности классификации и обнаружения категорий, особенно в сложных сценариях, представленных в наборе данных Stanford Cars, включающем множество схожих моделей автомобилей.
В ходе экспериментов на наборе данных Herbarium 19, InfoSculpt продемонстрировал повышение точности на 2.9% по сравнению с наиболее эффективным существующим подходом. Этот результат был получен при использовании стандартной методологии оценки и подтверждает эффективность предложенного метода в задачах обнаружения обобщенных категорий, особенно в случаях, когда требуется высокая точность классификации сложных визуальных данных, таких как изображения растений.
На датасете Stanford Cars, InfoSculpt демонстрирует точность в 78.4% при классификации известных классов автомобилей. Этот показатель был достигнут благодаря использованию Vision Transformer, предварительно обученного с помощью DINO, в сочетании с разработанным CMI-based фреймворком. Полученная точность превосходит результаты, демонстрируемые существующими методами в задаче Generalized Category Discovery (GCD) на данном датасете.
Визуализация с использованием t-SNE подтверждает, что InfoSculpt генерирует более компактные и чётко разделенные представления данных. Анализ распределения признаков, полученных InfoSculpt, показывает формирование кластеров, соответствующих категориям, с минимальным перекрытием между ними. Это способствует более точной идентификации и разграничению категорий в процессе Generalized Category Discovery, поскольку компактность представлений снижает вычислительную сложность, а их разделенность обеспечивает более надёжную классификацию и обнаружение новых категорий.
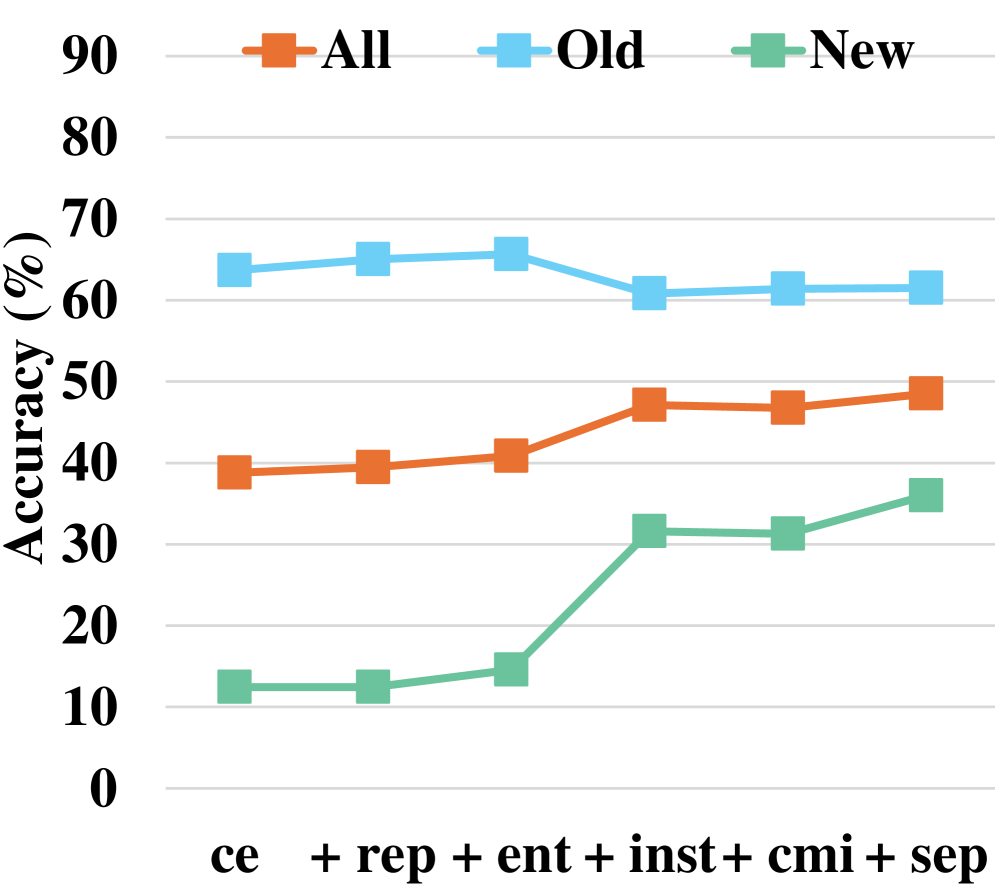
Для предотвращения коллапса модели и оптимизации её производительности в InfoSculpt реализованы регуляризация энтропии и функция потерь перекрестной энтропии. Регуляризация энтропии стимулирует модель генерировать более разнообразные и информативные представления, предотвращая доминирование отдельных признаков. Функция потерь перекрестной энтропии, в свою очередь, способствует более точному разграничению категорий, минимизируя расстояние между точками данных, принадлежащими к одному классу, и максимизируя расстояние между точками разных классов. Комбинация этих двух методов позволяет добиться стабильной работы модели и повышения её точности на различных наборах данных.
Влияние и Перспективы: К Надежному Неконтролируемому Обучению
Успех InfoSculpt ярко демонстрирует эффективность принципов теории информации в создании надежных и минимальных представлений данных. Данная система, используя концепции взаимной информации и минимизации избыточности, способна выделять наиболее существенные характеристики объектов, отбрасывая несущественные детали. Это позволяет формировать компактные и устойчивые к шуму представления, которые особенно ценны при работе с большими объемами неструктурированных данных. В отличие от традиционных методов, InfoSculpt не требует предварительной разметки данных, что значительно расширяет возможности его применения и позволяет автоматически выявлять скрытые закономерности и взаимосвязи, лежащие в основе сложных данных. Такой подход открывает новые перспективы для развития самообучающихся систем и интеллектуального анализа данных, где требуется извлечение знаний из немаркированных источников.
