Автор: Денис Аветисян
Новое исследование показывает, что эффективное использование промежуточных слоев Vision Transformers значительно улучшает производительность в задачах переноса обучения.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"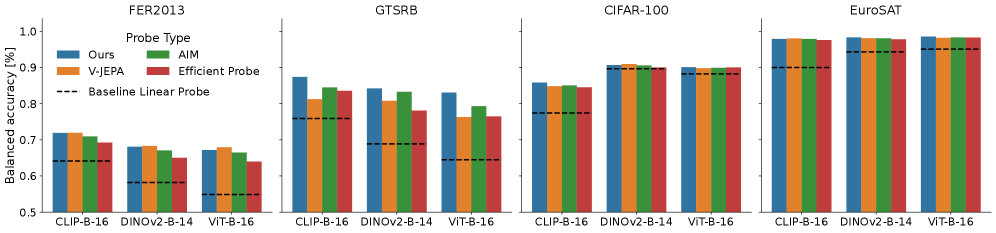
В статье предлагается механизм внимательного слияния промежуточных представлений для повышения эффективности Vision Transformers.
Несмотря на успехи крупных предобученных моделей, эффективная адаптация к конкретным задачам остается сложной проблемой. В статье ‘Beyond the final layer: Attentive multilayer fusion for vision transformers’ предложен новый подход, использующий информацию из всех слоев Vision Transformer посредством механизма внимательного объединения. Показано, что динамическое взвешивание вкладов различных слоев позволяет значительно повысить производительность в задачах переносного обучения по сравнению с использованием только финальных представлений. Какие еще возможности скрыты в промежуточных слоях глубоких нейронных сетей и как их можно эффективно использовать для повышения эффективности адаптации моделей?
Визуальные Трансформеры и Самообучение: Новый Взгляд на Обработку Изображений
Визуальные трансформаторы (ViT) представляют собой инновационный подход к обработке изображений, заимствующий архитектуру трансформаторов, первоначально разработанную для задач обработки естественного языка. Вместо традиционных сверточных нейронных сетей, ViT разделяет изображение на последовательность патчей, рассматривая каждый патч как “токен”, подобно словам в предложении. Этот подход позволяет модели эффективно улавливать глобальные зависимости в изображении, используя механизм внимания, присущий трансформаторам. В результате, ViT демонстрируют впечатляющую производительность в различных задачах компьютерного зрения, включая классификацию, обнаружение объектов и сегментацию, часто превосходя традиционные модели при обучении на достаточно больших наборах данных. Их способность к параллельной обработке и масштабируемости делает их перспективным направлением для дальнейших исследований и разработок в области искусственного интеллекта.
Методы самообучения, в частности, маскированные автоэнкодеры (MAE), играют ключевую роль в предварительной подготовке моделей компьютерного зрения, таких как Vision Transformers. Суть подхода заключается в том, что модель обучается восстанавливать недостающие части изображения, которые были намеренно замаскированы. Этот процесс позволяет модели самостоятельно извлекать полезные признаки из больших объемов неразмеченных данных, что существенно снижает потребность в трудоемкой ручной разметке. Вместо того, чтобы полагаться на заранее определенные метки, модель учится понимать визуальные закономерности, что обеспечивает более эффективное обучение и обобщение на различные задачи, включая классификацию, обнаружение объектов и сегментацию изображений. Такой подход позволяет создавать мощные и универсальные системы компьютерного зрения, способные эффективно работать с реальными данными.
Модели, такие как DINOv2 и CLIP, демонстрируют значительный прогресс в обучении надежным визуальным представлениям, используя методы самообучения. Вместо традиционной маркировки данных, эти модели учатся, реконструируя или сопоставляя части изображений, что позволяет им извлекать существенные признаки без участия человека. Полученные визуальные представления служат прочной основой для широкого спектра задач, включая распознавание объектов, сегментацию изображений и даже генерацию контента. Их способность обобщать знания, полученные на больших немаркированных наборах данных, делает их ключевым компонентом в современных системах компьютерного зрения и открывает новые возможности для автоматизированного анализа и понимания визуальной информации.
