Автор: Денис Аветисян
Исследователи представили MedVL-SAM2 — систему, объединяющую возможности понимания языка и точного 3D-сегментирования медицинских изображений для улучшения диагностики и взаимодействия с данными.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"![В предложенной архитектуре визуально-языковая модель, подобная LLaVA, обрабатывает трехмерные объемы данных и генерирует текст, при этом активация токена [SEG] инициирует передачу скрытого состояния в модуль сегментации SAM2, где оно объединяется с визуальными подсказками - точками или ограничивающими рамками - для формирования окончательной маски сегментации.](https://arxiv.org/html/2601.09879v1/x2.png)
MedVL-SAM2 — это унифицированная 3D модель, сочетающая возможности обработки изображений и языка для мультимодального анализа и интерактивной сегментации в медицинской визуализации.
Несмотря на значительный прогресс в области медицинских моделей «зрение-язык», объединение высокоуровневого семантического анализа с точной трехмерной сегментацией остается сложной задачей. В настоящей работе представлена модель MedVL-SAM2: A unified 3D medical vision-language model for multimodal reasoning and prompt-driven segmentation, предлагающая унифицированный подход к анализу трехмерных медицинских изображений, объединяющий понимание языка, визуальное обоснование и интерактивную сегментацию. Ключевым результатом является возможность гибкого взаимодействия с данными посредством текстовых запросов, указателей или ограничивающих рамок, обеспечивая точную локализацию и пространственное рассуждение. Способна ли данная архитектура стать основой для создания интеллектуальных систем поддержки принятия решений в клинической практике?
Вызов Трёхмерного Медицинского Понимания
Традиционные методы анализа медицинских изображений часто сталкиваются с серьёзными трудностями при обработке трёхмерных объёмов данных. Сложность заключается в том, что получение полной и точной картины требует учёта огромного количества информации, представленной в различных срезах и проекциях. Это может приводить к ошибкам в диагностике, поскольку даже незначительные детали, скрытые в трёхмерном пространстве, могут быть упущены из виду. Неспособность эффективно анализировать трёхмерные данные ограничивает возможности врачей в выявлении ранних признаков заболеваний и разработке оптимальных стратегий лечения, особенно в таких областях, как онкология и нейрохирургия, где точность имеет решающее значение.
Существующие методы анализа медицинских изображений часто сталкиваются с трудностями при интеграции визуальной информации с текстовыми отчётами, что существенно ограничивает возможности всестороннего понимания клинической картины. Врачи, как правило, вынуждены сопоставлять данные, полученные с томографических и рентгеновских снимков, с результатами лабораторных исследований и письменными заключениями, что является трудоёмким и подверженным ошибкам процессом. Отсутствие автоматизированных систем, способных объединить эти разнородные источники информации, приводит к неполной оценке состояния пациента и может негативно сказаться на точности диагностики и выборе оптимальной стратегии лечения. Разработка алгоритмов, объединяющих визуальные и текстовые данные, представляется критически важной задачей для повышения эффективности и надёжности медицинской диагностики.

MedVL-SAM2: Унифицированная 3D Медицинская VLM
MedVL-SAM2 представляет собой новую архитектуру 3D медицинской модели Vision-Language (VLM), объединяющую задачи сегментации, генерации отчётов и визуального вопросно-ответного анализа (VQA) в единый фреймворк. В отличие от традиционных подходов, требующих отдельных моделей для каждой задачи, MedVL-SAM2 позволяет выполнять все три типа анализа на основе единого набора параметров и данных, что повышает эффективность и согласованность результатов. Интеграция этих функций позволяет модели не только идентифицировать и выделять анатомические структуры, но и автоматически формировать текстовые описания и отвечать на вопросы, касающиеся изображений, обеспечивая комплексный анализ медицинских данных.
Интеграция Segment Anything Model 2 (SAM2) с мультимодальной архитектурой, основанной на LLaVA, и MLP-Mixer обеспечивает превосходное пространственное обоснование и логическое мышление. SAM2, как мощный инструмент сегментации изображений, предоставляет точные маски объектов, которые служат основой для понимания анатомических структур. Архитектура LLaVA позволяет модели эффективно обрабатывать как визуальную, так и языковую информацию, объединяя их для выполнения различных задач. MLP-Mixer, в свою очередь, улучшает способность модели к рассуждениям, позволяя ей устанавливать связи между различными частями изображения и текстового описания, что критически важно для точной интерпретации медицинских данных и ответов на вопросы.
