Автор: Денис Аветисян
Новое исследование предлагает более точные модели для понимания поведения пользователей в интерфейсах-каруселях, таких как Netflix и Spotify.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Разработка моделей кликов, основанных на отслеживании взгляда, для повышения точности рекомендаций в многосписочных интерфейсах.
В большинстве существующих моделей кликов, используемых в рекомендательных системах, не учитывается сложность современных интерфейсов, таких как карусели. В работе ‘From Latent to Observable Position-Based Click Models in Carousel Interfaces’ предложены новые модели кликов для карусельных интерфейсов, использующие данные отслеживания взгляда для более точного моделирования поведения пользователей. Полученные результаты демонстрируют, что предложенная модель, основанная на наблюдаемых сигналах внимания, превосходит традиционные подходы по точности предсказания кликов и соответствию паттернам просмотра. Однако, достаточно ли только точного предсказания кликов для адекватного моделирования поведения пользователя в сложных интерактивных системах?
Понимание поведения пользователей в современных интерфейсах
Современные пользовательские интерфейсы, особенно активно использующие карусели и горизонтальную прокрутку, создают серьезные трудности для понимания поведения пользователей. В отличие от традиционных списков, где выбор элемента относительно прост и предсказуем, карусели предлагают множество вариантов, скрытых от непосредственного взгляда, что усложняет процесс принятия решения. Пользователь может прокручивать контент, перескакивать между элементами, или вовсе игнорировать определенные части карусели, что делает невозможным применение стандартных моделей анализа кликов. Изучение паттернов прокрутки, времени, проведенного над каждым элементом, и глубины прокрутки становится ключевым для адекватного понимания пользовательского намерения и оценки эффективности подобного типа интерфейсов. Понимание этих особенностей необходимо для оптимизации дизайна и повышения удобства использования, ведь неверная интерпретация поведения может привести к неоптимальному представлению информации и снижению вовлеченности.
Традиционные модели анализа кликов, разработанные для простых списков, оказываются неэффективными при изучении взаимодействия пользователей с современными многоуровневыми интерфейсами, такими как карусели. Эти модели, как правило, предполагают последовательное перечисление элементов и клик по одному из них, не учитывая специфику прокрутки, скрытых элементов и сложных паттернов выбора, характерных для каруселей. В результате, оценка вероятности клика по конкретному элементу в карусели становится неточной, поскольку не отражает влияние позиционирования элемента, видимости и динамики прокрутки. Это создает значительные трудности при интерпретации данных о пользовательском поведении и, как следствие, при оптимизации дизайна интерфейса для повышения его удобства и эффективности.
Точное моделирование поведения пользователей в контексте современных интерфейсов имеет решающее значение для оптимизации их дизайна и повышения качества пользовательского опыта. Неспособность адекватно учитывать сложные паттерны взаимодействия, возникающие в многоуровневых средах, таких как карусели, приводит к неэффективным интерфейсам и снижению удовлетворенности пользователей. Понимание того, как люди навигаруют по этим сложным структурам, позволяет разработчикам создавать более интуитивные и удобные системы, повышая вовлеченность и продуктивность. В конечном итоге, акцент на точном моделировании поведения становится ключевым фактором в создании цифровых продуктов, ориентированных на потребности и ожидания пользователей.
