Автор: Денис Аветисян
В статье представлен всесторонний обзор методов конструирования запросов для современных систем генерации естественного языка, позволяющих добиться желаемого результата.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"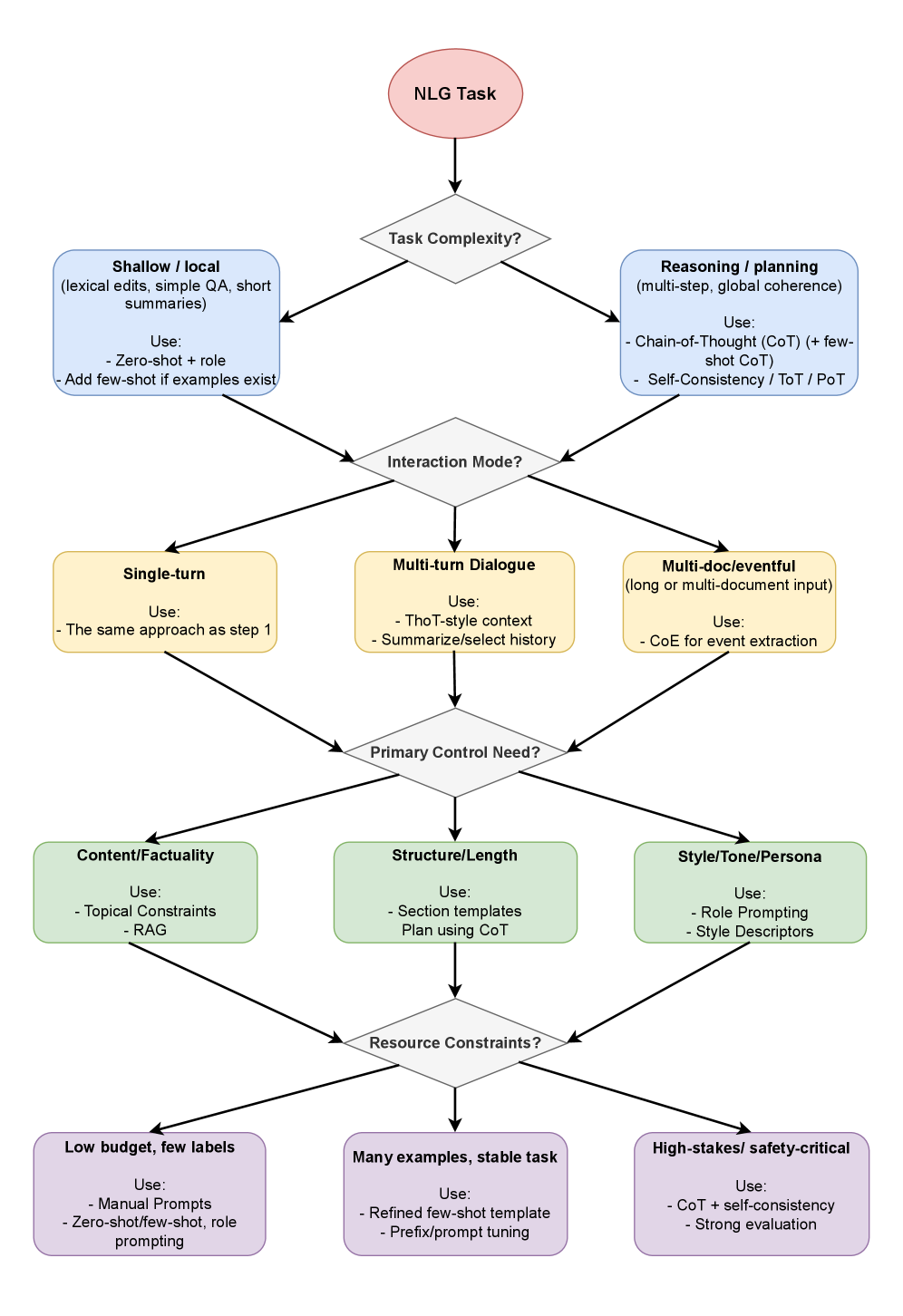
Систематизация подходов к разработке, оптимизации и оценке запросов для повышения управляемости и качества генерируемого текста.
