Автор: Денис Аветисян
Обзор посвящен стремительному развитию методов обнаружения ложной информации с использованием больших языковых моделей, способных анализировать текст и изображения.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"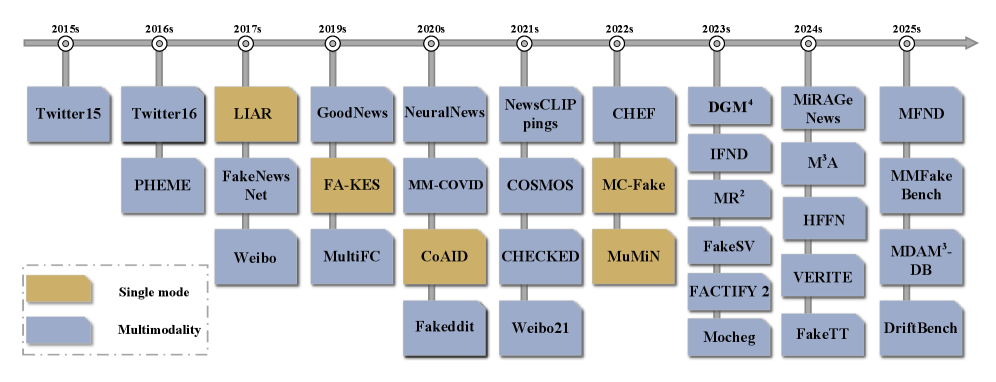
Всесторонний анализ современных подходов к мультимодальному выявлению фейковых новостей с использованием больших моделей, объединяющих зрение и язык, а также обзор ключевых проблем и перспективных направлений исследований.
Несмотря на растущую распространенность мультимодальной дезинформации, традиционные подходы к ее выявлению часто оказываются неэффективными в улавливании сложных семантических связей между текстом и изображениями. В данной работе, ‘The Paradigm Shift: A Comprehensive Survey on Large Vision Language Models for Multimodal Fake News Detection’, представлен всесторонний обзор современного состояния исследований в области выявления мультимодальной дезинформации с использованием больших моделей, объединяющих обработку зрения и языка. Обзор систематизирует существующие подходы, выявляет ключевые проблемы, такие как надежность и интерпретируемость, и определяет перспективные направления развития, включая интеграцию знаний и смягчение галлюцинаций моделей. Какие инновационные решения позволят эффективно противостоять распространению мультимодальной дезинформации и обеспечить достоверность информации в цифровой среде?
Элегантность в Многообразии: Введение в Мультимодальный Обман
В эпоху цифровых технологий наблюдается экспоненциальный рост объёма мультимодального контента — сочетания текста, изображений и видеоматериалов. Эта тенденция, с одной стороны, открывает новые возможности для коммуникации и обмена информацией, но, с другой, создаёт благодатную почву для распространения дезинформации и фейковых новостей. Злоумышленники всё чаще используют комбинацию различных форматов для манипулирования общественным мнением, создавая убедительные, но ложные нарративы. Изображения и видео, особенно в сочетании с вводящим в заблуждение текстом, способны значительно усилить воздействие дезинформации, делая её более правдоподобной и вирусной. В результате традиционные методы выявления фейков, ориентированные на анализ только текстового контента, становятся всё менее эффективными в борьбе с этой новой формой обмана.
Традиционные методы обнаружения фейковых новостей, основанные преимущественно на анализе текстового содержания, оказываются неэффективными перед лицом все более изощренных схем дезинформации. Сложность заключается в том, что современные манипуляции часто используют согласованный, но ложный нарратив, представленный в различных модальностях — тексте, изображениях и видео. Простые алгоритмы, выявляющие несоответствия в тексте, не способны уловить противоречия между визуальным рядом и текстовым описанием, или же не учитывают контекст, в котором представлен мультимедийный контент. Например, сфабрикованное изображение может быть подкреплено убедительным, но ложным текстовым сообщением, создавая иллюзию достоверности, которую существующие системы часто не способны распознать. Таким образом, для эффективной борьбы с дезинформацией необходимы новые подходы, способные комплексно анализировать информацию, представленную в различных форматах, и выявлять несоответствия между ними.