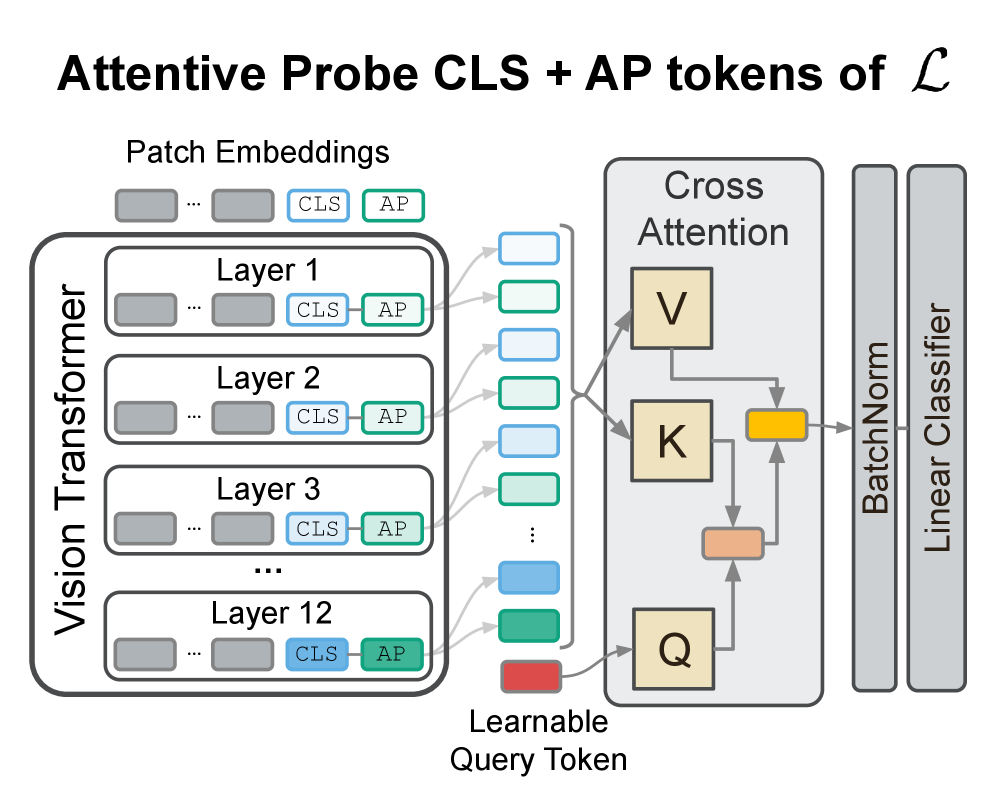
Зондирование Моделей: Раскрытие Внутренних Механизмов
Методы зондирования (probing) позволяют исследователям анализировать, какие признаки и представления формируются во внутренних слоях больших языковых моделей (Foundation Models). Этот подход заключается в изучении активаций промежуточных слоев модели для определения, какие аспекты входных данных (например, синтаксис, семантика, или конкретные сущности) кодируются на различных уровнях абстракции. Зондирование не требует изменения предобученных весов модели, а вместо этого использует обучение небольших, дополнительных модулей на основе этих активаций, что позволяет оценить качество представлений, сформированных моделью, без изменения ее основных параметров.
Метод линейного зондирования представляет собой базовый подход к анализу внутренних представлений больших языковых моделей, позволяющий получить первоначальное представление о выученных признаках. В отличие от него, методы зондирования с использованием механизмов внимания, такие как V-JEPA, AIM и Efficient Probe (EP), обеспечивают более детальное извлечение признаков. Эти методы анализируют, какие части входных данных наиболее важны для конкретных представлений, что позволяет выявить более сложные зависимости и взаимосвязи, выученные моделью. Использование механизмов внимания позволяет оценить, какие элементы входной последовательности оказывают наибольшее влияние на активации в определенных слоях модели, предоставляя более гранулярное понимание процесса обучения.
Методы зондирования (probing) моделей основываются на замораживании (freezing) предварительно обученных весов основной модели и последующем обучении небольшого, дополнительного модуля (probe) поверх этих замороженных весов. Такой подход позволяет эффективно оценить качество представлений, полученных на промежуточных слоях модели, без необходимости переобучения всей сети. Обучение легкого модуля требует значительно меньше вычислительных ресурсов и времени, что делает этот метод практичным для анализа больших языковых моделей и выявления специфических признаков, закодированных в их внутренних представлениях.
