Автор: Денис Аветисян
Новое исследование показывает, что не размер сети определяет ее эффективность, а баланс между глубиной и способностью сохранять важную информацию.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"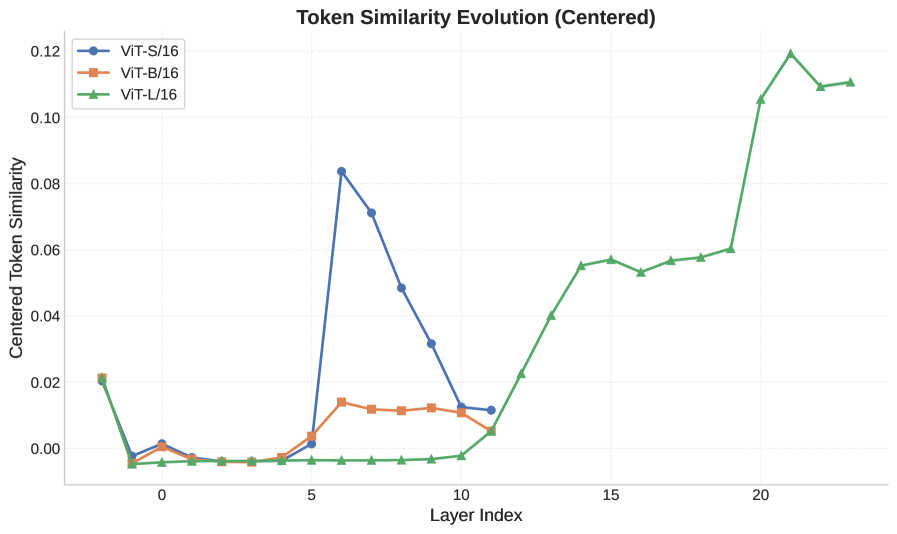
Анализ механизмов немонотонного масштабирования Vision Transformers выявляет ключевую роль информационного потока и геометрического качества представления данных.
Неоднозначные результаты масштабирования Vision Transformers ставят под вопрос общепринятые представления о влиянии глубины сети на производительность. В работе ‘Mechanisms of Non-Monotonic Scaling in Vision Transformers’ проведен систематический анализ ViT-S, ViT-B и ViT-L на ImageNet, выявивший закономерность «Обрыв-Плато-Подъем», определяющую эволюцию представлений с увеличением глубины. Исследование показывает, что повышение эффективности связано с прогрессивным снижением роли [CLS]-токена и переходом к распределенному консенсусу между токенами патчей. Не приведет ли более точная калибровка глубины сети, направленная на оптимизацию фазовых переходов, к созданию Vision Transformers, превосходящих по эффективности более крупные модели?
Трансформеры зрения: Новый подход к пониманию изображений
Традиционные свёрточные нейронные сети, несмотря на свою эффективность в обработке изображений, испытывают трудности с установлением связей между отдалёнными участками сцены. Этот недостаток ограничивает их способность к комплексному пониманию изображения, поскольку для анализа контекста и выявления сложных взаимосвязей между объектами необходимо учитывать информацию, разбросанную по всей картинке. В отличие от свёрточных сетей, которые обрабатывают изображение локальными фильтрами, ограничивая поле зрения, способность улавливать долгосрочные зависимости является ключевым фактором для достижения подлинного «понимания» визуальной информации. Именно этот аспект и определяет необходимость поиска новых архитектур, способных эффективно моделировать глобальные взаимосвязи в изображениях и обеспечивать более целостное восприятие визуальной сцены.
В отличие от традиционных сверточных нейронных сетей, которые обрабатывают изображения локально, Vision Transformers (ViT) используют механизм внимания для установления связей между различными участками изображения, позволяя им учитывать глобальный контекст. Это достигается путем разбиения изображения на последовательность небольших фрагментов, или «патчей», и анализа взаимосвязей между ними. Однако, для эффективной работы и обучения модели ViT требуется значительно больше данных для тренировки, чем сверточным сетям. Это связано с тем, что механизм внимания имеет большое количество параметров, и для их точной настройки необходимо огромное количество примеров, чтобы избежать переобучения и обеспечить обобщающую способность модели на новых, ранее не виденных изображениях. Таким образом, несмотря на свой потенциал в улучшении понимания изображений, применение ViT сопряжено с необходимостью решения проблемы нехватки данных и разработки методов эффективного обучения.