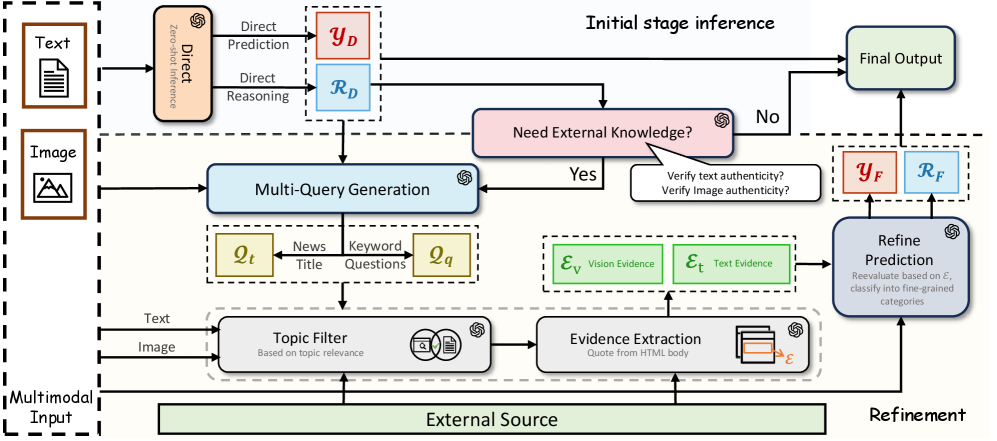
Для эффективного противодействия распространению дезинформации в современном цифровом пространстве требуется разработка продвинутых систем искусственного интеллекта, способных к комплексному анализу мультимодального контента. Такие системы должны не просто распознавать отдельные элементы — текст, изображение или видео — но и понимать взаимосвязи между ними, выявляя несоответствия и манипуляции, которые остаются незамеченными при анализе каждого модальности по отдельности. Необходимость кросс-модального рассуждения обусловлена тем, что ложные нарративы часто строятся на сочетании правдивых и ложных элементов, представленных в различных форматах, что требует от ИИ способности к интеграции информации и выявлению скрытых противоречий. Разработка подобных систем представляет собой сложную задачу, требующую новых алгоритмов и подходов к машинному обучению, способных эффективно обрабатывать и интерпретировать данные, представленные в различных модальностях.
Визуальные и Текстовые Модели: Гармония в Анализе Данных
Большие визуально-языковые модели (LVLM) активно внедряются в задачи, требующие обработки мультимодальных данных, то есть информации, представленной в виде изображений и текста. Эти модели используют архитектуры, позволяющие одновременно анализировать визуальные признаки, извлекаемые из изображений, и семантическое содержание текстовых данных. Такой подход позволяет LVLM решать широкий спектр задач, включая визуальный вопрос-ответ, генерацию подписей к изображениям, а также анализ и понимание мультимедийного контента, объединяя информацию из различных источников для достижения более высокого уровня понимания и принятия решений.
Адаптация больших визуально-языковых моделей (LVLM) к конкретным задачам может быть осуществлена посредством техник заморозки параметров (parameter freezing) и тонкой настройки параметров (parameter tuning). Заморозка параметров подразумевает фиксацию весов большей части модели, обучая лишь небольшое количество параметров, что снижает вычислительные затраты и предотвращает переобучение, особенно при работе с ограниченными данными. Тонкая настройка параметров, напротив, предполагает обучение всех или большей части параметров модели на новом наборе данных, обеспечивая более высокую производительность, но требуя значительно больше вычислительных ресурсов и времени. Выбор между этими подходами зависит от доступных ресурсов, размера целевого набора данных и требуемой степени точности.
Эффективное проектирование запросов (prompt engineering) играет ключевую роль в управлении вниманием больших визуально-языковых моделей (LVLM) и повышении точности рассуждений. Это достигается путем формулирования запросов, которые направляют модель на релевантную информацию в визуальном и текстовом контенте. Механизмы перекрестного внимания (cross-attention) дополнительно усиливают способность LVLM к интеграции информации из различных модальностей, позволяя модели устанавливать связи между визуальными элементами и соответствующим текстом. В процессе работы механизм перекрестного внимания определяет, какие части изображения наиболее важны для понимания текста запроса и наоборот, обеспечивая более точное и контекстуально-осведомленное рассуждение.
Современные большие визуально-языковые модели (LVLM) демонстрируют общую точность около 92% в задачах обнаружения мультимодальной дезинформации. Однако, эффективность LVLM существенно варьируется в зависимости от используемого набора данных. Различия в структуре данных, объеме выборки, а также специфике фейковых новостей в каждом наборе данных приводят к колебаниям точности. Например, модели могут показывать более высокую производительность на наборах данных, содержащих изображения с явными признаками манипуляции, и более низкую — на данных, где дезинформация представлена более тонко и требует сложного анализа контекста. Таким образом, при оценке эффективности LVLM в задачах обнаружения фейковых новостей необходимо учитывать специфику используемого набора данных и избегать обобщений на основе результатов, полученных только на одном датасете.