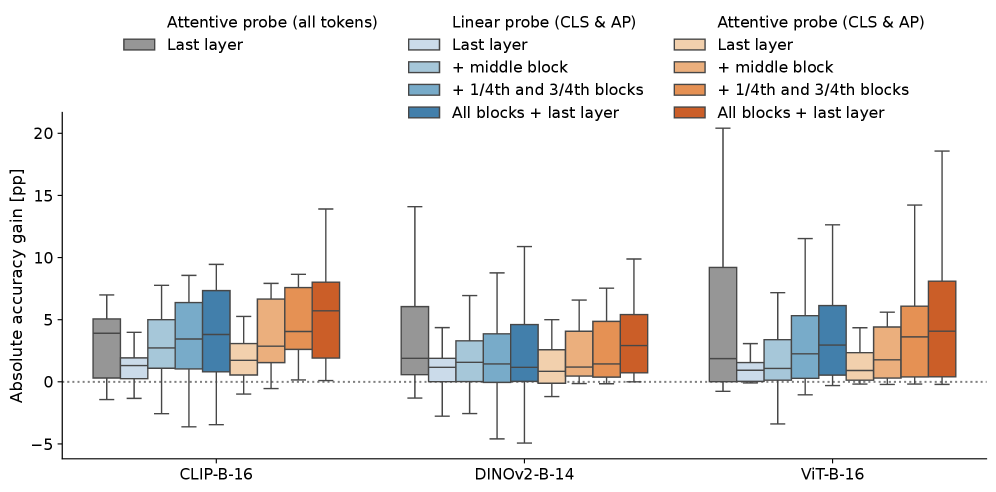
Измерение Сходства Представлений: Понимание Иерархии Признаков
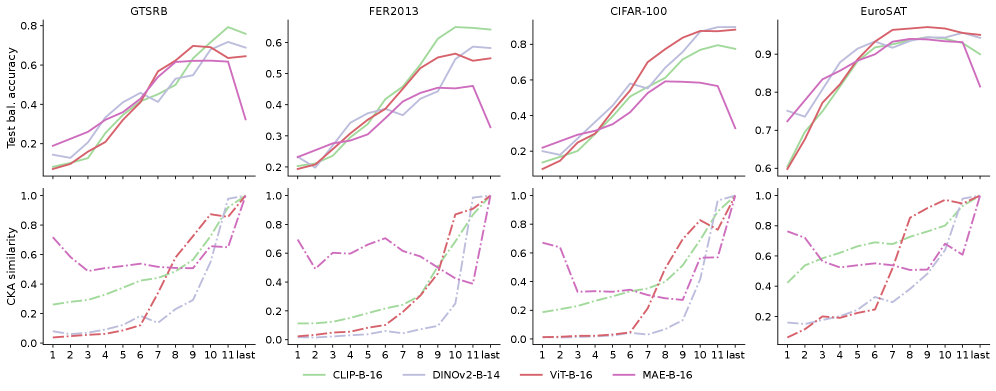
Метрики сходства представлений, такие как выравнивание центрированных ядер (Centered Kernel Alignment, CKA), позволяют количественно оценить степень схожести признаков, извлеченных в различных слоях нейронной сети. CKA вычисляет корреляцию между матрицами признаков, полученными из разных слоев, после центрирования и нормализации. Значение CKA варьируется от 0 до 1, где 1 указывает на полное соответствие представлений, а 0 — на их полное отсутствие. Этот метод позволяет сравнивать представления, полученные в различных слоях одной и той же сети, а также сравнивать представления, полученные из разных сетей, обученных на одном и том же наборе данных. Полученные значения сходства используются для анализа иерархической организации признаков, извлеченных нейронной сетью.
Анализ сходства представлений, полученных из разных слоёв нейронной сети, в сочетании с методами зондирования (probing), позволяет выявить иерархическую организацию извлеченных признаков. Зондирование, направленное на предсказание определенных свойств входных данных на основе активаций конкретного слоя, в сочетании с метриками сходства, такими как Centered Kernel Alignment (CKA), позволяет определить, какие слои кодируют информацию о конкретных аспектах входных данных и как эта информация преобразуется по мере продвижения по сети. Высокая степень сходства между слоями указывает на сохранение информации, в то время как низкая степень сходства свидетельствует о трансформации признаков и формировании новых представлений. Сопоставление результатов зондирования и метрик сходства позволяет построить карту иерархии признаков, демонстрирующую, как информация структурируется и обрабатывается в различных уровнях сети.
Оптимизация производительности и обобщающей способности нейронных сетей напрямую зависит от понимания процессов трансформации информации, происходящих на каждом слое. Анализ потока данных позволяет выявить, какие признаки извлекаются и как они комбинируются для формирования более сложных представлений. Эффективная передача информации между слоями, минимизация потери релевантных признаков и предотвращение искажений сигнала критически важны для достижения высокой точности и способности модели к обобщению на новые, ранее не встречавшиеся данные. Соответственно, понимание этих процессов позволяет целенаправленно модифицировать архитектуру сети, функции активации и методы обучения для улучшения её характеристик.
