Автор: Денис Аветисян
Исследователи разработали иерархическую систему управления, позволяющую роботам выполнять сложные манипуляции с объектами, не требующие захвата, с высокой точностью и надежностью.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"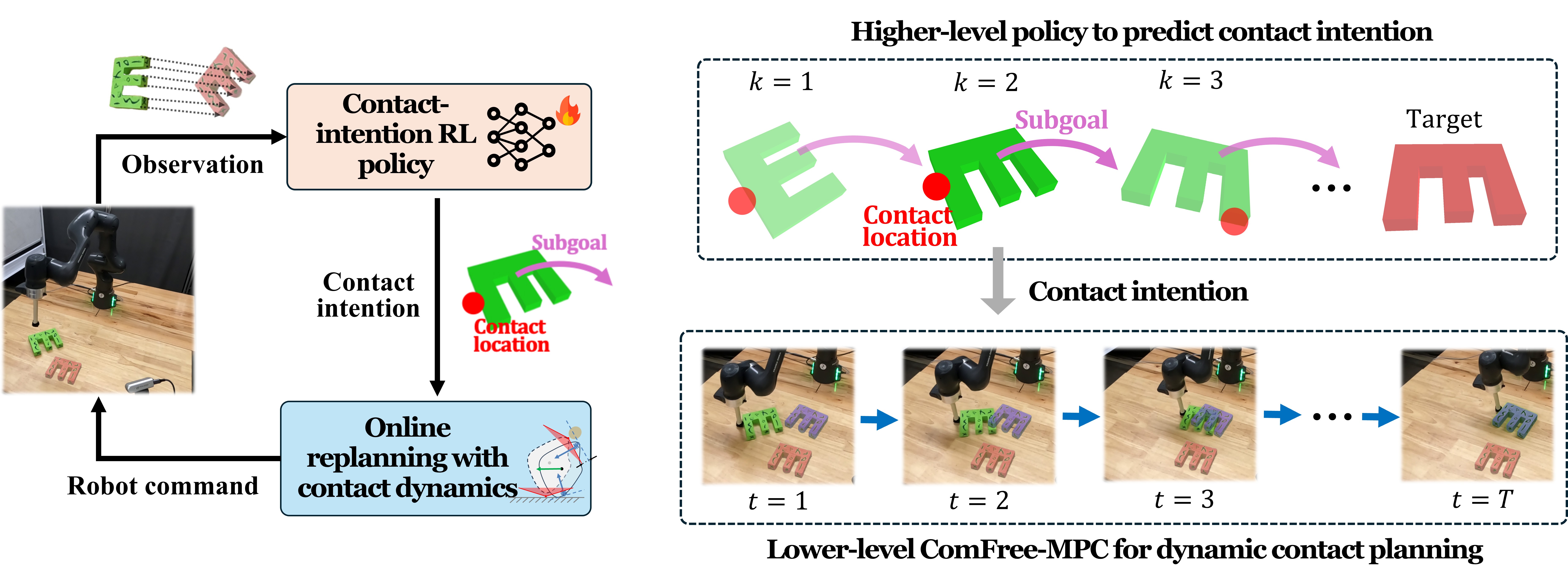
Предложенная иерархическая структура, объединяющая обучение с подкреплением и предсказательное управление, обеспечивает эффективное и обобщаемое манипулирование, а также успешный перенос результатов из симуляции в реальный мир.
Несмотря на значительный прогресс в области робототехники, сложные манипуляции, требующие одновременного учета геометрии, кинематических ограничений и динамики контактов, остаются сложной задачей. В работе ‘Where to Touch, How to Contact: Hierarchical RL-MPC Framework for Geometry-Aware Long-Horizon Dexterous Manipulation’ предложен иерархический подход, объединяющий обучение с подкреплением и модельно-прогнозирующее управление, для эффективного решения задач манипулирования. Ключевым нововведением является разделение планирования на геометрическом и кинематическом уровнях от управления динамикой контактов, что обеспечивает высокую эффективность, устойчивость и обобщающую способность, особенно в задачах не-захватного манипулирования. Возможно ли дальнейшее развитие данного подхода для решения более сложных задач и расширения области применения робототехнических систем?