Иллюзии Разума: Преодоление Галлюцинаций в Моделях
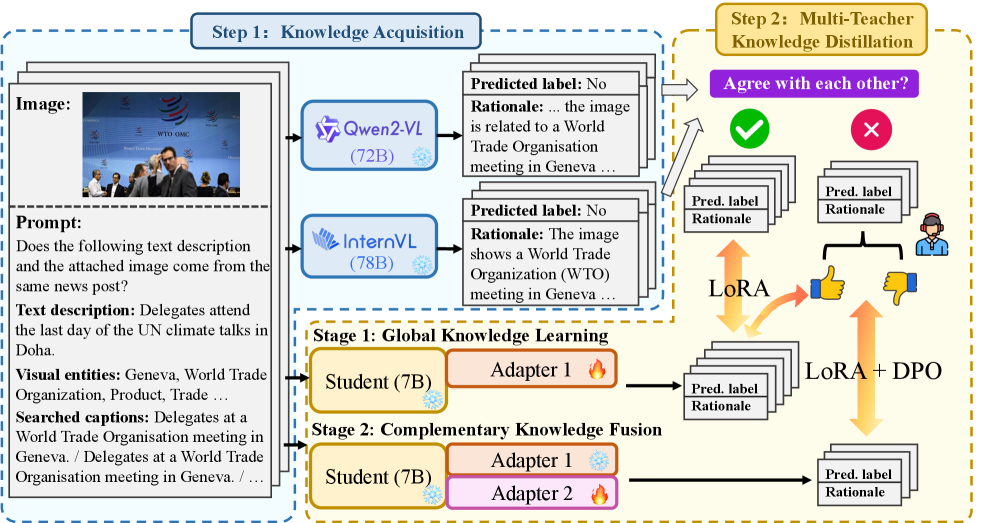
Визуально-языковые большие языковые модели (LVLM) способны генерировать мультимодальные галлюцинации, проявляющиеся в создании ложной или вводящей в заблуждение информации, охватывающей как текстовые, так и визуальные компоненты. Это означает, что модель может сгенерировать описание изображения, которое не соответствует содержанию самого изображения, или же создать визуальное представление, не соответствующее предоставленному текстовому описанию. Галлюцинации не являются случайными ошибками, а представляют собой систематические отклонения от фактических данных, что может приводить к дезинформации и снижению доверия к системе. Причины возникновения галлюцинаций включают неполноту или предвзятость обучающих данных, а также ограничения в способности модели к логическому выводу и пониманию контекста.
Методы смягчения последствий галлюцинаций на этапе инференса, такие как селективная интервенция в слои модели, представляют собой перспективный подход к снижению количества ложной или вводящей в заблуждение информации, генерируемой большими визуально-языковыми моделями (LVLMs). В отличие от дорогостоящей переподготовки модели, эти методы направлены на корректировку процесса рассуждений модели непосредственно во время генерации ответа. Селективная интервенция позволяет целенаправленно изменять активации определенных слоев, что способствует более точной привязке к входным данным и снижает вероятность фабрикации контента, не основанного на реальных данных. Такой подход позволяет улучшить надежность модели без необходимости внесения изменений в ее архитектуру или веса.
Методы вмешательства на этапе инференса, направленные на корректировку процесса рассуждений языковой модели, достигают снижения галлюцинаций путем активного управления генерацией контента. Вместо переобучения всей модели, эти техники фокусируются на изменении промежуточных представлений или вероятностей на этапах вывода. Это достигается путем анализа и модификации активаций определенных слоев сети, что позволяет модели более точно опираться на входные данные и избегать фабрикации информации, не подкрепленной входным контекстом. Эффективность подхода заключается в динамической адаптации процесса генерации, обеспечивающей большую согласованность с исходными данными и снижающей вероятность появления ложных или вводящих в заблуждение результатов.