Модель MedVL-SAM2 использует предварительно обученный 3D-энкодер M3D-CLIP для улучшения восприятия и понимания сложных анатомических структур. M3D-CLIP, обученный на больших объёмах 3D-медицинских данных, позволяет модели эффективно извлекать признаки из волюметрических изображений, таких как КТ и МРТ. Это обеспечивает более точное пространственное позиционирование и понимание взаимосвязей между различными анатомическими объектами, что критически важно для задач сегментации, генерации отчётов и ответов на вопросы по изображениям.
Усиление Производительности посредством Мультимодального Рассуждения
Модель MedVL-SAM2 демонстрирует повышенную точность в задачах генерации отчётов и визуального вопросно-ответного взаимодействия (VQA) благодаря интеграции визуальной и текстовой информации. В основе этой способности лежит LLM-бэкбон (Large Language Model), который позволяет модели эффективно обрабатывать и сопоставлять данные из различных модальностей. Это обеспечивает более глубокое понимание медицинских изображений и контекста, что, в свою очередь, приводит к более точным и информативным результатам в задачах, требующих анализа и интерпретации визуальных данных и сопутствующего текста.
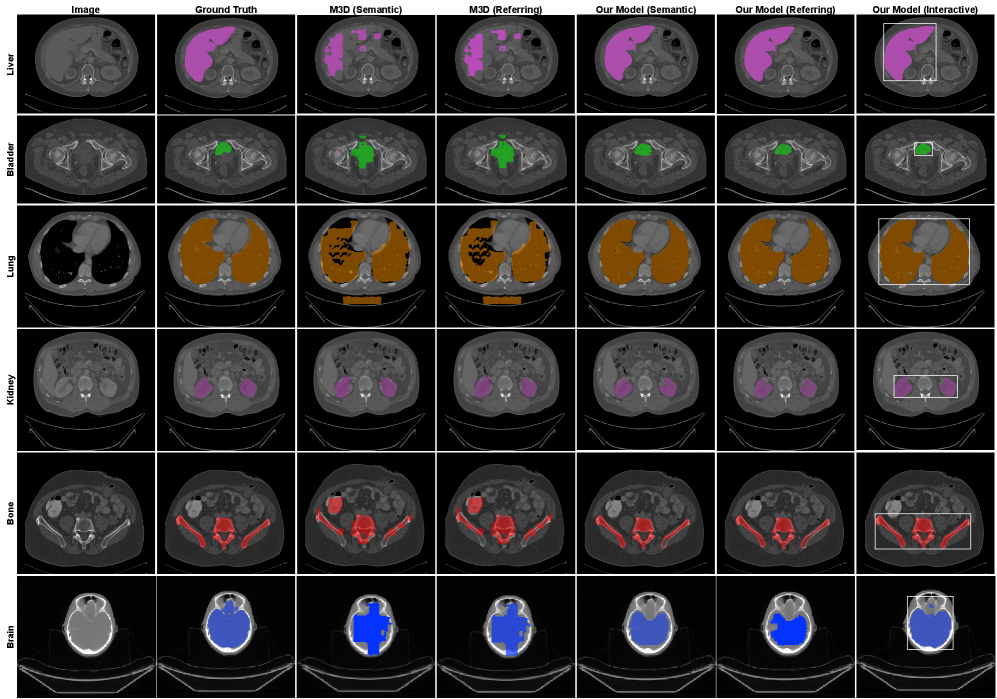
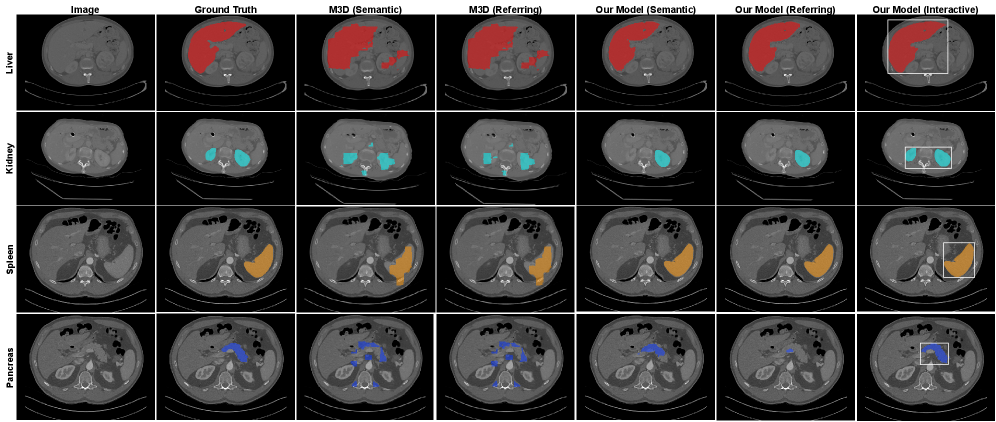
Инженерное проектирование промптов в MedVL-SAM2 обеспечивает детализированное управление сегментацией и другими задачами, позволяя пользователю интерактивно уточнять результаты и добиваться точной анатомической детализации. Это достигается за счёт возможности задания конкретных инструкций и параметров в промпте, определяющих, какие структуры необходимо выделить, какие критерии сегментации использовать, и как обрабатывать сложные или неоднозначные случаи. Такой подход позволяет не только автоматизировать процесс сегментации, но и адаптировать его к специфическим потребностям конкретной задачи и обеспечивать высокую точность анатомического определения.