Взлом Ловкости: Вызовы Управления Роботами
Достижение подлинно ловкой манипуляции остается ключевой задачей в робототехнике, требующей разработки сложных и адаптивных стратегий управления. В отличие от промышленных роботов, выполняющих повторяющиеся действия в контролируемой среде, создание робота, способного выполнять разнообразные задачи в непредсказуемой обстановке, сопоставимо с координацией человеческой руки. Это подразумевает не просто точное следование запрограммированному движению, но и способность реагировать на изменяющиеся условия, учитывать свойства объектов, с которыми взаимодействует робот, и адаптировать усилия, чтобы избежать повреждений или обеспечить надежный захват. Такие системы требуют продвинутых алгоритмов, способных обрабатывать сенсорную информацию в реальном времени, прогнозировать динамику контакта и генерировать оптимальные траектории движения, что представляет собой серьезный вызов для современных вычислительных мощностей и методов искусственного интеллекта.
Традиционные методы управления роботами часто сталкиваются с серьезными трудностями при работе с контактной динамикой и непредсказуемыми условиями окружающей среды. Они, как правило, опираются на точные модели взаимодействия объекта с миром, которые, однако, редко соответствуют реальности. Неопределенности в трении, деформации материалов и неточности сенсоров приводят к отклонениям в поведении робота, делая выполнение сложных манипуляций, таких как захват хрупких предметов или сборка сложных конструкций, крайне сложной задачей. В условиях постоянно меняющейся обстановки, когда робот сталкивается с неожиданными препятствиями или необходимостью адаптироваться к новым задачам, традиционные алгоритмы часто оказываются неэффективными, требуя постоянной корректировки и перенастройки, что значительно ограничивает их применимость в реальных сценариях.
Масштабирование методов управления роботами для выполнения разнообразных задач и адаптации к реальным условиям представляет собой значительную вычислительную проблему. Разработка алгоритмов, способных обрабатывать бесконечное количество вариаций в окружающей среде — от незначительных изменений в текстуре поверхности до неожиданных препятствий — требует огромных объемов данных для обучения и мощных вычислительных ресурсов для обработки информации в реальном времени. По мере увеличения сложности задачи и количества степеней свободы манипулятора, потребность в вычислительной мощности и данных возрастает экспоненциально, что делает создание универсальных и надежных систем управления сложной задачей. Это обусловлено тем, что каждый новый объект, материал или незначительное изменение в окружении требует повторной калибровки и обучения алгоритмов, что делает текущие подходы зачастую непрактичными для широкого спектра применений.

Иерархическое Рассуждение: Разбиение Сложного на Простое
Иерархическое рассуждение представляет собой эффективный подход к решению сложных задач манипулирования, заключающийся в декомпозиции общей цели на последовательность более простых и управляемых подцелей. Этот метод позволяет разделить сложную задачу на отдельные этапы, каждый из которых может быть спланирован и выполнен независимо. Например, сборка объекта может быть разбита на подцели: захват детали, перемещение к месту установки, ориентация и вставка. Такая декомпозиция значительно упрощает процесс планирования и позволяет роботу эффективно решать задачи, которые были бы невыполнимы при попытке прямого планирования всего действия как единого целого. Применение иерархического подхода снижает вычислительную сложность и повышает надежность выполнения сложных манипуляций.
Геометрико-кинематическое рассуждение и рассуждение о динамике контакта являются ключевыми компонентами планирования движений роботов. Геометрико-кинематическое рассуждение позволяет определять возможные конфигурации робота и объектов в пространстве, учитывая ограничения суставов и геометрию окружения. Рассуждение о динамике контакта анализирует силы и моменты, возникающие при взаимодействии робота с объектами, включая трение, столкновения и распределение нагрузки. Комбинируя эти два подхода, робот может прогнозировать результаты своих действий, избегать столкновений и эффективно манипулировать объектами, что необходимо для решения сложных задач.
Определение высокоуровневых намерений контакта позволяет роботам стратегически ориентироваться в сложных сценариях и адаптироваться к меняющимся условиям. Вместо планирования каждой отдельной траектории движения, робот определяет желаемый результат контакта (например, «захватить объект», «установить опору», «отвести препятствие») и позволяет системе планирования самостоятельно разработать необходимые последовательности действий. Такой подход значительно упрощает задачу планирования, особенно в условиях неопределенности или при наличии большого количества степеней свободы. Определение намерений контакта позволяет роботу перепланировать действия в реальном времени, если первоначальный план становится невозможным из-за неожиданных изменений в окружающей среде или характеристиках объекта. Это повышает надежность и гибкость робота при выполнении сложных манипуляций.