Несмотря на впечатляющие возможности современных больших языковых моделей (LLM), их эффективное применение в задачах генерации естественного языка требует продуманного подхода к формированию инструкций. В данной работе, ‘From Instruction to Output: The Role of Prompting in Modern NLG’, предпринята попытка систематизировать методы и техники prompt engineering, играющие ключевую роль в раскрытии потенциала LLM. Предлагается таксономия парадигм prompt engineering, а также практический фреймворк для проектирования, оптимизации и оценки, направленный на повышение контролируемости и обобщающей способности генерации текста. Сможет ли предложенный подход преодолеть текущую фрагментарность в области prompt engineering и способствовать развитию более надежных и предсказуемых систем генерации естественного языка?
Истинная Сущность Языковых Моделей: Вызовы и Возможности
Современные большие языковые модели демонстрируют впечатляющую способность выполнять широкий спектр задач обработки естественного языка, включая перевод, суммирование и генерацию текста. Однако, несмотря на масштабы и сложность этих систем, они часто испытывают трудности при решении задач, требующих глубокого логического мышления и поддержания фактической точности. Несмотря на кажущуюся связность генерируемых текстов, модели могут допускать ошибки в рассуждениях, противоречить самим себе или выдавать недостоверную информацию, что ставит под вопрос их надежность в критически важных приложениях и подчеркивает необходимость дальнейших исследований в области улучшения их когнитивных способностей и проверки фактов.
Несмотря на впечатляющие размеры и сложность, большие языковые модели демонстрируют удивительную чувствительность к формулировкам запросов. Даже незначительные изменения в тексте вопроса или инструкции могут приводить к существенным колебаниям качества генерируемого ответа. Исследования показывают, что кажущаяся незначительная перефразировка способна кардинально изменить логику рассуждений модели, приводя к непредсказуемым и иногда ошибочным результатам. Эта особенность вызывает серьезные опасения относительно надежности и стабильности LLM, особенно в критически важных приложениях, где требуется высокая точность и последовательность. Возникает необходимость в разработке методов, позволяющих смягчить зависимость от конкретной формулировки запроса и обеспечить более устойчивое и предсказуемое поведение моделей.
Одной из серьезных проблем, стоящих перед разработчиками больших языковых моделей, является смягчение эффекта усиления предвзятости, когда даже незначительные формулировки запросов могут невольно воспроизводить и усиливать существующие в обществе стереотипы и предубеждения в генерируемом тексте. Исследования показывают, что модели, обученные на обширных текстовых данных, отражают исторически сложившиеся социальные неравенства, и при определенном подходе это может приводить к дискриминационным или несправедливым результатам. Важно понимать, что предвзятость может проявляться в различных формах — гендерной, расовой, религиозной и других — и требует комплексного подхода к разработке, включающего тщательный анализ обучающих данных, разработку методов детекции и смягчения предвзятости, а также постоянный мониторинг выходных данных моделей.
Инженерия Запросов: Искусство Управления Языковой Моделью
Инженерия запросов (Prompt Engineering) представляет собой ключевой интерфейс для управления поведением больших языковых моделей (LLM), позволяя контролировать стиль, содержание и структуру генерируемого текста. Вместо прямой модификации параметров модели, инженерия запросов фокусируется на разработке и оптимизации входных данных — самих запросов — для получения желаемого результата. Это достигается путем точного формулирования инструкций, предоставления контекста, указания формата вывода и использования различных техник, таких как указание тональности или ограничение длины ответа. Эффективная инженерия запросов позволяет существенно повысить релевантность, точность и согласованность генерируемого текста, не требуя дорогостоящей переподготовки модели.
