Автор: Денис Аветисян
Исследователи представляют систему, объединяющую возможности больших мультимодальных моделей и носимых устройств для создания интуитивно понятного голосового управления в смешанной реальности.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"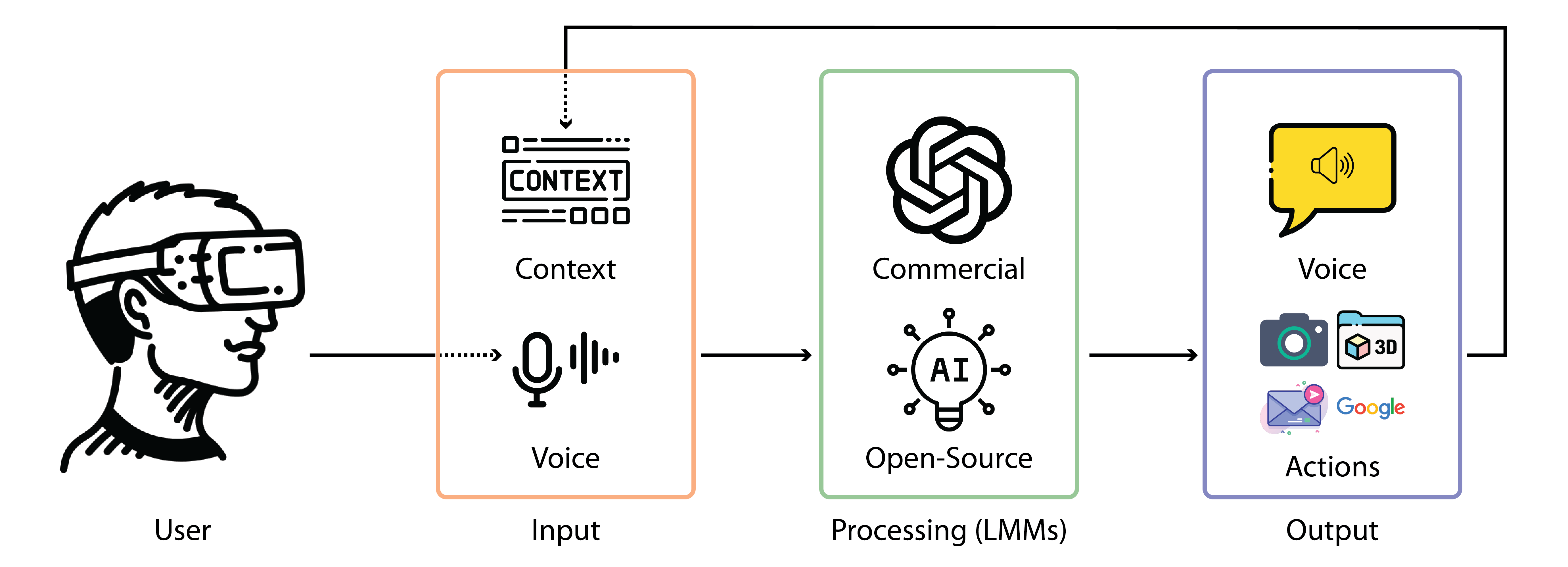
В статье рассматривается Reality Copilot — система, использующая современные модели искусственного интеллекта для обеспечения контекстно-зависимой помощи в смешанной реальности с использованием голосового интерфейса.
Несмотря на значительный прогресс в области смешанной реальности и искусственного интеллекта, их интеграция для создания интуитивно понятных и контекстно-зависимых рабочих процессов остается сложной задачей. В данной работе, ‘Reality Copilot: Voice-First Human-AI Collaboration in Mixed Reality Using Large Multimodal Models’, представлен Reality Copilot — голосовой помощник на базе больших мультимодальных моделей, предназначенный для смешанной реальности. Система обеспечивает естественное взаимодействие, понимание окружающей среды и генерацию 3D-контента, открывая возможности для беспрецедентного сотрудничества человека и ИИ. Какие новые сценарии использования и улучшения в области носимых вычислений и искусственного интеллекта может предложить подобный подход?