Квантизация моделей до 8-бит является распространенным методом снижения их размера и задержки, что особенно важно для развертывания на устройствах с ограниченными ресурсами. Этот процесс подразумевает уменьшение точности представления весов и активаций в нейронной сети с 32-битной (float32) до 8-битной (int8) точности. Несмотря на значительное уменьшение размера модели и ускорение вычислений, квантизация может приводить к некоторой потере точности, поскольку уменьшение разрядности приводит к снижению точности представления числовых значений. Для смягчения этого эффекта применяются различные методы калибровки и fine-tuning, направленные на минимизацию потери производительности после квантизации.
За рамками Точности: Надежность и Доверие к Мультимодальному ИИ
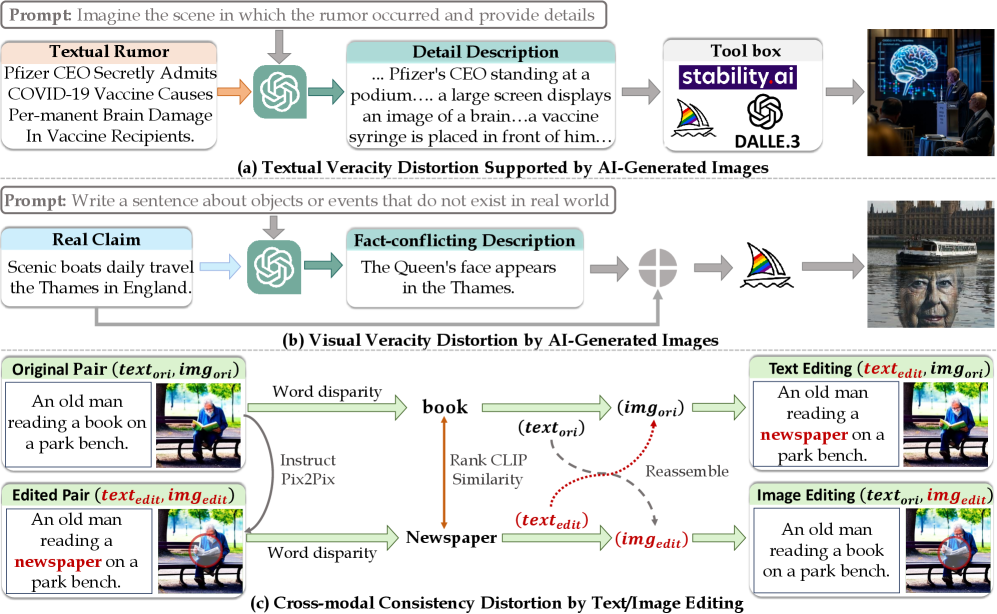
Большие языковые модели, работающие с визуальной информацией (LVLM), часто демонстрируют предвзятость, унаследованную от обучающих наборов данных. Это означает, что предсказания модели могут быть неточными или несправедливыми, особенно в ситуациях, отличающихся от тех, что представлены в данных для обучения. Например, если набор данных содержит преимущественно изображения определенной этнической группы, модель может показывать сниженную точность при анализе изображений представителей других групп. Данная предвзятость возникает из-за того, что модель учится соотносить определенные визуальные признаки с определенными категориями или предсказаниями, и эти связи могут быть искажены, если обучающие данные не являются репрезентативными и сбалансированными. В результате, использование таких моделей в критически важных приложениях, таких как распознавание лиц или автоматизированное принятие решений, может приводить к дискриминационным результатам и требовать тщательной оценки и смягчения последствий предвзятости.
Для повышения устойчивости больших визуально-языковых моделей (LVLM) к непредсказуемым входным данным и потенциальным атакам, активно применяются методы, известные как состязательное обучение. Суть данного подхода заключается в намеренном создании слегка модифицированных, но визуально или семантически близких примеров, способных вызвать ошибки в работе модели. Эти «состязательные» примеры, часто незаметные для человеческого глаза, заставляют LVLM пересматривать свои прогнозы и учиться различать тонкие, но важные различия в данных. Регулярное воздействие модели такими сложными случаями способствует развитию ее способности к обобщению и снижает уязвимость к шуму или искажениям в реальных сценариях, что делает систему более надежной и предсказуемой в различных условиях эксплуатации.