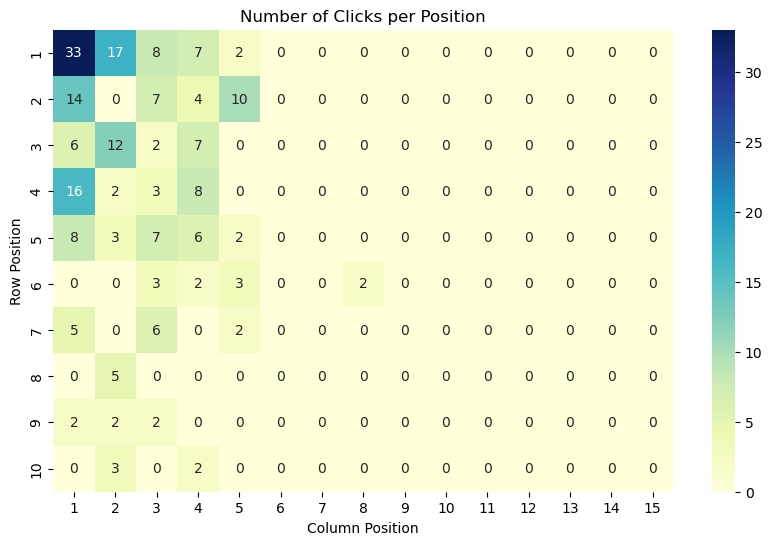
Позиционные модели: первый шаг к пониманию
Позиционные модели представляют собой базовый подход к анализу взаимодействия пользователей с элементами, основанный исключительно на ранге позиции каждого элемента в списке, без учета характеристик самих элементов или их взаимосвязей. Данный подход рассматривает вероятность взаимодействия пользователя с элементом как функцию только от его позиции — например, первый элемент имеет более высокую вероятность просмотра, чем элементы, расположенные ниже. Игнорирование атрибутов контента и контекста позволяет упростить анализ и создать начальную модель поведения, однако ограничивает точность прогнозирования в более сложных сценариях взаимодействия.
Позиционные модели предсказывают внимание пользователя, используя понятия вероятности привлечения (P_{attract}) и вероятности осмотра (P_{examine}). Вероятность привлечения отражает, насколько позиция элемента привлекает внимание пользователя, а вероятность осмотра — вероятность того, что пользователь действительно посмотрит на элемент, находящийся в данной позиции. Эти вероятности часто рассчитываются на основе наблюдаемых данных о поведении пользователей, таких как частота кликов или время просмотра, и используются для оценки относительной важности каждой позиции в списке или на странице. Комбинация этих вероятностей позволяет модели предсказывать, какие элементы, вероятно, получат наибольшее внимание.
Позиционные модели, несмотря на свою простоту, демонстрируют ограниченную эффективность в анализе поведения пользователей в сложных интерфейсах, таких как карусели. Это связано с тем, что они рассматривают элементы исключительно на основе их ранга, игнорируя контекст и взаимодействие между элементами. Пользователи в каруселях часто пролистывают контент, не обращая внимания на позиции, и их выбор определяется визуальными характеристиками, релевантностью контента и предыдущими взаимодействиями. Таким образом, позиционные модели не способны адекватно отразить сложность пользовательского поведения в таких средах и часто приводят к неточным прогнозам.
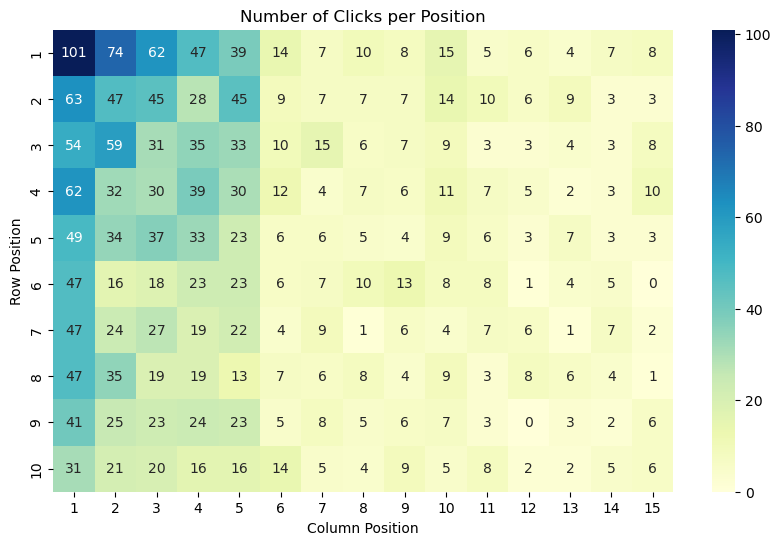
Интеграция отслеживания взгляда для повышения точности
Модель, основанная на наблюдаемой позиции осмотра (Observed Examination Position Based Model), отличается от традиционных подходов интеграцией данных отслеживания взгляда (Eye Tracking Data). Это позволяет фиксировать и анализировать зрительное внимание пользователя при взаимодействии с элементами интерфейса. Вместо использования только информации о кликах, модель учитывает, куда именно пользователь смотрит, как долго он фиксирует взгляд на определенных объектах и последовательность этих фиксаций. Данный подход позволяет более точно определить факторы, влияющие на процесс осмотра элементов и, как следствие, на вероятность клика.