За пределами голосового управления: К воплощению истинно коллаборативного ИИ
Традиционные интерфейсы взаимодействия с вычислительными системами зачастую требуют постоянного внимания пользователя, что существенно снижает продуктивность при выполнении сложных задач. Непрерывное переключение между задачами и необходимость непосредственного управления каждым шагом работы приводят к когнитивной перегрузке и снижению эффективности. Исследования показывают, что постоянная потребность в визуальном и ментальном контроле над процессами отвлекает от более важных аспектов работы, снижая креативность и увеличивая вероятность ошибок. В результате, возможности современных технологий часто оказываются ограниченными из-за неспособности адаптироваться к естественным процессам человеческого мышления и деятельности, что подчеркивает необходимость разработки более интуитивных и незаметных способов взаимодействия.
Истинный коллаборативный ИИ-помощник должен органично встраиваться в окружающую пользователя среду и адаптироваться к его потребностям. Вместо пассивного ответа на запросы, такая система способна воспринимать контекст происходящего — что делает пользователь, где он находится, какие задачи выполняет — и, основываясь на этих данных, проактивно предлагать помощь. Это означает, что помощник не просто выполняет команды, а предвидит потребности, предлагая релевантные инструменты или информацию в нужный момент, фактически становясь расширением когнитивных способностей человека. Такая адаптивность требует не только сложных алгоритмов анализа данных, но и способности к обучению в реальном времени, позволяя системе постоянно совершенствовать свои навыки и предоставлять всё более персонализированную поддержку.
Представленная в данной работе система «Reality Copilot» демонстрирует функционирующего искусственного ассистента, который активно использует возможности аппаратного обеспечения, такие как доступ к камере и кодирование видео. Это позволяет системе не просто реагировать на команды, но и воспринимать окружающую обстановку, анализировать действия пользователя в реальном времени и предлагать помощь на основе визуальной информации. Используя данные с камеры, «Reality Copilot» способен идентифицировать объекты, понимать контекст происходящего и, например, автоматически предлагать инструкции по сборке мебели или помощь в приготовлении блюда, основываясь на том, что видит в поле зрения. Такой подход выходит за рамки традиционных голосовых ассистентов, предлагая более интуитивное и контекстно-зависимое взаимодействие, значительно повышающее эффективность и удобство использования.
Для реализации действительно полезного искусственного интеллекта, способного к сотрудничеству, необходима система, обладающая способностью к восприятию контекста окружающей среды. Она должна не просто реагировать на прямые команды, но и интерпретировать намерения пользователя, анализируя его действия и окружение. Такая система выходит за рамки пассивного помощника, активно предлагая релевантную помощь, предвосхищая потребности и оптимизируя рабочий процесс. Способность к проактивному содействию требует сложного алгоритма, сочетающего в себе обработку визуальной информации, анализ поведения и предсказательное моделирование, что позволяет ИИ действовать не как инструмент, а как полноценный партнер в решении задач.
Мультимодальный интеллект: Ключ к глубокому пониманию окружения
Reality Copilot использует большие мультимодальные модели для объединения и обработки данных, поступающих из различных источников: голосового ввода, визуальной информации и данных пространственного картирования. Этот процесс синтеза позволяет системе одновременно анализировать речь пользователя, изображения, полученные с камеры, и трехмерную модель окружающего пространства. Интеграция этих модальностей обеспечивает комплексное понимание контекста, необходимое для эффективного взаимодействия и выполнения задач, превосходя возможности систем, основанных на обработке только одного типа данных. Мультимодальный подход позволяет Reality Copilot интерпретировать не только что говорит пользователь, но и где он находится и на что он смотрит.
Ключевые компоненты системы, FastVLM и SAM3D, обеспечивают обработку визуальной информации в реальном времени и генерацию трехмерных моделей. FastVLM (Fast Vision Language Model) отвечает за быстрое понимание изображений, позволяя системе идентифицировать объекты и сцены с минимальной задержкой. SAM3D (Segment Anything Model 3D) используется для создания детальных трехмерных моделей окружения на основе визуальных данных, что необходимо для точного позиционирования и взаимодействия виртуального ассистента с физическим пространством пользователя. Совместная работа этих моделей позволяет Reality Copilot анализировать окружающую среду и создавать ее цифровую репрезентацию для эффективного выполнения задач.