Модель MedVL-SAM2 обеспечивает анатомическую согласованность между соседними срезами изображений благодаря механизму Cross-Slice Consistency. Данный механизм позволяет модели учитывать пространственные взаимосвязи между анатомическими структурами, представленными на различных срезах, что критически важно для построения точного трёхмерного представления. В процессе сегментации и анализа изображений, Cross-Slice Consistency гарантирует, что идентифицированные структуры логически связаны и непрерывны при переходе от одного среза к другому, снижая вероятность ошибок и обеспечивая более надежную реконструкцию анатомических объектов. Это особенно важно для задач, требующих точного понимания пространственного расположения и формы органов и тканей.
Масштабирование с Данными: Набор Данных CT-RATE
Набор данных CT-RATE представляет собой обширный ресурс, состоящий из трёхмерных томографических изображений грудной клетки, сопоставленных с радиологическими заключениями и парами вопросов-ответов (VQA). Этот набор данных является критически важным для обучения и оценки модели MedVL-SAM2, обеспечивая необходимую информацию для развития её возможностей в области медицинской визуализации и обработки естественного языка. Объем и разнообразие данных в CT-RATE позволяют модели эффективно обучаться и обобщать знания, что необходимо для надёжной работы в различных клинических сценариях. Структура данных, включающая как изображения, так и текстовые описания, позволяет проводить комплексную оценку и оптимизацию производительности модели в задачах генерации отчётов и визуального вопросно-ответного анализа.
Масштабный характер набора данных CT-RATE обеспечивает надёжную производительность модели MedVL-SAM2 в широком спектре клинических сценариев. Большой объём 3D-изображений КТ, сопоставленных с радиологическими отчётами и парами вопросов-ответов, позволяет модели обучаться на разнообразных примерах, что значительно повышает её способность к обобщению. Это означает, что MedVL-SAM2 демонстрирует стабильно высокие результаты не только на данных, использованных при обучении, но и на новых, ранее не встречавшихся случаях, что критически важно для практического применения в медицинской диагностике и анализе.
Использование датасета CT-RATE позволило модели MedVL-SAM2 достичь передовых результатов, превзойдя существующие 3D медицинские VLMs, такие как CT-Chat и M3D. В задачах генерации радиологических заключений наблюдалось улучшение по метрикам BLEU-1, ROUGE, METEOR и CIDEr. В частности, точность модели в задачах VQA с множественным выбором ответов составила 89.74%, что свидетельствует о высокой эффективности MedVL-SAM2 в понимании и анализе медицинских изображений и связанных с ними отчётов.
