Автор: Денис Аветисян
Исследователи представили SLAY — механизм внимания, позволяющий значительно увеличить длину контекста в трансформерах без потери производительности.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"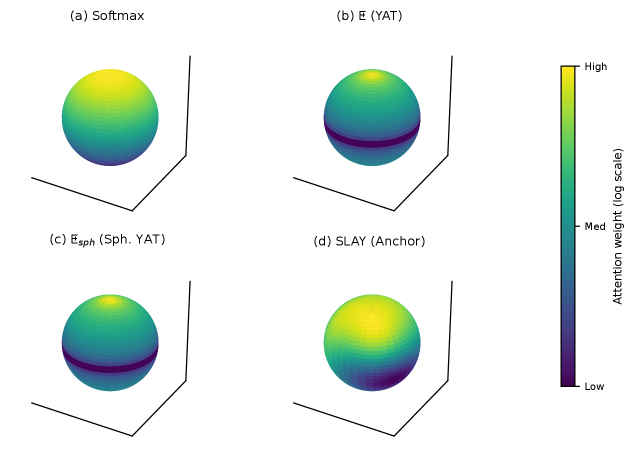
В статье описывается SLAY (Spherical Linearized Attention with Yat-Kernel) — метод линейного внимания, использующий сферическую линеаризацию и ядро Ят для эффективной обработки длинных последовательностей.
Вычислительная сложность механизма внимания в трансформерах ограничивает их применение к задачам с длинными последовательностями. В данной работе представлена новая архитектура, ‘SLAY: Geometry-Aware Spherical Linearized Attention with Yat-Kernel’, предлагающая линейное по времени приближение к стандартному softmax вниманию, основанное на сферической линеаризации и ядре Ят. Предложенный метод, SLAY, обеспечивает производительность, сопоставимую с традиционным вниманием, при значительном снижении вычислительных затрат и сохранении масштабируемости к большим контекстам. Открывает ли SLAY новые перспективы для создания эффективных и масштабируемых трансформеров для обработки данных с высокой размерностью и длинными зависимостями?
Квадратичная Сложность Внимания: Узкое Место Современных Моделей
Архитектура Transformer, несмотря на свою мощь и широкое применение, базируется на механизме внимания, который по своей сути страдает от квадратичной сложности. Это означает, что вычислительные затраты и объем памяти, необходимые для обработки последовательности, растут пропорционально квадрату ее длины O(n^2). В результате, при увеличении длины входной последовательности, вычисления становятся экспоненциально более трудоемкими, что создает серьезные ограничения для обработки длинных текстов, видео или других типов данных. Данная квадратичная зависимость представляет собой фундаментальное препятствие для масштабирования Transformer-моделей и их эффективного применения в задачах, требующих анализа больших объемов информации, что стимулирует поиск альтернативных подходов к механизмам внимания, направленных на снижение вычислительной сложности.
Квадратичная сложность механизма внимания существенно ограничивает возможности обработки длинных последовательностей в архитектуре Transformer. По мере увеличения длины входных данных, вычислительные затраты растут пропорционально квадрату этой длины, что быстро становится непомерным бременем для ресурсов. Данное ограничение особенно критично при решении сложных задач, требующих анализа больших объемов информации, таких как обработка длинных текстов, видео или геномных данных. В результате, производительность модели ухудшается, а возможности масштабирования становятся ограниченными, что препятствует применению Transformer в задачах, требующих анализа контекста большой глубины и продолжительности.
Традиционные механизмы внимания, лежащие в основе современных нейронных сетей, сталкиваются с серьезными ограничениями при обработке длинных последовательностей данных. Сложность вычислений возрастает пропорционально квадрату длины последовательности O(n^2), что делает обработку больших объемов информации крайне затратной и неэффективной. По мере увеличения длины входных данных, потребность в вычислительных ресурсах и времени обработки растет экспоненциально, что существенно ограничивает масштабируемость моделей и препятствует их применению в задачах, требующих анализа обширных текстов, видео или других последовательных данных. Это препятствие вынуждает исследователей искать альтернативные подходы к механизмам внимания, способные снизить вычислительную сложность и обеспечить эффективную обработку длинных последовательностей, расширяя возможности применения нейронных сетей в различных областях.
Эффективное Внимание: Переход к Линейной Сложности
Разработка механизмов эффективного внимания (Efficient Attention) направлена на снижение вычислительной сложности, возникающей при обработке последовательностей данных. Традиционные механизмы внимания требуют O(n^2) операций, где n — длина последовательности, что становится критичным для длинных последовательностей. Эффективные механизмы внимания стремятся к снижению этой сложности, приближаясь к линейной зависимости O(n), что позволяет обрабатывать последовательности значительно большей длины при сохранении приемлемой производительности. Данный подход особенно актуален для задач обработки естественного языка и компьютерного зрения, где длинные последовательности являются нормой.