Доступ к данным с камер наружного обзора (passthrough) обеспечивает необходимый визуальный ввод для привязки виртуального ассистента к физическому пространству пользователя. Этот процесс включает в себя непрерывную передачу видеопотока от камер устройства в систему искусственного интеллекта, позволяя ей анализировать окружающую среду в реальном времени. На основе полученных данных, система определяет положение пользователя, распознает объекты и поверхности в комнате, и, как следствие, способна отображать виртуальные элементы и взаимодействовать с ними в соответствии с физическим окружением. Без доступа к визуальной информации, корректная привязка и взаимодействие виртуального ассистента с реальным миром становится невозможной.
Объединение различных модальностей данных — голоса, зрения и пространственного картирования — позволяет Reality Copilot выходить за рамки простого выполнения команд и переходить к осмысленной совместной работе над задачами. Как показано в представленной научной работе, данная интеграция позволяет системе не только понимать запросы пользователя, но и активно участвовать в процессе их реализации, например, путем визуального анализа окружения и адаптации своих действий к реальному физическому пространству. Это создает возможность для более естественного и эффективного взаимодействия между пользователем и ИИ-ассистентом, приближая его к роли полноценного партнера в решении различных задач.

Контекстуальная осведомленность: Сохранение последовательности взаимодействия
Reality Copilot использует обработку контекста на основе стека (Stack-Based Context Processing) для сохранения устойчивого понимания целей пользователя и истории взаимодействия. Данный подход предполагает хранение информации о текущем запросе и предыдущих обращениях в структуре, напоминающей стек, где каждый новый запрос добавляется поверх предыдущих. Это позволяет системе учитывать не только непосредственный запрос, но и предшествующий контекст, что необходимо для корректной интерпретации неоднозначных формулировок и поддержания связного диалога. Информация в стеке контекста может включать в себя ключевые слова, объекты, действия и другие релевантные данные, необходимые для обеспечения персонализированного и эффективного взаимодействия с пользователем.
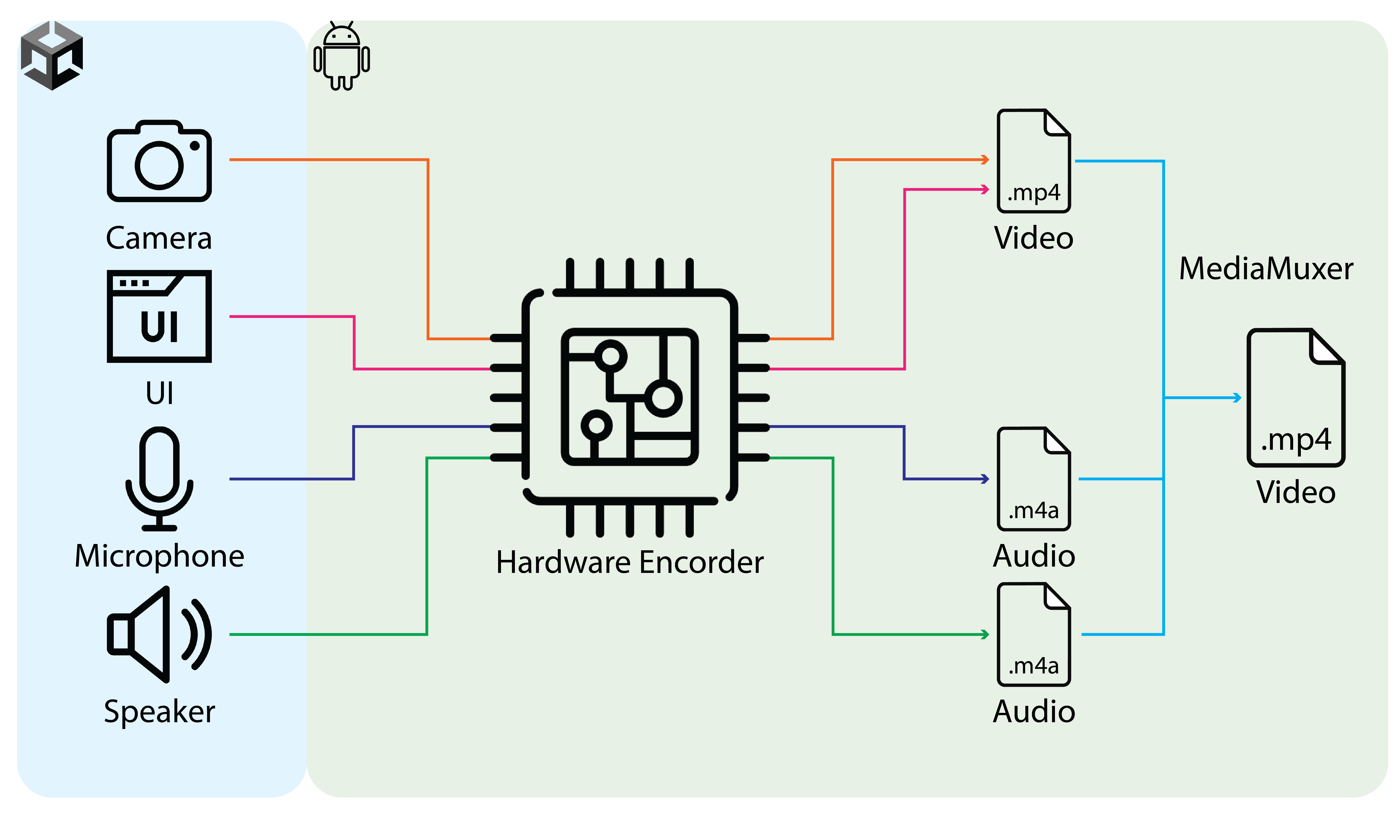
Двухканальная аудиозапись в Reality Copilot фиксирует как реплики пользователя, так и ответы системы. Это позволяет проводить детальный анализ не только содержания запросов, но и акустических характеристик речи, таких как тембр, скорость и интонация. Запись ответов системы важна для последующего анализа и улучшения качества синтеза речи, а также для обучения модели более точно интерпретировать контекст и намерения пользователя. Совместный анализ обеих дорожек позволяет повысить точность распознавания речи, снизить количество ошибок и обеспечить более естественное и плавное взаимодействие.