![Предложенные методы превосходят CT-CHAT в задачах визуального вопросно-ответного анализа (VQA), включая вопросы с развернутыми, краткими ответами и множественным выбором, при этом важная клиническая информация выделена красным цветом, а CT-CHAT использует специальные токены ([short_answer],[long_answer],[multiple_choice]) для обозначения подмножества вопросов.](https://arxiv.org/html/2601.09879v1/x3.png)
Будущее AI-Ассистированной Медицинской Визуализации
MedVL-SAM2 представляет собой значительный прорыв в области автоматизированной медицинской визуализации, открывая новые возможности для оптимизации рабочих процессов и повышения точности диагностики. Эта инновационная система способна автоматизировать рутинные задачи, такие как сегментация органов и выявление патологий на изображениях компьютерной томографии и других видах медицинских снимков. Повышение эффективности анализа изображений позволяет врачам сосредоточиться на более сложных клинических случаях, а также ускоряет проведение исследований и разработку новых методов лечения. Благодаря способности к более детальному и точному анализу, MedVL-SAM2 способствует более раннему выявлению заболеваний и, как следствие, улучшению прогноза для пациентов. Данная разработка имеет потенциал для трансформации подходов к медицинской диагностике и оказанию помощи, открывая путь к персонализированной медицине и более эффективному лечению.
Интерактивная сегментация, реализованная в системе, предоставляет клиницистам уникальную возможность уточнять и корректировать результаты анализа медицинских изображений. Вместо автоматической, полностью независимой интерпретации, система предлагает совместную работу человека и искусственного интеллекта. Клиницист может вносить правки, выделять области, требующие особого внимания, и таким образом, направлять процесс анализа. Этот подход не только повышает точность диагностики, особенно в сложных случаях, но и позволяет учитывать индивидуальные особенности пациента, которые могут быть упущены при автоматической обработке. В результате, формируется более полное и надёжное заключение, основанное на синергии опыта специалиста и вычислительных возможностей искусственного интеллекта.
Модель MedVL-SAM2 демонстрирует значительное повышение точности сегментации, что подтверждается улучшенными показателями Dice на наборах данных CT-Org и ACT-1K. Особенно примечательно, что система успешно справляется с задачами, требующими выделения небольших структур, даже при использовании ограничивающих прямоугольников в качестве подсказок. Сочетание возможностей трёхмерного анализа изображений и понимания естественного языка позволяет MedVL-SAM2 открывать новые перспективы в области персонализированной медицины, способствуя более точной диагностике и, как следствие, улучшению результатов лечения пациентов. Эта технология может стать ключевым инструментом для автоматизации рутинных задач, снижения нагрузки на врачей-радиологов и повышения эффективности всей системы здравоохранения.

Исследование представляет собой стремление к математической чистоте в области медицинской визуализации. Модель MedVL-SAM2 демонстрирует, что элегантность алгоритма не зависит от конкретной реализации, а определяется непротиворечивостью и точностью. Как отмечал Дэвид Марр: «Вы должны понимать, что представление — это не просто данные, а модель мира». Эта цитата прекрасно иллюстрирует суть работы — создание не просто сегментирующей модели, а целостного представления о 3D медицинских изображениях, способного к логическому выводу и взаимодействию на основе языковых запросов. Модель, способная к объемному рассуждению, является шагом к созданию по-настоящему интеллектуальных систем медицинской диагностики.
Куда же дальше?
Представленная работа, безусловно, демонстрирует потенциал унифицированных моделей для работы с трёхмерными медицинскими изображениями и языковыми запросами. Однако, не стоит обманываться кажущейся элегантностью. Если сегментация кажется магией — значит, инварианты, лежащие в её основе, остаются недостаточно изученными. Проблема не в достигнутой точности, а в её объяснимости. До тех пор, пока алгоритм не может предоставить формальное доказательство корректности своих решений, он остаётся лишь сложным эвристическим инструментом.
Следующим шагом представляется не просто увеличение объёма обучающих данных или усложнение архитектуры, а разработка формальных методов верификации и валидации таких моделей. Необходимо перейти от эмпирических оценок к доказательству робастности и надёжности алгоритмов. Интересно представляется исследование возможностей применения формальных методов, таких как теоремы инвариантности и логические исчисления, для обеспечения надёжности медицинских приложений на основе искусственного интеллекта.
Кроме того, остаётся открытым вопрос о масштабируемости подобных моделей для работы с данными различного качества и модальности. Унификация — это прекрасно, но она не должна приводить к усреднению и потере специфических особенностей каждого типа медицинских изображений. Истинная элегантность заключается не в сложности, а в способности к упрощению и обобщению, сохраняя при этом точность и надёжность.
Оригинал статьи: https://arxiv.org/pdf/2601.09879.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- Лучшие смартфоны. Что купить в марте 2026.
2026-01-19 00:03