Анализ направления взгляда пользователей позволяет получить более глубокое понимание факторов, влияющих на просмотр элементов и частоту кликов в каруселях. Отслеживание движений глаз фиксирует, какие элементы привлекают внимание, как долго пользователь удерживает взгляд на конкретном объекте, и последовательность просмотра. Эти данные позволяют выявить корреляции между визуальным вниманием и действиями пользователя, такими как клики или прокрутка, что дает возможность оптимизировать представление контента в карусели для повышения вовлеченности и улучшения пользовательского опыта. Например, можно определить, какие визуальные характеристики элементов (цвет, размер, расположение) наиболее эффективно привлекают внимание, и использовать эту информацию для улучшения дизайна карусели.
Разработанная модель демонстрирует логарифмическую правдоподобность на тестовом наборе данных в -0.2264, что свидетельствует о значительном превосходстве над базовыми моделями. Для обучения и валидации данной модели используется датасет ‘RecGaze’, объединяющий данные о кликах пользователей и отслеживании их взгляда. Этот датасет предоставляет ценную информацию для анализа и улучшения алгоритмов, учитывающих визуальное внимание пользователя.
Методы обучения и оптимизации моделей
Обучение сложных моделей кликов, используемых в карусельных интерфейсах, базируется на применении продвинутых статистических методов, таких как метод максимального правдоподобия (Maximum Likelihood Estimation, MLE) и алгоритм Expectation-Maximization (EM). MLE позволяет оценить параметры модели путем максимизации функции правдоподобия, определяющей вероятность наблюдения имеющихся данных при заданных параметрах. Алгоритм EM, в свою очередь, применяется для поиска оценок параметров в моделях, содержащих скрытые переменные, и итеративно уточняет эти оценки путем чередования шагов ожидания (Expectation) и максимизации (Maximization). Оба метода требуют значительных вычислительных ресурсов, особенно при работе с большими объемами данных, но обеспечивают высокую точность и надежность полученных моделей.
В ходе обучения моделей, алгоритмы оптимизации, в частности, метод градиентного подъема (Gradient Ascent), демонстрировали стабильно более высокие результаты по сравнению с методами максимального правдоподобия (Maximum Likelihood Estimation) и ожиданий-максимизации (Expectation-Maximization). Экспериментальные данные показали, что градиентный подъем обеспечивает более быструю сходимость и позволяет достичь более высокой точности прогнозирования в задачах обучения моделей кликов. Преимущество данного метода проявляется в способности эффективно адаптироваться к сложным параметрическим пространствам, характерным для моделей, используемых в карусельных интерфейсах.
Обучение моделей кликов для карусельных интерфейсов основывается на анализе наблюдаемых данных о взаимодействии пользователей. Эти данные, включающие информацию о просмотренных элементах, кликах и времени, проведенном на каждом элементе, используются для выявления закономерностей в поведении пользователей. Модели, построенные на основе этих данных, позволяют прогнозировать вероятность клика на конкретный элемент карусели, учитывая контекст взаимодействия и индивидуальные предпочтения пользователей. Точность прогнозирования напрямую зависит от объема и качества данных, а также от эффективности используемых статистических методов и алгоритмов оптимизации.
Перспективы и широкое влияние исследований
Несмотря на свою упрощенность, каскадная модель играет важную роль в оценке эффективности более сложных подходов. Она служит надежным базовым уровнем для сравнения, позволяя четко определить, насколько существенно улучшают результаты добавление новых факторов и особенностей. Именно благодаря возможности сопоставления с этой базовой моделью исследователям удается точно измерить влияние каждого нового элемента интерфейса на поведение пользователя и, в конечном итоге, создать более адаптивные и персонализированные системы. Каскадная модель предоставляет отправную точку, позволяющую оценить прирост производительности, обеспечиваемый более сложными алгоритмами, и является необходимым инструментом для разработки и оптимизации пользовательских интерфейсов будущего.
