Автор: Денис Аветисян
Исследователи разработали систему, имитирующую человеческое восприятие видео, для повышения точности поиска видеороликов по текстовым запросам.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"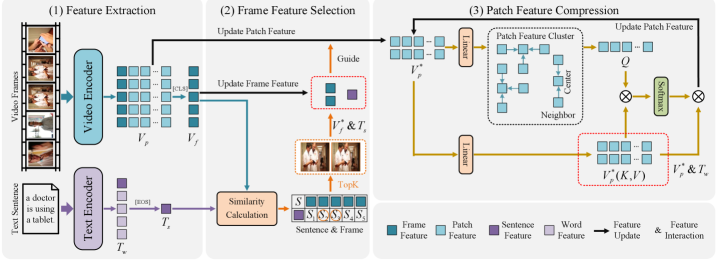
Предлагается новый фреймворк (HVD) для обучения представлений видео, основанный на отборе ключевых кадров и сжатии признаков, для улучшения межмодального выравнивания и повышения эффективности поиска по тексту и видео.
Несмотря на значительный прогресс в области извлечения информации из видео, современные методы часто сталкиваются с трудностями в выделении ключевых визуальных элементов на фоне шума. В данной работе, озаглавленной ‘HVD: Human Vision-Driven Video Representation Learning for Text-Video Retrieval’, предлагается новый подход, вдохновленный когнитивными способностями человека. Предложенная модель HVD, посредством отбора ключевых кадров и компрессии патчей, обеспечивает более точное выравнивание модальностей и улучшает качество представления видео для задач поиска по тексту. Сможет ли данный подход, имитирующий человеческое зрение, стать основой для создания более эффективных систем мультимедийного поиска?
Семантический Разрыв: Проблема Сопоставления Текста и Видео
Эффективный поиск видео по текстовому запросу существенно затруднён из-за семантического разрыва между этими двумя модальностями. Текст и видео представляют информацию принципиально разными способами: текст оперирует символами и абстракциями, в то время как видео — визуальными образами и временной последовательностью событий. Это несоответствие означает, что компьютерные алгоритмы сталкиваются с трудностями при установлении чёткой связи между словами в запросе и конкретными моментами в видеоролике. Несмотря на прогресс в области искусственного интеллекта, понимание контекста и извлечение смысла из видео остается сложной задачей, что препятствует точному сопоставлению текстового запроса с релевантными фрагментами видеоконтента. Преодоление этого семантического барьера является ключевым шагом к созданию эффективных систем поиска видео, способных удовлетворить потребности пользователей.
Существующие методы поиска по видео, ориентированные на текстовые запросы, зачастую сталкиваются с трудностями в улавливании тонких взаимосвязей между текстом и визуальным содержанием. Большинство алгоритмов полагаются на прямое сопоставление ключевых слов или общих признаков, игнорируя контекстуальные нюансы и скрытые смыслы, которые могут быть выражены в видеоряде. Например, запрос «грустный клоун» может привести к видео с изображением клоуна, но не передать эмоциональную составляющую грусти, если визуальный ряд не соответствует этому состоянию. Такое несоответствие ограничивает точность поиска и может приводить к предоставлению пользователю нерелевантных результатов, даже если формально запрос и видео содержат общие термины. Учет этих тонкостей требует более сложных моделей, способных к семантическому анализу как текста, так и видео, и к пониманию взаимосвязи между ними.
Несоответствие между текстовыми запросами и визуальным содержанием видео значительно затрудняет поиск релевантных фрагментов. Имеющиеся методы часто не способны уловить тонкие взаимосвязи между тем, что пользователь ищет в текстовой форме, и тем, что на самом деле происходит в видеоряде. Это приводит к тому, что система может предложить неточные или неполные результаты, не соответствующие намерениям пользователя. В результате, даже при наличии обширной видеобазы, поиск конкретной информации может оказаться сложным и неэффективным, снижая ценность самого видеоконтента и усложняя взаимодействие с ним.

