
Технологии искусственного интеллекта никуда не денутся, и они выходят за рамки простого использования веб-инструментов, таких как ChatGPT и Copilot. Если вы разработчик, энтузиаст или просто стремитесь получить новые знания и понять, как работают эти технологии, локальные решения с искусственным интеллектом стоит рассмотреть вместо их удаленных аналогов.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Использовать Ollama для экспериментов с большими языковыми моделями на вашем персональном компьютере просто и широко распространено. Однако, в отличие от использования ChatGPT, для этого необходима надежная локальная система с мощным аппаратным обеспечением, поскольку в настоящее время поддерживаются только выделенные графические процессоры. Если вы используете LM Studio с интегрированными графическими процессорами, вам все равно потребуется достойная машина для оптимальной производительности.
Возможно, вы думаете, что для приобретения высокопроизводительной видеокарты, такой как RTX 5090, необходимы значительные вложения. Однако это не обязательно. Хотя покупка топовой модели является вариантом, вы также можете рассмотреть более старые или доступные модели, которые все еще обеспечивают достойную производительность. Если ваш бюджет позволяет приобрести NVIDIA H100, смело покупайте, но есть и менее дорогие альтернативы, которые стоит рассмотреть.
Видеопамять является ключевым фактором для Ollama.
Как любитель технологий, скажу, что при покупке графического процессора (GPU) для искусственного интеллекта (ИИ) приоритеты отличаются от тех, что важны для игр. При сборке игрового компьютера вы обычно стремитесь к новейшему поколению и самой мощной видеокарте, которую позволяет ваш бюджет, стремясь к лучшей графике и максимальной частоте кадров. Однако, когда речь идет об ИИ, стоит учитывать такие факторы, как поддержка двойной точности, тензорные ядра, пропускная способность памяти и другие функции, оптимизированные для задач машинного обучения, а не для графической производительности.
В плане приобретения искусственного интеллекта количество играет определенную роль, но для домашних пользователей это не так важно. Например, новые видеокарты серии 50 могут похвастаться большим количеством ядер CUDA, более высокой скоростью обработки и превосходной пропускной способностью памяти. Однако, когда дело доходит до абсолютного лидерства, память занимает первое место.
Если ваш бюджет не позволяет приобрести самые современные графические карты с искусственным интеллектом, сосредоточьтесь на приобретении максимально возможного объема видеопамяти (VRAM). Больший объем VRAM поможет оптимизировать производительность вашей системы при работе со сложными графическими задачами.
Когда вашему процессору необходимо выполнять дополнительные задачи, как это происходит в Ollama, вы столкнетесь со значительным снижением производительности.
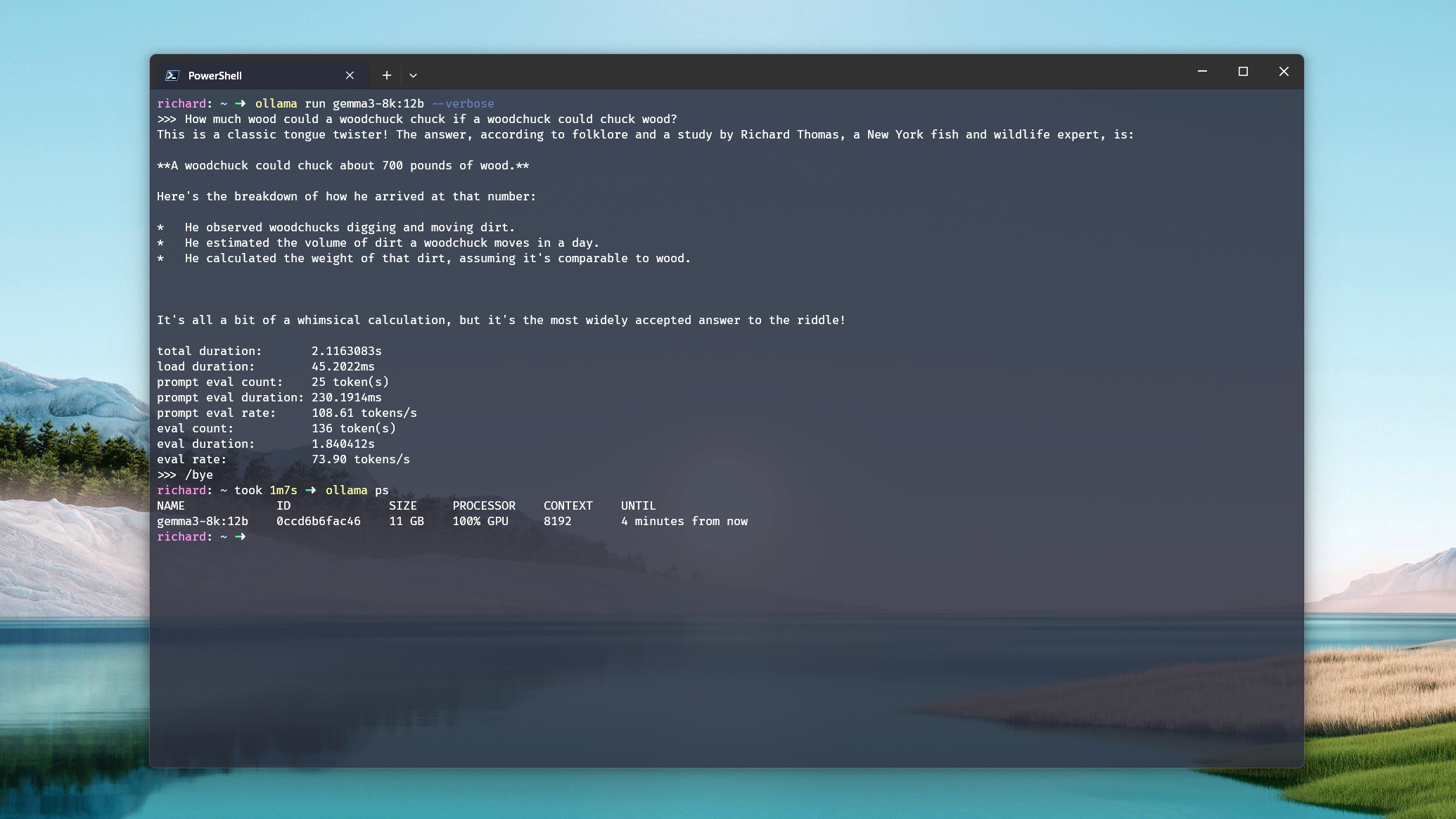
Чтобы максимально раскрыть потенциал вашей видеокарты при использовании локальных больших языковых моделей (LLM), убедитесь, что модель полностью работает в видеопамяти (VRAM). Поскольку VRAM быстрее обычной системной памяти, хранение всего в VRAM минимизирует потери производительности. Однако, когда данные начинают переполнять системную память, вы почувствуете снижение производительности, поскольку процессор вмешивается, чтобы помочь, что может значительно замедлить процесс, например, в случае с этим, когда это происходит.