Методы запросной инженерии, такие как Zero-Shot и Few-Shot обучение, обеспечивают основу для обучения в контексте (in-context learning), позволяя большим языковым моделям (LLM) выполнять задачи без необходимости обширной донастройки (fine-tuning). Zero-Shot обучение предполагает выполнение задачи на основе только описания задачи в запросе, без предоставления примеров. Few-Shot обучение, напротив, включает в себя предоставление модели небольшого количества примеров (обычно от 1 до 10) входных данных и соответствующих ожидаемых результатов непосредственно в запросе. Это позволяет модели извлекать закономерности и применять их к новым, невидимым ранее данным, значительно снижая потребность в трудоемком процессе дообучения на больших размеченных наборах данных.
Более продвинутые методы промптинга, такие как Chain-of-Thought (CoT), Thread-of-Thought (ToT) и Program-of-Thought (PoT), направлены на явное стимулирование пошагового рассуждения в больших языковых моделях (LLM). CoT предполагает включение в промпт примеров, демонстрирующих логическую цепочку рассуждений для решения задачи, что позволяет модели генерировать более точные и обоснованные ответы. ToT расширяет эту концепцию, позволяя модели динамически формировать и исследовать различные ветви рассуждений. PoT идет еще дальше, предлагая модели генерировать программный код для решения задачи, что обеспечивает более структурированный и проверяемый процесс рассуждения. Эффективность этих методов подтверждается структурированным синтезом методов промптинга для задач генерации естественного языка (NLG), демонстрируя улучшение точности и интерпретируемости результатов.
Верификация Рассуждений и Обеспечение Надежных Результатов
Метод LLM-as-a-Judge использует возможности самих больших языковых моделей (LLM) для оценки сгенерированного текста, обеспечивая масштабируемое решение для контроля качества. Вместо ручной проверки или использования отдельных моделей оценки, LLM выступает в роли арбитра, анализируя выходные данные другой LLM по заданным критериям, таким как релевантность, точность и связность. Этот подход позволяет автоматизировать процесс оценки больших объемов текста, снижая затраты и время, необходимые для обеспечения качества. Масштабируемость достигается за счет возможности параллельной обработки запросов и использования инфраструктуры, предназначенной для работы с LLM. Эффективность метода зависит от качества промптов, используемых для LLM-судьи, и от четкости определенных критериев оценки.
Метод самосогласованной генерации (Self-Consistency Prompting) повышает устойчивость больших языковых моделей (LLM) за счет многократного генерирования цепочек рассуждений для одного и того же запроса. Вместо выбора единственного ответа, система генерирует несколько вариантов решения задачи, используя различные вероятные пути рассуждений. Затем, результаты агрегируются, например, путем выбора наиболее часто встречающегося ответа или путем усреднения вероятностей. Такой подход позволяет смягчить влияние отдельных ошибок в процессе рассуждений, поскольку вероятность того, что ошибка повторится во всех сгенерированных цепочках, значительно ниже. Это повышает общую надежность и точность выходных данных LLM, особенно в задачах, требующих сложных логических выводов.
Методы, такие как Retrieval Augmented Generation (RAG), повышают фактическую точность генерируемого текста за счет соотнесения ответов с внешними источниками знаний. В отличие от традиционного подхода, основанного на эмпирическом подборе запросов, данная работа представляет собой систематизированный фреймворк, объединяющий этапы проектирования, оптимизации и оценки. Это позволяет перейти от итеративного тестирования различных формулировок запросов к более предсказуемому и контролируемому процессу создания надежных и фактических ответов, используя внешнюю базу знаний для верификации и уточнения генерируемого контента.
За пределами Инструкций: Детальный Контроль и Адаптация
Управление на уровне декодирования представляет собой механизм, позволяющий модифицировать процесс генерации текста после вычисления вероятностей. Вместо изменения самой модели, этот подход оперирует с вероятностным распределением, влияя на выбор следующего токена. Это даёт возможность целенаправленно корректировать стиль и содержание генерируемого текста, например, усиливая или ослабляя определенные темы, избегая нежелательных выражений или повышая разнообразие лексики. Такой контроль достигается за счёт применения различных стратегий, включая фильтрацию вероятностей, передистрибуцию вероятностей и использование штрафов, что позволяет адаптировать выходные данные модели без её переобучения и сохранять согласованность генерируемого текста.