Возможность использования как размеченных, так и неразмеченных данных в рамках InfoSculpt открывает перспективы для масштабирования процесса открытия новых категорий и закономерностей в значительно больших наборах данных. Традиционные методы обучения зачастую ограничены объемом доступных размеченных примеров, что затрудняет их применение к крупномасштабным задачам. Используя неразмеченные данные для предварительного формирования компактных и информативных представлений, InfoSculpt снижает потребность в большом количестве размеченных данных для последующей кластеризации и обнаружения категорий. Это позволяет анализировать огромные объемы информации, ранее недоступные для автоматизированного анализа, и выявлять скрытые зависимости, которые могли бы остаться незамеченными при использовании только размеченных данных. В результате, подход демонстрирует значительный потенциал для решения задач, требующих обработки и анализа больших данных в различных областях, от обработки изображений и естественного языка до биоинформатики и анализа социальных сетей.
Принципы двойной минимизации взаимной информации (Dual CMI Minimization), лежащие в основе InfoSculpt, оказываются применимы не только для обнаружения категорий, но и для решения более широкого спектра задач неконтролируемого обучения. Исследования показывают, что стремление к минимизации избыточности информации и максимизации релевантности позволяет эффективно извлекать полезные представления из данных, даже при отсутствии размеченных примеров. Это открывает перспективы для использования данного подхода в таких областях, как выявление аномалий, где требуется обнаружить необычные паттерны, и обучение с небольшим количеством примеров (few-shot learning) , где необходимо быстро адаптироваться к новым задачам, используя ограниченный набор данных. Таким образом, Dual CMI Minimization представляет собой универсальный инструмент для построения эффективных и устойчивых моделей в условиях неполной информации.
В дальнейшем планируется расширить область применения InfoSculpt, исследуя его эффективность в задачах обнаружения аномалий и обучения с небольшим количеством примеров. Обнаружение аномалий, где алгоритм должен выявлять необычные или нетипичные данные, может быть существенно улучшено за счет способности InfoSculpt выявлять минимальные и информативные представления данных. Аналогично, в сценариях обучения с небольшим количеством примеров, где доступно ограниченное количество размеченных данных, InfoSculpt может использовать неразмеченные данные для улучшения обобщающей способности модели. Исследования в этих направлениях позволят оценить универсальность принципов минимизации двойной взаимной информации и продемонстрировать потенциал InfoSculpt в качестве мощного инструмента для различных задач машинного обучения, требующих эффективного использования данных.
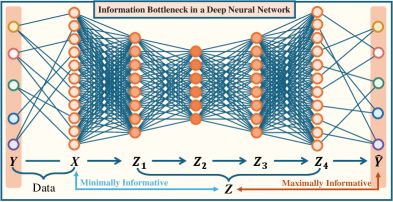
Представленная работа демонстрирует элегантный подход к организации латентного пространства, что особенно важно для обобщенного обнаружения категорий. InfoSculpt, используя двойную функцию условной взаимной информации, словно скульптор, придает форму данным, выделяя наиболее значимые признаки и отбрасывая шум. Это не просто улучшение производительности в открытых сценариях обучения, а стремление к созданию более понятных и интерпретируемых представлений. Как однажды заметил Джеффри Хинтон: «Иногда, чтобы сделать что-то сложное, нужно сделать это простым». Этот принцип находит отражение в InfoSculpt, где простота и ясность структуры латентного пространства служат ключом к обобщению и адаптации к новым, неизвестным категориям.
Куда же дальше?
Представленная работа, стремясь к созданию более скульптурного и, следовательно, более понятного латентного пространства, поднимает вопрос о цене этой “элегантности”. Улучшение обобщающей способности в открытом мире — задача, безусловно, благородная, но не стоит ли эта эффективность излишней сложности? Очевидно, что дальнейшие исследования должны быть направлены на оценку компромисса между выразительностью латентного пространства и его вычислительной доступностью. Нельзя допустить, чтобы стремление к красоте алгоритма затмило его практическую применимость.
Особый интерес представляет возможность адаптации предложенного подхода к задачам, где данные изначально не структурированы по категориям. Как InfoSculpt поведет себя в условиях полной неопределенности, когда даже само понятие “категория” является расплывчатым и субъективным? Или, возможно, истинный путь лежит в отказе от явного определения категорий, позволяя системе самостоятельно формировать представления о мире, исходя из внутренних закономерностей данных?
В конечном счете, успех InfoSculpt, как и любого другого подхода к машинному обучению, будет определяться не только его способностью к обобщению, но и его способностью к эволюции. Необходимо помнить, что мир постоянно меняется, и система, не способная адаптироваться к этим изменениям, обречена на устаревание. Истинная элегантность — это не статичная красота, а динамичная гармония между формой и функцией, способная выдержать испытание временем.
Оригинал статьи: https://arxiv.org/pdf/2601.10098.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- Российский рынок в 2025: Инвестиции, Экспорт и Новые Возможности (27.02.2026 15:32)
- Xiaomi Poco M7 ОБЗОР: плавный интерфейс, удобный сенсор отпечатков, большой аккумулятор
2026-01-17 16:08