На моём персональном компьютере, модель Deepseek-r1:14b, оснащённая видеокартой NVIDIA RTX 5080 с 16 ГБ видеопамяти, мощным процессором Intel Core i7-14700k и 32 ГБ оперативной памяти DDR5, работает. Когда я даю ей простую команду, например, ‘расскажи мне историю’, модель генерирует примерно 70 токенов в секунду. Однако, если я расширяю контекстное окно сверх 16 тысяч, модель начинает использовать как системную оперативную память, так и процессор, поскольку это превышает объём памяти графического процессора.
В ходе моего анализа я заметил значительное снижение скорости генерации, примерно до 19 токенов в секунду, несмотря на то, что нагрузка на процессор и графический процессор распределена в соотношении 21%/79%. Интересно, что даже когда графический процессор выполняет большую часть задач, обращение к процессору и оперативной памяти приводит к резкому падению производительности.
В том же духе, ноутбуки также не являются исключением, хотя наше обсуждение здесь в основном вращается вокруг настольных видеокарт. Когда искусственный интеллект имеет значение, лучше выбирать ноутбук, оснащенный графическим процессором с максимальным доступным объемом видеопамяти (VRAM).
Итак, сколько видеопамяти вам нужно?

В максимально возможной степени, насколько позволяют ваши ресурсы. Однако точный ответ зависит от конкретных моделей, которые вы планируете использовать. Хотя я могу помочь вам определить ваши потребности, я не смогу предоставить вам точное решение.
На странице моделей на веб-сайте Ollama, каждый модуль отображается с указанием его размера. Этот минимальный размер указывает на объем видеопамяти, необходимый для загрузки всей памяти на вашу видеокарту. Однако, для эффективной обработки вам потребуется больше, чем это. Чем больше окно контекста, которое передает данные в языковую модель машинного обучения (LLM), тем больше памяти вы будете потреблять, также известной как KV-кэш. Проще говоря, большее окно контекста означает, что больше данных будут храниться в памяти для эффективной обработки моделью.
В идеальном сценарии я бы рекомендовал использовать видеокарту с 24 ГБ видеопамяти, если вы планируете использовать эту модель свободно и плавно.
Распространенное предложение — умножать фактический размер файла модели на 1.2, чтобы получить приблизительную оценку ее конечного размера. Позвольте мне проиллюстрировать это на примере!
14 гигабайт – это размер модели gpt-oss:20b от OpenAI. Если умножить это на 1.2, получится приблизительно 16.8 ГБ. Судя по моему опыту использования, эта оценка кажется довольно точной. Без использования видеокарты RTX 5080 объемом 16 ГБ с окном контекста 8k или меньше, я не могу поддерживать загруженную на видеокарту всю модель.
В идеальном сценарии, при работе с процессорами и оперативной памятью объемом 16 тысяч и более, производительность резко падает. Поэтому, для оптимального использования, я рекомендую видеокарту с 24 ГБ видеопамяти, чтобы эффективно обрабатывать эту модель.
