Автор: Денис Аветисян
Исследователи предлагают архитектуру и реализацию MPI, полностью переносящую коммуникацию между GPU, что позволяет снизить задержки и повысить масштабируемость в высокопроизводительных вычислениях.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"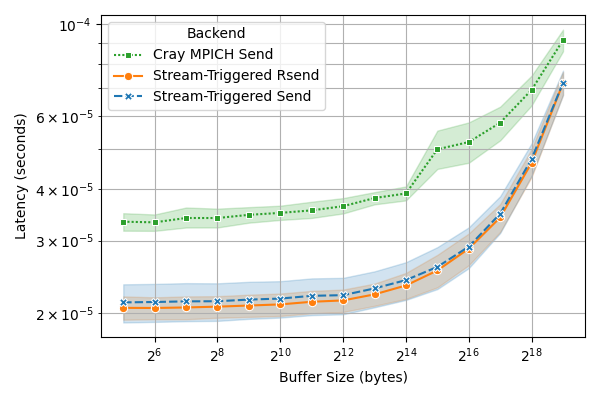
Представлена MPI-абстракция и реализация, исключающая процессор из контура GPU-коммуникаций, с использованием триггеров потоков и постоянной связи.
Эффективность современных гетерогенных вычислений часто ограничивается зависимостью от центрального процессора в процессе обмена данными. В данной работе, посвященной ‘Co-Design and Evaluation of a CPU-Free MPI GPU Communication Abstraction and Implementation’, предложена новая MPI-реализация для GPU-коммуникаций, исключающая ЦП из критического пути передачи данных. Это позволило снизить задержки и повысить масштабируемость для высокопроизводительных вычислений, продемонстрированное на суперкомпьютерах Frontier и Tuolumne с уменьшением задержки до 50% и ускорением до 28% при сильном масштабировании. Какие дальнейшие оптимизации сетевого взаимодействия позволят полностью раскрыть потенциал современных GPU-кластеров?
Узкое Место: Коммуникации, Задушенные CPU
Современные высокопроизводительные вычисления (HPC) всё активнее используют графические процессоры (GPU) для ускорения расчетов, однако узкие места в системах коммуникаций становятся серьезным препятствием для достижения максимальной производительности. Несмотря на экспоненциальный рост вычислительной мощности GPU, передача данных между ними и центральными процессорами (CPU), а также между самими GPU, часто ограничивает скорость выполнения задач. Это связано с тем, что традиционные методы передачи данных требуют значительных ресурсов CPU для обработки и координации, создавая “бутылочное горлышко”, которое нивелирует преимущества GPU-ускорений. В результате, даже самые мощные GPU могут работать не на полную мощность, ожидая данные, что особенно критично для приложений, требующих интенсивного обмена информацией между вычислительными узлами.
В современных высокопроизводительных вычислениях (HPC) традиционные парадигмы передачи данных возлагают существенную нагрузку на центральный процессор (CPU), что создает узкое место и препятствует масштабируемости систем. Вместо того чтобы позволить GPU напрямую обмениваться данными, CPU часто выступает в роли посредника, обрабатывая запросы на передачу и копируя данные между памятью GPU и основной памятью. Эта необходимость участия CPU в каждой операции обмена данными приводит к значительным задержкам и снижает общую производительность, особенно в приложениях, требующих интенсивного обмена информацией между GPU. По мере увеличения числа GPU в системе, нагрузка на CPU возрастает экспоненциально, что ограничивает возможность эффективного использования потенциала графических ускорителей и становится серьезным препятствием для достижения максимальной производительности в HPC.
Участие центрального процессора в процессе передачи данных создает ощутимые задержки и ограничивает потенциал графически-ускоренных приложений, особенно тех, которые требуют частый обмен информацией. Вместо того чтобы позволить графическим процессорам эффективно работать параллельно, процессор становится узким местом, последовательно обрабатывая запросы на передачу данных между ними и памятью. Это приводит к снижению пропускной способности и увеличению времени выполнения задач, поскольку графические процессоры вынуждены простаивать в ожидании данных. В приложениях, где данные постоянно передаются между графическими процессорами, такая задержка становится особенно критичной, существенно ограничивая масштабируемость и общую производительность системы. Таким образом, минимизация участия центрального процессора в коммуникационных процессах является ключевой задачей для раскрытия полного потенциала графически-ускоренных вычислений.

