Автор: Денис Аветисян
Новая модель VAGNet анализирует взаимодействие человека и объектов на видео, чтобы точно определять возможные способы использования предметов в 3D-пространстве.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"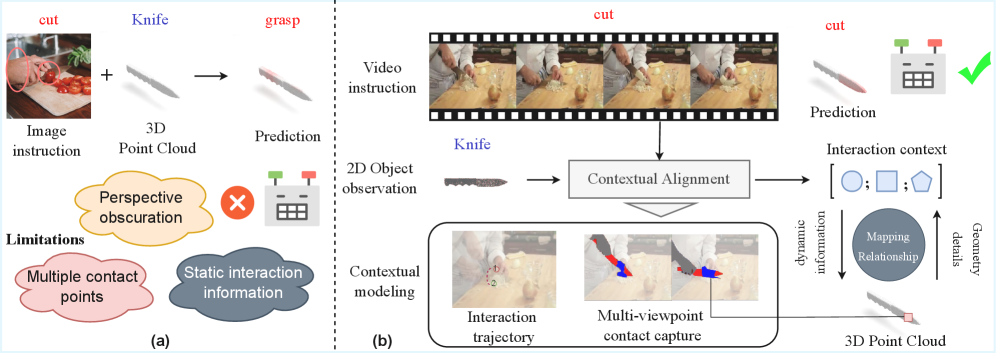
Исследование предлагает подход к 3D-обоснованию аффордансов, использующий динамические видеоролики с взаимодействием человека и объектов для повышения точности определения возможностей использования.
Несмотря на значительные успехи в области трехмерного понимания объектов, определение областей, поддерживающих взаимодействие человека с объектом, остаётся сложной задачей. В данной работе, представленной под названием ‘VAGNet: Grounding 3D Affordance from Human-Object Interactions in Videos’, предлагается новый подход к определению трехмерных аффордансов, основанный на анализе динамических видео последовательностей, демонстрирующих взаимодействие человека и объекта. Предложенная архитектура VAGNet позволяет более точно выявлять функциональные области объектов, используя информацию о действиях, в отличие от методов, полагающихся только на статические признаки. Не откроет ли это путь к созданию более интеллектуальных и адаптивных робототехнических систем, способных к более естественному взаимодействию с окружающим миром?
Понимание Окружающего Мира: Проблема Аффордансов
Роботизированные системы испытывают трудности с обобщением навыков манипулирования объектами из-за ограниченного понимания аффордансов — возможностей для действия, которые объект предоставляет. Вместо того, чтобы воспринимать предмет как набор свойств, позволяющих выполнить определенные действия (например, возможность захвата, вращения, скольжения), многие роботы оперируют лишь визуальными данными или заранее запрограммированными инструкциями. Это приводит к тому, что робот, успешно манипулирующий одним и тем же предметом в знакомой обстановке, может потерпеть неудачу при незначительном изменении условий или при встрече с новым, но похожим объектом. Неспособность к обобщению аффордансов существенно ограничивает гибкость и адаптивность роботов, препятствуя их широкому применению в реальных, динамично меняющихся средах.
Традиционные подходы к обучению роботов манипулированию объектами часто оказываются неэффективными из-за зависимости от заранее определенных, “ручной” настройки признаков. Вместо того чтобы позволить роботу самостоятельно извлекать информацию из визуальных данных и трехмерной модели окружения, системы полагаются на жестко заданные параметры, что ограничивает их способность адаптироваться к новым объектам или ситуациям. Неспособность эффективно объединить восприятие изображения с пространственным рассуждением приводит к тому, что роботы испытывают трудности в понимании возможностей взаимодействия с объектами — их “аффордансов”. В результате, даже незначительные изменения в освещении, фоне или форме объекта могут существенно снизить эффективность манипуляций, подчеркивая необходимость более гибких и интеллектуальных систем, способных к самообучению и адаптации.
Успешное сопоставление возможностей взаимодействия с трехмерным пространством является ключевым фактором для создания надежных и адаптируемых робототехнических систем. Обоснование аффордансов — потенциальных действий, которые объект позволяет выполнить — в трехмерном контексте позволяет роботам не просто «видеть» объекты, но и понимать, как с ними взаимодействовать. Это означает, что робот способен предвидеть последствия своих действий, планировать сложные манипуляции и корректировать свои стратегии в ответ на меняющиеся условия. В отличие от систем, полагающихся на заранее запрограммированные правила или двухмерные изображения, трехмерное понимание аффордансов позволяет роботам обобщать полученные знания и эффективно применять их к новым, ранее невиданным объектам и ситуациям, обеспечивая более гибкое и естественное взаимодействие с окружающим миром.