Сближение Теории и Практики: RL-MPC и Объектно-Ориентированные Представления
Фреймворк RL-MPC объединяет преимущества обучения с подкреплением (RL) и модельно-прогнозного управления (MPC) для обеспечения адаптивного и оптимального управления роботами. MPC использует модель динамики системы для прогнозирования будущего поведения и оптимизации управляющих воздействий на заданном горизонте планирования. В свою очередь, RL позволяет обучать политику управления на основе опыта, что особенно важно в сложных или не полностью известных средах. В RL-MPC, RL используется для обучения модели динамики или непосредственно политики управления, которая затем используется в MPC для планирования и управления. Такой подход позволяет системе адаптироваться к изменяющимся условиям и оптимизировать свои действия для достижения поставленных целей, сочетая способность MPC к точной оптимизации с обучаемостью и адаптивностью RL.
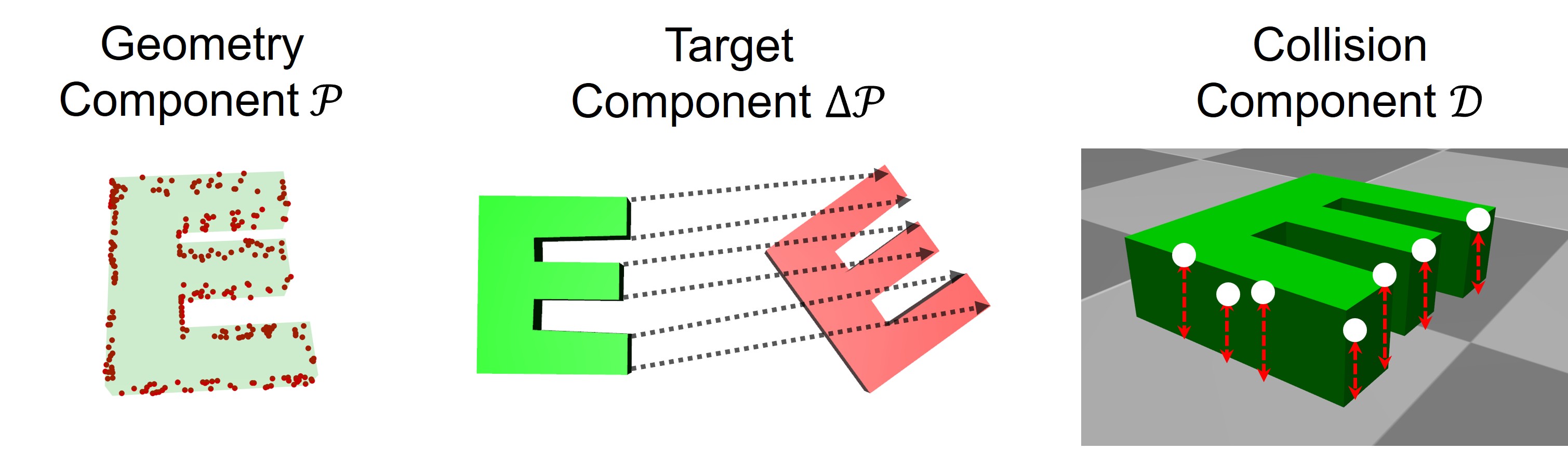
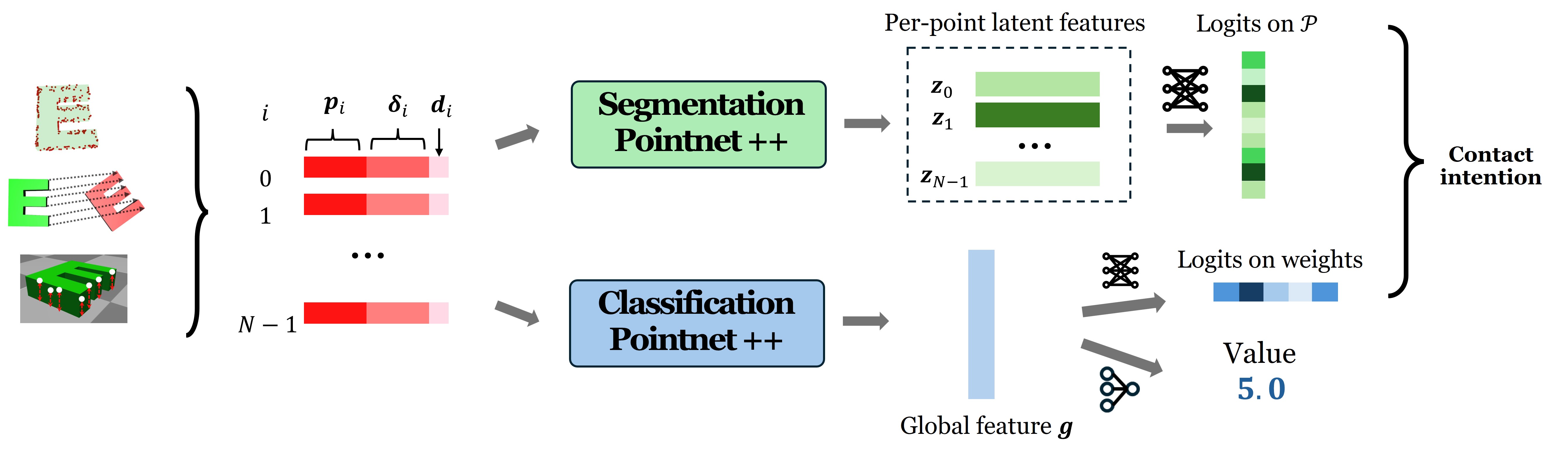
Объектно-ориентированные представления, такие как трикомпонентное представление (Tri-Component Representation), обеспечивают компактное и информативное пространство состояний для обучения с подкреплением и планирования. Вместо непосредственной работы с пикселями или необработанными сенсорными данными, эти представления фокусируются на выделении и отслеживании ключевых объектов в сцене и их релевантных свойств. Трикомпонентное представление, в частности, кодирует состояние объекта через его положение, ориентацию и тип, что значительно снижает размерность пространства состояний по сравнению с прямым использованием сенсорных данных. Это упрощение не только ускоряет процесс обучения, но и повышает обобщающую способность агента, позволяя ему эффективнее адаптироваться к новым, ранее не встречавшимся ситуациям и манипулировать объектами с большей точностью.
Комбинация обучения с подкреплением и модельно-прогнозного управления (RL-MPC) позволяет роботам эффективно обучаться на опыте и обобщать полученные знания для работы в новых, ранее не встречавшихся ситуациях. В задачах незахватной манипуляции, где требуется перемещение объектов без их непосредственного захвата, применение данной комбинации демонстрирует стабильно высокие результаты, достигающие почти 100% успешности выполнения задач. Это обусловлено способностью RL-MPC адаптироваться к динамически меняющимся условиям и оптимизировать стратегии управления, используя как данные, полученные в процессе обучения, так и предсказательную модель окружения.