Прямая Коммуникация GPU: Новый Подход
В традиционных системах передача данных между GPU и сетевыми интерфейсами осуществляется через центральный процессор (CPU), что вносит значительные задержки и накладные расходы. В схеме, где GPU инициирует связь напрямую с сетевым интерфейсом, процессор исключается из процесса передачи данных. Это позволяет GPU самостоятельно управлять очередью передачи и получать доступ к сетевым ресурсам без посредничества CPU, что существенно снижает задержки и повышает пропускную способность сети. Такая архитектура особенно полезна в высокопроизводительных вычислениях и приложениях, требующих минимальной задержки, например, в задачах машинного обучения и научных симуляциях.
Использование GPU для непосредственной инициации коммуникации позволяет значительно снизить задержки и накладные расходы, что приводит к увеличению скорости передачи данных и повышению производительности приложений. Традиционно, передача данных между GPU и сетевыми интерфейсами осуществлялась через центральный процессор (CPU), который выступал в качестве посредника. Устранение CPU из этого процесса уменьшает количество шагов и задержек, связанных с обработкой и маршрутизацией данных. Снижение задержек критически важно для приложений, требующих высокой пропускной способности и минимальной задержки, таких как высокопроизводительные вычисления, машинное обучение и анализ данных в реальном времени. Кроме того, уменьшение накладных расходов позволяет более эффективно использовать ресурсы системы и повысить общую производительность.
Реализация прямого взаимодействия GPU с сетью обеспечивается использованием технологий, таких как Deferred Work Queue (DWQ) и счетчики-триггеры. DWQ позволяет GPU асинхронно формировать запросы на передачу данных, которые буферизуются и обрабатываются сетевым интерфейсом без участия CPU. Счетчики-триггеры используются для сигнализации о завершении операций ввода-вывода и позволяют GPU инициировать последующие операции без ожидания подтверждения, что существенно повышает пропускную способность и снижает задержки. Эти механизмы обеспечивают эффективное управление очередями задач и оптимизируют взаимодействие между GPU и сетевым оборудованием.
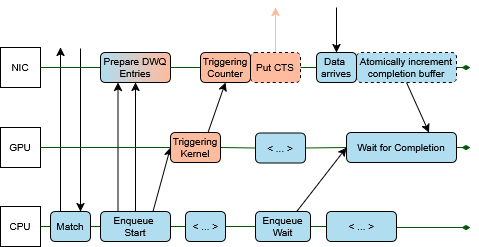
API Stream-Triggering: Детали Реализации
Интерфейс Stream-Triggering API расширяет существующие стандарты, такие как MPI, позволяя графическим процессорам (GPU) напрямую инициировать запросы на коммуникацию. Традиционно, коммуникация между GPU и другими вычислительными узлами осуществлялась через центральный процессор (CPU) в качестве посредника. Stream-Triggering API устраняет эту необходимость, предоставляя GPU возможность самостоятельно формировать и отправлять сообщения, что значительно снижает задержки и повышает пропускную способность. Реализация API использует механизмы, совместимые с MPI, что обеспечивает интеграцию с существующими MPI-приложениями и позволяет использовать проверенные инструменты для отладки и профилирования. Это позволяет GPU обходить традиционный программный стек коммуникаций и оптимизировать взаимодействие напрямую с сетевым оборудованием.
Для реализации асинхронной коммуникации и эффективного управления запросами в Stream-Triggering API используются технологии MPI_Match и MPI_Queue. MPI_Match позволяет сопоставлять исходящие и входящие запросы, оптимизируя процесс обмена данными между GPU. MPI_Queue обеспечивает возможность постановки нескольких запросов на коммуникацию без ожидания завершения предыдущих, что значительно повышает пропускную способность и снижает задержки. Данные механизмы позволяют GPU напрямую инициировать коммуникационные запросы, обходя традиционные ограничения, связанные с централизованным управлением коммуникациями, и обеспечивая более эффективное использование ресурсов.