Линейное внимание представляет собой ключевое нововведение, направленное на достижение линейной вычислительной сложности в расчетах внимания. Традиционные механизмы внимания требуют квадратичной сложности O(n^2) по отношению к длине последовательности n, что становится узким местом при обработке длинных последовательностей. Линейное внимание, напротив, стремится снизить эту сложность до O(n), используя различные математические приемы, такие как разложение функций ядра и использование ассоциативных операций. Это достигается путем переформулировки вычислений таким образом, чтобы операции над векторами можно было выполнять параллельно и эффективно, что значительно ускоряет процесс и позволяет обрабатывать более длинные последовательности данных.
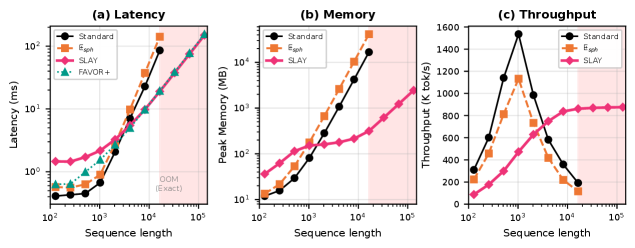
Методы эффективного внимания направлены на аппроксимацию стандартного механизма внимания с целью значительного снижения вычислительной нагрузки. В отличие от стандартного внимания, сложность которого растет квадратично с длиной последовательности, эти подходы позволяют добиться линейной сложности, что критически важно при обработке больших объемов данных. В результате, становится возможной обработка последовательностей, длина которых в 30 раз превышает возможности стандартных механизмов внимания, что открывает перспективы для задач, требующих анализа длинных текстов, видео или временных рядов.
SLAYformer: Новая Реализация Эффективного Внимания
SLAYformer использует специализированный механизм внимания, позволяющий достичь линейной вычислительной сложности по отношению к длине последовательности. Традиционные механизмы внимания в архитектуре Transformer имеют квадратичную сложность O(n^2), что ограничивает их применение к длинным последовательностям. SLAYformer, заменяя стандартное внимание на свой собственный механизм, снижает сложность до O(n), что значительно ускоряет обработку длинных текстов и позволяет обучать модели на более крупных наборах данных. Это достигается за счет оптимизации вычислений и использования альтернативных методов оценки важности различных элементов последовательности.
Модель SLAYformer сохраняет общую структуру архитектуры Transformer, однако заменяет стандартный механизм внимания (attention) на разработанный механизм SLAY attention. В стандартном Transformer, вычисление внимания требует квадратичной сложности по отношению к длине последовательности, что ограничивает его масштабируемость. Замена стандартного внимания на SLAY attention позволяет снизить вычислительную сложность до линейной, сохраняя при этом сопоставимую производительность. Это достигается за счет изменения способа вычисления весов внимания, что позволяет обрабатывать более длинные последовательности с меньшими вычислительными затратами и потреблением памяти.
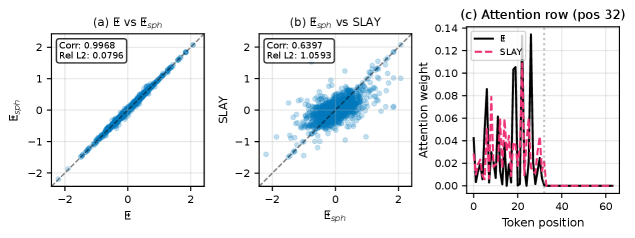
Механизм внимания SLAY, вдохновленный принципами нейронных сетей материи (Neural Matter Networks), использует ядро Ят (Yat Kernel) для повышения эффективности вычислений. В отличие от стандартного механизма внимания на основе softmax, ядро Ят позволяет снизить вычислительную сложность, приближая производительность к стандартному softmax вниманию, но с меньшими затратами ресурсов. Это достигается за счет использования специфической функции ядра, которая позволяет эффективно оценивать важность различных частей входной последовательности без необходимости полного вычисления softmax.
Подтвержденная Эффективность: SLAYformer в Действии
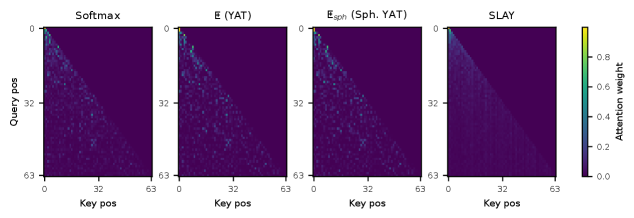
Исследования показали, что SLAYformer демонстрирует сопоставимую с классическим механизмом softmax attention величину потерь на проверочном наборе данных. Это означает, что, несмотря на упрощение вычислительной сложности, модель не уступает в точности при решении задач обработки последовательностей. Полученные результаты подтверждают, что SLAYformer способен эффективно улавливать важные зависимости в данных, обеспечивая сопоставимую производительность с более ресурсоемкими подходами. Такое соответствие в показателях потерь указывает на перспективность SLAYformer как альтернативы стандартному вниманию, особенно в задачах, требующих обработки длинных последовательностей и ограниченных вычислительных ресурсов.