Видео-Руководство к 3D-Аффордансам: Многомодальный Подход
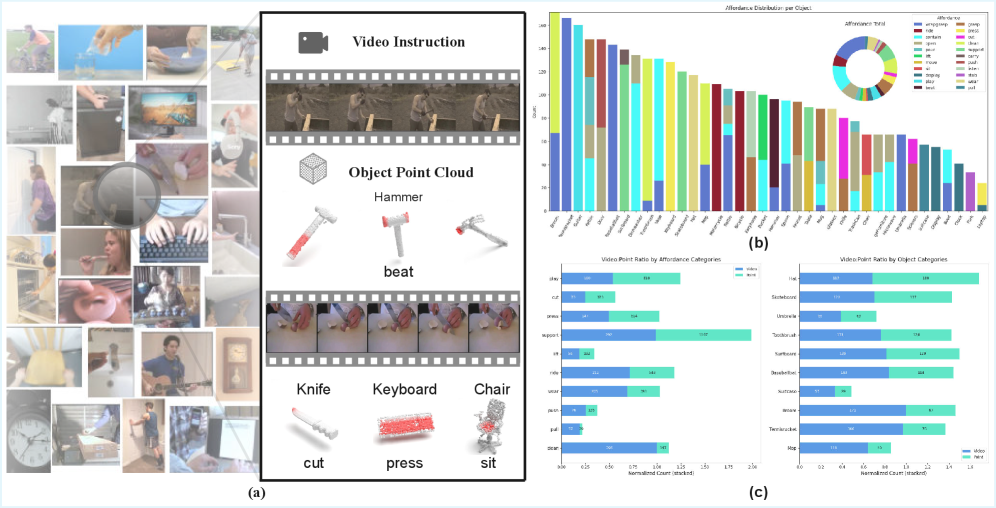
Основа предложенного подхода к определению аффордансов 3D-объектов заключается в использовании видеозаписей взаимодействия человека и объекта (Human-Object Interaction, HOI) в качестве ключевого источника информации. Данные видеоматериалы предоставляют контекст, необходимый для понимания того, как люди взаимодействуют с объектами в реальных условиях. Использование HOI-видео позволяет алгоритмам обучения извлекать информацию о функциональных возможностях объекта, таких как поверхности, подходящие для захвата, области для приложения силы или точки опоры. Это особенно актуально в ситуациях, когда доступные 3D-данные ограничены или неполны, поскольку видео предоставляет дополнительные визуальные подсказки, необходимые для точного определения аффордансов.
Объединение визуальных сигналов из видео с трехмерными представлениями объектов позволяет модели предсказывать, какие области объекта поддерживают конкретные действия. Этот процесс включает в себя анализ видеоматериалов, демонстрирующих взаимодействие человека с объектом, и сопоставление визуальной информации с соответствующими частями 3D-модели. В результате, система способна идентифицировать области, пригодные для захвата, нажатия, перемещения или других взаимодействий, основываясь на наблюдаемых паттернах в видеоданных и геометрии объекта. Обучение происходит путем сопоставления визуальных признаков с соответствующими регионами 3D-объекта, которые участвуют в действиях, что позволяет модели обобщать и предсказывать поддерживаемые действия для новых объектов и сценариев.
Проблема разреженности 3D-данных, часто возникающая при моделировании объектов, эффективно решается за счет использования видеоинформации. Видеоматериалы, демонстрирующие взаимодействие человека с объектами, предоставляют ценный контекст, позволяющий восполнить недостающие данные о форме и структуре объектов. Анализируя визуальные подсказки из видео, система может определить, какие области объекта поддерживают определенные действия, даже если 3D-модель объекта не содержит полной геометрической информации. Это позволяет создавать более точные и надежные модели аффордансов, определяющие возможности взаимодействия с объектами.