Исследование продемонстрировало существенное улучшение наблюдаемой логарифмической правдоподобности при использовании предложенного подхода по сравнению с каскадными моделями. Важно отметить, что каскадные модели оказались неспособными к оценке из-за неопределённых значений, что подчеркивает значимость предложенного метода для более точного анализа данных. Полученные результаты свидетельствуют о возможности преодоления ограничений существующих моделей и открывают перспективы для разработки более эффективных алгоритмов, способных учитывать сложные паттерны поведения пользователей и обеспечивать более адекватную оценку вероятности различных сценариев взаимодействия с интерфейсом.
Исследование открывает перспективы для создания персонализированных пользовательских интерфейсов, способных адаптироваться к индивидуальным предпочтениям и паттернам внимания каждого пользователя. Вместо универсальных решений, предлагаемых большинством современных систем, разработанный подход позволяет динамически формировать интерфейс, учитывая особенности восприятия информации конкретным человеком. Это достигается за счет анализа поведения пользователя при взаимодействии с системой, выявления его приоритетов и предпочтительных способов обработки данных. В результате, интерфейс может автоматически оптимизировать расположение элементов, выделять наиболее важную информацию и предлагать наиболее релевантные функции, повышая эффективность работы и улучшая пользовательский опыт. Такой подход особенно важен в контексте растущей сложности программного обеспечения и перегруженности информацией, поскольку позволяет пользователям быстро и легко находить необходимые инструменты и данные.
Исследование показывает, что поведение пользователя в карусельных интерфейсах сложнее, чем предполагалось ранее. Если система рекомендаций держится на костылях, пытаясь учесть только позицию элемента, значит, мы переусложнили её, игнорируя контекст взгляда. Как точно отметил Анри Пуанкаре: «Математика — это искусство находить закономерности, которые скрыты от глаз». В данном случае, закономерности кроются в движении глаз пользователя, позволяя создать более адекватную модель кликов и, как следствие, повысить точность рекомендаций. Модульность без понимания контекста — иллюзия контроля, а карусельный интерфейс требует целостного подхода к анализу поведения.
Куда двигаться дальше?
Представленная работа, исследуя переход от скрытых к наблюдаемым моделям кликов в карусельных интерфейсах, обнажает фундаментальную сложность понимания поведения пользователя. Зачастую, элегантность решения кроется не в усложнении модели, а в выявлении ключевых взаимодействий. Однако, вопрос о том, как адекватно масштабировать полученные результаты на различные типы контента и интерфейсов, остается открытым. Простое добавление новых параметров, без глубокого понимания их влияния на общую структуру системы, может привести к непредсказуемым последствиям.
Особый интерес представляет изучение динамики взгляда не только как предвестника клика, но и как индикатора когнитивной нагрузки. В конце концов, интерфейс должен служить пользователю, а не наоборот. Попытки оптимизировать кликабельность любой ценой, игнорируя когнитивные издержки, выглядят, по меньшей мере, нелогично. Вместо погони за точкой клика, возможно, стоит сосредоточиться на создании интуитивно понятных и эффективных систем навигации.
В перспективе, интеграция данных о движении глаз с другими источниками информации — например, с данными о контексте использования, эмоциональном состоянии пользователя или его предыдущем опыте — может привести к созданию действительно адаптивных и персонализированных рекомендательных систем. Но следует помнить: любая система, как живой организм, требует бережного отношения и постоянного анализа, чтобы избежать нежелательных мутаций.
Оригинал статьи: https://arxiv.org/pdf/2602.16541.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Неважно, на что вы фотографируете!
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Что такое ISO в фотоаппарате
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- Технологии и вера: новый взгляд на инклюзивный дизайн
- vivo iQOO Z11 Turbo ОБЗОР: огромный накопитель, отличная камера, много памяти
2026-02-19 17:04