Реальные Применения: Незахватная Манипуляция и Преодоление Границ
Незахватная манипуляция представляет собой перспективное применение предложенной системы, позволяющее роботам воздействовать на объекты, не прибегая к захвату. Такой подход открывает возможности для работы в сложных, загроможденных средах, где традиционные методы захвата затруднены или невозможны. Вместо удержания объекта, робот использует толкание, скольжение или другие формы воздействия для перемещения и ориентации предмета. Данная технология особенно актуальна для задач сортировки, сборки и обслуживания, где требуется манипулирование большим количеством объектов различной формы и размера. Использование незахватной манипуляции способствует повышению гибкости и адаптивности робототехнических систем, позволяя им эффективно функционировать в реальных условиях, приближенных к человеческой деятельности.
Для повышения надежности и точности манипуляций в динамичных условиях, исследования используют передовые методы визуального отслеживания, такие как TwinTrack и FoundationPose++. Эти системы позволяют роботу эффективно определять и отслеживать положение и ориентацию объектов, даже при частичной видимости или быстром движении. TwinTrack обеспечивает устойчивое отслеживание объектов, используя комбинацию различных признаков и алгоритмов фильтрации, а FoundationPose++ позволяет точно оценивать позу объектов в 3D-пространстве, что критически важно для планирования не-захватных манипуляций. Сочетание этих технологий значительно улучшает способность робота адаптироваться к изменяющейся обстановке и успешно выполнять поставленные задачи по перемещению и переориентации объектов без необходимости их захвата.
Предложенная система обучения с подкреплением и модельного предсказательного управления (RL-MPC) продемонстрировала впечатляющие результаты в задачах манипулирования объектами без захвата. Эксперименты показали 100%-ную успешность в перемещении объектов путем толкания в рамках известных геометрических конфигураций. Более того, система успешно справляется с новыми, ранее не встречавшимися конфигурациями букв с точностью 99,06%, а также выполняет переориентацию трехмерных объектов с эффективностью 98,75%. Эти результаты подчеркивают способность системы к обобщению и адаптации к новым условиям, что является важным шагом на пути к надежному и универсальному роботизированному манипулированию в реальном мире.