Эффективная Адаптация: За Пределами Полной Перенастройки
Полная перенастройка модели (Full Fine-tuning), несмотря на свою эффективность, требует значительных вычислительных ресурсов и больших объемов данных для обучения. В качестве альтернативы предлагается параметрически-эффективная перенастройка (Parameter-Efficient Fine-tuning, PEFT). PEFT позволяет адаптировать предварительно обученную модель к новым задачам, обучая лишь небольшую часть параметров, что существенно снижает вычислительные затраты и требования к объему данных, сохраняя при этом сравнимую или даже более высокую производительность. Этот подход особенно актуален в условиях ограниченных ресурсов и необходимости быстрой адаптации модели к новым данным.
Методы, такие как LoRA (Low-Rank Adaptation), позволяют значительно снизить количество обучаемых параметров в процессе адаптации больших языковых моделей. Вместо обновления всех весов модели, LoRA вводит низкоранговые матрицы, которые обучаются параллельно с замороженными исходными весами. Это существенно сокращает вычислительные затраты и объем необходимых данных для обучения, при этом сохраняя сравнимую производительность с полной тонкой настройкой. Практически, LoRA позволяет адаптировать модели на ограниченных ресурсах, что делает возможным их применение в сценариях, где полная тонкая настройка была бы невозможна.
Параметрически-эффективная настройка (PEFT) позволяет быстро адаптировать модель к новым задачам и наборам данных за счет обновления лишь части весов модели. В ходе экспериментов наша методика демонстрирует среднее увеличение точности на 5.54 процентных пункта по сравнению со стандартным линейным зондированием, а также сокращение времени обучения в 36 раз по сравнению с полной перенастройкой модели. Это достигается за счет фокусировки на наиболее значимых параметрах, что снижает вычислительные затраты и требования к объему данных для обучения.
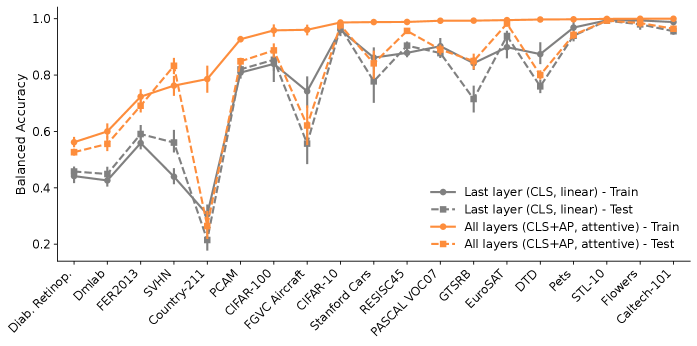
Использование Пространственно Усредненных Признаков для Устойчивости
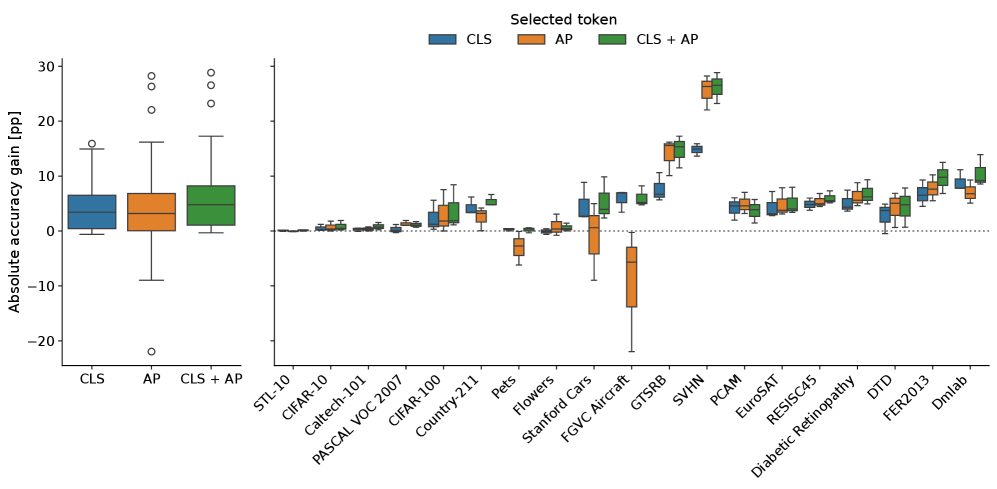
В архитектуре Vision Transformers (ViT) ключевую роль играют токены, представляющие собой сегменты изображения, в том числе и Average-Pooled (AP) токены. Эти токены формируются путем усреднения значений пикселей по определенной пространственной области, что позволяет эффективно кодировать глобальный контекст изображения. В отличие от обработки каждого пикселя по отдельности, AP токены фокусируются на обобщенных признаках, что значительно снижает чувствительность модели к незначительным изменениям в положении объектов или к шумам на изображении. Таким образом, использование усредненных пространственных признаков способствует повышению устойчивости и обобщающей способности ViT, позволяя модели более эффективно работать с разнообразными изображениями.