VAGNet: Сопоставление Видео и 3D-Миров
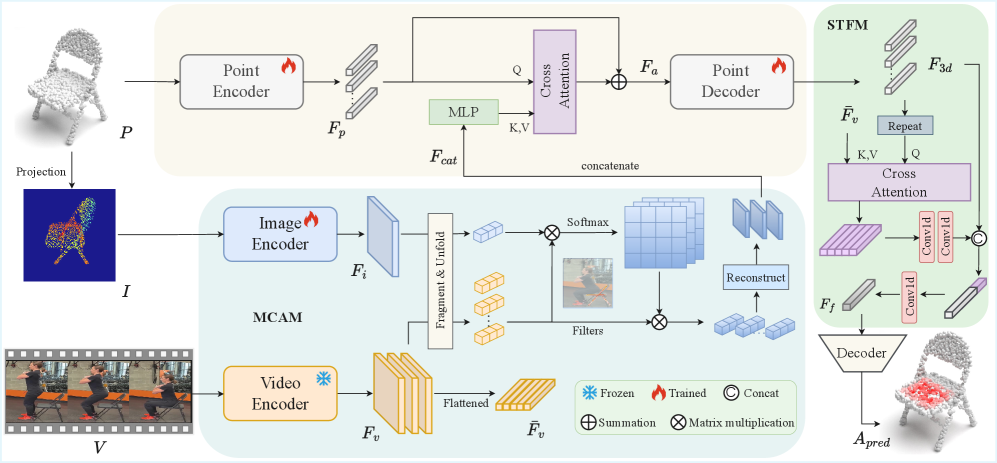
VAGNet — это нейронная сеть, разработанная специально для привязки видеоинформации к 3D-моделям объектов с целью определения возможных действий с ними (affordance grounding). Архитектура сети включает в себя модули для извлечения и выравнивания мультимодальных признаков, что позволяет эффективно объединять информацию из 2D-видео и 3D-представлений объектов. Основная задача VAGNet — установить соответствие между визуальными данными из видео и геометрией 3D-объектов, что необходимо для понимания, какие действия можно совершить с объектом, основываясь на его визуальном восприятии и 3D-структуре.
Модуль мультимодального контекстного выравнивания (MCAM) осуществляет эффективное сопоставление 2D видеокадров с 3D представлениями объектов посредством механизма кросс-внимания. Этот подход позволяет сети устанавливать соответствия между визуальными признаками, извлеченными из видео, и геометрическими характеристиками 3D моделей. Кросс-внимание позволяет MCAM динамически взвешивать различные части видеокадра при анализе конкретной 3D точки, и наоборот, фокусируясь на релевантной информации для определения доступных действий (affordances). В результате достигается более точное выравнивание и понимание взаимосвязи между 2D визуальными данными и 3D пространством.
Модуль пространственно-временного слияния (STFM) предназначен для интеграции динамических признаков видео с трехмерными представлениями объектов, что обеспечивает комплексное понимание аффордансов. STFM обрабатывает временные последовательности признаков, извлеченных из видео, и объединяет их с признаками, полученными из трехмерных моделей объектов посредством PointNet++. Этот процесс позволяет учитывать как статическую геометрию объектов, так и динамические изменения в видео, что критически важно для точного определения возможных взаимодействий и действий, связанных с объектами в сцене. В результате STFM формирует объединенное представление, которое учитывает пространственное расположение объектов и временную динамику видео, предоставляя полную информацию для анализа аффордансов.
Для обеспечения надежного восприятия VAGNet использует PointNet++ для извлечения признаков из 3D-моделей и ResNet или TimeSformer для кодирования видеоданных. PointNet++ эффективно обрабатывает неструктурированные облака точек, представляющие 3D-объекты, выделяя ключевые геометрические характеристики. ResNet и TimeSformer, в свою очередь, обеспечивают извлечение временных и пространственных признаков из видеопотока, позволяя сети учитывать динамические изменения в сцене. Комбинация этих архитектур позволяет VAGNet создавать надежные представления как 3D-объектов, так и видеоданных, необходимые для последующего анализа и определения доступных действий (affordances).