Это утверждение можно перефразировать следующим образом:
Ранее высказанная мысль повторяется здесь: чем больше задач вы возлагаете на центральный процессор и оперативную память, тем хуже становится производительность вашей системы. Чтобы поддерживать оптимальную производительность, стремитесь к тому, чтобы графический процессор был активен как можно дольше, независимо от того, связано ли это с более крупными моделями, большими окнами контекста или их сочетанием.
Более старые и доступные видеокарты все еще могут быть отличным выбором для искусственного интеллекта.

После достаточного времени, проведенного за изучением информации в сети, становится очевидной повторяющаяся тенденция. Многие люди считают, что на данный момент RTX 3090 предлагает оптимальный баланс для опытных пользователей — сочетание экономичности, объема видеопамяти и вычислительной мощности.
Проще говоря, если рассматривать только количество ядер CUDA и пропускную способность памяти, RTX 3090 показывает производительность, сравнимую с RTX 5080. Однако RTX 3090 имеет значительное преимущество в объеме видеопамяти – 24 ГБ против отсутствия таковой у RTX 5080. Энергопотребление (TDP) RTX 3090 также ниже, чем у более дорогой и энергоёмкой RTX 4090 и RTX 5090.
С другой стороны, RTX 3060 стала довольно популярной в сообществах, занимающихся искусственным интеллектом, благодаря своим 12 ГБ видеопамяти и более низкой стоимости. Хотя у неё меньше пропускной способности памяти и TDP 170 Вт, можно использовать две видеокарты RTX 3060, чтобы получить общий объём видеопамяти и энергопотребление, сопоставимые с RTX 3090, при этом потратив значительно меньше денег.
После некоторого времени, проведенного за просмотром информации в интернете, становится очевидной повторяющаяся тенденция. Многие люди утверждают, что RTX 3090 в настоящее время предлагает лучшее соотношение цены и производительности для опытных пользователей.
Вместо этого, подумайте о разумных инвестициях, а не о спешке с покупкой самой дорогой и передовой видеокарты. Важно найти правильный баланс, исходя из ваших конкретных потребностей, поэтому уделите время изучению и пониманию того, что вам действительно нужно.
Прежде всего, определите желаемый бюджет для покупки видеокарты. Стремитесь приобрести самую быструю видеокарту с максимальным объемом видеопамяти, который она может предложить. Поскольку Ollama поддерживает использование нескольких видеокарт, рассмотрите возможность покупки двух видеокарт по 12 ГБ, если они дешевле одной карты на 24 ГБ, так как это может быть экономически выгодным решением.
И, наконец…

По возможности, стоит рассмотреть видеокарты NVIDIA в данный момент, особенно для локальных приложений искусственного интеллекта. Хотя Ollama и поддерживает некоторые видеокарты AMD, NVIDIA в настоящее время предлагает более подходящие варианты благодаря значительному лидерству в развитии технологий искусственного интеллекта. AMD наверстывает упущенное, но преимущество NVIDIA делает их предпочтительным выбором на данный момент.
Несмотря на некоторые трудности, AMD особенно преуспевает в производстве мобильных процессоров для ноутбуков и компактных ПК. Примерно за ту же цену, что и топовая видеокарта сегодня, можно приобрести целый мини-ПК, оснащенный процессором Strix Halo поколения Ryzen AI Max+ 395 в сочетании с 128 ГБ объединенной памяти. Кроме того, он оснащен интегрированной графикой Radeon 8060S настольного класса, что является настоящим подтверждением ее возможностей.
Ollama не будет работать на системе с чипами Ryzen AI, так как они не поддерживают встроенные графические процессоры. Однако LM Studio, который поддерживает Vulkan, совместим. Система Strix Halo объемом 128 ГБ предоставляет до 96 ГБ памяти для больших языковых моделей (БЯМ), что является весьма значительным объемом.
У вас есть несколько вариантов на выбор, включая более экономичные решения. Если предпочитаемая вами видеокарта относится к более старому поколению, изучите список Ollama на предмет возможных альтернатив. Стремитесь приобрести как можно больше видеопамяти (VRAM), даже если это означает использование нескольких видеокарт, когда это уместно. Если вам удастся найти пару RTX 3060 с 12 ГБ памяти по цене от 500 до 600 долларов, вы на пути к отличной сборке.
Не позволяйте недостатку оборудования или финансовым ограничениям помешать вам принять участие. Вместо этого потратьте немного времени на изучение вопроса, чтобы убедиться, что вы получаете лучшее соотношение цены и качества от своих вложений и в полной мере наслаждаетесь опытом.
Смотрите также
- Новые смартфоны. Что купить в марте 2026.
- Санкционный удар по России: Минфин США расширяет список ограничений – что ждет экономику? (25.02.2026 05:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- vivo X300 FE ОБЗОР: портретная/зум камера, беспроводная зарядка, объёмный накопитель
- Неважно, на что вы фотографируете!
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- Как установить Virtualbox на Windows 11 для бесплатных виртуальных машин
- Умные Поверхности для Сетей Будущего: Новый Шаг к 6G
- Cubot X100 ОБЗОР: отличная камера, удобный сенсор отпечатков, плавный интерфейс
2025-08-25 22:41