Для повышения способности больших визуально-языковых моделей (LVLM) к рассуждениям и адаптации к новым, ранее не встречавшимся данным, активно исследуется улучшение согласованности между визуальной и текстовой информацией. Этот процесс включает в себя не просто сопоставление изображения и текста, но и глубокое понимание взаимосвязей между ними. В частности, интеграция графов знаний позволяет моделям использовать структурированную информацию о мире, что значительно повышает их способность к логическим выводам и обобщениям. Благодаря такому подходу, LVLM способны не только распознавать объекты на изображении и описывать их, но и понимать контекст, причинно-следственные связи и делать более обоснованные прогнозы, даже в ситуациях, отличающихся от тех, на которых они обучались. Таким образом, развитие кросс-модального выравнивания и использование графов знаний открывает путь к созданию более надежных и интеллектуальных систем искусственного интеллекта.
Для построения доверия к большим визуально-языковым моделям (LVLM) принципиально важна разработка методов объяснимого искусственного интеллекта (XAI). Недостаточно просто получить точный результат; необходимо понимать, как модель пришла к этому выводу. XAI предоставляет инструменты для анализа процесса принятия решений LVLM, выявляя, какие визуальные признаки и языковые конструкции оказали наибольшее влияние на результат. Это позволяет не только верифицировать корректность работы модели, но и обнаруживать потенциальные смещения или уязвимости, а также повышать уверенность пользователей в надежности и прозрачности системы. Развитие XAI для LVLM — это ключевой шаг к созданию искусственного интеллекта, который можно не только использовать, но и понимать.
Разрабатываемые архитектуры больших языковых моделей визуального ряда стремятся к десятикратному увеличению скорости обработки по сравнению с традиционными монолитными моделями. Этот амбициозный план предполагает отказ от единой, огромной нейронной сети в пользу более модульных и параллельных структур. Вместо последовательной обработки информации, новые подходы фокусируются на распределении задач между специализированными компонентами, что потенциально позволит значительно сократить время отклика и повысить эффективность использования вычислительных ресурсов. Несмотря на то, что достижение десятикратного ускорения остается пока целью, прогресс в области оптимизации моделей и аппаратного обеспечения указывает на перспективность такого подхода к созданию более быстрых и доступных систем обработки визуальной информации.
Будущее Мультимодального Рассуждения: За горизонтом возможностей
Методы, подобные WisdoM, представляют собой перспективное направление в развитии мультимодального рассуждения, поскольку они не полагаются на заранее заданные знания, а генерируют и объединяют информацию динамически в процессе анализа. Этот подход позволяет системе адаптироваться к новым ситуациям и более эффективно обрабатывать сложные запросы, требующие интеграции данных из различных источников — текста, изображений, аудио и видео. В отличие от традиционных моделей, которые ограничены своим набором предварительно обученных параметров, WisdoM способен формировать новые знания, необходимые для решения конкретной задачи, и тем самым демонстрирует повышенную устойчивость к неполной или противоречивой информации. Благодаря этой гибкости и способности к обучению в процессе работы, подобные методы открывают возможности для создания более надежных и универсальных систем искусственного интеллекта, способных решать широкий спектр задач, требующих сложного мультимодального анализа.
Интеграция контрфактического рассуждения открывает перед большими визуально-языковыми моделями (LVLM) возможность не просто констатировать факты, но и исследовать альтернативные варианты развития событий. Этот подход позволяет моделям задавать вопросы типа “Что, если бы…?” и оценивать, насколько обоснованы их первоначальные выводы в свете измененных условий. Вместо пассивного принятия информации, LVLM начинают активно анализировать причинно-следственные связи, выявляя слабые места в своих рассуждениях и повышая надежность принимаемых решений. Например, модель может проанализировать изображение и текст, а затем, изменяя ключевые элементы сценария, оценить, как это повлияет на конечный результат, демонстрируя тем самым способность к более глубокому и критическому мышлению.
Для оценки эффективности систем обнаружения фейковых новостей, использующих мультимодальный подход, активно применяются специализированные наборы данных, среди которых значительное место занимает FakeNewsNet. Этот ресурс предоставляет обширную коллекцию новостных статей, сопровождаемых информацией из различных источников, включая текст, изображения и социальные сети. Наличие размеченных данных, указывающих на достоверность информации, позволяет разработчикам обучать и тестировать алгоритмы, направленные на выявление манипуляций и дезинформации. FakeNewsNet не только служит эталоном для сравнения различных моделей, но и способствует развитию новых методов, учитывающих взаимосвязь между текстовым содержанием и визуальными компонентами, что критически важно для борьбы с распространением ложной информации в современном цифровом пространстве.