HVD: Человеческий Взгляд на Поиск Видео
Модель HVD представляет собой новый подход к задаче поиска соответствий между текстом и видео, основанный на принципах человеческого зрительного восприятия. В отличие от традиционных методов, HVD использует многоуровневое представление видеоконтента, что позволяет более точно сопоставлять семантическое содержание текста с визуальными данными. Архитектура модели разработана с учетом особенностей обработки визуальной информации человеком, что позволяет ей эффективно извлекать и сопоставлять ключевые признаки из видео и текстовых запросов, повышая точность поиска релевантных видеороликов по текстовому описанию.
Модель HVD использует многоуровневые признаки, извлеченные из видео и текстовых запросов, для повышения эффективности поиска. Видео анализируются с использованием как полных кадров, так и небольших фрагментов (патчей), что позволяет захватить как глобальный контекст, так и детализированную информацию. Параллельно, текстовые запросы преобразуются в векторные представления предложений, отражающие семантическое значение. Комбинирование признаков кадров, патчей и предложений позволяет модели комплексно оценивать соответствие между визуальным и текстовым контентом, что улучшает точность поиска релевантных видео по текстовому запросу.
Модель HVD использует многогранулярные представления, объединяя признаки, извлеченные из видео (кадры и патчи), с признаками предложений из текстовых запросов. Такой подход позволяет модели учитывать информацию на различных уровнях детализации — от общих характеристик всего кадра до локальных особенностей отдельных фрагментов видео и семантики текстового описания. Комбинирование этих представлений обеспечивает более полное и контекстуально-обогащенное понимание как визуального, так и текстового контента, что способствует повышению точности поиска релевантных видео по текстовым запросам и наоборот.
Выравнивание Признаков: Повышение Точности Сопоставления
В рамках предлагаемого подхода применяется метод улучшения признаков, включающий в себя последовательное, от общего к частному, выравнивание (coarse-to-fine alignment) текстовых и видео-признаков. Данная техника предполагает начальное грубое сопоставление признаков для установления приблизительной корреляции, за которым следует более точное выравнивание на последующих этапах. Это позволяет уточнить соответствие между текстовым запросом и визуальным контентом, учитывая разницу в представлениях данных и повышая точность сопоставления признаков, что способствует более эффективному поиску релевантных видео по текстовому запросу.
Для расширения текстовых представлений и улавливания более широких семантических связей, мы исследуем методы моделирования на основе семантической близости. Данный подход заключается в выявлении слов и фраз, близких по значению к исходному тексту запроса, и включении их векторных представлений в расширенную модель текста. Это позволяет учитывать синонимы, связанные понятия и контекстуальные нюансы, которые могли быть упущены при прямой сопоставлении признаков. В результате, повышается способность системы находить релевантные видео, даже если они не содержат точные ключевые слова из запроса, но связаны с ним по смыслу. Используемые метрики семантической близости включают в себя косинусное сходство и другие методы оценки векторных представлений слов, полученных с помощью предварительно обученных языковых моделей.
Применение стратегий выравнивания признаков значительно повышает точность сопоставления релевантных видео с текстовыми запросами. Это достигается за счет улучшения соответствия между векторными представлениями текста и видео, что позволяет более эффективно находить видео, семантически связанные с запросом. Улучшение точности сопоставления напрямую влияет на повышение показателей производительности систем поиска видео, измеряемых такими метриками, как precision и recall. В результате, пользователи получают более релевантные результаты поиска, а системы демонстрируют более высокую эффективность в задачах извлечения видеоинформации.
Надёжность и Широкая Поддержка Наборов Данных: Подтверждение Эффективности
Модель HVD прошла тщательное тестирование на различных наборах данных, включающих MSRVTT, DiDeMo, ActivityNet и Charades. Этот широкий спектр данных, охватывающий разнообразные видео-сцены и действия, позволил всесторонне оценить надежность и обобщающую способность разработанного подхода. Использование столь неоднородных наборов данных гарантирует, что модель способна эффективно работать в различных реальных условиях и демонстрирует устойчивость к изменениям в освещении, ракурсах и типах действий. Проверка на таких эталонных наборах данных обеспечивает объективное сравнение с существующими методами и подтверждает потенциал HVD для широкого спектра практических применений в области анализа видео.