Процесс тонкой настройки предоставляет возможность адаптировать внутренние представления больших языковых моделей (LLM) к конкретным задачам и ожидаемым результатам. Вместо обучения модели с нуля, тонкая настройка использует предварительно обученную модель и корректирует ее параметры на относительно небольшом, специализированном наборе данных. Это позволяет добиться существенного повышения производительности в узкой области, например, в генерации юридических документов, создании креативного контента или ответе на вопросы в определенной предметной области. В результате, модель становится более эффективной и точной в решении поставленных задач, демонстрируя улучшенное понимание контекста и способность генерировать релевантные и качественные ответы, адаптированные к специфическим требованиям пользователя.
Исследования демонстрируют, что применение альтернативных стратегий промптинга, таких как “Дерево Мыслей” и промптинг на основе ролей, существенно расширяет возможности больших языковых моделей в плане сложного рассуждения и понимания контекста. Метод “Дерево Мыслей” позволяет модели исследовать несколько возможных путей решения задачи, оценивая каждый из них перед выбором наиболее оптимального, что имитирует человеческий процесс обдумывания. Промптинг на основе ролей, в свою очередь, предполагает наделение модели определенной личностью или экспертизой, что способствует генерации более релевантных и контекстуально обоснованных ответов. Эти подходы позволяют преодолеть ограничения традиционного промптинга, когда модель реагирует исключительно на прямо сформулированные инструкции, открывая путь к более гибкому и интеллектуальному взаимодействию с искусственным интеллектом.
Исследование, представленное в данной работе, подчеркивает важность систематического подхода к проектированию и оптимизации подсказок для моделей генерации естественного языка. Это согласуется с убеждением, что математическая строгость и доказуемость являются краеугольными камнями надежных алгоритмов. Как однажды заметил Андрей Колмогоров: «Математика — это искусство не делать ошибок». В контексте разработки подсказок это означает, что каждая подсказка должна быть сформулирована таким образом, чтобы однозначно определять желаемый результат, исключая двусмысленность и неопределенность. Стремление к систематизации, предложенное в обзоре, является попыткой привнести эту математическую точность в область, которая часто полагается на эмпирические методы и неформальные практики.
Что дальше?
Представленный обзор, хотя и систематизирует текущее состояние «инженерии запросов», неизбежно обнажает глубину нерешенных проблем. Акцент на эмпирической оптимизации, без строгого математического обоснования, напоминает алхимию — множество рецептов, мало понимания. Истинная элегантность алгоритма не в его способности генерировать правдоподобный текст, а в его предсказуемости и устойчивости к возмущениям. Необходим переход от «работает на тестах» к формальному доказательству свойств сгенерированного вывода.
Ключевым направлением представляется разработка метрик, отражающих не поверхностное сходство с эталонными текстами, а внутреннюю когерентность и логическую состоятельность. Оценка, сводящаяся к статистической корреляции, упускает из виду фундаментальные аспекты семантики. Сложность алгоритма измеряется не количеством строк кода, а пределом масштабируемости и асимптотической устойчивостью, что требует принципиально новых подходов к моделированию и верификации.
В конечном итоге, задача не в создании «более умных» языковых моделей, а в разработке формальной теории управления генерацией текста. И лишь тогда, когда каждый запрос будет подкреплен математической гарантией, можно будет говорить о подлинном прогрессе в области естественной лингвистики.
Оригинал статьи: https://arxiv.org/pdf/2602.11179.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Неважно, на что вы фотографируете!
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Как самому почистить матрицу. Продолжение.
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- Что такое глубина резкости в фотографии?
- MSI Katana 17 HX B14WGK ОБЗОР
- Российский рынок: Рубль, ДВМП и рекордный рост рублевых вкладов – что ждет инвесторов? (28.03.2026 11:32)
- Они на наносекунды отстают от нас — генеральный директор NVIDIA бьет тревогу по поводу роста искусственного интеллекта в Китае и ставит под сомнение стратегию США в отношении чипов.
- Обзор объектива Nikkor AF-S 24-70mm f/2.8G ED
2026-02-15 20:26