Результаты и Более Широкие Последствия
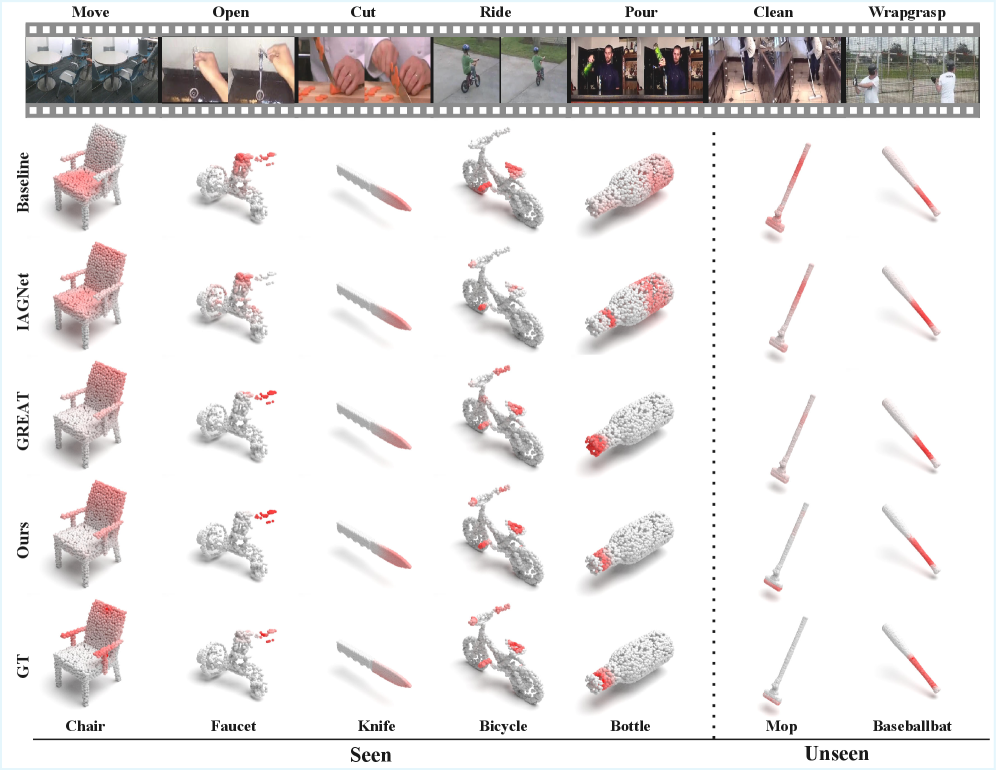
Разработанная нейронная сеть VAGNet продемонстрировала передовые результаты на наборе данных Point-Video Affordance Dataset (PVAD), что свидетельствует о ее способности точно определять возможности взаимодействия объектов в трехмерном пространстве. Основываясь на анализе видеопоследовательностей и облаков точек, VAGNet успешно выявляет, какие действия возможны с конкретными объектами, например, можно ли поднять кружку или открыть дверь. Эта высокая точность в определении «аффордансов» — потенциальных возможностей взаимодействия — является ключевым шагом к созданию более интеллектуальных и адаптивных робототехнических систем, способных эффективно функционировать в реальных условиях и взаимодействовать с окружающей средой аналогично человеку. Подобная способность к пониманию окружающего мира открывает новые перспективы для применения в сферах роботизированной манипуляции, взаимодействия человека и робота, а также создания иммерсивных виртуальных сред.
Успех сети VAGNet во многом обусловлен применением эффективных функций потерь, таких как Focal Loss и Dice Loss, которые позволяют успешно решать проблему дисбаланса данных. В задачах, связанных с определением аффордансов, часто возникает ситуация, когда одни классы объектов представлены значительно чаще, чем другие. Focal Loss концентрируется на сложных для классификации примерах, уменьшая влияние легко распознаваемых объектов и повышая точность определения редких аффордансов. Dice Loss, в свою очередь, оптимизирует перекрытие между предсказанными и фактическими областями, что особенно важно для точного определения границ объектов и их потенциальных взаимодействий. Комбинированное использование этих функций потерь позволяет VAGNet достигать высокой производительности даже при работе с несбалансированными наборами данных, что является ключевым фактором для надежного функционирования в реальных условиях.
Предложенная архитектура VAGNet демонстрирует высокую гибкость, успешно интегрируя и расширяя возможности существующих методов, таких как OpenAD, IAGNet, XMF и PointTalk. Вместо разработки совершенно новой системы, исследователи использовали эти устоявшиеся подходы в качестве строительных блоков, адаптировав их для повышения точности определения аффордансов. Такой подход не только упрощает процесс разработки, но и позволяет использовать накопленные знания и опыт, обеспечивая совместимость и широкую применимость разработанного фреймворка в различных областях, включая робототехнику и виртуальную реальность. Успешная интеграция этих методов подчеркивает потенциал VAGNet в качестве универсальной платформы для дальнейших исследований и разработок в области понимания действий и взаимодействия с окружающим миром.