Несмотря на впечатляющие результаты, масштабирование Vision Transformers (ViT) демонстрирует сложную внутреннюю динамику, требующую более детального изучения. Исследования показывают, что увеличение размера модели и объёма данных не всегда приводит к пропорциональному улучшению производительности, а может приводить к неоптимальному использованию вычислительных ресурсов и возникновению «узких мест» в процессе обработки информации. Особое внимание уделяется изучению потока информации внутри сети — как различные участки изображения влияют друг на друга при принятии решений, и как формируется представление об объектах и сценах. Анализ промежуточных слоёв ViT позволяет выявить, какие признаки оказываются наиболее важными для классификации, а также обнаружить потенциальные проблемы с обобщающей способностью модели и её устойчивостью к шуму и искажениям. Понимание этих внутренних механизмов критически важно для разработки более эффективных и надёжных систем компьютерного зрения на базе архитектуры Transformer.
Декодирование потока информации: Роль внимания и позиционного кодирования
Механизм внимания является ключевым компонентом Vision Transformer (ViT), позволяя каждому патчу изображения взаимодействовать со всеми остальными. Однако, несмотря на эту глобальную связность, она не гарантирует эффективного распространения информации по сети. Полная связанность требует значительных вычислительных ресурсов и не подразумевает, что важная информация будет эффективно распространена или что сеть будет фокусироваться на наиболее релевантных признаках. Анализ показывает, что простое обеспечение связи между всеми патчами недостаточно для эффективной обработки визуальных данных, и требуются дополнительные механизмы для управления потоком информации и выделения наиболее значимых признаков.
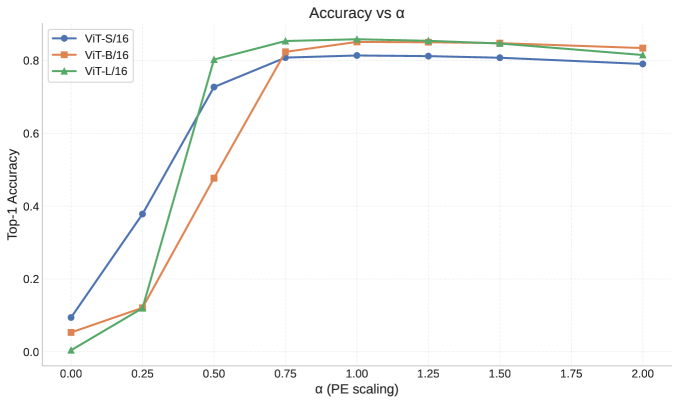
Позиционное кодирование (PE) играет ключевую роль в архитектуре Transformer, предоставляя информацию о пространственном расположении входных токенов, что необходимо для обработки последовательностей, в частности изображений в Vision Transformers (ViT). В отличие от рекуррентных сетей, Transformer не имеет встроенного представления о порядке входных данных; PE добавляется к эмбеддингам токенов, позволяя модели учитывать относительное и абсолютное положение каждого элемента. Это кодирование влияет на организацию признаков в каждом слое, определяя, как информация интегрируется и трансформируется. Анализ показывает, что применение PE способствует формированию иерархических представлений, где более абстрактные признаки возникают в более глубоких слоях сети, поскольку пространственные отношения между элементами эффективно кодируются и используются при обработке данных.
Анализ потока информации в ViT показывает неравномерность распространения данных между слоями. В начальных слоях наблюдается паттерн “резкий спад — плато — восхождение” (cliff-plateau-climb) в мере схожести токенов между слоями. Данный паттерн указывает на поэтапную обработку визуальной информации: первоначальный резкий спад, вероятно, связан с отбрасыванием избыточной информации и выделением наиболее значимых признаков, затем период плато характеризует стабилизацию представления, а последующий восход отражает формирование более сложных и абстрактных представлений, необходимых для последующих слоев сети. Наблюдаемый характер изменения схожести токенов подтверждает гипотезу о иерархической организации обработки визуальных данных в архитектуре ViT.
Отношение доминирования позиционного кодирования (PE Dominance Ratio) представляет собой метрику, количественно оценивающую вклад позиционной информации в общую репрезентацию токенов внутри сети Vision Transformer. Оно рассчитывается как отношение дисперсии, объясняемой позиционным кодированием, к общей дисперсии признаков токенов. Высокое значение PE Dominance Ratio указывает на то, что пространственные отношения между патчами эффективно закодированы и оказывают существенное влияние на процесс обработки изображения, в то время как низкое значение свидетельствует о преобладании информации о содержании патчей над информацией о их расположении. Анализ данного отношения позволяет оценить эффективность использования позиционного кодирования и выявить потенциальные узкие места в процессе кодирования пространственных зависимостей, что важно для оптимизации архитектуры и повышения производительности модели. Значение рассчитывается для каждого слоя сети, что позволяет отслеживать изменение важности позиционной информации по мере распространения данных.