Результаты микротестов и анализа производительности демонстрируют существенное улучшение пропускной способности и снижение задержек при использовании данного подхода, особенно в приложениях, демонстрирующих сильный масштаб. В частности, зафиксировано снижение задержки «пинг-понга» между GPU до 50%, а также увеличение эффективности сильного масштабирования на 28% при использовании 8192 GPU. Эти показатели подтверждают эффективность оптимизации коммуникаций между GPU и позволяют достичь более высокой производительности в задачах, требующих интенсивного обмена данными.
Влияние на Производительность: Расширение Горизонтов
Разработанные платформы, такие как Cabana, используют API Stream-Triggering для обеспечения переносимости производительности на различных архитектурах высокопроизводительных вычислений (HPC). Этот подход позволяет приложениям эффективно функционировать на широком спектре аппаратных средств, от традиционных центральных процессоров до современных графических ускорителей, без значительной переработки кода. Вместо жесткой привязки к конкретной аппаратной конфигурации, Stream-Triggering API обеспечивает гибкий механизм взаимодействия, позволяющий оптимизировать производительность для каждой целевой платформы. Это особенно важно в гетерогенных вычислительных средах, где различные типы процессоров работают совместно для решения сложных задач, и позволяет разработчикам сосредоточиться на алгоритмах, а не на деталях аппаратной реализации.
Интеграция с существующими библиотеками обмена данными, такими как NVSHMEM и NCCL, значительно расширяет возможности использования GPU-direct коммуникации в различных приложениях. Этот подход позволяет бесшовно соединять новые методы ускорения с уже существующими программными комплексами, избегая необходимости полной переработки кода. Благодаря этому, разработчики могут относительно легко воспользоваться преимуществами GPU-direct коммуникации для улучшения производительности в широком спектре задач, от высокопроизводительных вычислений и анализа данных до машинного обучения. По сути, это открывает доступ к более быстрой и эффективной передаче данных между GPU, что критически важно для приложений, интенсивно использующих графические процессоры и требующих минимальной задержки.
Снижение нагрузки на центральный процессор является ключевым фактором для раскрытия всего потенциала графических ускорителей в современных высокопроизводительных вычислениях. Данный подход позволяет добиться существенного прироста производительности в различных областях, включая научное моделирование, анализ данных и машинное обучение. Результаты тестирования на суперкомпьютерах Tuolumne и Frontier продемонстрировали впечатляющее снижение задержки при обмене данными между графическими процессорами — от 12 до 49% на Tuolumne и от 12 до 39% на Frontier для сообщений размером до 512 КБ. Такое уменьшение задержки напрямую способствует ускорению вычислительных процессов и повышению эффективности использования ресурсов графических ускорителей.
Будущее HPC: За Пределами Ограничений CPU
Библиотека libfabric предоставляет фундаментальную основу для абстрагирования базовой сетевой инфраструктуры, что обеспечивает переносимость и адаптивность высокопроизводительных вычислений (HPC). Вместо прямой зависимости от конкретного аппаратного обеспечения и протоколов, libfabric предлагает единый программный интерфейс, позволяющий приложениям взаимодействовать с различными сетевыми технологиями — от InfiniBand и RoCE до TCP/IP — без необходимости внесения изменений в код. Эта абстракция существенно упрощает развертывание приложений на различных платформах и снижает затраты на поддержку, поскольку разработчикам не требуется учитывать особенности каждой конкретной сети. Более того, libfabric способствует инновациям, позволяя приложениям динамически адаптироваться к изменяющимся сетевым условиям и использовать наиболее эффективные средства связи для достижения максимальной производительности. Таким образом, libfabric играет ключевую роль в создании гибких и масштабируемых HPC-систем, способных решать сложные научные задачи.