Постоянное совершенствование и всесторонняя оценка являются ключевыми факторами для обеспечения надёжности и доверия к мультимодальным системам искусственного интеллекта. В условиях быстрого развития технологий, недостаточно просто создать модель, способную обрабатывать информацию из различных источников; необходимо регулярно проводить тестирование в реалистичных сценариях, выявлять слабые места и оперативно внедрять улучшения. Особое внимание уделяется не только точности, но и устойчивости к искажениям, а также способности к адаптации к новым данным и задачам. Внедрение автоматизированных систем мониторинга и оценки позволяет выявлять отклонения от ожидаемого поведения и предотвращать потенциальные ошибки, что в конечном итоге способствует формированию более надёжных и заслуживающих доверия решений в области мультимодального ИИ.
Разрабатываются новые метрики оценки для мультимодальных систем, делающие акцент на “правдивости” (faithfulness) — способности модели обосновывать свои выводы представленными доказательствами. Эти метрики направлены на количественную оценку степени, в которой ответы модели действительно основаны на входных данных, а не на внутренних предубеждениях или галлюцинациях — генерации неправдоподобной или нерелевантной информации. Оценка “обоснованности” (evidence grounding) позволяет определить, насколько полно и точно модель использует доступные доказательства, в то время как измерение частоты “галлюцинаций” выявляет склонность модели к генерации ложных утверждений. Внедрение подобных метрик крайне важно для повышения надежности и достоверности мультимодального искусственного интеллекта, особенно в критически важных приложениях, где точность и обоснованность являются первостепенными.
Исследование демонстрирует, что современные системы обнаружения фейковых новостей, использующие большие визуально-языковые модели, всё чаще сталкиваются с проблемой устойчивости и объяснимости. Подобно тому, как сложно предсказать все последствия изменения в сложной системе, модели оказываются уязвимы к незначительным искажениям во входных данных. Как отмечал Эдсгер Дейкстра: «Программа без структуры — это лишь усложненная манера делать что-либо неверно». Эта фраза подчеркивает важность четкой архитектуры и понимания взаимосвязей между компонентами системы. Работа указывает на необходимость интеграции внешних знаний и смягчения галлюцинаций модели для повышения её надёжности и прозрачности, ведь только хорошо структурированная система способна давать предсказуемые и достоверные результаты.
Куда двигаться дальше?
Представленный обзор, как и любая попытка систематизации бурно развивающейся области, лишь подчеркивает глубину нерешенных вопросов. Модели, оперирующие с мультимodalльными данными, демонстрируют впечатляющую способность к распознаванию манипуляций, однако их внутренняя логика зачастую остается непрозрачной. В конечном счете, эффективная система выявления дезинформации — это не просто алгоритм, а сложная инфраструктура, требующая постоянной адаптации и верификации. Необходимо избегать соблазна «перестраивать квартал» каждый раз, когда обнаруживается новая уязвимость.
Ключевым направлением представляется не просто увеличение объема знаний, «закачиваемых» в модели, а развитие способности к критическому анализу и выявлению внутренних противоречий. Элегантное решение должно исходить из простоты и ясности — достаточность, а не избыточность, должна определять структуру системы. Недостаточная устойчивость к намеренным искажениям и склонность к «галлюцинациям» — это не просто технические недостатки, а фундаментальные проблемы, связанные с отсутствием глубокого понимания контекста и семантики.
В конечном итоге, успех в этой области будет зависеть не от создания «всезнающего» алгоритма, а от формирования экосистемы, в которой люди и машины совместно работают над выявлением и противодействием дезинформации. Подобно живому организму, система должна постоянно эволюционировать, адаптироваться к новым угрозам и учиться на своих ошибках. Игнорирование этой простой истины чревато серьезными последствиями.
Оригинал статьи: https://arxiv.org/pdf/2601.15316.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Российский рынок: Оптимизм на фоне геополитики и корпоративных сделок (20.01.2026 00:32)
- Российская экономика 2025: Рекорды энергопотребления, падение добычи и укрепление рубля (22.01.2026 17:32)
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Сургутнефтегаз акции привилегированные прогноз. Цена SNGSP
- Что такое виньетирование? Коррекция периферийного освещения в Кэнон.
- Lava Agni 4 ОБЗОР: большой аккумулятор, яркий экран, плавный интерфейс
- Типы дисплеев. Какой монитор выбрать?
- Новые смартфоны. Что купить в январе 2026.
- Xiaomi Redmi A3 Pro ОБЗОР: большой аккумулятор, удобный сенсор отпечатков
- Huawei P30 pro
2026-01-24 06:27