Представление признаков и консенсус сети
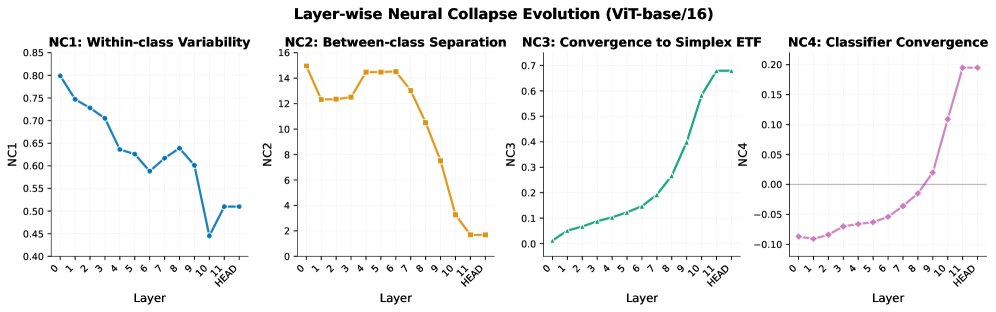
Модель ViT-B/16 демонстрирует превосходное геометрическое качество признаков и явление Neural Collapse в своих финальных слоях, что указывает на эффективную консолидацию признаков и разделение классов. Количественно это подтверждается низким значением метрики Neural Collapse 2 (NC2), составляющим 1.679. Низкое значение NC2 свидетельствует о высокой степени сходимости признаков внутри каждого класса и чётком разделении между классами в пространстве признаков, что говорит о способности модели формировать компактные и различимые представления данных.
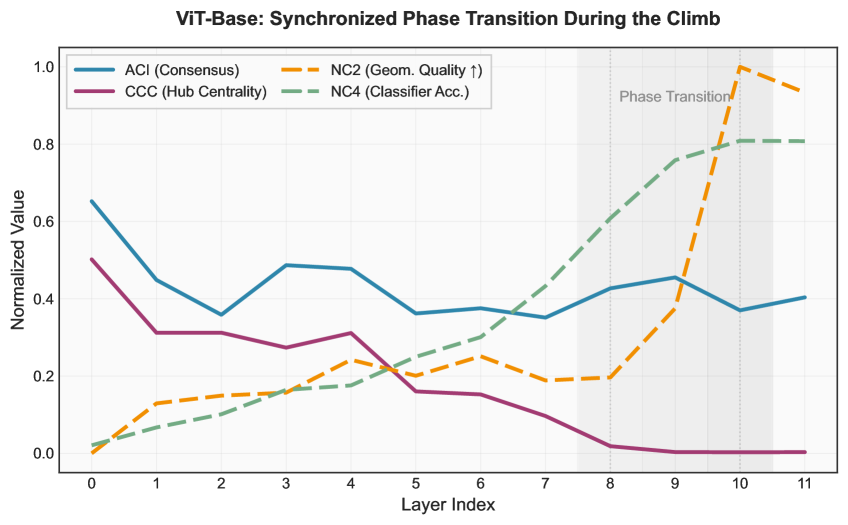
В архитектуре ViT-B/16 наблюдается явление, известное как «маргинализация хаба», которое заключается в снижении влияния CLS-токена. Измерение CLS Centrality (CCC) показало уменьшение данного параметра на 99.3%, со значения 0.502 до 0.004. Это свидетельствует о переходе к распределенному консенсусу в процессе формирования представлений, где информация о признаках не концентрируется в одном токена, а равномерно распределяется между патчами изображения, что способствует более устойчивому и эффективному представлению данных.
Индекс консенсуса внимания (Attention Consensus Index) используется для оценки скорости глобального смешивания информации в модели. В случае ViT-B/16, данный индекс демонстрирует эффективную коммуникацию между патчами, достигая значения 0.905 в слоях 8-10. Это указывает на быструю передачу и интеграцию информации между различными частями изображения в процессе обработки моделью, что способствует формированию целостного представления об изображении.
Для оценки качества формируемых представлений в ViT-B/16 применялись линейные зонды, использующие Индекс Перемешивания Информации (Information Scrambling Index). Результаты показали, что модель развивает богатые и информативные представления, поддерживая контролируемый диапазон перемешивания в пределах $0.004 — 0.009$. Низкий и стабильный показатель перемешивания указывает на то, что признаки, извлекаемые моделью, хорошо структурированы и содержат значимую информацию, необходимую для последующей классификации и решения задач компьютерного зрения.
Архитектурные вариации и компромиссы в производительности
Исследование архитектур Vision Transformer (ViT) выявило, что модель ViT-S/16, обладающая меньшей ёмкостью, демонстрирует эффект “коллапса коммуникаций” — резкое снижение эффективности обмена информацией между слоями сети. Данное явление указывает на критическую важность достаточной ёмкости модели для поддержания стабильного и эффективного потока информации при обработке изображений. Недостаток параметров в ViT-S/16 приводит к тому, что сеть не способна эффективно распространять и агрегировать информацию, что негативно сказывается на её способности к обучению и обобщению. Таким образом, результаты подчеркивают, что увеличение размера модели не всегда гарантирует улучшение производительности, но достаточная ёмкость является необходимым условием для поддержания надлежащей коммуникации и эффективной обработки визуальной информации.