Результаты экспериментов демонстрируют значительное превосходство VAGNet над наиболее эффективной базовой моделью GREAT. В условиях «Seen» (изученных ранее объектов) наблюдается увеличение показателя aIoU (Intersection over Union) на 2.73%, что свидетельствует о более точной локализации и классификации доступных действий. При оценке на «Unseen» (ранее не встречавшихся объектах) прирост aIoU составляет 1.67%, подтверждая способность сети обобщать знания и адаптироваться к новым ситуациям. Кроме того, VAGNet превосходит GREAT по показателю AUC (Area Under the Curve) на 1.48% и SIM (Similarity) на 0.02% в условиях «Seen», что указывает на улучшенную способность к ранжированию и сопоставлению предсказанных действий с реальными.
Достижения в области понимания аффордансов, продемонстрированные VAGNet, открывают значительные перспективы для развития робототехники, взаимодействия человека и робота, а также технологий виртуальной реальности. Способность сети точно определять потенциальные действия, которые объект позволяет выполнить, критически важна для создания роботов, способных эффективно манипулировать окружающим миром и безопасно взаимодействовать с людьми. В контексте взаимодействия человека и робота, точное понимание аффордансов позволяет создавать более интуитивные и естественные интерфейсы, где робот предсказывает потребности пользователя и реагирует соответствующим образом. В виртуальной реальности, реалистичное моделирование аффордансов повышает уровень погружения, позволяя пользователям взаимодействовать с виртуальными объектами так же, как и с реальными, что значительно улучшает пользовательский опыт и открывает новые возможности для обучения и развлечений.
Исследование, представленное в статье о VAGNet, пытается выжать максимум из видео, чтобы понять, как люди взаимодействуют с объектами. Идея, конечно, не нова — всегда же пытались понять контекст. Но, как обычно, возникает вопрос — а не проще ли было просто взять bash-скрипт и заставить его работать? Сейчас это назовут AI и получат инвестиции. Как метко заметил Ян Лекун: «Машинное обучение — это то, что компьютеры делают хорошо: они хорошо подстраивают параметры». В данном случае, видимо, параметры подстраивают под очередную иллюзию понимания. VAGNet, стремясь к 3D-основанному пониманию аффордансов, неминуемо столкнется с тем, что реальный мир гораздо хаотичнее любой модели. И, как всегда, документация соврет.
Что Дальше?
Представленный подход к определению 3D-аффордансов, несомненно, добавляет ещё один слой абстракции между машиной и реальностью. Вместо того, чтобы напрямую понимать физические свойства объектов, система теперь полагается на интерпретацию видео, где динамика взаимодействия человека и предмета становится решающим фактором. Однако, стоит помнить: каждый новый слой абстракции — это потенциальная точка отказа. Как только видеопоток прервется, или освещение изменится, или человек начнет действовать непредсказуемо, элегантная теория рискует столкнуться с суровой реальностью.
Проблема, конечно, не в самой идее использования видео, а в её реализации. Настоящим вызовом остаётся создание системы, устойчивой к шуму, вариативности и неполноте данных. Не стоит забывать, что документация к этим сложным моделям — это миф, созданный менеджерами, и каждый разработчик в конечном итоге полагается на эмпирический опыт и бесконечные часы отладки. CI/CD — это, по сути, храм, в котором мы молимся, чтобы ничего не сломалось.
В будущем, вероятно, потребуется сместить фокус с простого распознавания аффордансов на понимание намерений человека. Ведь объект может быть использован для множества целей, и истинное понимание заключается не в том, что можно сделать с объектом, а в том, зачем человек хочет это сделать. И тогда, возможно, мы столкнёмся с ещё более сложными проблемами — с необходимостью моделирования когнитивных процессов и предсказания поведения.
Оригинал статьи: https://arxiv.org/pdf/2602.20608.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Неважно, на что вы фотографируете!
- Санкционный удар по России: Минфин США расширяет список ограничений – что ждет экономику? (25.02.2026 05:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Личные банкротства и онлайн-табак: что ждет потребительский сектор в 2026 году (22.02.2026 10:33)
- Как установить Virtualbox на Windows 11 для бесплатных виртуальных машин
- Новые смартфоны. Что купить в феврале 2026.
- Cubot X100 ОБЗОР: отличная камера, удобный сенсор отпечатков, плавный интерфейс
- Huawei Mate 80 Pro ОБЗОР: плавный интерфейс, большой аккумулятор, огромный накопитель
- Практический обзор OnePlus OxygenOS 15
- Прогноз курса доллара к рублю на 2026 год
2026-02-25 07:44