Исследования показали значительное повышение эффективности поиска видео благодаря новой модели. На тестовом наборе данных MSRVTT, модель достигла показателя R@1 в 48.8%, что свидетельствует о ее способности точно находить релевантные видеофрагменты. Этот результат превосходит показатели базовой модели HBI на 0.2 пункта и подтверждает перспективность подхода, основанного на моделировании человеческого зрения, для практического применения в системах поиска и анализа видеоконтента. Достигнутое улучшение демонстрирует способность модели эффективно обрабатывать сложные видеоданные и предоставлять пользователям наиболее подходящие результаты.
Достижение прироста в 0.2 пункта по показателю R@1 на наборе данных MSRVTT по сравнению с базовой моделью HBI свидетельствует об эффективности предложенного подхода, основанного на моделировании человеческого зрения. Этот прирост, хотя и кажется небольшим, подтверждает, что имитация принципов визуального восприятия человеком позволяет более точно сопоставлять видео и текстовые описания. Такая точность имеет значительный потенциал для практического применения в различных областях, включая поиск видеоконтента, автоматическое создание субтитров и разработку интеллектуальных систем видеонаблюдения, где надёжное понимание видеоданных играет ключевую роль.
Представленная работа демонстрирует стремление к элегантности в решении задачи извлечения информации из видеоданных. Авторы, подобно математикам, ищут наиболее лаконичное и эффективное представление видео, фокусируясь на ключевых кадрах и сжатии признаков. Этот подход, направленный на улучшение кросс-модального выравнивания, напоминает принцип поиска минимального достаточного набора данных для достижения максимальной точности. Как однажды заметил Эндрю Ын: «Мы должны стремиться к созданию систем, которые не просто работают, но и понятны и предсказуемы». Применение этого принципа в контексте извлечения видеоинформации позволяет создать не просто работающую, но и доказуемо эффективную систему.
Что дальше?
Представленный подход, имитирующий избирательность человеческого зрения, несомненно, представляет собой шаг к более элегантным решениям в задаче извлечения информации из мультимодальных данных. Однако, стоит признать, что подражание биологическим системам — это всегда лишь приближение, а не абсолютная истина. Ключевым ограничением остается зависимость от эвристических правил выбора ключевых кадров. Более строгие математические модели, основанные на теории информации и принципах оптимальной кодировки, представляются перспективным направлением.
Особое внимание следует уделить вопросу о масштабируемости. Предлагаемая компрессия признаков, хоть и эффективна, всё же требует вычислительных ресурсов. Необходимо исследовать возможность применения разреженных представлений и квантования, чтобы минимизировать избыточность и добиться большей эффективности без потери точности. Любой алгоритм, претендующий на практическое применение, обязан демонстрировать линейную сложность при росте объёма данных.
В конечном счёте, настоящая проверка предложенного подхода — это его способность к обобщению. Решение, корректное лишь для ограниченного набора данных, — это иллюзия прогресса. Необходимо подвергнуть систему строгим тестам на различных наборах данных, чтобы убедиться в её устойчивости и надёжности. И только тогда можно будет говорить о реальном прорыве в области извлечения информации из видео.
Оригинал статьи: https://arxiv.org/pdf/2601.16155.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Новые смартфоны. Что купить в марте 2026.
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Лучшие смартфоны. Что купить в марте 2026.
- Нефть и бриллианты лидируют: обзор воскресных торгов на «СПБ Бирже» (08.03.2026 16:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Неважно, на что вы фотографируете!
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Oppo Reno15 ОБЗОР: отличная камера, много памяти, скоростная зарядка
- Деформация сеток: новый подход на основе нейронных операторов
2026-01-24 21:29