Система TEN VAD (Voice Activity Detection) обеспечивает работу без использования рук за счет автоматического определения начала и окончания речи пользователя. Это исключает необходимость в ручном включении или отключении микрофона для активации голосового управления. Алгоритм TEN VAD непрерывно анализирует аудиопоток, определяя периоды, когда пользователь говорит, и автоматически активирует систему распознавания речи в эти моменты. Когда речь прекращается, система переходит в режим ожидания, минимизируя потребление ресурсов и снижая вероятность ложных срабатываний. Такая реализация позволяет пользователю взаимодействовать с системой непрерывно, не отвлекаясь на дополнительные действия.
Система Reality Copilot использует EmBARDiment — набор инструментов, предназначенный для интеграции AI-агентов в окружения Android XR. EmBARDiment предоставляет разработчикам API и SDK для создания и развертывания интеллектуальных агентов, способных взаимодействовать с пользователем в дополненной и виртуальной реальности. Данный инструментарий охватывает такие аспекты, как обработка голосовых команд, распознавание жестов, отслеживание взгляда и взаимодействие с виртуальными объектами, обеспечивая возможность создания сложных и интуитивно понятных пользовательских интерфейсов для AI-агентов в XR-средах.

Проактивная помощь: Автоматизация задач и расширение возможностей
Система Reality Copilot значительно упрощает коммуникацию благодаря автоматической генерации и отправке электронных писем через API Gmail. Функционал не просто отправляет заранее заданные шаблоны, а анализирует текущий контекст — данные с датчиков, действия пользователя, и другую релевантную информацию — для создания персонализированных сообщений. Это позволяет, например, автоматически отправлять отчеты о выполненных задачах, уведомления о важных событиях или ответы на часто задаваемые вопросы, освобождая пользователя от рутинной работы с электронной почтой и повышая эффективность взаимодействия.
Аппаратное ускорение записи видео позволяет Reality Copilot фиксировать происходящее в реальном времени и мгновенно делиться полученными данными. В отличие от традиционных методов, требующих значительных вычислительных ресурсов, данная технология обеспечивает плавную и бесперебойную видеосъемку даже при высокой нагрузке на систему. Это особенно ценно для документирования сложных процессов, обучения персонала или оперативного обмена информацией, поскольку позволяет создавать наглядные материалы непосредственно во время выполнения задач, не требуя дополнительной обработки и сокращая время на создание отчетов и инструкций. В результате, повышается эффективность работы и упрощается передача знаний.