В архитектуре Vision Transformers (ViT) специальные токены, известные как Average-Pooled (AP) токены, играют ключевую роль в обеспечении устойчивости модели к изменениям во входных изображениях. Эти токены формируют усредненное представление пространственной информации, позволяя модели улавливать глобальный контекст, независимо от незначительных вариаций, таких как сдвиги, повороты или изменения освещения. По сути, AP-токены служат своеобразным «резюме» изображения, концентрируя в себе наиболее важные характеристики и позволяя модели игнорировать несущественные детали. Это значительно повышает надежность модели при обработке реальных изображений, где неизбежны различные искажения и помехи, и обеспечивает стабильные результаты, подтвержденные низкой стандартной девиацией точности (менее 0.01) при проведении экспериментов с различными начальными условиями.
Исследование взаимодействия токенов, представляющих усредненные пространственные признаки, с другими элементами модели Vision Transformer позволяет значительно оптимизировать её производительность и способность к обобщению. Анализ выявил, что эффективное использование этих токенов способствует повышению устойчивости модели к изменениям входных данных и улучшению точности предсказаний. Полученные результаты демонстрируют высокую стабильность предложенного подхода: стандартное отклонение точности составило менее 0.01 при проведении пяти серий экспериментов с разными начальными условиями, что подтверждает надежность и воспроизводимость полученных результатов.
Исследование показывает, что эффективное использование промежуточных слоев в Vision Transformers, посредством механизма внимательного объединения, значительно улучшает производительность в задачах, требующих перенос обучения. Авторы статьи подчеркивают, что простое использование финальных слоев не позволяет полностью раскрыть потенциал модели. Этот подход к изучению внутренних представлений согласуется с убеждением, что даже кажущиеся аномалии могут содержать ценную информацию. Как однажды заметил Эндрю Ын: «Мы должны стремиться не просто к точности, но и к пониманию того, почему модель принимает те или иные решения». Понимание закономерностей, скрытых в промежуточных слоях, открывает новые возможности для повышения эффективности и интерпретируемости моделей.
Куда Ведет Этот Путь?
Представленные исследования, демонстрируя эффективность использования промежуточных слоев Vision Transformer, открывают скорее вопросы, чем дают окончательные ответы. Каждое изображение, как и любая сложная система, скрывает структурные зависимости, которые необходимо выявить. Простое суммирование признаков, даже с использованием механизмов внимания, кажется упрощением. Настоящая задача заключается не в достижении впечатляющих результатов на стандартных наборах данных, а в понимании того, как именно эти промежуточные представления кодируют информацию о мире.
Очевидным направлением дальнейших исследований представляется разработка более тонких методов слияния. Механизмы внимания, безусловно, полезны, но они могут упускать более сложные взаимосвязи между слоями. Необходимо исследовать, как различные слои специализируются на разных аспектах визуальной информации и как эти специализации можно эффективно объединить. Важно помнить, что интерпретация моделей важнее красивых результатов — только глубокое понимание внутренних механизмов позволит создавать действительно интеллектуальные системы.
В конечном счете, представленная работа указывает на необходимость смещения акцента с “черных ящиков” на прозрачные и интерпретируемые модели. Задача не в том, чтобы построить систему, которая “работает”, а в том, чтобы создать систему, которую можно понять. Иначе, все эти сложные архитектуры останутся лишь впечатляющими, но бесполезными конструкциями.
Оригинал статьи: https://arxiv.org/pdf/2601.09322.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- vivo V70 ОБЗОР: современный дизайн, портретная/зум камера, высокая автономность
- Дебют iQOO Pad2 и Pad2 Pro
2026-01-16 01:31