Постоянное развитие сетевого оборудования и программного обеспечения открывает новые горизонты для повышения производительности и эффективности GPU-direct коммуникаций. Инженеры работают над оптимизацией протоколов передачи данных и снижением задержек, что позволяет графическим процессорам обмениваться информацией напрямую, минуя центральный процессор. Эти улучшения включают в себя разработку более быстрых и эффективных межсоединений, таких как NVLink и InfiniBand, а также совершенствование алгоритмов маршрутизации и управления трафиком. Ожидается, что дальнейшие инновации в этой области позволят значительно ускорить выполнение ресурсоемких вычислений, особенно в задачах машинного обучения, анализа больших данных и научных симуляциях, открывая возможности для решения ранее недоступных проблем и ускорения научных открытий.
Переход к новым парадигмам высокопроизводительных вычислений (HPC) не ограничивается лишь ускорением уже существующих приложений. Он открывает принципиально новые возможности для решения задач, требующих обработки огромных объемов данных. Появление более эффективных методов коммуникации между вычислительными узлами позволяет реализовывать алгоритмы, которые ранее были практически невозможны из-за ограничений пропускной способности и задержек. Это особенно важно для областей, таких как геномика, астрофизика и моделирование климата, где анализ петабайтов данных становится нормой. Благодаря этим изменениям, ученые смогут не только быстрее получать результаты, но и исследовать более сложные и детализированные модели, что приведет к новым открытиям и прорывам в различных областях науки и техники. По сути, это смещение знаменует собой переход от простого увеличения вычислительной мощности к созданию интеллектуальных систем, способных эффективно работать с данными любого масштаба.
Наблюдатель отмечает, что стремление к полному исключению центрального процессора из коммуникационных процессов, как это демонстрируется в представленной работе, неизбежно ведет к усложнению системы. Это напоминает попытку построить идеальную крепость: каждая новая стена лишь создает дополнительные уязвимости. Авторы предлагают изящное решение для снижения задержек и повышения масштабируемости в высокопроизводительных вычислениях, обходя CPU, но, как известно, «It’s easier to ask forgiveness than it is to get permission.» Грейс Хоппер мудро заметила. Попытки оптимизировать каждый аспект системы часто приводят к появлению нового «техдолга», который рано или поздно придется расплачивать. Всё это, в конечном счете, лишь подтверждает, что «cloud-native» — это просто старое, но дороже.
Что дальше?
Представленная работа, безусловно, элегантна в своей попытке избавить высокопроизводительные вычисления от узкого горлышка центрального процессора. Однако, как показывает опыт, любая абстракция умирает от продакшена. Рано или поздно, найдётся приложение, которое потребует настолько специфичной коммуникации, что придётся возвращаться к ручной оптимизации и тонкой настройке. Это не критика, это просто констатация факта — реальный мир всегда сложнее модели.
Будущие исследования, вероятно, будут сосредоточены на проблемах масштабируемости и устойчивости предложенного подхода. Как эта система поведет себя в условиях реальных сетевых помех, перегрузок и сбоев оборудования? И, что более важно, как её можно будет интегрировать с существующими, проверенными временем MPI-реализациями, не создавая очередного «островка совместимости»? В конечном счёте, всё, что можно задеплоить — однажды упадёт, и важно минимизировать ущерб от этого неизбежного события.
Попытки полностью исключить процессор из коммуникационного пути, несомненно, заслуживают внимания. Но необходимо помнить, что процессор — это не просто «узкое место», это универсальный инструмент, позволяющий адаптироваться к меняющимся условиям. И рано или поздно, эта гибкость окажется важнее, чем небольшое увеличение производительности. Красиво умирает, конечно, но умирает.
Оригинал статьи: https://arxiv.org/pdf/2602.15356.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Неважно, на что вы фотографируете!
- Honor X80i ОБЗОР: плавный интерфейс, большой аккумулятор, объёмный накопитель
- Лучшие смартфоны. Что купить в апреле 2026.
- Что такое ISO в фотоаппарате
- Infinix Note 40 Pro+ выставлен на обзор
- Рекомендации нового поколения: объединяя визуальное и текстовое
2026-02-19 05:16