Исследование архитектур Vision Transformer выявило интересный парадокс: увеличение размера модели не всегда приводит к повышению её производительности. В частности, ViT-L/16, обладая наибольшим числом параметров среди исследуемых моделей, показал результаты, уступающие ViT-B/16. Данный факт указывает на то, что ключевым фактором, определяющим эффективность модели, является не только её размер, но и оптимальное сочетание архитектурных решений, способствующих эффективной обработке и передаче информации. Более крупная модель, при отсутствии соответствующей оптимизации, может страдать от избыточности параметров и затруднений в процессе обучения, что негативно сказывается на её способности к обобщению и, как следствие, на итоговой точности.
Обучение всех исследованных моделей — ViT-B/16, ViT-S/16 и ViT-L/16 — проводилось на широко известном датасете ImageNet, что подчеркивает его фундаментальную роль в формировании приобретенных представлений. ImageNet, содержащий миллионы изображений, размеченных по различным категориям, служит основой для обучения алгоритмов компьютерного зрения, обеспечивая им необходимый объем данных для распознавания закономерностей и формирования обобщенных знаний об окружающем мире. Успешность всех трех моделей в решении поставленных задач напрямую связана с качеством и разнообразием данных, содержащихся в ImageNet, что подтверждает важность тщательно подобранных обучающих выборок для достижения высокой производительности в области визуального анализа.
Исследование архитектурных вариаций Vision Transformer (ViT) выявило интересную закономерность в динамике схожести внутренних представлений различных моделей. В частности, ViT-L/16 демонстрирует продолжительный период — целых 14 слоёв — в течение которого внутренние представления модели сохраняют низкий уровень схожести. Этот феномен, известный как “плато”, значительно превышает аналогичные показатели для ViT-S (6 слоёв) и ViT-B (12 слоёв). Более длительное “плато” в ViT-L/16 указывает на то, что модель требует большего количества слоёв для установления стабильных и значимых связей между признаками изображения, что может влиять на скорость обучения и обобщающую способность. Данное наблюдение подчеркивает важность анализа динамики внутренних представлений при разработке и оптимизации архитектур глубокого обучения, поскольку продолжительность “плато” может служить индикатором эффективности и стабильности процесса обучения.
Исследование механизмов масштабирования в Vision Transformers выявляет, что простое увеличение размера модели не гарантирует повышение производительности. Напротив, ключевым фактором является глубина сети и ее влияние на поток информации. Как отмечал Эдсгер Дейкстра: «Простота — это высшая степень совершенства». Данная работа подтверждает эту мысль, демонстрируя, что модели средней величины могут превзойти более крупные, достигая лучшего баланса между сохранением информации и эффективностью выполнения задач. Особое внимание уделяется геометрическому качеству представления данных и процессу «hub marginalization», что позволяет оптимизировать информацию, проходящую через слои сети и, таким образом, повысить общую производительность.
Куда двигаться дальше?
Представленная работа, хотя и проливает свет на нетривиальную зависимость масштабирования Vision Transformers от глубины сети, лишь подчеркивает фундаментальную сложность понимания внутренних механизмов этих моделей. Утверждение о том, что “достаточность” модели может быть достигнута не только увеличением параметров, но и оптимизацией потока информации, звучит, конечно, элегантно, однако требует строгого математического обоснования. Простое наблюдение корреляции между геометрическим качеством представлений и производительностью недостаточно. Необходимы доказательства причинно-следственной связи, а не эмпирические подтверждения.
Особое внимание следует уделить исследованию пределов эффективности “сжатия” информации. Где та граница, за которой потеря информации становится критичной для решения задачи? Анализ влияния различных методов регуляризации и “разбавления” сети, направленных на повышение устойчивости к шуму и снижение вычислительной сложности, представляется перспективным направлением. Важно понимать, что любое решение должно быть непротиворечивым, а не просто «работать на тестах».
В конечном итоге, задача заключается не в создании всё более крупных моделей, а в разработке принципиально новых архитектур, способных эффективно извлекать и использовать информацию. Оптимизация существующих решений, безусловно, важна, но истинный прогресс требует пересмотра базовых принципов проектирования нейронных сетей. Иначе, мы рискуем бесконечно усложнять системы, не понимая их внутренней логики.
Оригинал статьи: https://arxiv.org/pdf/2511.21635.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Xiaomi Poco M7 ОБЗОР: плавный интерфейс, удобный сенсор отпечатков, большой аккумулятор
- Российский рынок в 2025: Инвестиции, Экспорт и Новые Возможности (27.02.2026 15:32)
2025-11-30 01:36