Несмотря на значительное упрощение вычислительной сложности, SLAYformer демонстрирует высокую эффективность при решении поставленных задач. Исследования показали, что снижение требований к ресурсам не приводит к ухудшению качества результатов, сравнимых с традиционными механизмами внимания softmax. Это достигается за счет инновационной архитектуры, которая позволяет эффективно обрабатывать информацию, избегая избыточных вычислений. Такая оптимизация открывает возможности для применения SLAYformer в задачах, требующих обработки больших объемов данных с ограниченными вычислительными ресурсами, например, в мобильных устройствах или при работе с длинными последовательностями текста и видео. Сохранение высокой производительности при снижении сложности делает SLAYformer перспективным решением для широкого круга приложений в области машинного обучения и искусственного интеллекта.
Исследования показали, что SLAYformer демонстрирует значительное преимущество в обработке длинных последовательностей данных. В частности, эта архитектура способна обрабатывать последовательности, в 30 раз превышающие возможности стандартных механизмов внимания, при этом сохраняя сравнимую скорость обработки с другими линейными базовыми моделями. Это достижение открывает новые перспективы для задач, требующих анализа объемных данных, таких как обработка естественного языка, анализ генома и моделирование временных рядов, где обработка длинных контекстов является ключевым фактором эффективности и точности.
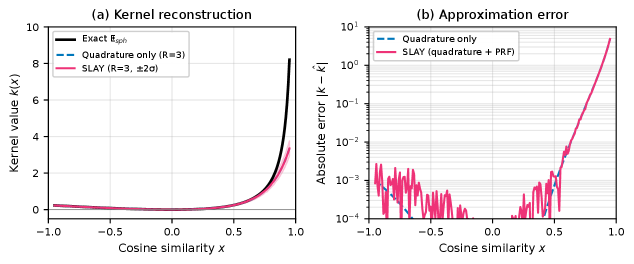
Исследование демонстрирует стремление к элегантности в архитектуре нейронных сетей. Предложенный механизм внимания SLAY, с его сферической линеаризацией и ядром Ят, представляет собой попытку упростить сложные вычисления, не жертвуя при этом производительностью. Как отмечал Пол Эрдёш: «Если вы не можете понять что-то простое, как вы можете понять что-то сложное?». Подобно тому, как SLAY стремится к линейному времени вычислений, чтобы обрабатывать длинные последовательности, Эрдёш подчеркивал важность ясности и простоты в любой сложной системе. В контексте данной работы, это означает, что эффективная архитектура внимания должна быть не только мощной, но и понятной, чтобы обеспечить ее масштабируемость и надежность.
Куда же дальше?
Предложенный подход, SLAY, демонстрирует элегантность в упрощении вычислений внимания, но не стоит забывать: каждая оптимизация имеет свою цену. Переход к сферической линеаризации и ядру Yat, безусловно, открывает возможности для работы с более длинными контекстами, однако вопрос о сохранении тонких нюансов взаимодействия между элементами последовательности остаётся открытым. Успех SLAY в сравнении с традиционным softmax вниманием требует тщательного анализа в различных задачах и с разными типами данных; простая победа в бенчмарках не гарантирует универсальности.
Дальнейшие исследования неизбежно потребуют более глубокого понимания взаимосвязи между геометрией пространства признаков и эффективностью внимания. Следует исследовать, как различные ядра и методы случайных признаков влияют на способность модели к обобщению и устойчивости к шуму. Поиск баланса между вычислительной сложностью и выразительностью, между скоростью и точностью — вот истинный вызов, стоящий перед исследователями.
Нельзя исключать, что истинный прорыв потребует отказа от самой концепции внимания в его нынешнем виде. Возможно, будущее за совершенно иными архитектурами, вдохновлёнными не нейронными сетями, а принципами организации сложных систем в природе. Простота и ясность — вот к чему стоит стремиться, помня, что даже самая изящная система — лишь приближение к реальности.
Оригинал статьи: https://arxiv.org/pdf/2602.04915.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Макросъемка
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Прогнозы цен на эфириум к рублю: анализ криптовалюты ETH
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- MINISFORUM добавляет опцию Ryzen 9 8945HX в линейку мини-ПК MS-A2
- От фотографий к фильмам: полное руководство по переходу на видеосъемку
2026-02-08 21:43