Интеграция с передовыми моделями искусственного интеллекта, такими как Google Gemini и OpenAI ChatGPT, значительно расширяет возможности системы, обеспечивая продвинутое понимание естественного языка и генерацию ответов. Данная функция позволяет системе не просто реагировать на команды, но и интерпретировать сложные запросы, учитывать контекст беседы и предоставлять осмысленные, релевантные ответы. Благодаря этому, взаимодействие со средой становится более интуитивным и эффективным, а пользователь получает доступ к интеллектуальному помощнику, способному решать широкий спектр задач — от поиска информации и анализа данных до создания креативного контента и автоматизации рутинных операций. Такая интеграция открывает новые горизонты в области взаимодействия человека и компьютера, стирая границы между простым управлением и полноценным диалогом.
Интеграция Vuplex 3D WebView значительно расширяет возможности пользовательского интерфейса, позволяя бесшовно объединять среду разработки Unity с веб-технологиями HTML. Это создает уникальный опыт взаимодействия, где трехмерные элементы и интерактивные веб-приложения сосуществуют в едином пространстве. Такой подход позволяет разработчикам использовать знакомые инструменты веб-разработки для создания сложных и визуально привлекательных интерфейсов внутри приложений, созданных в Unity, что открывает новые горизонты для дизайна и функциональности, а также упрощает процесс разработки и обновления контента.
Исследование, представленное в статье, демонстрирует стремление к созданию не просто помощника, но партнера в смешанной реальности. Reality Copilot, опираясь на большие мультимодальные модели, пытается выйти за рамки простых команд, понимая контекст и предлагая релевантную помощь. Это напоминает о словах Дональда Дэвиса: «Самое сложное — не создать систему, а понять, как она работает». Ведь только понимание принципов функционирования позволяет эффективно взаимодействовать с ней, а в данном случае — и создавать новые возможности для взаимодействия человека и искусственного интеллекта. Каждый новый патч в Reality Copilot — это признание того, что совершенства не существует, а лишь постоянное стремление к улучшению.
Куда же дальше?
Представленная работа, хоть и демонстрирует потенциал голосового управления в смешанной реальности посредством больших мультимодальных моделей, лишь слегка приоткрывает дверь в неизведанное. Истинный вызов заключается не в создании «помощника», а в формировании системы, способной к подлинному пониманию контекста — не просто распознаванию объектов, а улавливанию намерений, предвосхищению потребностей. Текущие модели, при всей своей впечатляющей мощи, остаются лишь сложными статистическими машинами, имитирующими интеллект. Настоящая проверка ждет их в условиях непредсказуемости реального мира, где двусмысленность и неполнота данных — норма, а не исключение.
Особый интерес представляет вопрос о «слепом пятне» подобных систем — о тех областях знаний и опыте, которые остаются за пределами их понимания. Обучение на огромных массивах данных не гарантирует интуиции или критического мышления. Необходимо исследовать возможности интеграции символьного и нейронного подходов, чтобы создать системы, способные к логическому выводу и абстрактному мышлению. В конечном счете, цель состоит не в том, чтобы заменить человеческий интеллект, а в его расширении — в создании симбиотического партнера, способного решать задачи, непосильные для любой из сторон в одиночку.
И, конечно, не стоит забывать о фундаментальных вопросах безопасности и этики. Система, обладающая глубоким пониманием контекста и способная влиять на реальный мир, требует строжайшего контроля и защиты от злоупотреблений. Правила создаются для того, чтобы их нарушать — и именно поэтому необходимо заранее продумать все возможные сценарии и разработать механизмы защиты от несанкционированного доступа и манипулирования.
Оригинал статьи: https://arxiv.org/pdf/2602.11025.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Макросъемка
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Как самому почистить матрицу. Продолжение.
- Российский рынок: между ставкой ЦБ, геополитикой и отчетами компаний (25.03.2026 17:32)
- Прогнозы цен на эфириум к рублю: анализ криптовалюты ETH
- Неважно, на что вы фотографируете!
- Пульт дистанционного управления для фотоаппарата
- MINISFORUM добавляет опцию Ryzen 9 8945HX в линейку мини-ПК MS-A2
- Как фотографировать на телефон.
2026-02-12 16:41